") SC-Depth系列的網(wǎng)絡(luò)都解決了什么問題以及實(shí)現(xiàn)了什么效果
SC-Depth系列的網(wǎng)絡(luò)都解決了什么問題以及實(shí)現(xiàn)了什么效果
0. 筆者個(gè)人體會(huì)
因?yàn)轫?xiàng)目原因需要用到無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò),目前SC-Depth系列是非常經(jīng)典的框架,因此寫下這篇文章記錄自己的學(xué)習(xí)經(jīng)歷。 深度估計(jì)其實(shí)是一個(gè)非常早的問題,早期方法主要是Structure from Motion (SfM)和Multi View Stereo (MVS)這兩種。
SfM算法輸入是一系列無序照片,兩兩照片通過特征點(diǎn)建立匹配關(guān)系,利用三角化方法獲得稀疏點(diǎn)云,之后使用BA進(jìn)行聯(lián)合優(yōu)化,輸出是整個(gè)模型是三維點(diǎn)云和相機(jī)位姿。但此類方法獲得的是稀疏點(diǎn)云,就是說深度圖也是稀疏的。MVS與SfM原理類似,但它是對(duì)每個(gè)像素都去提取特征并進(jìn)行匹配,最終可以獲得稠密的深度圖。
相較雙目/多目深度估計(jì)而言,單目深度估計(jì)更具挑戰(zhàn)性,這是因?yàn)閱文恳曈X天生就存在致命缺陷:尺度模糊。近年來深度學(xué)習(xí)技術(shù)的發(fā)展,引發(fā)了一系列單目深度估計(jì)網(wǎng)絡(luò)的問世。近期SC-DepthV3發(fā)表在了新一期的TPAMI上,對(duì)單目深度估計(jì)問題又提出了一個(gè)新的解決思路。本文將分別介紹牛津大學(xué)提出的SC-Depth系列的三個(gè)網(wǎng)絡(luò),探討它們都解決了什么問題,以及實(shí)現(xiàn)了什么效果。
1. 為什么是無監(jiān)督?
先說答案:
因?yàn)橛斜O(jiān)督太貴了!
目前單目深度估計(jì)網(wǎng)絡(luò)在KITTI、NYU等數(shù)據(jù)集上的性能其實(shí)已經(jīng)非常好了,各項(xiàng)定量指標(biāo)也好,定性估計(jì)深度圖也好,看起來已經(jīng)非常完美。但任何網(wǎng)絡(luò)、任何模型歸根結(jié)底都是要落地的,只在數(shù)據(jù)集上跑一跑沒辦法創(chuàng)造實(shí)際的產(chǎn)能。可是深度學(xué)習(xí)本身就是依賴數(shù)據(jù)集的,如果想把一個(gè)訓(xùn)練好的模型拓展到實(shí)際場(chǎng)景中,往往需要在實(shí)際場(chǎng)景進(jìn)行finetune。
如果是有監(jiān)督網(wǎng)絡(luò)的話,實(shí)際場(chǎng)景的微調(diào)就需要激光雷達(dá)、高精相機(jī)等昂貴傳感器提供的ground truth。這在很大程度上就限制了有監(jiān)督單目深度估計(jì)網(wǎng)絡(luò)的實(shí)際落地。我們更想實(shí)現(xiàn)的目標(biāo)是拿著一個(gè)相機(jī)(甚至手機(jī))拍一組視頻,就可獲得每幀的深度!
