 DiffusionDet檢測范式實現良好性能
DiffusionDet檢測范式實現良好性能
Diffusion model是目前非常火的圖片生成模型,其主要步驟是將原始圖像作為真實值,然后在上面添加多輪噪聲,后一輪的噪聲圖像只在上一輪圖像的基礎上生成,是一個十分標準的馬爾科夫鏈。訓練時即學習其噪聲生成的過程,推理時即使用其逆過程。噪聲是以像素為基本單位。在本文中,以噪聲框為基本單位,通過生成的隨機噪聲框來推理出真實值,是一種十分新穎的推理思路。
常見的生成框有這么幾種,最簡單的即滑動窗口,然后是通過訓練生成的檢測框,隨著并行計算的發展,滑動窗口演化為錨框,隨后則是比較新的基于查詢的檢測范式。
我們提出了 DiffusionDet,這是一個新的框架,它將對象檢測表述為從噪聲框到對象框的去噪擴散過程。在訓練階段,目標框從真實框擴散到隨機分布,模型學會逆轉這個噪聲過程。在推理中,該模型以漸進的方式將一組隨機生成的框細化為輸出結果。對包括 MS-COCO 和 LVIS 在內的標準基準進行的廣泛評估表明,與之前行之有效的檢測器相比,DiffusionDet 實現了良好的性能。我們的工作在物體檢測方面帶來了兩個重要發現。首先,隨機框雖然與預定義錨點或學習查詢有很大不同,但也是有效的候選對象。其次,目標檢測是代表性的感知任務之一,可以通過生成的方式解決。
1.介紹
對象檢測旨在為一幅圖像中的目標對象預測一組邊界框和相關類別標簽。作為一項基本的視覺識別任務,它已成為許多相關識別場景的基石,例如實例分割 [33, 48],姿態估計 [9, 20],動作識別 [29, 73],對象跟蹤 [41, 58] 和視覺關系檢測 [40, 56]。
現代對象檢測方法隨著候選對象的發展而不斷發展,即從經驗對象先驗 [24、53、64、66] 到可學習對象查詢 [10,81,102])。具體來說,大多數檢測器通過對經驗設計的候選對象定義代理回歸和分類來解決檢測任務,例如滑動窗口 [25、71]、區域建議 [24、66]、錨框 [50、64] 和參考點 [ 17, 97, 101]。最近,DETR [10] 提出可學習的對象查詢來消除手工設計的組件并建立端到端的檢測管道,引起了人們對基于查詢的檢測范式的極大關注 [21、46、81、102]。
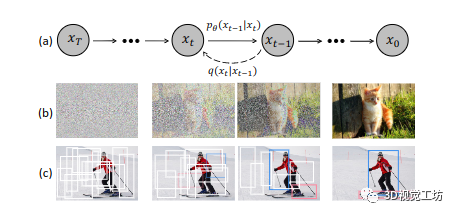
圖 1. 用于對象檢測的擴散模型。(a) 擴散模型,其中 q 是擴散過程,pθ 是逆過程。(b) 圖像生成任務的擴散模型。(c) 我們建議將目標檢測表述為從噪聲框到目標框的去噪擴散過程
雖然這些作品實現了簡單有效的設計,但它們仍然依賴于一組固定的可學習查詢。一個自然的問題是:是否有一種更簡單的方法甚至不需要可學習查詢的替代?
