") 分享10個Pandas在實際應(yīng)用中肯定會用到的技巧
分享10個Pandas在實際應(yīng)用中肯定會用到的技巧
pandas是數(shù)據(jù)科學(xué)家必備的數(shù)據(jù)處理庫,我們今天總結(jié)了10個在實際應(yīng)用中肯定會用到的技巧。
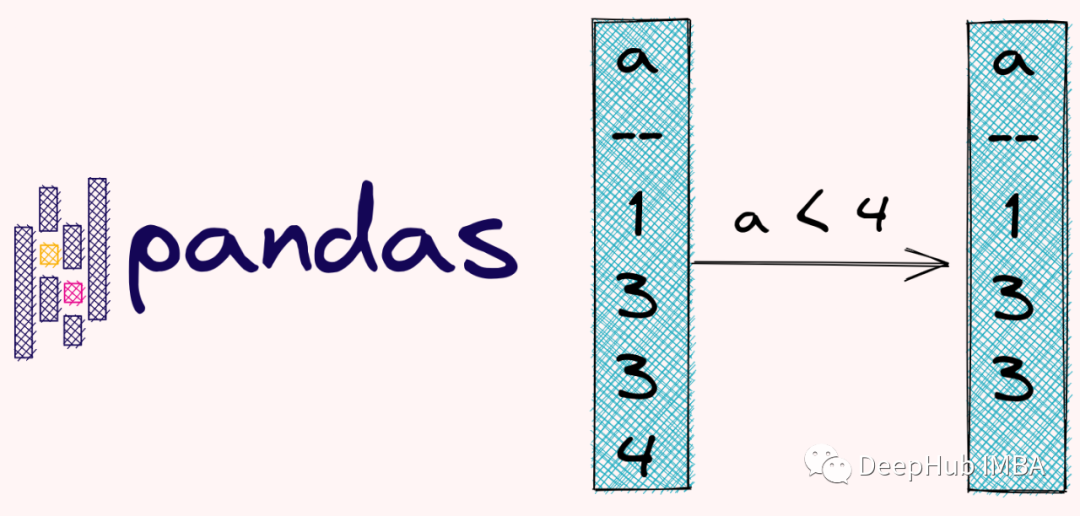
1、Select from table where f1=’a’ and f2=’b’
使用AND或OR選擇子集:
dfb=df.loc[(df.Week==week)&(df.Day==day)]
OR的話是這樣dfb=df.loc[(df.Week==week)|(df.Day==day)]
2、Select where in
從一個df中選擇一個包含在另外一個df的數(shù)據(jù),例如下面的sql
select*fromtable1wherefield1in(selectfield1fromtable2)
我們有一個名為“days”的df,它包含以下值。