那么怎么辦呢?
無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò)就可以很好得解決這一問題!無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò)不需要提供深度真值就可以進(jìn)行訓(xùn)練,可以在任何場(chǎng)景通過一組單目視頻進(jìn)行finetune,這就意味著網(wǎng)絡(luò)具備極強(qiáng)的泛化能力! 最早的無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò)來源于2016年ECCV論文“Unsupervised CNN for single view depth estimation: Geometry to the rescue.”。
網(wǎng)絡(luò)輸入是雙目相機(jī)中的左右目圖像,但是只估計(jì)左目圖像的深度。由于左右目位姿是已知的,那么我們就可以通過左目深度圖和左右目位姿去重建左圖,之后去計(jì)算重建左圖和真實(shí)左圖之間的差異,回傳損失進(jìn)行訓(xùn)練。除這個(gè)損失外,這個(gè)網(wǎng)絡(luò)還提出了深度值的平滑損失。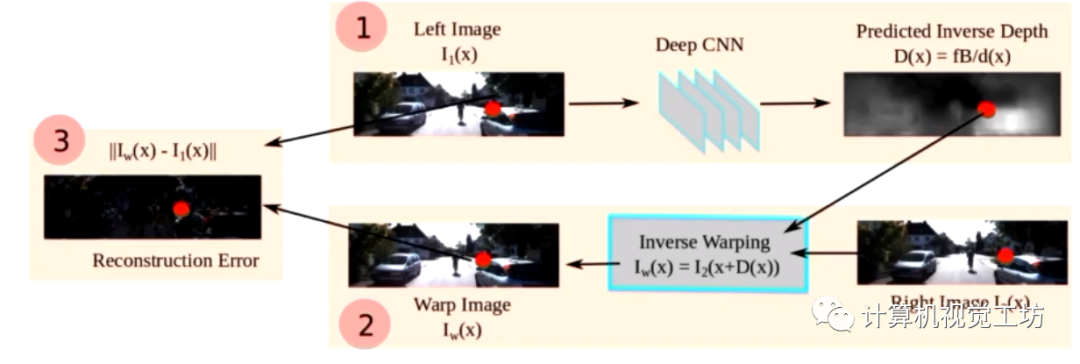
這個(gè)網(wǎng)絡(luò)名義上確實(shí)是單目深度估計(jì)網(wǎng)絡(luò),因?yàn)橹还烙?jì)了左圖的深度。但我們更希望的是網(wǎng)絡(luò)輸入是真正的單目圖像。 最早的真正只使用單目圖像的無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò)是2017年CVPR論文“Unsupervised Learning of Depth and Ego-Motion from Video”。
這個(gè)網(wǎng)絡(luò)與上一篇論文的原理類似,它的輸入是單目視頻序列中的前后兩幀。首先給第一幀圖像估計(jì)深度圖,同時(shí)估計(jì)兩幀圖像中的位姿,之后利用深度圖和位姿重建第一幀圖像,同樣去計(jì)算與真實(shí)圖像之間的差異。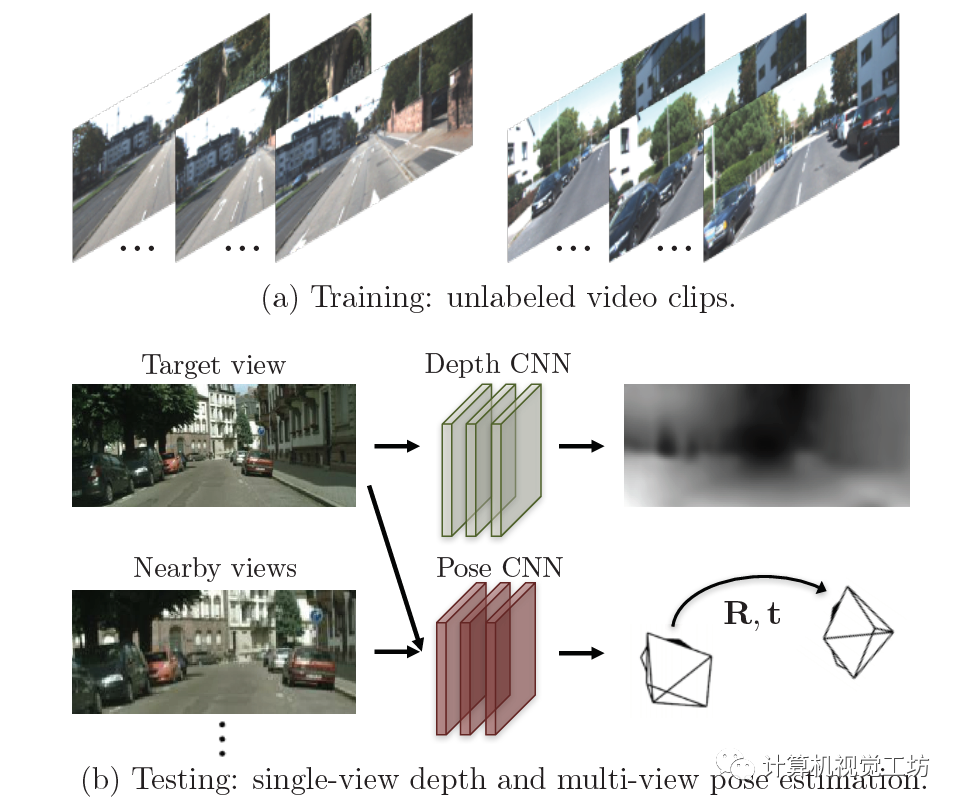
之后的SOTA方法就是大家所熟知的Monodepth2,來源于2019年ICCV論文“Digging Into Self-Supervised Monocular Depth Estimation”。其原理還是利用SfM同時(shí)估計(jì)深度網(wǎng)絡(luò)和位姿網(wǎng)絡(luò)。網(wǎng)絡(luò)輸入為單目視頻的連續(xù)多幀圖片,根據(jù)深度網(wǎng)絡(luò)和位姿網(wǎng)絡(luò)構(gòu)建重投影圖像,計(jì)算重投影誤差并引入至損失函數(shù)。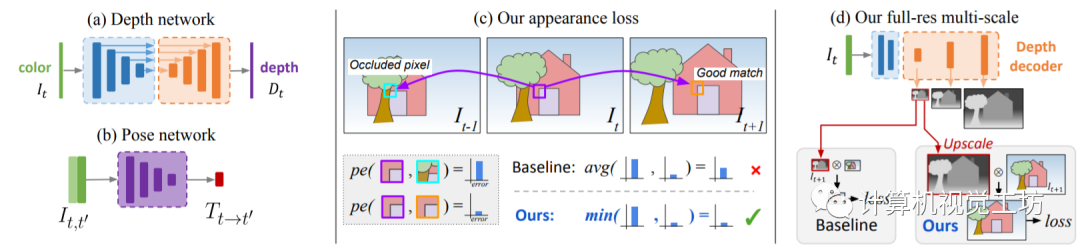
雖然近些年也出現(xiàn)了非常多的單目深度估計(jì)網(wǎng)絡(luò),但大多都是基于Monodepth2和SC-Depth框架進(jìn)行的。因此,本文對(duì)其他網(wǎng)絡(luò)結(jié)構(gòu)不再贅述。