我們通過設計一個新穎的框架來回答這個問題,該框架直接從一組隨機框中檢測對象。從不包含需要在訓練中優化的可學習參數的純隨機框開始,我們期望逐漸細化這些框的位置和大小,直到它們完美地覆蓋目標對象。這種噪聲到框的方法不需要啟發式對象先驗,也不需要可學習的查詢,進一步簡化了對象候選并推動了檢測流程的發展。
我們的動機如圖 1 所示。我們認為噪聲到框范式的哲學類似于去噪擴散模型 [15、35、79] 中的噪聲到圖像過程,它們是一類可能性基于模型通過學習去噪模型逐漸去除圖像中的噪聲來生成圖像。擴散模型在許多生成任務 [3, 4, 37, 63, 85] 中取得了巨大成功,并開始在圖像分割等感知任務中進行探索 [1, 5, 6, 12, 28, 42, 89]。然而,據我們所知,還沒有成功地將其應用于目標檢測的現有技術。
在這項工作中,我們提出了 DiffusionDet,它通過在邊界框的位置(中心坐標)和大小(寬度和高度)的空間上將檢測作為生成任務來處理擴散模型的對象檢測任務圖片。在訓練階段,將由方差時間表 [35] 控制的高斯噪聲添加到真實值以獲得噪聲框。然后,這些噪聲框用于從骨干編碼器的輸出特征圖中裁剪感興趣區域 (RoI) 的 [33、66] 特征,例如 ResNet [34]、Swin Transformer [54]。最后,這些 RoI 特征被發送到檢測解碼器,該解碼器被訓練來預測沒有噪聲的真實值。有了這個訓練目標,DiffusionDet 就能夠從隨機框中預測出真實框。在推理階段,DiffusionDet 通過反轉學習的擴散過程生成邊界框,該過程將嘈雜的先驗分布調整為邊界框上的學習分布。
DiffusionDet 的 noise-to-box 管道具有 Once-for-All 的吸引人優勢:我們可以訓練網絡一次,并在推理的不同設置下使用相同的網絡參數。(1) 動態框:利用隨機框作為候選對象,DiffusionDet 將訓練和評估分離。DiffusionDet 可以用 Ntrain 隨機框進行訓練,同時用 Neval 隨機框進行評估,其中 Neval 是任意的,不需要等于 Ntrain。(2) 漸進細化:擴散模型通過迭代細化使 DiffusionDet 受益。我們可以調整去噪采樣步數以提高檢測精度或加快推理速度。這種靈活性使 Diffusion-Det 能夠適應對精度和速度有不同要求的不同檢測場景
我們在 MS-COCO [51] 數據集上評估 DiffusionDet。使用 ResNet-50 [34] 主干,DiffusionDet 使用單個采樣步驟實現 45.5 AP,這顯著優于 Faster R-CNN [66](40.2 AP)、DETR [10](42.0 AP)并且與稀疏 R 相當-CNN [81] (45.0 )。此外,我們可以通過增加采樣步驟的數量進一步將 DiffusionDet 提高到 46.2 AP。相反,現有的方法 [10, 81, 102] 不具有這種細化特性,并且在以迭代方式進行評估時會出現顯著的性能下降。此外,我們進一步在具有挑戰性的 LVIS [31] 數據集上進行了實驗,DiffusionDet 在這個長尾數據集上也表現良好,使用 Swin-Base [54] 主干實現了 42.1 AP
我們的貢獻總結如下:
? 我們將目標檢測制定為生成去噪過程,據我們所知,這是第一項將擴散模型應用于目標檢測的研究。
? 我們的噪聲到框檢測范例具有幾個吸引人的特性,例如動態框的解耦訓練和評估階段以及漸進式細化。
? 我們對MS-COCO 和LVIS 基準進行了大量實驗。DiffusionDet 相對于之前行之有效的檢測器實現了良好的性能
2.相關工作
物體檢測。大多數現代對象檢測方法對經驗對象先驗執行框回歸和類別分類,例如建議框 [24、66]、錨點 [50、64、65]、點 [84、87、101]。最近,Carion 等人。提出 DETR [10] 使用一組固定的可學習查詢來檢測對象。從那時起,基于查詢的檢測范式引起了極大的關注,并激發了一系列后續工作[46、52、57、80、81、102]。在這項工作中,我們使用 DiffusionDet 進一步推進了對象檢測管道的開發,如圖 2 所示。
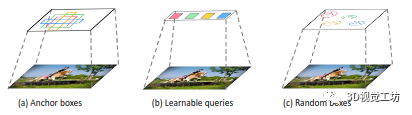
