") 一起來看看RDMA讓網(wǎng)絡(luò)實現(xiàn)低時延的絕招
一起來看看RDMA讓網(wǎng)絡(luò)實現(xiàn)低時延的絕招
眾所周知,互聯(lián)網(wǎng)數(shù)據(jù)的爆炸式增長,給數(shù)據(jù)中心的處理能力帶來了很大的挑戰(zhàn)。
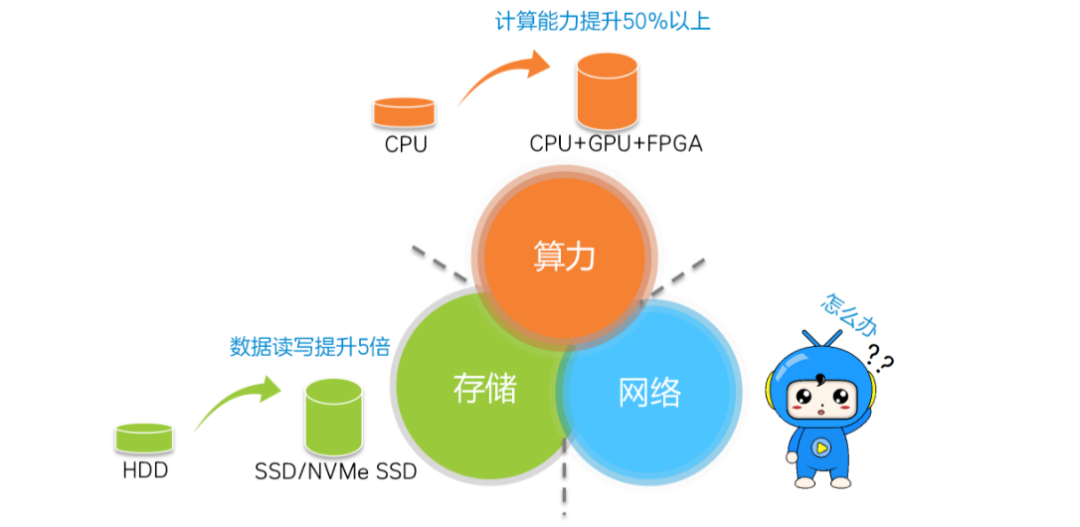
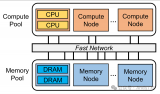
計算、存儲和網(wǎng)絡(luò),是推動數(shù)據(jù)中心發(fā)展的三駕馬車。
計算隨著CPU、GPU和FPGA的發(fā)展,算力得到了極大的提升。存儲隨著閃存盤(SSD)的引入,數(shù)據(jù)存取時延已大幅降低。
但是,網(wǎng)絡(luò)的發(fā)展明顯滯后,傳輸時延高,逐漸成為了數(shù)據(jù)中心高性能的瓶頸。
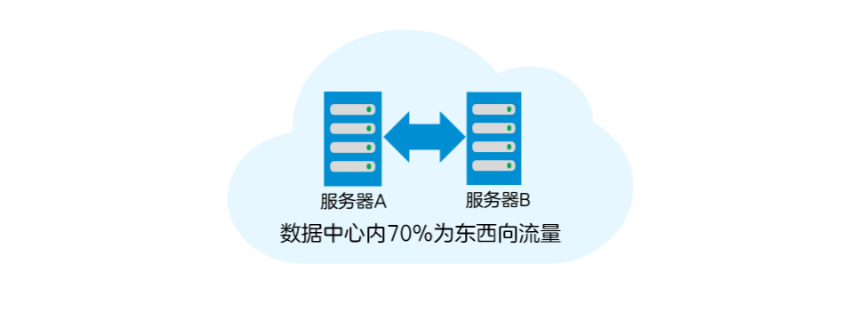
在數(shù)據(jù)中心內(nèi),70%的流量為東西向流量(服務(wù)器之間的流量)。這些流量,一般為數(shù)據(jù)中心進(jìn)行高性能分布式并行計算時的過程數(shù)據(jù)流,通過TCP/IP網(wǎng)絡(luò)傳輸。
如果服務(wù)器之間的TCP/IP傳輸速率提升了,數(shù)據(jù)中心的性能自然也會跟著提升。
下面,我們就來看看服務(wù)器之間數(shù)據(jù)TCP/IP傳輸?shù)倪^程,了解一下“時間都去哪了”,才好“對癥下藥”。
服務(wù)器間的TCP/IP傳輸
在數(shù)據(jù)中心,服務(wù)器A向服務(wù)器B發(fā)送數(shù)據(jù)的過程如下: 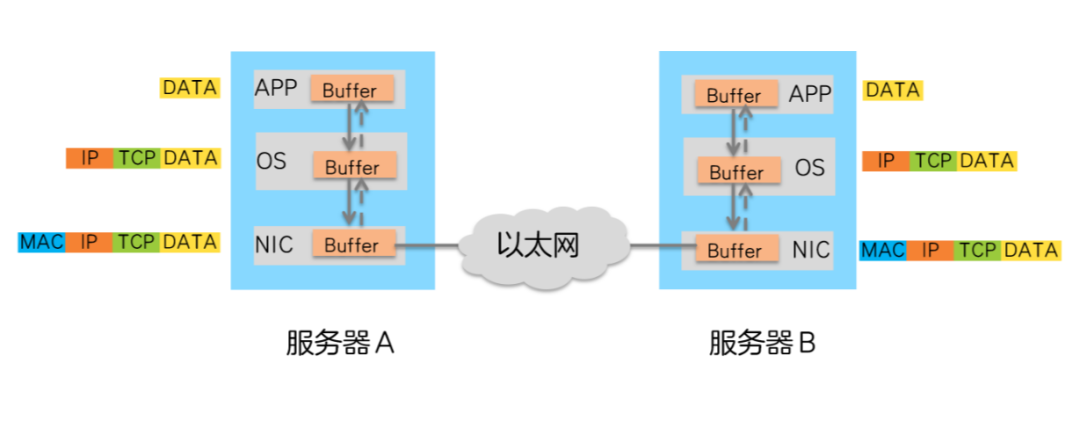
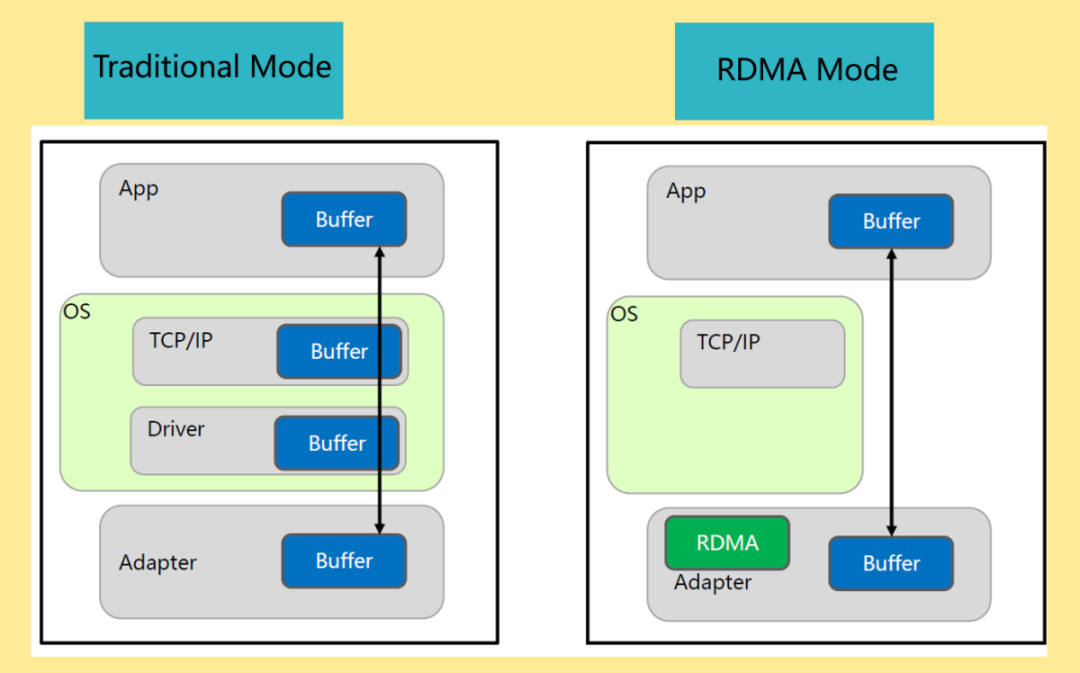
1、CPU控制數(shù)據(jù)由A的APP Buffer拷貝到操作系統(tǒng)Buffer。
2、CPU控制數(shù)據(jù)在操作系統(tǒng)(OS)Buffer中添加TCP、IP報文頭。