2. SC-DepthV1做了什么?
至此,開始引入本文真正的主角:SC-Depth系列。
之前的單目深度估計(jì)網(wǎng)絡(luò)的重投影損失,更多的是利用前后幀的顏色誤差進(jìn)行約束,得到了比較精確的結(jié)果。但它們基本上都有一個(gè)共性問題:深度值不連續(xù)!連續(xù)幾張圖像之間的深度值不連續(xù)!也就是說,在不同的幀上產(chǎn)生尺度不一致的預(yù)測(cè),因?yàn)樗鼈兂惺芰嗣繋瑘D像的尺度不確定性。
這種問題這不會(huì)影響基于單個(gè)圖像的任務(wù),但對(duì)于基于視頻的應(yīng)用至關(guān)重要,例如不能用于VSLAM系統(tǒng)中的初始化。 因此,SC-DepthV1為解決此問題提出了尺度一致性約束。具體來說,就是給前后兩幀圖像都預(yù)測(cè)深度,利用兩張圖像的深度和位姿投影到3D空間中,進(jìn)而去計(jì)算尺度一致性損失。
這種方法確保了相鄰幀之間尺度的一致性,如果每連續(xù)兩幀圖像的尺度都是一致的,那么整個(gè)視頻序列的深度序列也就是連續(xù)的。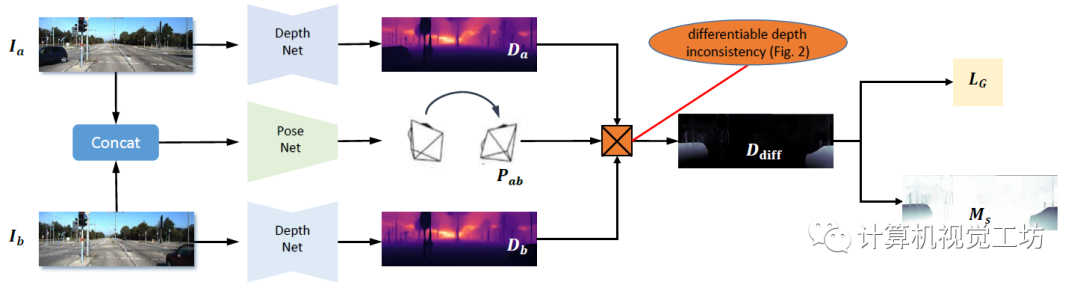
此外,SC-DepthV1還使用了一種Mask,對(duì)應(yīng)視頻上出現(xiàn)不連續(xù)的區(qū)域。作者認(rèn)為這就是動(dòng)態(tài)物體,通過去除這種Mask可以使得網(wǎng)絡(luò)具備一定的動(dòng)態(tài)環(huán)境魯棒性。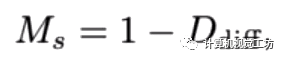
定量結(jié)果顯示,SC-DepthV1取得了與Monodepth2相持平的結(jié)果。但SC-DepthV1估計(jì)出的深度圖具有連續(xù)性,因此還是SC-DepthV1更勝一籌。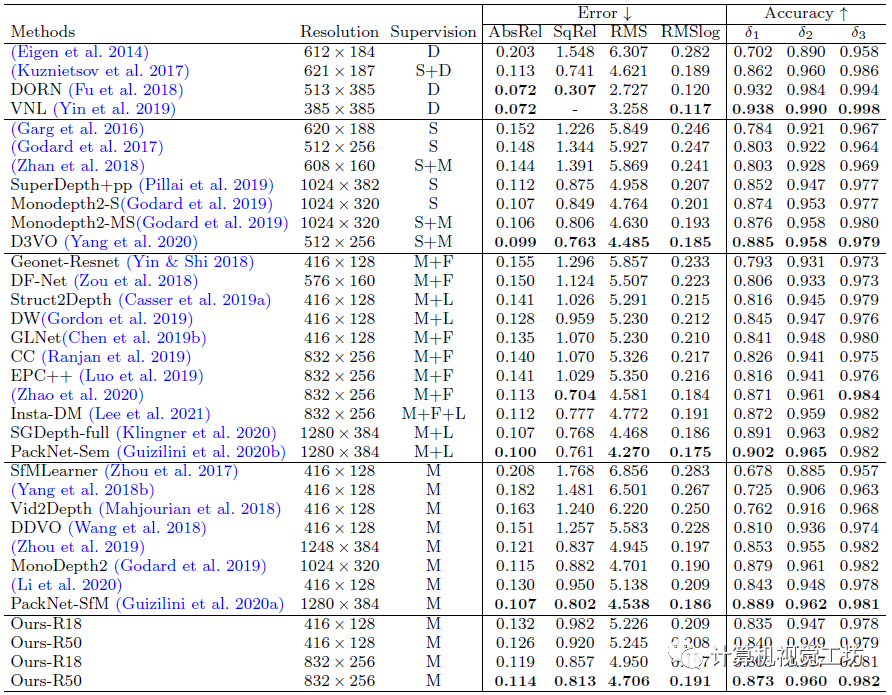
值得一提的是,SC-DepthV1在論文里除了介紹自己的定量結(jié)果外,還將單目深度估計(jì)結(jié)果引入到了ORB-SLAM2中,構(gòu)建了一個(gè)偽RGB-D SLAM系統(tǒng)。在一些序列中,Monodepth2+ORB-SLAM2的系統(tǒng)由于深度不連續(xù)問題,很快跟丟。而SC-DepthV1+ORB-SLAM2的組合可以獲得較好的跟蹤結(jié)果。