圖 2. 不同對象檢測范例的比較。(a) 從經驗對象先驗檢測 [64, 66];(b) 從可學習查詢中檢測 [10、81、102];(c) 從隨機框(我們的)中檢測。
擴散模型。作為一類深度生成模型,擴散模型[35,77,79]從隨機分布的樣本開始,通過漸進的去噪過程恢復數據樣本。擴散模型最近在計算機視覺 [4, 19, 30, 32, 36, 60, 63, 68, 69, 74, 96, 99],自然語言處理 [3, 27, 47] 等領域取得了顯著成果,音頻處理[38、43、45、62、82、92、95],跨學科應用[2、37、39、70、85、91、94]等。擴散模型的更多應用可以在最近的調查 [8, 96]。
感知任務的擴散模型。雖然擴散模型在圖像生成方面取得了巨大成功 [15,35,79],但它們在判別任務中的潛力尚未得到充分探索。一些先驅作品嘗試采用擴散模型進行圖像分割任務 [1, 5, 6, 12, 28, 42, 89],例如,Chen 等人。[12] 采用比特擴散模型 [13] 對圖像和視頻進行全景分割 [44]。然而,盡管對這個想法很感興趣,但以前沒有成功地將生成擴散模型用于對象檢測的解決方案,其進展明顯落后于分割。我們認為這可能是因為分割任務是以圖像到圖像的方式處理的,這在概念上更類似于圖像生成任務,而對象檢測是一個集合預測問題[10],需要分配候選對象[ 10, 49, 66] 到真實對象。據我們所知,這是第一個采用擴散模型進行目標檢測的工作。
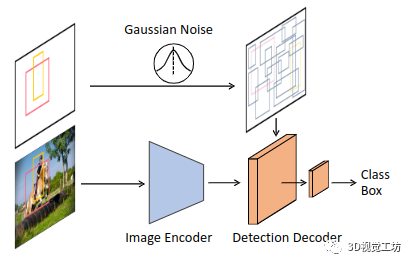
圖 3. DiffusionDet 框架。圖像編碼器從輸入圖像中提取特征表示。檢測解碼器將噪聲框作為輸入并預測類別分類和框坐標。在訓練期間,噪聲框是通過向真實值添加高斯噪聲來構建的。在推論中,噪聲框是從高斯分布中隨機采樣的。
3.實現方式
3.1預備知識
物體檢測。對象檢測的學習目標是輸入-目標對(x, b, c),其中x是輸入圖像,b和c分別是圖像x中對象的一組邊界框和類別標簽。更具體地說,我們將集合中的第 i 個框表示為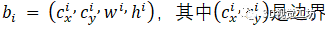 ,其中
,其中 是邊界框的中心坐標,
是邊界框的中心坐標, 分別是該邊界框的寬度和高度
分別是該邊界框的寬度和高度
擴散模型。擴散模型 [35, 75–77] 是一類受非平衡熱力學啟發的基于似然的模型 [77, 78]。這些模型通過逐漸向樣本數據中添加噪聲來定義擴散前向過程的馬爾可夫鏈。前向噪聲過程定義為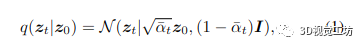
它通過向 z0 添加噪聲將數據樣本 z0 轉換為 t ∈ {0, 1, 。.., T } 的潛在噪聲樣本 zt。
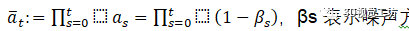 ,βs 表示噪聲方差表 [35]。在訓練期間,神經網絡 fθ (zt, t) 被訓練為通過最小化帶有 l2 損失的訓練目標從 zt 預測 z0 [35]:
,βs 表示噪聲方差表 [35]。在訓練期間,神經網絡 fθ (zt, t) 被訓練為通過最小化帶有 l2 損失的訓練目標從 zt 預測 z0 [35]:
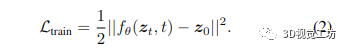
在推理階段,使用模型 fθ 和更新規則 [35, 76] 以迭代方式從噪聲 zT 重建數據樣本 z0,即 zT → zT ?Δ → 。.. → z0。可以在附錄 A 中找到更詳細的擴散模型公式。
在這項工作中,我們旨在通過擴散模型解決目標檢測任務。在我們的設置中,數據樣本是一組邊界框 z0 = b,其中 b ∈ RN ×4 是一組 N 個框。神經網絡 fθ (zt, t, x) 被訓練來從噪聲框 zt 預測 z0,以相應的圖像 x 為條件。對應的類別標簽c據此產生。
3.2網絡結構
由于擴散模型迭代生成數據樣本,因此需要在推理階段多次運行模型 fθ。然而,在每個迭代步驟中直接將 fθ 應用于原始圖像在計算上是難以處理的。因此,我們建議將整個模型分成兩部分,圖像編碼器和檢測解碼器,其中前者只運行一次以從原始輸入圖像 x 中提取深度特征表示,后者以此深度特征為條件,而不是原始圖像,以逐步細化來自嘈雜框 zt 的框預測。
