 港大&騰訊提出DiffusionDet:第一個用于目標檢測的擴散模型
港大&騰訊提出DiffusionDet:第一個用于目標檢測的擴散模型
擴散模型不但在生成任務上非常成功,這次在目標檢測任務上,更是超越了成熟的目標檢測器。
擴散模型( Diffusion Model )作為深度生成模型中的新 SOTA,已然在圖像生成任務中超越了原 SOTA:例如 GAN,并且在諸多應用領域都有出色的表現,如計算機視覺,NLP、分子圖建模、時間序列建模等。
近日,來自香港大學的羅平團隊、騰訊 AI Lab 的研究者聯合提出一種新框架 DiffusionDet,將擴散模型應用于目標檢測。據了解,還沒有研究可以成功地將擴散模型應用于目標檢測,可以說這是第一個采用擴散模型進行目標檢測的工作。
DiffusionDet 的性能如何呢?在 MS-COCO 數據集上進行評估,使用 ResNet-50 作為骨干,在單一采樣 step 下,DiffusionDet 實現 45.5 AP,顯著優于 Faster R-CNN (40.2 AP), DETR (42.0 AP),并與 Sparse R-CNN (45.0 AP)相當。通過增加采樣 step 的數量,進一步將 DiffusionDet 性能提高到 46.2 AP。此外,在 LVIS 數據集上,DiffusionDet 也表現良好,使用 swin - base 作為骨干實現了 42.1 AP。

DiffusionDet: Diffusion Model for Object Detection
論文地址:https://arxiv.org/abs/2211.09788
項目地址(剛剛開源):
https://github.com/ShoufaChen/DiffusionDet
該研究發現在傳統的目標檢測里,存在一個缺陷,即它們依賴于一組固定的可學習查詢。然后研究者就在思考:是否存在一種簡單的方法甚至不需要可學習查詢就能進行目標檢測?
為了回答這一問題,本文提出了 DiffusionDet,該框架可以直接從一組隨機框中檢測目標,它將目標檢測制定為從噪聲框到目標框的去噪擴散過程。這種從 noise-to-box 的方法不需要啟發式的目標先驗,也不需要可學習查詢,這進一步簡化了目標候選,并推動了檢測 pipeline 的發展。
如下圖 1 所示,該研究認為 noise-to-box 范式類似于去噪擴散模型中的 noise-to-image 過程,后者是一類基于似然的模型,通過學習到的去噪模型逐步去除圖像中的噪聲來生成圖像。