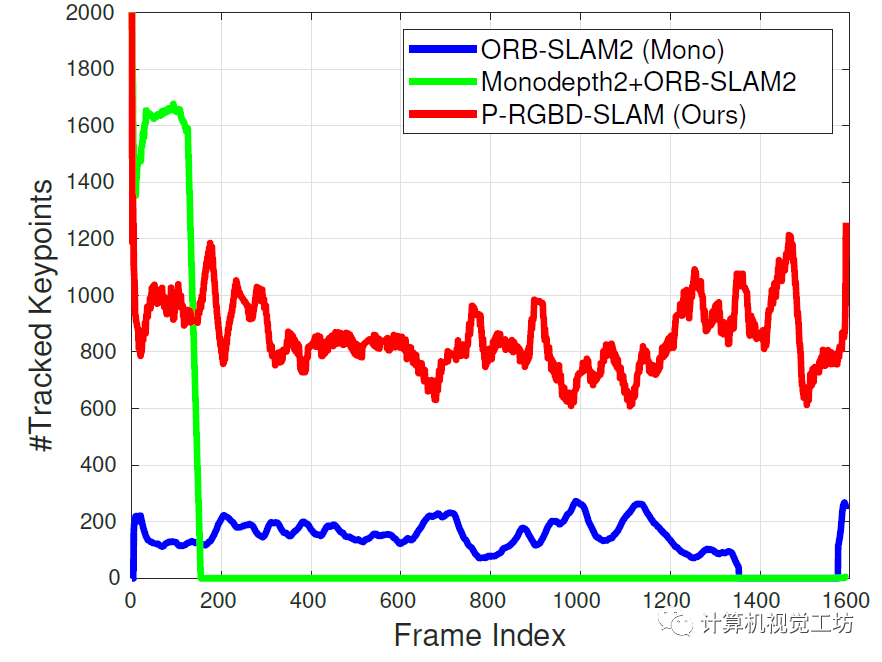
一句話總結(jié):SC-DepthV1解決了深度連續(xù)性問題。
3. SC-DepthV2做了什么?
之前的SC-DepthV1和MonoDepth2等網(wǎng)絡(luò)主要針對(duì)KITTI等室外場(chǎng)景,取得了非常不錯(cuò)的效果。但SC-Depth系列的作者發(fā)現(xiàn),這些網(wǎng)絡(luò)很難泛化到室內(nèi)場(chǎng)景中,室內(nèi)估計(jì)出的深度圖很差。這就很奇怪了,按理說只要經(jīng)過足夠的訓(xùn)練,室內(nèi)和室外場(chǎng)景應(yīng)該是可以取得相似的精度的。
這是為什么呢?
有一些學(xué)者認(rèn)為,這是因?yàn)槭覂?nèi)場(chǎng)景中有大量的弱紋理區(qū)域,比如白墻。這些區(qū)域很難去提取特征,就更不用說去做特征匹配,是這些弱紋理區(qū)域?qū)е律疃裙烙?jì)不準(zhǔn)。看似有一定道理,但要知道室外場(chǎng)景中的天空也是弱紋理區(qū)域啊,并且也占了圖像中的很大一部分。
為什么同樣是存在大量弱紋理場(chǎng)景,性能卻差了那么多呢? SC-Depth系列的作者認(rèn)為,室外場(chǎng)景中的相機(jī)運(yùn)動(dòng)主要是平移,旋轉(zhuǎn)所占的比重很小,而室內(nèi)場(chǎng)景正好相反。那么是不是室內(nèi)場(chǎng)景中的旋轉(zhuǎn)分量,對(duì)單目深度估計(jì)結(jié)果造成了影響呢? SC-Depth系列的作者對(duì)此進(jìn)行了嚴(yán)密的數(shù)學(xué)推導(dǎo):

這個(gè)數(shù)學(xué)推導(dǎo)很有意思。SC-Depth系列作者發(fā)現(xiàn)旋轉(zhuǎn)運(yùn)動(dòng)和深度估計(jì)結(jié)果完全無關(guān)!但平移運(yùn)動(dòng)和深度估計(jì)結(jié)果卻是相關(guān)的!
這個(gè)結(jié)論是什么意思呢?