圖像編碼器。圖像編碼器將原始圖像作為輸入,并為接下來的檢測解碼器提取其高級特征。我們使用 ResNet [34] 等卷積神經網絡和 Swin [54] 等基于 Transformer 的模型來實現 DiffusionDet。特征金字塔網絡 [49] 用于根據 [49、54、81] 為 ResNet 和 Swin 主干生成多尺度特征圖。
檢測解碼器。借鑒稀疏 R-CNN [81],檢測解碼器將一組建議框作為輸入,從圖像編碼器生成的特征圖中裁剪 RoI 特征 [33、66],并將這些 RoI 特征發送到檢測頭以獲得框回歸和分類結果。在 [10,81,102] 之后,我們的檢測解碼器由 6 個級聯階段組成。我們的解碼器與 Sparse R-CNN 解碼器的區別在于:
(1)DiffusionDet 從隨機框開始,而 Sparse R-CNN 在推理中使用一組固定的學習框;
(2) 稀疏 R-CNN 將建議框及其相應的建議特征對作為輸入,而 DiffusionDet 只需要建議框;
(3) DiffusionDet 在迭代采樣步驟中重新使用檢測器頭,并且參數在不同步驟之間共享,每個步驟都通過時間步嵌入 [35、86] 指定到擴散過程,而稀疏 R-CNN 使用檢測解碼器僅在前向傳播中進行一次
3.3訓練
在訓練過程中,我們首先構建從 ground-truth boxes 到 noisy boxes 的擴散過程,然后訓練模型來反轉這個過程。算法 1 提供了 DiffusionDet 訓練過程的偽代碼

真實值填充。對于現代對象檢測基準 [18、31、51、72],感興趣實例的數量通常因圖像而異。因此,我們首先將一些額外的框填充到原始真實值,以便所有框加起來達到固定數量 Ntrain。我們探索了幾種填充策略,例如,重復現有的真實值、連接隨機框或圖像大小框。這些策略的比較在 4.4 節中,連接隨機框效果最好
Box corruption。我們將高斯噪聲添加到填充的真實值。噪聲尺度由 αt 控制(在等式(1)中),如 [59] 中所提出的,αt 在不同的時間步長 t 中采用單調遞減的余弦時間表。值得注意的是,真實值坐標也需要縮放,因為信噪比對擴散模型的性能有顯著影響 [12]。我們觀察到對象檢測比圖像生成任務更傾向于使用相對更高的信號縮放值 [13,15,35]。更多討論在第 4.4 節
訓練損失。檢測器將 Ntrain 個損壞的框作為輸入,并預測 Ntrain 個類別分類和框坐標的預測。我們在 Ntrain 預測集上應用集預測損失 [10, 81, 102]。我們通過最佳傳輸分配方法 [16、22、23、90] 選擇成本最低的前 k 個預測,為每個基本事實分配多個預測。
3.4推理
DiffusionDet 的推理過程是從噪聲到目標框的去噪采樣過程。從以高斯分布采樣的框開始,模型逐漸改進其預測,如算法 2 所示。
采樣步驟。在每個采樣步驟中,隨機框或來自上一個采樣步驟的估計框被發送到檢測解碼器以預測類別分類和框坐標。在獲得當前步驟的框后,采用 DDIM [76] 來估計下一步的框。我們注意到,將沒有 DDIM 的預測框發送到下一步也是一種可選的漸進細化策略。然而,如第 4.4 節所述,它會帶來顯著的惡化。
box更新。在每個采樣步驟之后,可以將預測框粗略地分為兩類,期望預測和非期望預測。期望的預測包含正確位于相應對象的框,而不期望的預測是任意分布的。直接將這些不需要的框發送到下一個采樣迭代不會帶來好處,因為它們的分布不是由訓練中的框損壞構建的。為了使推理更好地與訓練保持一致,我們提出了框更新策略,通過用隨機框替換它們來恢復這些不需要的框。具體來說,我們首先過濾掉分數低于特定閾值的不需要的框。然后,我們將剩余的框與從高斯分布中采樣的新隨機框連接起來。
Once-for-all。得益于隨機框設計,我們可以使用任意數量的隨機框和采樣步驟數來評估 DiffusionDet,而無需等于訓練階段。作為比較,以前的方法 [10、81、102] 在訓練和評估期間依賴相同數量的處理框,并且它們的檢測解碼器在前向傳遞中僅使用一次
4.實驗
我們首先展示了 DiffusionDet 的Once-for-all屬性。然后我們將 DiffusionDet 與之前在 MS-COCO [51] 和 LVIS [31] 數據集上建立良好的檢測器進行比較。最后,我們提供了 DiffusionDet 組件的消融研究。