3、添加TCP、IP報文頭后的數(shù)據(jù)傳送到網(wǎng)卡(NIC),添加以太網(wǎng)報文頭。
4、報文由網(wǎng)卡發(fā)送,通過以太網(wǎng)絡(luò)傳輸?shù)椒?wù)器B網(wǎng)卡。
5、服務(wù)器B網(wǎng)卡卸載報文的以太網(wǎng)報文頭后,將其傳輸?shù)讲僮飨到y(tǒng)Buffer。
6、CPU控制操作系統(tǒng)Buffer中的報文卸載TCP、IP報文頭。
7、CPU控制卸載后的數(shù)據(jù)傳輸?shù)紸PP Buffer中。
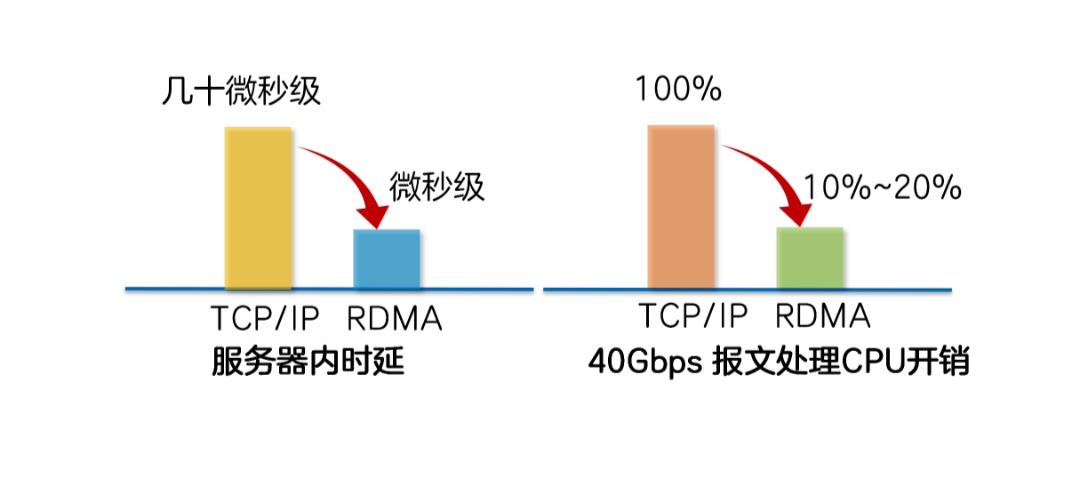
從數(shù)據(jù)傳輸?shù)倪^程可以看出,數(shù)據(jù)在服務(wù)器的Buffer內(nèi)多次拷貝,在操作系統(tǒng)中需要添加/卸載TCP、IP報文頭,這些操作既增加了數(shù)據(jù)傳輸時延,又消耗了大量的CPU資源,無法很好得滿足高性能計算的需求。
那么,如何構(gòu)造高吞吐量、超低時延和低CPU開銷的高性能數(shù)據(jù)中心網(wǎng)絡(luò)呢?
RDMA技術(shù)可以做到。
什么是RDMA
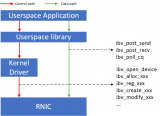
RDMA( Remote Direct Memory Access,遠(yuǎn)程直接地址訪問技術(shù) )是一種新的內(nèi)存訪問技術(shù),可以讓服務(wù)器直接高速讀寫其他服務(wù)器的內(nèi)存數(shù)據(jù),而不需要經(jīng)過操作系統(tǒng)/CPU耗時的處理。
RDMA不算是一項新技術(shù),已經(jīng)廣泛應(yīng)用于高性能(HPC)科學(xué)計算中。隨著數(shù)據(jù)中心高帶寬、低時延的發(fā)展需求,RDMA也開始逐漸應(yīng)用于某些要求數(shù)據(jù)中心具備高性能的場景中。
舉個例子,2021年某大型網(wǎng)上商城的雙十一交易額再創(chuàng)新高,達(dá)到5000多億,比2020年又增長了近10%。如此巨大的交易額背后是海量的數(shù)據(jù)處理,該網(wǎng)上商城采用了RDMA技術(shù)來支撐高性能網(wǎng)絡(luò),保障了雙十一的順暢購物。