也就是說,對(duì)于旋轉(zhuǎn)運(yùn)動(dòng)來說,就算估計(jì)的很準(zhǔn)也不會(huì)幫助單目深度估計(jì)結(jié)果,但如果估計(jì)的不準(zhǔn)就會(huì)給深度估計(jì)帶來大量噪聲。而對(duì)于平移運(yùn)動(dòng)來說,如果估計(jì)的位姿準(zhǔn)確是可以輔助單目深度估計(jì)結(jié)果的。 因此,SC-depthV2提出了位姿自修正網(wǎng)絡(luò),這個(gè)網(wǎng)絡(luò)只估計(jì)旋轉(zhuǎn)運(yùn)動(dòng),并借此剔除場(chǎng)景中的旋轉(zhuǎn)運(yùn)動(dòng)。
之后將第二幀圖像旋轉(zhuǎn)到第一張圖,這樣兩幀圖像之間的位姿就只剩下的平移運(yùn)動(dòng)。自此,自監(jiān)督深度估計(jì)網(wǎng)絡(luò)就可以得到很好的訓(xùn)練。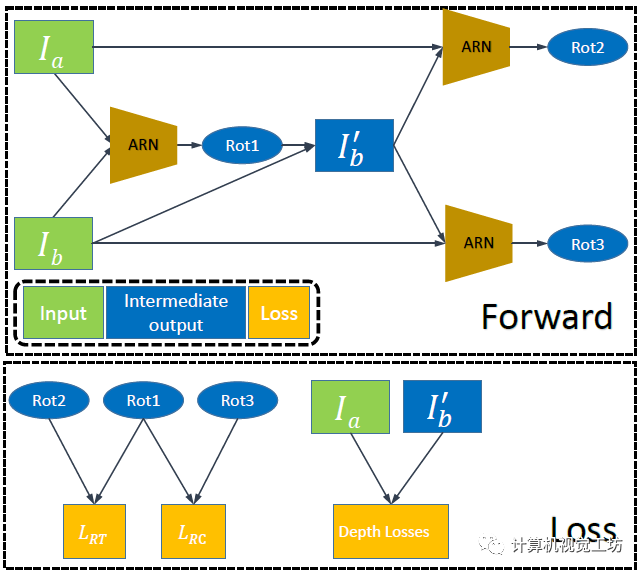
此外,SC-depthV2還提出了兩個(gè)新的損失約束。這里具體解釋一下:前面我們知道,Ia和Ib通過ARN生成了去除旋轉(zhuǎn)運(yùn)動(dòng)的圖像,理論上此時(shí)Ia和Ib’之間應(yīng)該是不包含任何旋轉(zhuǎn)的。
也就是說Ia和Ib’再進(jìn)行一次ARN得到的Rot2應(yīng)該為0。此外,Ib’和Ib再進(jìn)行一次ARN得到的Rot3應(yīng)該和第一次得到的Rot1是相等的。通過這兩個(gè)約束可以完全剔除兩幀之間的旋轉(zhuǎn)運(yùn)動(dòng),得到更好的位姿估計(jì)結(jié)果。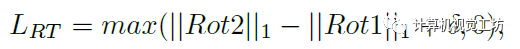
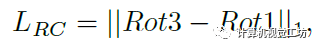
至于定量結(jié)果,由于作者主要思路就是針對(duì)室內(nèi)場(chǎng)景中的旋轉(zhuǎn)運(yùn)動(dòng),因此主要評(píng)估的數(shù)據(jù)集是室內(nèi)NYU。
結(jié)果顯示,SC-depthV2相較于之前的方法實(shí)現(xiàn)了大幅提升,這也驗(yàn)證了作者的想法。
一句話總結(jié):SC-DepthV2解決了旋轉(zhuǎn)位姿對(duì)深度估計(jì)的影響問題。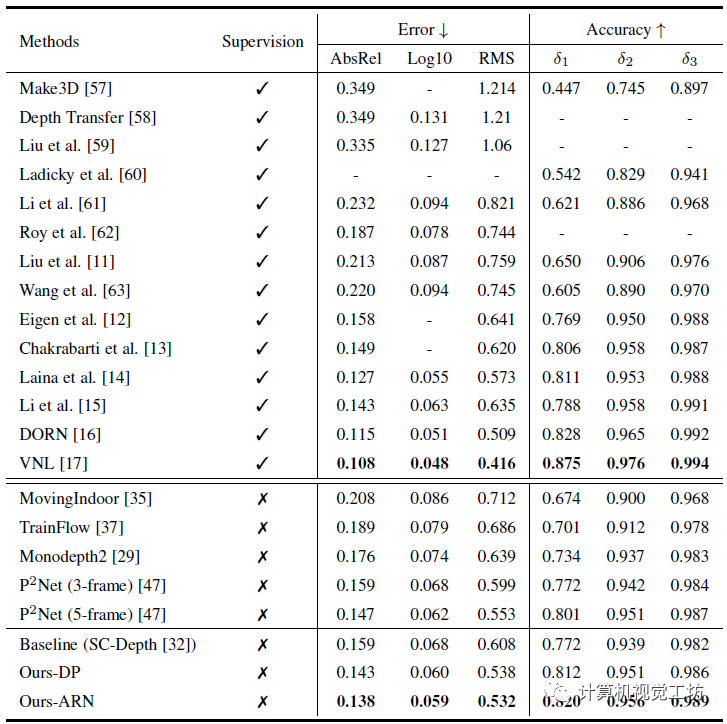