MS-COCO [51] 數據集在 train2017 集中包含約 118K 個訓練圖像,在 val2017 集中包含約 5K 個驗證圖像。總共有 80 個對象類別。我們報告多個 IoU 閾值 (AP)、閾值 0.5 (AP50) 和 0.75 (AP75) 的框平均精度
LVIS v1.0 [31] 數據集是一個大詞匯對象檢測和實例分割數據集,具有 100K 訓練圖像和 20K 驗證圖像。LVIS 與 MS-COCO 共享相同的源圖像,而其注釋捕獲 1203 個類別的長尾分布。我們在 LVIS 評估中采用 MS-COCO 風格的框度量 AP、AP50 和 AP75
4.1實施細節
訓練時間表。ResNet 和 Swin 主干分別在 ImageNet-1K 和 ImageNet-21K [14] 上使用預訓練的權重進行初始化。新添加的檢測解碼器使用 Xavier init [26] 進行初始化。我們使用 AdamW [55] 優化器訓練 DiffusionDet,初始學習率為 2.5 × 10?5,權重衰減為 10?4。所有模型都在 8 個 GPU 上使用大小為 16 的小批量進行訓練。對于 MS-COCO,默認的訓練計劃是 450K 次迭代,學習率在 350K 和 420K 次迭代時除以 10。對于LVIS,訓練計劃是210K、250K、270K。數據擴充策略包含隨機水平翻轉、調整輸入圖像大小的縮放抖動,使得最短邊至少為 480 且最多為 800 像素,而最長邊最多為 1333 [93],以及隨機裁剪擴充。我們不使用 EMA 和一些強大的數據增強,如 MixUp [98] 或 Mosaic [23]。
推理細節。在推理階段,檢測解碼器迭代地改進高斯隨機框的預測。我們分別為 MS-COCO 和 LVIS 選擇前 100 名和前 300 名的評分預測。NMS 將每個采樣步驟的預測組合在一起以獲得最終預測。
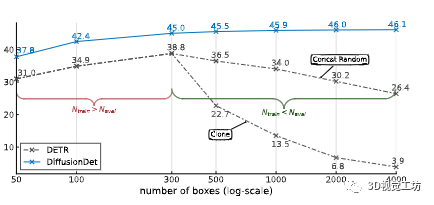
(a) 動態框。DETR 和 DiffusionDet 都經過 300 個對象查詢或建議框的訓練。推理中更多的建議框帶來了 DiffusionDet 的準確性提升,同時退化了 DETR
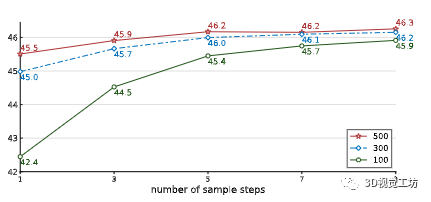
(b) 漸進細化。DiffusionDet 使用 300 個建議框進行訓練,并使用不同數量的建議框進行評估。對于所有情況,準確度都會隨著細化次數的增加而增加。
圖 4. DiffusionDet 的Once-for-all屬性。所有實驗都在 COCO 2017 訓練集上進行訓練,并在 COCO 2017 驗證集上進行評估。DiffusionDet 對圖 4a 和 4b 中的所有設置使用相同的網絡參數。我們提出的 DiffusionDet 能夠受益于更多的建議框和使用相同網絡參數的迭代改進。
4.2主要性能
DiffusionDet 的主要屬性在于對所有推理案例進行一次訓練。一旦模型被訓練好,它可以通過改變框的數量和推理中的樣本步驟的數量來使用,如圖4所示。Diffusion-Det可以通過使用更多的框或/和更多的細化步驟來獲得更好的準確性,代價是更高的延遲。因此,我們可以將單個 DiffusionDet 部署到多個場景,并在無需重新訓練網絡的情況下獲得所需的速度-精度權衡
動態盒子。我們將 DiffusionDet 與 DETR [10] 進行比較,以顯示動態框的優勢。與其他檢測器的比較在附錄 B 中。我們使用官方代碼和 300 輪訓練的默認設置使用 300 個對象查詢重現 DETR [10]。我們用 300 個隨機框訓練 DiffusionDet,以便候選的數量與 DETR 一致,以便進行公平比較。評估針對 {50, 100, 300, 500, 1000, 2000, 4000} 個查詢或框。
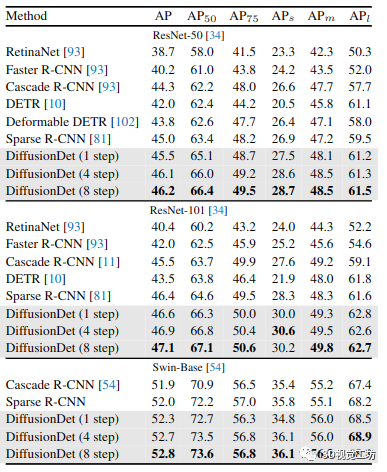
表 1. 在 COCO 2017 val set 上與不同物體檢測器的比較。每個方法后面的參考標明其結果的來源。沒有引用的方法是我們的實現
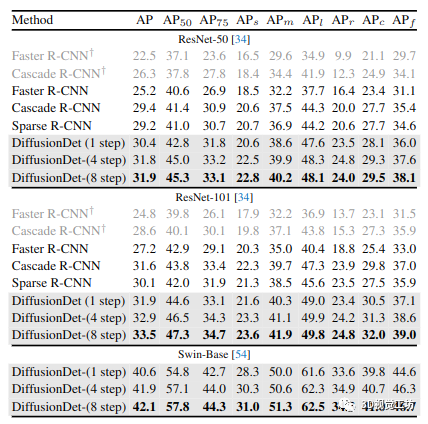
表 2. 在 LVIS v1.0 驗證集上與不同物體檢測器的比較。我們使用聯合損失 [100] 重新實現所有檢測器,除了淺灰色的行(帶有 ?)