下面我們一起來看看RDMA讓網(wǎng)絡(luò)實現(xiàn)低時延的絕招吧。
RDMA將服務(wù)器應(yīng)用數(shù)據(jù)直接由內(nèi)存?zhèn)鬏數(shù)?a href="http://www.nxhydt.com/v/" target="_blank">智能網(wǎng)卡(固化RDMA協(xié)議),由智能網(wǎng)卡硬件完成RDMA傳輸報文封裝,解放了操作系統(tǒng)和CPU。
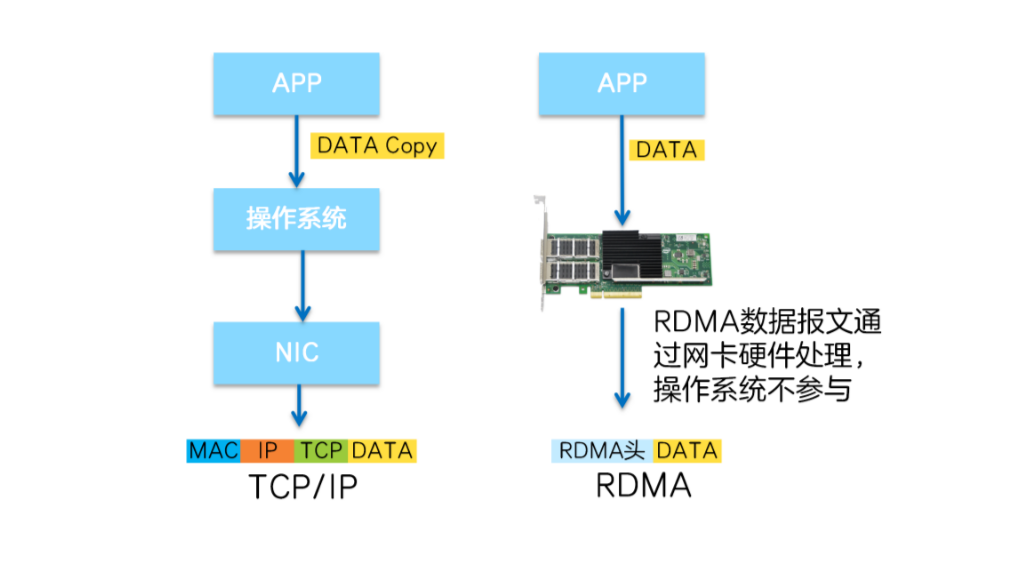
這使得RDMA具有兩大優(yōu)勢:
Zero Copy(零拷貝):無需將數(shù)據(jù)拷貝到操作系統(tǒng)內(nèi)核態(tài)并處理數(shù)據(jù)包頭部的過程,傳輸延遲會顯著減小。
Kernel Bypass(內(nèi)核旁路)和Protocol Offload(協(xié)議卸載):不需要操作系統(tǒng)內(nèi)核參與,數(shù)據(jù)通路中沒有繁瑣的處理報頭邏輯,不僅會使延遲降低,而且也大大節(jié)省了CPU的資源。
三大RDMA網(wǎng)絡(luò)
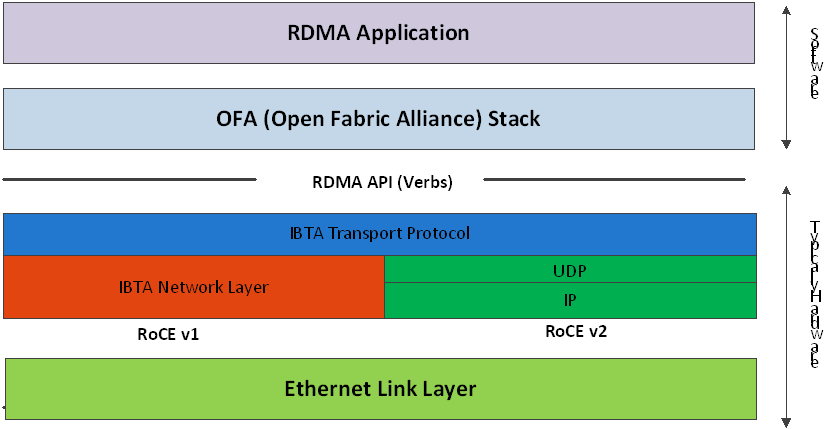
目前,大致有三類RDMA網(wǎng)絡(luò),分別是InfiniBand、RoCE(RDMA over Converged Ethernet,RDMA過融合以太網(wǎng))和iWARP(RDMAover TCP,互聯(lián)網(wǎng)廣域RDMA協(xié)議)。
RDMA最早專屬于Infiniband網(wǎng)絡(luò)架構(gòu),從硬件級別保證可靠傳輸,而RoCE和iWARP都是基于以太網(wǎng)的RDMA技術(shù)。
InfiniBand
InfiniBand是一種專為RDMA設(shè)計的網(wǎng)絡(luò)。
采用Cut-Through轉(zhuǎn)發(fā)模式(直通轉(zhuǎn)發(fā)模式),減少轉(zhuǎn)發(fā)時延。
基于Credit的流控機(jī)制(基于信用的流控機(jī)制),保證無丟包。