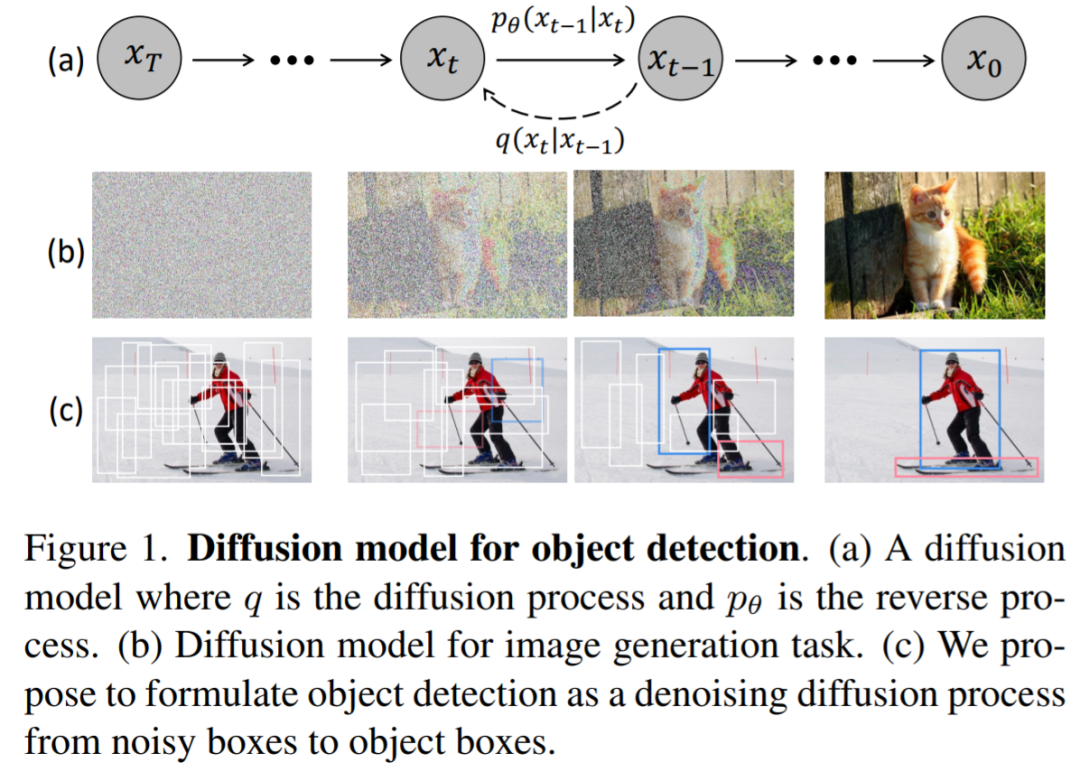
DiffusionDet 通過擴散模型解決目標檢測任務,即將檢測看作圖像中 bounding box 位置 (中心坐標) 和大小 (寬度和高度) 空間上的生成任務。在訓練階段,將方差表(schedule)控制的高斯噪聲添加到 ground truth box,得到 noisy box。然后使用這些 noisy box 從主干編碼器(如 ResNet, Swin Transformer)的輸出特征圖中裁剪感興趣區域(RoI)。最后,將這些 RoI 特征發送到檢測解碼器,該解碼器被訓練用來預測沒有噪聲的 ground truth box。在推理階段,DiffusionDet 通過反轉學習到的擴散過程生成 bounding box,它將噪聲先驗分布調整到 bounding box 上的學習分布。
方法概述
由于擴散模型迭代地生成數據樣本,因此在推理階段需要多次運行模型 f_θ。但是,在每一個迭代步驟中,直接在原始圖像上應用 f_θ在計算上很困難。因此,研究者提出將整個模型分為兩部分,即圖像編碼器和檢測解碼器,前者只運行一次以從原始輸入圖像 x 中提取深度特征表示,后者以該深度特征為條件,從噪聲框 z_t 中逐步細化框預測。