如果有第二個df:
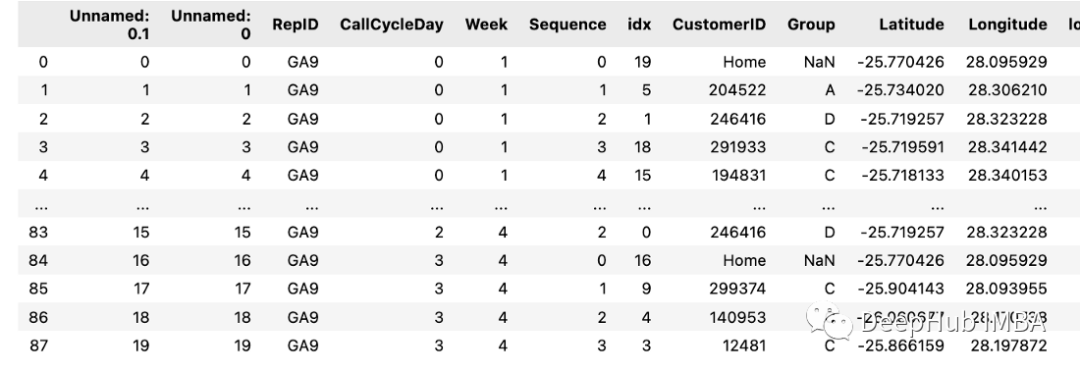
可以直接用下面的方式獲取
days=[0,1,2]
df[df(days)]
3、Select where not in
就像IN一樣,我們肯定也要選擇NOT IN,這個可能是更加常用的一個需求,但是卻很少有文章提到,還是使用上面的數(shù)據(jù):
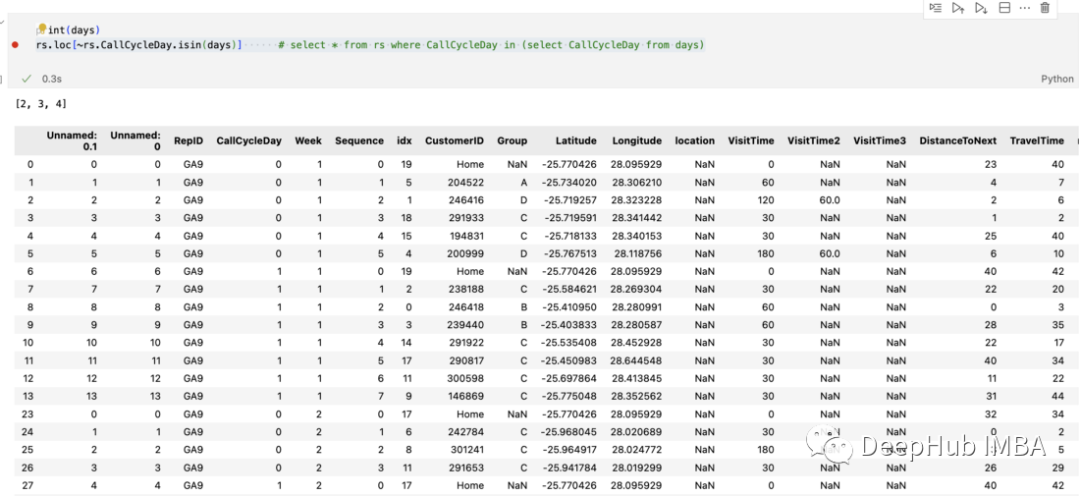
days=[0,1,2]
df[~df(days)]
使用~操作符就可以了
4、select sum(*) from table group by
分組統(tǒng)計和求和也是常見的操作,但是使用起來并不簡單:
df(by=['RepID','Week','CallCycleDay']).sum()
如果想保存結(jié)果或稍后使用它們并引用這些字段,請?zhí)砑?as_index=False
df.groupby(by=['RepID','Week','CallCycleDay'],as_index=False).sum()
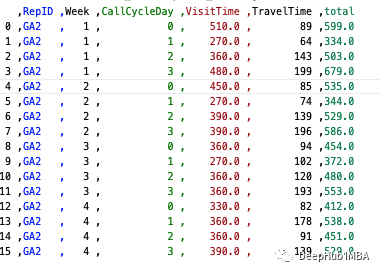
使用as_index= false,可以表的形式保存列
5、從一個表更另外一個表的字段
我們從一個df中更改了一些值,現(xiàn)在想要更新另外一個df,這個操作就很有用。
dfb=dfa[dfa.field1='somevalue'].copy()
dfb['field2']='somevalue'
dfa.update(dfb)
這里的更新是通過索引匹配的。
6、使用apply/lambda創(chuàng)建新字段
我們創(chuàng)建了一個名為address的新字段,它是幾個字段進(jìn)行拼接的。
dfa['address']=dfa.apply(lambdarow:row['StreetName']+','+
row['Suburb']+','+str(row['PostalCode']),axis=1)
7、插入新行
插入新數(shù)據(jù)的最佳方法是使用concat。我們可以用有pd. datafframe .from_records一將新行轉(zhuǎn)換為df。
newRow=row.copy()
newRow.CustomerID=str(newRow.CustomerID)+'-'+str(x)
newRow.duplicate=True
df=pd.concat([df,pd.DataFrame.from_records([newRow])])
8、更改列的類型
可以使用astype函數(shù)將其快速更改列的數(shù)據(jù)類型
df=pd.read_excel(customers_.xlsx')
df['Longitude']=df['Longitude'].astype(str)
df['Latitude']=df['Longitude'].astype(str)
9、刪除列
使用drop可以刪除列:
defcleanColumns(df):
forcolindf.columns:
ifcol[0:7]=="Unnamed":
df.drop(col,inplace=True,axis=1)
returndf
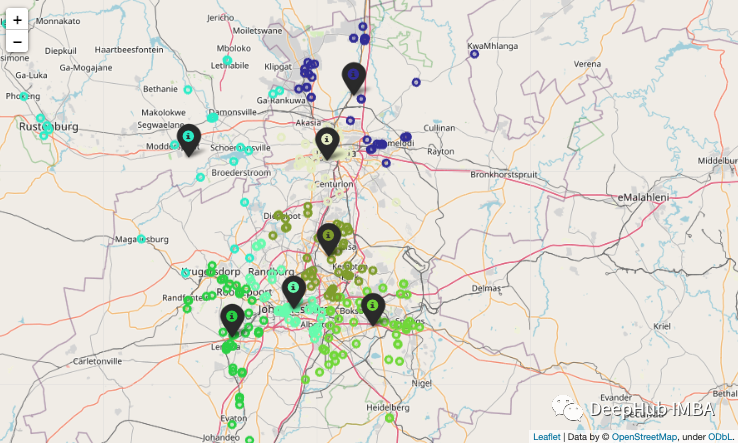
10、地圖上標(biāo)注點
這個可能是最沒用的技巧,但是他很好玩
這里我們有一些經(jīng)緯度的數(shù)據(jù):
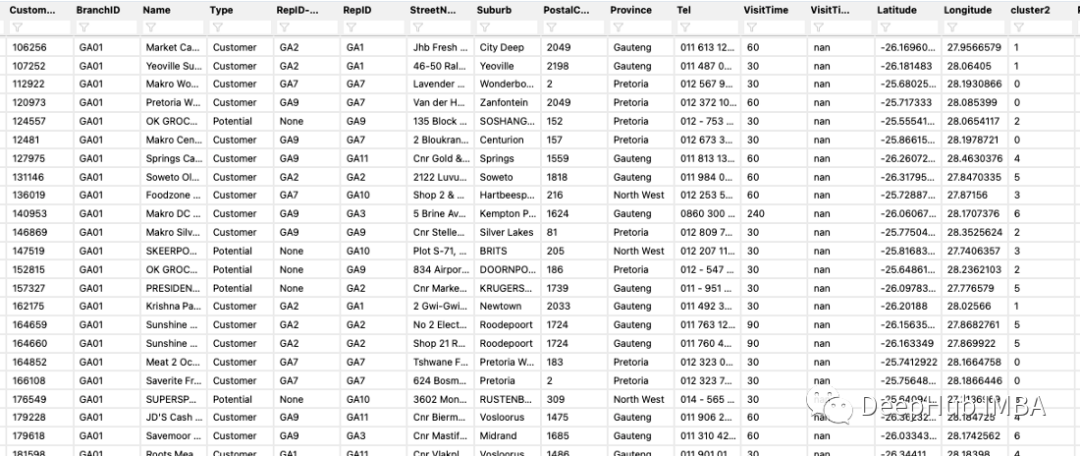
現(xiàn)在我們把它根據(jù)經(jīng)緯度在地圖上進(jìn)行標(biāo)注:
df_clustercentroids=pd.read_csv(centroidFile)
lst_elements=sorted(list(dfm.cluster2.unique()))
lst_colors=['#%06X'%np.random.randint(0,0xFFFFFF)foriinrange(len(lst_elements))]
dfm["color"]=dfm["cluster2"]
dfm["color"]=dfm["color"].apply(lambdax:lst_colors[lst_elements.index(x)])
m=folium.Map(location=[dfm.iloc[0].Latitude,dfm.iloc[0].Longitude],zoom_start=9)
forindex,rowindfm.iterrows():
folium.CircleMarker(location=[float(row['Latitude']),float(row['Longitude'])],radius=4,popup=str(row['RepID'])+'|'+str(row.CustomerID),color=row['color'],fill=True,fill_color=row['color']
).add_to(m)
forindex,rowindf_clustercentroids.iterrows():
folium.Marker(location=[float(row['Latitude']),float(row['Longitude'])],popup=str(index)+'|#='+str(dfm.loc[dfm.cluster2==index].groupby(['cluster2'])['CustomerID'].count().iloc[0]),icon=folium.Icon(color='black',icon_color=lst_colors[index]),tooltip=str(index)+'|#='+str(dfm.loc[dfm.cluster2==index].groupby(['cluster2'])['CustomerID'].count().iloc[0])).add_to(m)
m
結(jié)果如下:
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
6892瀏覽量
88828 -
SQL
+關(guān)注
關(guān)注
1文章
760瀏覽量
44076
原文標(biāo)題:分享 10 個 Pandas 的小技巧!
文章出處:【微信號:DBDevs,微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
RAPIDS cuDF將pandas提速近150倍

使用TLV3501做了一個單限比較器,可以使用到10MHZ,但是實際使用時卻達(dá)不到,為什么?
OPA552很容易損壞是怎么回事?

請問ESP-AT在編譯過程中會用到哪些源文件?
你一定會用到的紐扣電池選型方案

機(jī)器人會用到哪些傳感器
電感在使用中受潮會影響使用嗎
說說影響高低溫循環(huán)試驗箱價格的因素

用TMS320F2812的兩個單次訪問能實現(xiàn)一次配置讀寫或者普通讀寫嗎?
Python利用pandas讀寫Excel文件

優(yōu)化毫米波信號分析的五個提示

使用pandas進(jìn)行數(shù)據(jù)選擇和過濾的基本技術(shù)和函數(shù)
介紹一下I2C和SPI兩種常見的通信協(xié)議之間區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論