要求InfiniBand專用的網(wǎng)卡、交換機(jī)和路由器,建網(wǎng)成本最高。
RoCE
傳輸層為InfiniBand協(xié)議。
RoCE有兩個版本:RoCEv1基于以太網(wǎng)鏈路層實現(xiàn),只能在L2層傳輸;RoCEv2基于UDP承載RDMA,可部署于三層網(wǎng)絡(luò)。
需要支持RDMA專用智能網(wǎng)卡,不需要專用交換機(jī)和路由器(支持ECN/PFC等技術(shù),降低丟包率),建網(wǎng)成本最低。
iWARP
傳輸層為iWARP協(xié)議。
iWARP是以太網(wǎng)TCP/IP協(xié)議中TCP層實現(xiàn),支持L2/L3層傳輸,大型組網(wǎng)TCP連接會消耗大量CPU,所以應(yīng)用很少。
iWARP只要求網(wǎng)卡支持RDMA,不需要專用交換機(jī)和路由器,建網(wǎng)成本介于InfiniBand和RoCE之間。
Infiniband技術(shù)先進(jìn),但是價格高昂,應(yīng)用局限在HPC高性能計算領(lǐng)域,隨著RoCE和iWARPC的出現(xiàn),降低了RDMA的使用成本,推動了RDMA技術(shù)普及。
在高性能存儲、計算數(shù)據(jù)中心中采用這三類RDMA網(wǎng)絡(luò),都可以大幅度降低數(shù)據(jù)傳輸時延,并為應(yīng)用程序提供更高的CPU資源可用性。
其中,InfiniBand網(wǎng)絡(luò)為數(shù)據(jù)中心帶來極致的性能,傳輸時延低至百納秒,比以太網(wǎng)設(shè)備延時要低一個量級。
RoCE和iWARP網(wǎng)絡(luò)為數(shù)據(jù)中心帶來超高性價比,基于以太網(wǎng)承載RDMA,充分利用了RDMA的高性能和低CPU使用率等優(yōu)勢,同時網(wǎng)絡(luò)建設(shè)成本也不高。
基于UDP協(xié)議的RoCE比基于TCP協(xié)議的iWARP性能更好,結(jié)合無損以太網(wǎng)的流控技術(shù),解決了丟包敏感的問題。RoCE網(wǎng)絡(luò),已廣泛應(yīng)用于各行業(yè)高性能數(shù)據(jù)中心中。
結(jié)語