圖像編碼器將原始圖像作為輸入,并為檢測解碼器提取其高級特征。研究者使用 ResNet 等卷積神經網絡和 Swin 等基于 Transformer 的模型來實現 DiffusionDet。與此同時,特征金字塔網絡用于為 ResNet 和 Swin 主干網絡生成多尺度特征圖。
檢測解碼器借鑒了 Sparse R-CNN,將一組 proposal 框作為輸入,從圖像編碼器生成的特征圖中裁剪 RoI 特征,并將它們發送到檢測頭以獲得框回歸和分類結果。此外,該檢測解碼器由 6 個級聯階段組成。
訓練
在訓練過程中,研究者首先構建了從真值框到噪聲框的擴散過程,然后訓練模型來反轉這個過程。如下算法 1 提供了 DiffusionDet 訓練過程的偽代碼。
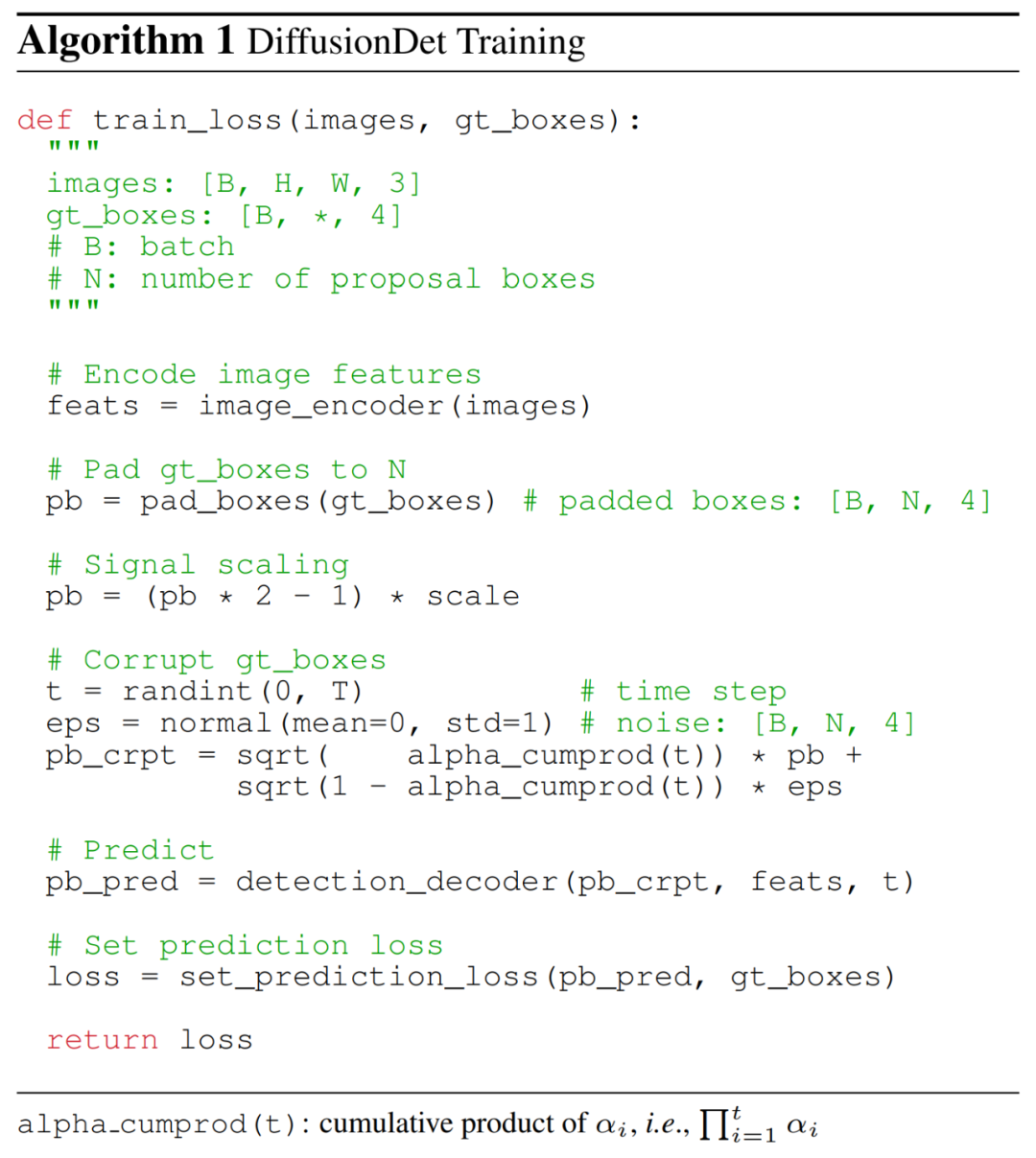
真值框填充。對于現代目標檢測基準,感興趣實例的數量通常因圖像而異。因此,研究者首先將一些額外的框填充到原始真值框,這樣所有的框被總計為一個固定的數字 N_train。他們探索了幾種填充策略,例如重復現有真值框、連接隨機框或圖像大小的框。