4. SC-DepthV3做了什么?
至此,其實(shí)SC-Depth系列已經(jīng)做的很好了。SC-DepthV1面向室外場(chǎng)景,SC-DepthV2面向室內(nèi)場(chǎng)景,可以說實(shí)現(xiàn)了很好的通用性和泛化能力。但SC-DepthV1和SC-DepthV2都是基于靜態(tài)環(huán)境假設(shè)的,雖然作者也利用Mask剔除了一些動(dòng)態(tài)物體的影響,但當(dāng)應(yīng)用場(chǎng)景是高動(dòng)態(tài)環(huán)境時(shí),算法很容易崩潰。
為了解決動(dòng)態(tài)物體和遮擋問題,現(xiàn)有網(wǎng)絡(luò)通常是檢測(cè)動(dòng)態(tài)物體,然后在訓(xùn)練時(shí)剔除這些區(qū)域。這些方法在訓(xùn)練時(shí)效果比較好,但是在推理時(shí)往往很難得到高精度。也有一些方法對(duì)每個(gè)動(dòng)態(tài)對(duì)象進(jìn)行建模,但網(wǎng)絡(luò)會(huì)變得非常笨重。 因此,SC-Depth系列作者又在近日提出了SC-DepthV3,面向高動(dòng)態(tài)場(chǎng)景的單目深度估計(jì)網(wǎng)絡(luò)!
在各種動(dòng)態(tài)場(chǎng)景中都可以魯棒的運(yùn)行! 具體來說,SC-DepthV3首先引入了一個(gè)在大規(guī)模數(shù)據(jù)集上有監(jiān)督預(yù)訓(xùn)練的單目深度估計(jì)模型LeReS,并通過零樣本泛化提供單圖像深度先驗(yàn),也就是偽深度,同時(shí)引入了一個(gè)新?lián)p失來約束網(wǎng)絡(luò)的訓(xùn)練。
注意,LeReS只需要訓(xùn)練一次,在新場(chǎng)景中不需要進(jìn)行finetune,因此這一網(wǎng)絡(luò)的引入并不會(huì)加入額外的成本。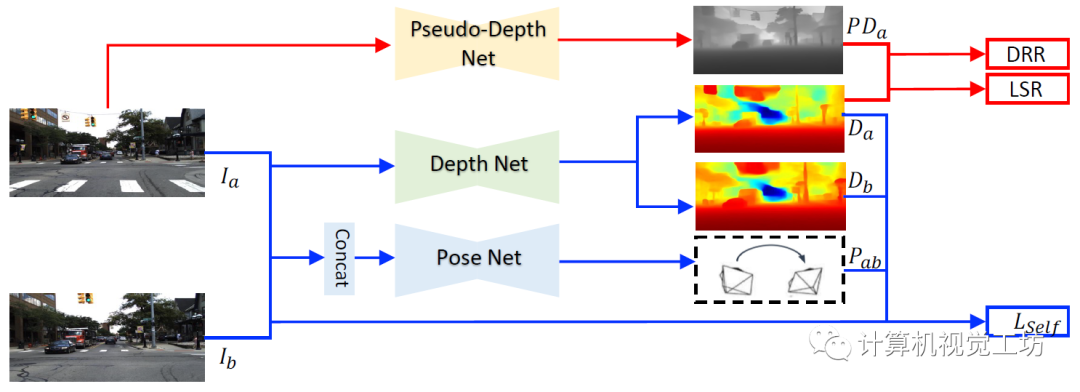
LeReS顯示了很好的定性結(jié)果,但偽深度的精度很低,偽深度的誤差圖也說明了這一問題。不過SC-DepthV3認(rèn)為經(jīng)過合適的模塊設(shè)計(jì),偽深度可以很好得促進(jìn)無監(jiān)督單目深度估計(jì)的結(jié)果。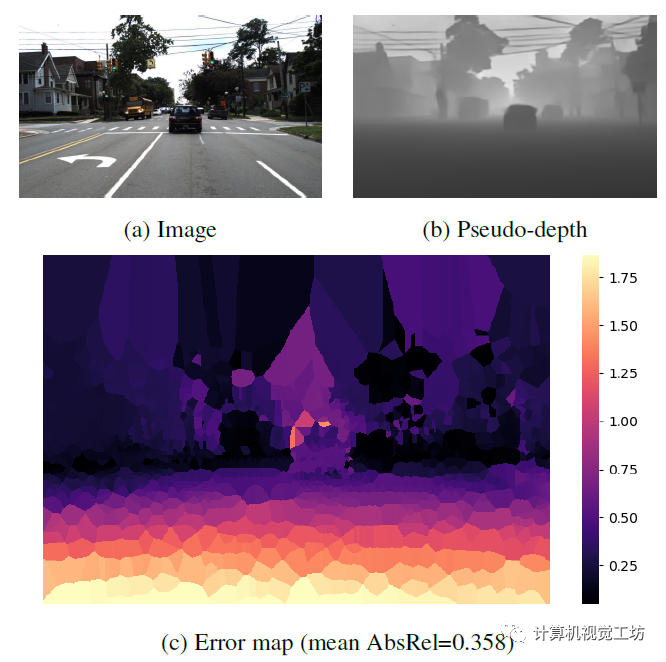
解決動(dòng)態(tài)區(qū)域問題的關(guān)鍵是作者提出的動(dòng)態(tài)區(qū)域細(xì)化(DRR)模塊,該方法的來源是,作者發(fā)現(xiàn)偽深度在任意兩個(gè)物體或像素之間保持極好的深度有序度。