由于在 DETR 的原始設置中訓練后可學習的查詢是固定的,我們提出了一個簡單的解決方法來使 DETR 能夠處理不同數量的查詢:當 Neval 《 Ntrain 時,我們直接從 Ntrain 查詢中選擇 Neval 查詢;當 Neval 》 Ntrain 時,我們連接額外的 Neval ? Ntrain 隨機初始化查詢(又名 concat random)。我們在圖 4a 中展示了結果。DiffusionDet 的性能隨著用于評估的框數的增加而穩步提高。相反,當 Neval 與 Ntrain 不同時,即 300,DETR 有明顯的性能下降。此外,當 Neval 和 Ntrain 之間的差異增加時,這種性能下降會變得更大。例如,當框數增加到 4000 時,DETR 只有 26.4 個 AP 和 concat 隨機策略,比峰值低 12.4(即 38.8 個 AP 和 300 個查詢)。作為比較,DiffusionDet 可以通過 4000 個盒子實現 1.1 的 AP 增益。
當 Neval 》 Ntrain 時,我們還為 DETR 實現了另一種方法,將現有的 Ntrain 查詢克隆到 Neval(也稱為克隆)。我們觀察到 concat 隨機策略始終比克隆策略表現更好。這是合理的,因為克隆查詢將產生與原始查詢相似的檢測結果。相比之下,隨機查詢為檢測結果引入了更多的多樣性
漸進式細化。DiffusionDet 的性能不僅可以通過增加隨機框的數量來提高,還可以通過迭代更多的步驟來提高。我們通過將迭代步驟從 1 增加到 9,使用 100、300 和 500 個隨機框評估 DiffusionDet。結果如圖 4b 所示。我們看到具有這三種設置的 DiffusionDet 都具有穩定的性能提升和更多的優化步驟。此外,具有較少隨機框的 DiffusionDet 往往會隨著細化而獲得更大的增益。例如,具有 100 個隨機框的 DiffusionDet 實例的 AP 從 42.4(1 步)增加到 45.9(9 步),絕對 3.5 AP 改進。這種精度性能與 300 個隨機框的 45.0(1 步)和 500 個隨機框的 45.5(1 步)相當,表明 DiffusionDet 的高精度可以通過增加建議框的數量或迭代步驟來實現。
相比之下,我們發現以前的方法 [10、81、102] 沒有這種細化特性。他們只能使用一次檢測解碼器。使用兩個或更多迭代步驟會降低性能。更詳細的比較可以在附錄 C 中找到。
4.3檢測數據集的基準測試
我們在 MS-COCO 和 LVIS 數據集上將 DiffusionDet 與之前的檢測器 [7,10, 50, 66, 81, 102] 進行比較。在本小節中,我們采用 500 個框進行訓練和推理。更詳細的實驗設置在附錄 D 中。
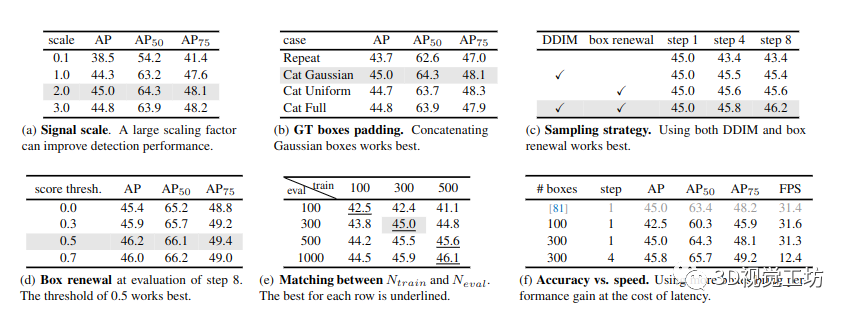
表 3.MS-COCO 上的 DiffusionDet 消融實驗。我們報告 AP、AP50 和 AP75。如果不指定,默認設置為:backbone是ResNet-50[34] with FPN[49],signal scale是2.0,ground-truth boxes padding方法是拼接Gaussian random boxes,采樣使用DDIM和box renewal步驟,其中框更新的分數閾值為0.5,訓練和評估都使用300個框。默認設置以灰色標記
MS-COCO。在表 1 中,我們比較了 DiffusionDet 與之前在 MS-COCO 上的檢測器的對象檢測性能。沒有細化的 DiffusionDet(即第 1 步)使用 ResNet-50 主干實現 45.5 AP,以非常重要的優勢優于 Faster R-CNN、RetinaNet、DETR 和 Sparse R-CNN 等成熟方法。此外,DiffusionDet 在使用更多迭代細化時可以使其優勢更加顯著。例如,當使用 ResNet-50 作為主干時,DiffusionDet 比稀疏 R-CNN 單步高 0.5 AP(45.5 對 45.0),而 8 步高 1.2 AP(46.2 對 45.0)。