框損壞。研究者將高斯噪聲添加到填充的真值框。噪聲尺度由如下公式(1)中的 α_t 控制,它在不同的時間步 t 中采用單調遞減的余弦調度。
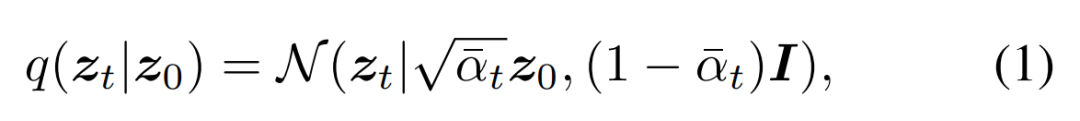
訓練損失。檢測解碼器將 N_train 損壞框作為輸入,預測 N_train 對類別分類和框坐標的預測。同時在 N_train 預測集上應用集預測損失(set prediction loss)。
推理
DiffusionDet 的推理過程是從噪聲到目標框的去噪采樣過程。從在高斯分布中采樣的框開始,該模型逐步細化其預測,具體如下算法 2 所示。
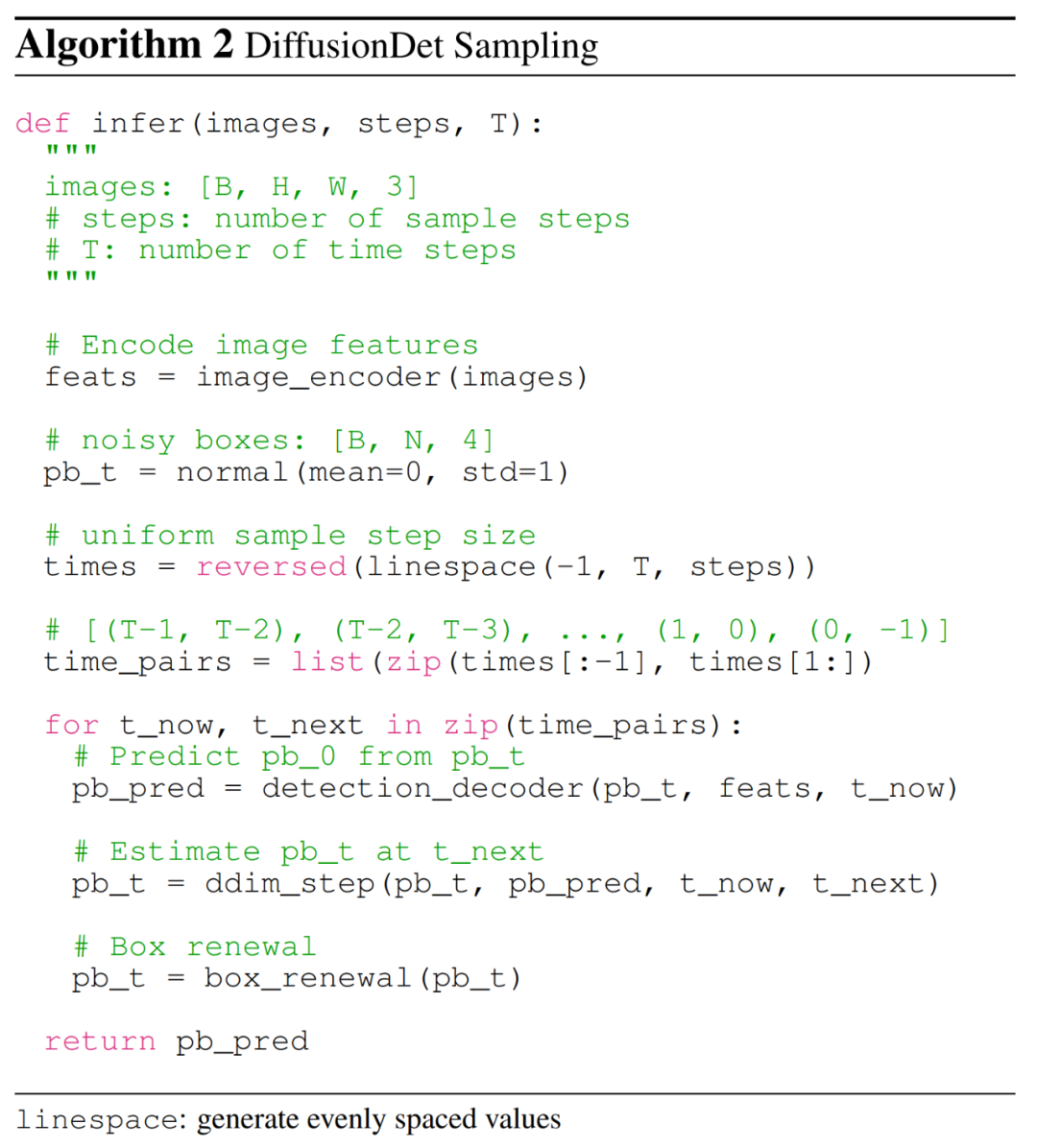
采樣步驟。在每個采樣步驟中,將上一個采樣步驟中的隨機框或估計框發送到檢測解碼器,以預測類別分類和框坐標。在獲得當前步驟的框后,采用 DDIM 來估計下一步驟的框。
框更新。為了使推理更好地與訓練保持一致,研究者提出了框更新策略,通過用隨機框替換非預期的框以使它們恢復。具體來說,他們首先過濾掉分數低于特定閾值的非預期的框,然后將剩余的框與從高斯分布中采樣的新隨機框連接起來。