因此,SC-DepthV3提取動(dòng)態(tài)和靜態(tài)區(qū)域之間的真值深度序信息,并使用它來規(guī)范動(dòng)態(tài)區(qū)域的自監(jiān)督深度估計(jì)。
為了從靜態(tài)背景中分割動(dòng)態(tài)區(qū)域,SC-DepthV3使用了SC-DepthV1中提出的Mask,并通過計(jì)算自監(jiān)督訓(xùn)練中的前后向深度不一致性來生成,因此不需要外部分割網(wǎng)絡(luò)。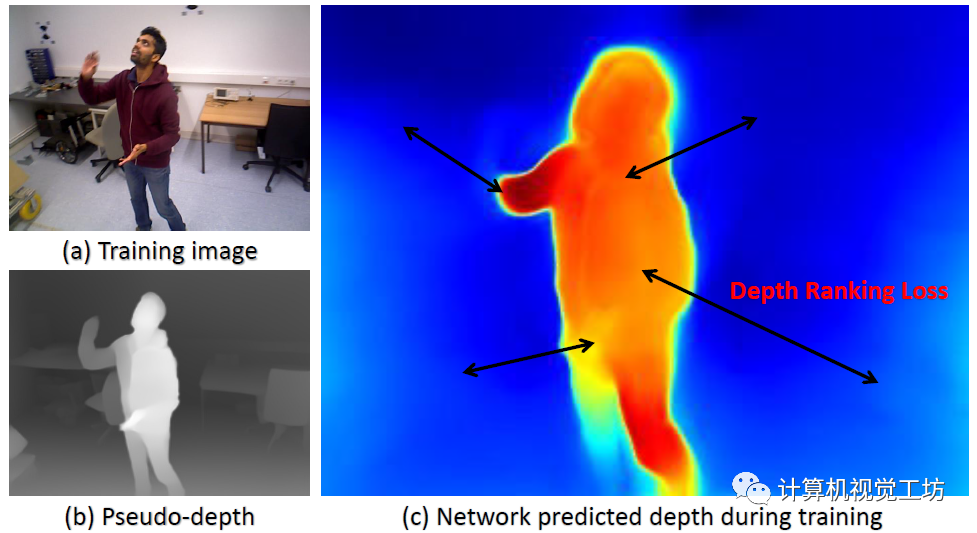
此外,偽深度顯示了光滑的局部結(jié)構(gòu)和物體邊界。因此SC-DepthV3提出一個(gè)局部結(jié)構(gòu)優(yōu)化(LSR)模塊來改進(jìn)深度細(xì)節(jié)的自監(jiān)督深度估計(jì)。該模塊包含兩個(gè)部分:一方面從偽深度和網(wǎng)絡(luò)預(yù)測(cè)深度中提取表面法線,并通過應(yīng)用法線匹配損失來約束;另一方面應(yīng)用相對(duì)法向角度損失來約束物體邊界區(qū)域的深度估計(jì)。
在損失函數(shù)的設(shè)置上,除了之前的幾何一致性損失、光度損失外,SC-DepthV3還提出了邊緣感知平滑損失來正則化預(yù)測(cè)的深度圖。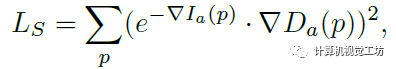
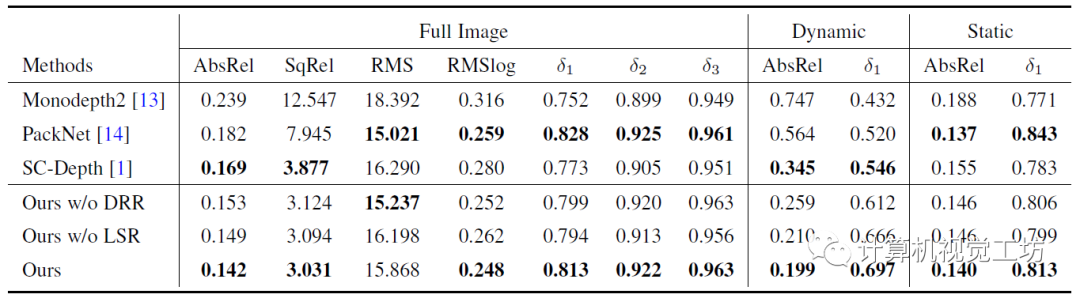
在具體的評(píng)估上,SC-DepthV3在DDAD、BONN、TUM、KITTI、NYUv2和IBims-1這六個(gè)數(shù)據(jù)集進(jìn)行了大量實(shí)驗(yàn),定性結(jié)果顯示SC-DepthV3在動(dòng)態(tài)環(huán)境中具有極強(qiáng)的魯棒性。
定量結(jié)果也說明了SC-DepthV3在動(dòng)態(tài)環(huán)境中的性能遠(yuǎn)超Monodepth2和SC-Depth。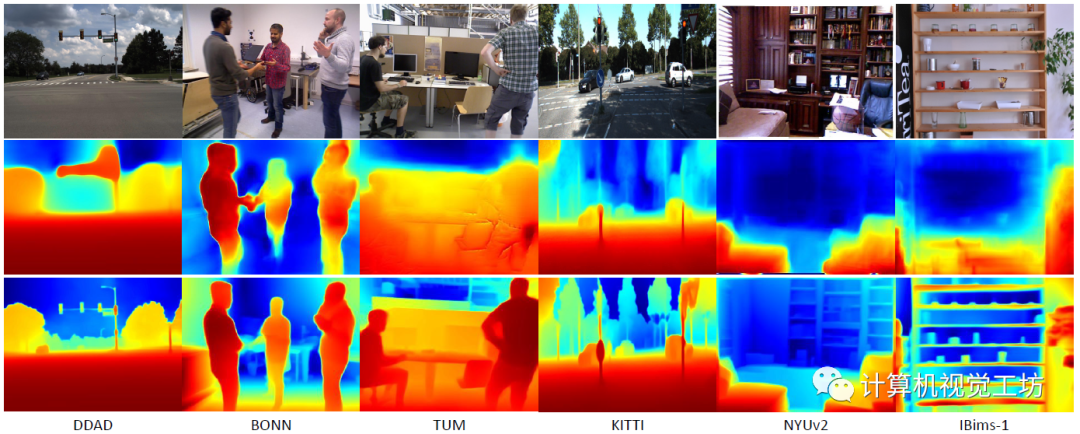
一句話總結(jié):SC-DepthV3解決了動(dòng)態(tài)環(huán)境問題。
5. 總結(jié)