當主干尺寸按比例增加時,DiffusionDet 顯示出穩定的改進。DiffusionDet with ResNet-101 達到 46.6 AP(1 步)和 47.1 AP(8 步)。當使用 ImageNet-21k 預訓練的 Swin-Base [54] 作為主干時,DiffusionDet 單步獲得 52.3 AP,8 步獲得 52.8 AP,優于 Cascade R-CNN 和 Sparse R-CNN
LVIS v1.0。我們在表 2 中比較了在更具挑戰性的 LVIS 數據集上的結果。我們基于 detectron2 [93] 重現了 Faster R-CNN 和 Cascade R-CNN,而在其原始代碼上重現了 Sparse R-CNN。我們首先使用 detectron2 的默認設置重現 Faster R-CNN 和 Cascade R-CNN,分別使用 ResNet-50/101 主干實現 22.5/24.8 和 26.3/28.8 AP(表 2 中帶有 ?)。此外,我們使用 [100] 中的聯合損失來提高它們的性能。由于 LVIS 中的圖像是以聯合方式注釋的 [31],負類別注釋稀疏,這會惡化訓練梯度,特別是對于稀有類別 [83]。聯邦損失被提議通過為每個訓練圖像采樣類的子集 S 來緩解這個問題,其中包括所有正注釋和負注釋的隨機子集。在 [100] 之后,我們選擇 |S| = 50 在所有實驗中。Faster R-CNN 和 Cascade R-CNN 通過聯邦損失獲得大約 3 個 AP 收益。以下所有比較均基于此損失
我們看到 DiffusionDet 使用更多的細化步驟獲得了顯著的收益,同時具有小型和大型骨干。此外,我們注意到與 MS-COCO 相比,細化在 LVIS 上帶來了更多收益。例如,它在 MS-COCO 上的性能從 45.5 增加到 46.2(+0.7 AP),而在 LVIS 上從 30.4 增加到 31.9(+1.5 AP),這表明我們的精煉策略將對更具挑戰性的基準更有幫助
4.4消融研究
我們在 MS-COCO 上進行消融實驗以詳細研究 DiffusionDet。所有實驗都使用帶有 FPN 的 ResNet-50 作為骨干和 300 個框用于訓練和推理,沒有進一步的說明。
信號縮放。信號比例因子控制擴散過程的信噪比 (SNR)。我們在表 3a 中研究了比例因子的影響。結果表明,2.0 的縮放因子實現了最佳 AP 性能,優于圖像生成任務中的標準值 1.0 [13、35] 和用于全景分割的標準值 0.1 [12]。我們解釋說這是因為一個框只有四個表示參數,即中心坐標(cx,cy)和框大小(w,h),這粗略地類似于圖像生成中只有四個像素的圖像。框表示比密集表示更脆弱,例如全景分割中的 512×512 掩模表示 [13]。因此,與圖像生成和全景分割相比,DiffusionDet 更喜歡具有更高信噪比的更簡單的訓練目標
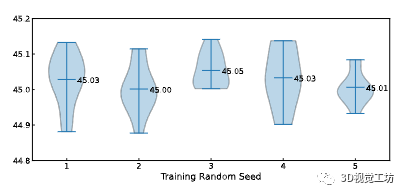
圖 5. 5 個獨立訓練實例的統計結果,每個實例用不同的隨機種子評估 10 次。圖中的數字表示平均值。
GT 框填充策略。如第 3.3 節所述,我們需要將額外的框填充到原始真實值,以便每個圖像具有相同數量的框。我們在表 3b 中研究了不同的填充策略,包括(1.)均勻地重復原始真實值,直到總數達到預定義值 Ntrain;(2.) 填充服從高斯分布的隨機框;(3.) 填充服從均勻分布的隨機框;(4.) 填充與整個圖像大小相同的框,這是 [81] 中可學習框的默認初始化。串聯高斯隨機框最適合 DiffusionDet。我們默認使用這種填充策略。
抽樣策略。我們在表 3c 中比較了不同的采樣策略。在評估不使用 DDIM 的 DiffusionDet 時,我們直接將當前步驟的輸出預測作為下一步的輸入。我們發現,當既不采用 DDIM 也不采用框更新時,DiffusionDet 的 AP 會隨著評估步驟的增加而降低。此外,僅使用 DDIM 或 box renewal 在 4 步時會帶來輕微的好處,而在使用更多步時不會帶來進一步的改進。此外,我們的 DiffusionDet 在配備 DDIM 和更新時獲得了顯著的收益。這些實驗共同驗證了采樣步驟中 DDIM 和盒子更新的必要性。
盒子更新閾值。如第 3.4 節所述,提出了框更新策略以重新激活分數低于特定閾值的預測。表 3d 顯示了框更新的分數閾值的影響。閾值 0.0 表示不使用框更新。結果表明 0.5 的閾值比其他閾值表現稍好。