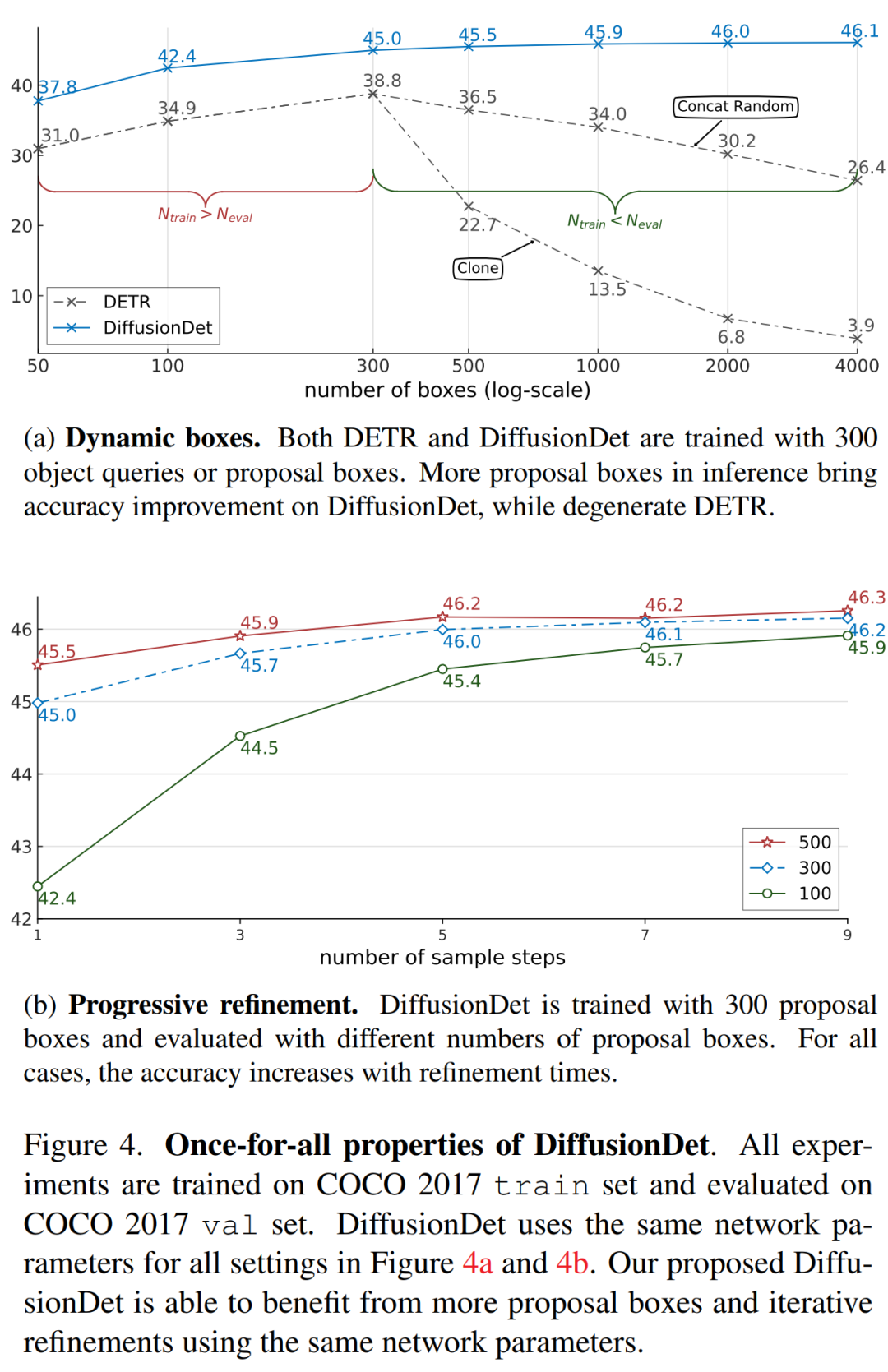
一次解決(Once-for-all)。得益于隨機框設計,研究者可以使用任意數量的隨機框和采樣步驟來評估 DiffusionDet。作為比較,以往的方法在訓練和評估期間依賴于相同數量的處理框,并且檢測解碼器在前向傳遞中僅使用一次。
實驗結果
在實驗部分,研究者首先展示了 DiffusionDet 的 Once-for-all 屬性,然后將 DiffusionDet 與以往在 MS-COCO 和 LVIS 數據集上成熟的檢測器進行比較。
DiffusionDet 的主要特性在于對所有推理實例進行一次訓練。一旦模型經過訓練,它就可以用于更改推理中框的數量和樣本步驟數,如下圖 4 所示。DiffusionDet 可以通過使用更多框或 / 和更多細化步驟來實現更高的準確度,但代價是延遲率更高。因此,研究者將單個 DiffusionDet 部署到多個場景中,并在不重新訓練網絡的情況下獲得所需的速度 - 準確率權衡。
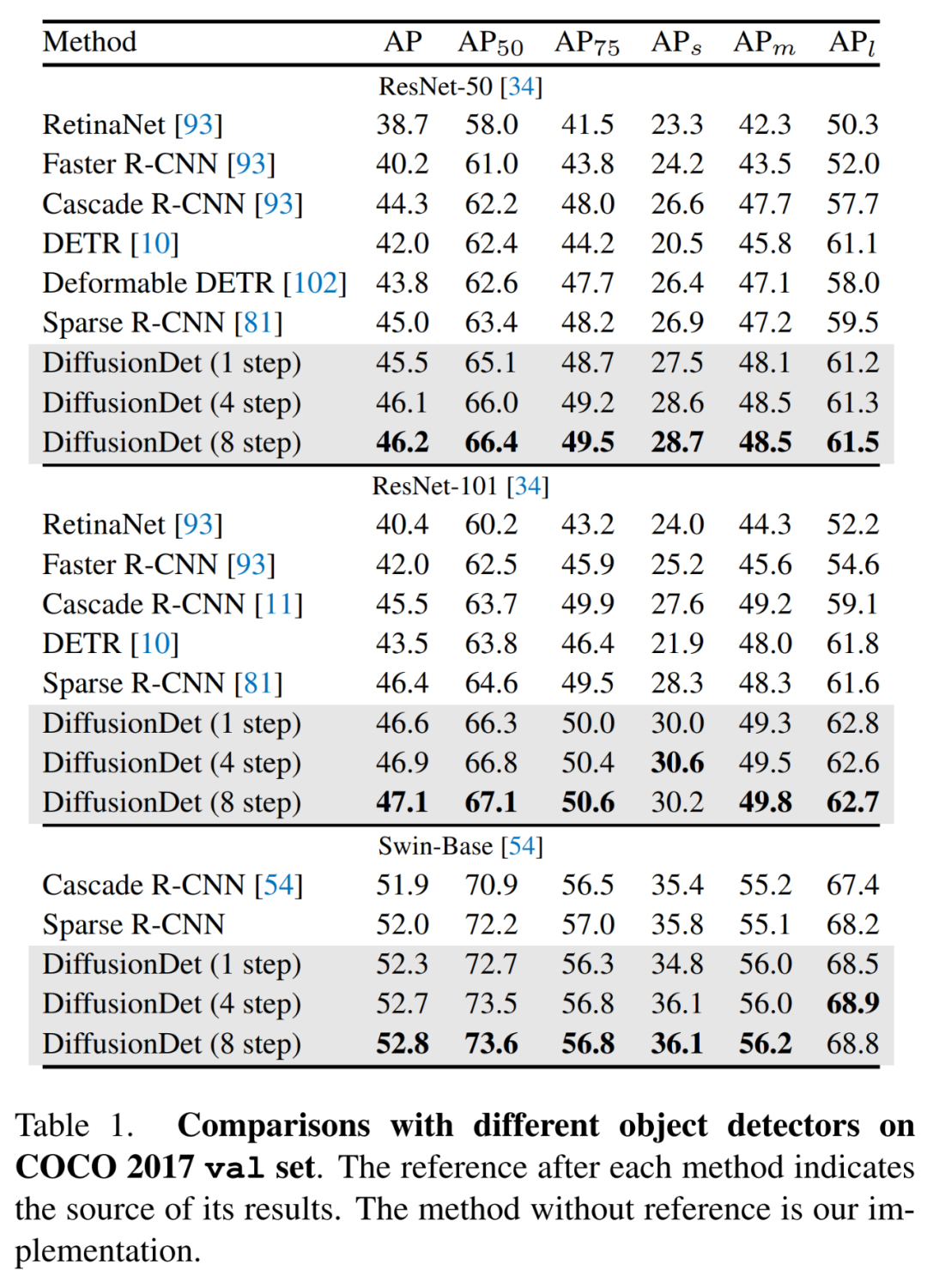