SC-Depth系列是非常經(jīng)典且先進(jìn)的無監(jiān)督單目深度估計(jì)網(wǎng)絡(luò),現(xiàn)在已經(jīng)有了V1、V2、V3三個(gè)版本。其中SC-DepthV1主要解決深度圖不連續(xù)的問題,SC-DepthV2主要解決室內(nèi)環(huán)境中旋轉(zhuǎn)位姿對(duì)深度估計(jì)產(chǎn)生噪聲的問題,SC-DepthV3主要解決動(dòng)態(tài)環(huán)境中的單目深度估計(jì)問題。可以說這三個(gè)網(wǎng)絡(luò)已經(jīng)可以應(yīng)用于大多數(shù)的場(chǎng)景,這樣在一個(gè)方向不斷深耕的團(tuán)隊(duì)并不多見。研究單目深度估計(jì)網(wǎng)絡(luò)的讀者一定不要錯(cuò)過。
審核編輯:劉清
-
傳感器
+關(guān)注
關(guān)注
2548文章
50709瀏覽量
752089 -
激光雷達(dá)
+關(guān)注
關(guān)注
967文章
3943瀏覽量
189613 -
VSLAM
+關(guān)注
關(guān)注
0文章
23瀏覽量
4312
原文標(biāo)題:SC-DepthV3來了!深度解析無監(jiān)督單目深度估計(jì)V1到V3的主要變化
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
原理圖中所有的gnd地 網(wǎng)絡(luò)名稱都變?yōu)閜rogb了
LabVIEW中圖像濾波Vi以及實(shí)現(xiàn)效果如何實(shí)現(xiàn)
人臉識(shí)別、語(yǔ)音翻譯、無人駕駛...這些高科技都離不開深度神經(jīng)網(wǎng)絡(luò)了!
分享一款不錯(cuò)的基于TCP/IP網(wǎng)絡(luò)協(xié)議設(shè)計(jì)并實(shí)現(xiàn)了浮標(biāo)網(wǎng)絡(luò)通信系統(tǒng)
在STM32F407上實(shí)現(xiàn)了直播聲卡
TEE解決了什么問題?
WS2811 led strip添加了analogWrite來控制板載LED的亮度,效果都失真了怎么解決?
js實(shí)現(xiàn)無縫跑馬燈效果(圖片輪播滾動(dòng)跑馬燈效果)
15個(gè)科技預(yù)言竟然都實(shí)現(xiàn)了
SK電訊成功實(shí)現(xiàn)了1.2Gbps的LTE網(wǎng)絡(luò)服務(wù)
光網(wǎng)絡(luò)(SDON)標(biāo)準(zhǔn)進(jìn)展的怎樣了
使用Matlab實(shí)現(xiàn)了一個(gè)通用無源網(wǎng)絡(luò)仿真引擎
CDN解決了什么問題





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論