隨著5G、人工智能、工業(yè)互聯(lián)網(wǎng)等新型領(lǐng)域的發(fā)展,RDMA技術(shù)的應(yīng)用會越來越普及,RDMA將成為助力數(shù)據(jù)中心高性能的一大功臣。
審核編輯:劉清
-
服務(wù)器
+關(guān)注
關(guān)注
12文章
9028瀏覽量
85199 -
SSD
+關(guān)注
關(guān)注
20文章
2851瀏覽量
117240 -
HPC
+關(guān)注
關(guān)注
0文章
312瀏覽量
23688 -
TCP協(xié)議
+關(guān)注
關(guān)注
1文章
91瀏覽量
12063 -
RDMA
+關(guān)注
關(guān)注
0文章
76瀏覽量
8928
原文標(biāo)題:到底什么是RDMA?為什么數(shù)據(jù)中心需要它?
文章出處:【微信號:鮮棗課堂,微信公眾號:鮮棗課堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
測速電機(jī)的工作原理和種類與性能 目前見過最全的 一起來看看吧

RoCE與IB對比分析(一):協(xié)議棧層級篇
以太網(wǎng)RDMA RoCE的技術(shù)局限
請問tas5731m PBTL模式,單聲道輸出(AB連一起,CD連一起)如何實現(xiàn)左右聲道的混音輸出?
選2088還是3051?一起來說說TA們的不同~

物聯(lián)網(wǎng)在智慧校園中的應(yīng)用有哪些?一起來看!
HarmonyOS實戰(zhàn)開發(fā)-如何實現(xiàn)音頻低時延錄制和播放,AudioVivid音樂播放的相關(guān)功能
TSMaster 2024.04 最新版已上線,來看看新增了哪些實用功能

六類網(wǎng)線可以和強(qiáng)電一起走嗎
利用CXL技術(shù)重構(gòu)基于RDMA的內(nèi)存解耦合
#新開端、新起點,2024一起加油#
RDMA RNIC虛擬化方案
SIM卡座自彈式、帶卡托和防呆款各有哪些優(yōu)勢,一起來看看

深入了解RDMA技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論