研究者將 DiffusionDet 與以往在 MS-COCO 和 LVIS 數據集上的檢測器進行了比較,具體如下表 1 所示。他們首先將 DiffusionDet 的目標檢測性能與以往在 MS-COCO 上的檢測器進行了比較。結果顯示,沒有細化步驟的 DiffusionDet 使用 ResNet-50 主干網絡實現了 45.5 AP,以較大的優勢超越了以往成熟的方法,如 Faster R-CNN、RetinaNet、DETR 和 Sparse R-CNN。并且當主干網絡的尺寸擴大時,DiffusionDet 顯示出穩定的提升。
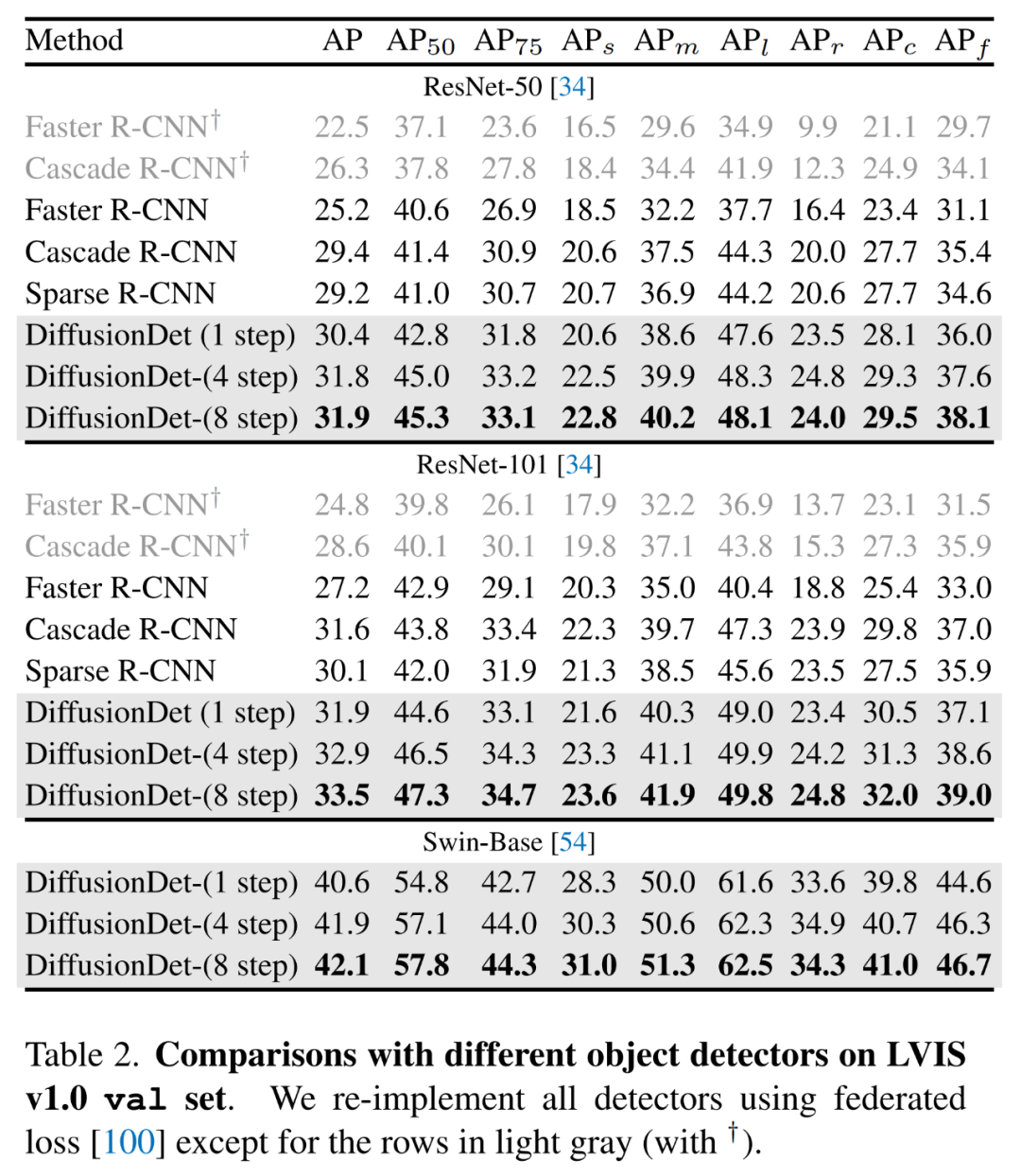
下表 2 中展示了在更具挑戰性的 LVIS 數據集上的結果,可以看到,DiffusionDet 使用更多的細化步驟可以獲得顯著的增益。
審核編輯 :李倩
-
目標檢測
+關注
關注
0文章
205瀏覽量
15590 -
計算機視覺
+關注
關注
8文章
1696瀏覽量
45930 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:港大&騰訊提出DiffusionDet:第一個用于目標檢測的擴散模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
浙大、微信提出精確反演采樣器新范式,徹底解決擴散模型反演問題

北美運營商AT&amp;amp;T認證的測試內容有哪些?


北美運營商AT&amp;amp;T認證的費用受哪些因素影響

onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用

FS201資料(pcb &amp; DEMO &amp; 原理圖)
北美運營商AT&amp;amp;T認證入庫產品范圍名單相關

解讀北美運營商,AT&amp;amp;T的認證分類與認證內容分享
在TSMaster中加載基于DotNet平臺的Seed&amp;amp;Key

Open RAN的未來及其對AT&amp;T的意義
百度開源DETRs在實時目標檢測中勝過YOLOs
Harvard FairSeg:第一個用于醫學分割的公平性數據集

基于DiAD擴散模型的多類異常檢測工作

開關模式下的電源電流如何檢測?這12個電路&amp;10個知識點講明白了
IGBT的物理結構模型—BJT&amp;MOS模型(1)





 工商網監
工商網監
評論