Ntrain 和 Neval 之間的匹配。正如在第二節中討論的那樣。4.2,DiffusionDet 具有使用任意數量的隨機框進行評估的吸引人的特性。為了研究訓練框的數量如何影響推理性能,我們分別使用 Ntrain ∈ {100, 300, 500} 隨機框訓練 DiffusionDet,然后使用 Neval ∈ {100, 300, 500, 1000} 評估這些模型中的每一個。結果總結在表 3e 中。首先,無論 DiffusionDet 使用多少個隨機框進行訓練,精度都會隨著 Neval 的增加而穩定增加,直到在大約 2000 個隨機框處達到飽和點。其次,當 Ntrain 和 Neval 相互匹配時,DiffusionDet 往往表現更好。例如,當 Neval = 100 時,使用 Ntrain = 100 個框訓練的 DiffusionDet 表現優于 Ntrain = 300 和 500。
精度與速度。我們在表 3f 中測試了 DiffusionDet 的推理速度。運行時間在單個 NVIDIA A100 GPU 上進行評估,小批量大小為 1。我們對 Ntrain ∈ {100, 300} 的多種選擇進行了實驗,并保持 Neval 與相應的 Ntrain 相同。我們看到將 Ntrain 從 100 增加到 300 會帶來 2.5 AP 增益,而延遲成本可以忽略不計(31.6 FPS 對 31.3 FPS)我們還測試了當 Ntrain = 300 時 4 步的推理速度。我們觀察到更多的改進成本帶來更多的推理次并導致更少的 FPS。將精煉步驟從 1 增加到 4 提供 0.8 AP 增益,但會使檢測器變慢。作為參考,我們將 DiffusionDet 與具有 300 個提議的稀疏 R-CNN 進行比較,而具有 300 個框的 DiffusionDet 與稀疏 R-CNN 的 FPS 非常接近。
隨機種子。由于 DiffusionDet 在推理開始時被賦予隨機框作為輸入,因此有人可能會問不同隨機種子之間是否存在較大的性能差異。我們通過獨立訓練五個模型來評估 DiffusionDet 的穩定性,除了隨機種子外,這些模型具有嚴格相同的配置。然后,我們使用 10 個不同的隨機種子評估每個模型實例,以衡量性能的分布,受到 [61, 88] 的啟發。如圖 5 所示,大多數評估結果都分布在 45.0 AP 附近。此外,平均值均在 45.0 AP 以上,不同模型實例之間的性能差異很小,這表明 DiffusionDet 對隨機框具有魯棒性并產生可靠的結果。
5.結論和未來的工作
在這項工作中,我們通過將對象檢測視為從噪聲框到對象框的去噪擴散過程,提出了一種新的檢測范式 DiffusionDet。我們的 noise-to-box 管道有幾個吸引人的特性,包括動態框和漸進式細化,使我們能夠使用相同的網絡參數來獲得所需的速度-精度權衡,而無需重新訓練模型。標準檢測基準的實驗表明,與成熟的檢測器相比,DiffusionDet 實現了良好的性能
為了進一步探索擴散模型解決對象級識別任務的潛力,未來的幾項工作是有益的。嘗試將 DiffusionDet 應用于視頻級任務,例如對象跟蹤和動作識別。另一種是將 DiffusionDet 從封閉世界擴展到開放世界或開放詞匯對象檢測
審核編輯:郭婷
-
解碼器
+關注
關注
9文章
1131瀏覽量
40684 -
檢測器
+關注
關注
1文章
860瀏覽量
47654 -
噪聲
+關注
關注
13文章
1118瀏覽量
47372
原文標題:DiffusionDet:用于對象檢測的擴散模型
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
第四范式前三季度營收穩健增長
東軟引領醫院智慧服務新范式
如何檢測阻尼器的性能
雨刮器壓力分布檢測wipe有用嗎?
如何在采用 SOT563 封裝的 TPS56x242-7 上實現更良好的熱性能

PPEC:零成本技術交底,賦能電源開發新范式
鴻蒙原生應用元服務開發-初識倉頡開發語言
鴻蒙原生應用元服務開發-初識倉頡開發語言
武漢凱迪正大分享電纜電氣性能檢測:檢測內容與規范
MEMS諧振傳感器新范式:熱噪聲驅動的傳感器的可行性與動態檢測性能


基于OpenHarmony音符檢測實現原理






 工商網監
工商網監
評論