 使用LIME解釋CNN
使用LIME解釋CNN
作者:Mehul Gupta
來源:DeepHub IMBA
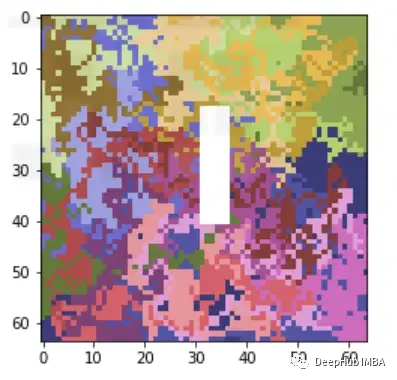
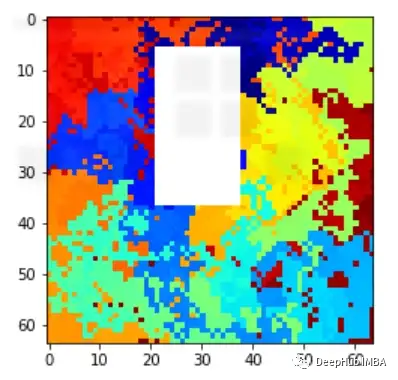
圖像與表格數據集有很大不同(顯然)。如果你還記得,在之前我們討論過的任何解釋方法中,我們都是根據特征重要性,度量或可視化來解釋模型的。比如特征“A”在預測中比特征“B”有更大的影響力。但在圖像中沒有任何可以命名的特定特征,那么怎么進行解釋呢?
一般情況下我們都是用突出顯示圖像中模型預測的重要區域的方法觀察可解釋性,這就要求了解如何調整LIME方法來合并圖像,我們先簡單了解一下LIME是怎么工作的。

LIME在處理表格數據時為訓練數據集生成摘要統計:
使用匯總統計生成一個新的人造數據集
從原始數據集中隨機提取樣本
根據與隨機樣本的接近程度為生成人造數據集中的樣本分配權重
用這些加權樣本訓練一個白盒模型
解釋白盒模型
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from keras.layers import Input, Dense, Embedding, Flatten
from keras.layers import SpatialDropout1D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.models import Sequential
from randimage import get_random_image, show_array
import random
import pandas as pd
import numpy as np
import lime
from lime import lime_image
from skimage.segmentation import mark_boundaries
#preparing above dataset artificially
training_dataset = []
training_label = []
for x in range(200):
img_size = (64,64)
img = get_random_image(img_size)
a,b = random.randrange(0,img_size[0]/2),random.randrange(0,img_size[0]/2)
c,d = random.randrange(img_size[0]/2,img_size[0]),random.randrange(img_size[0]/2,img_size[0])
value = random.sample([True,False],1)[0]
if value==False:
img[a:c,b:d,0] = 100
img[a:c,b:d,1] = 100
img[a:c,b:d,2] = 100
training_dataset.append(img)
training_label.append(value)
#training baseline CNN model
training_label = [1-x for x in training_label]
X_train, X_val, Y_train, Y_val = train_test_split(np.array(training_dataset).reshape(-1,64,64,3),np.array(training_label).reshape(-1,1), test_size=0.1, random_state=42)
epochs = 10
batch_size = 32
model = Sequential()
model.add(Conv2D(32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Flatten())
# Output layer
model.add(Dense(32,activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, validation_data=(X_val, Y_val), epochs=epochs, batch_size=batch_size, verbose=1)
x=10
explainer = lime_image.LimeImageExplainer(random_state=42)
explanation = explainer.explain_instance(
X_val[x],
model.predict,top_labels=2)
)
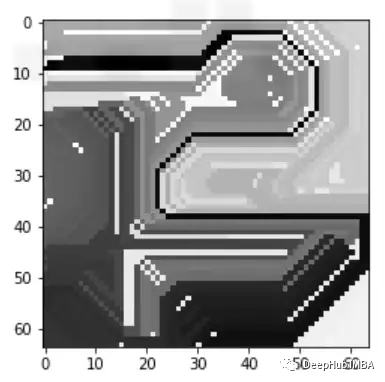
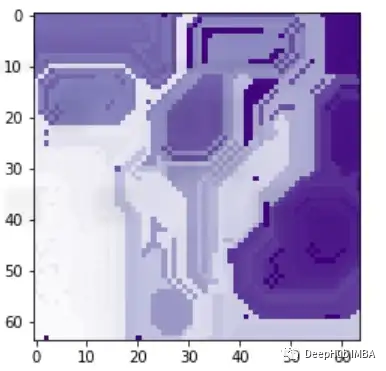
image, mask = explanation.get_image_and_mask(0, positives_only=True,
hide_rest=True)
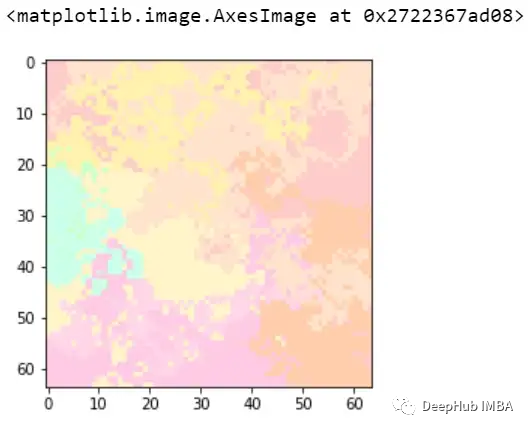
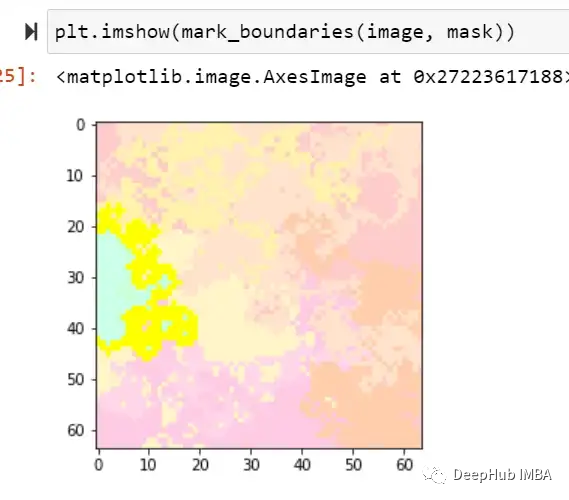
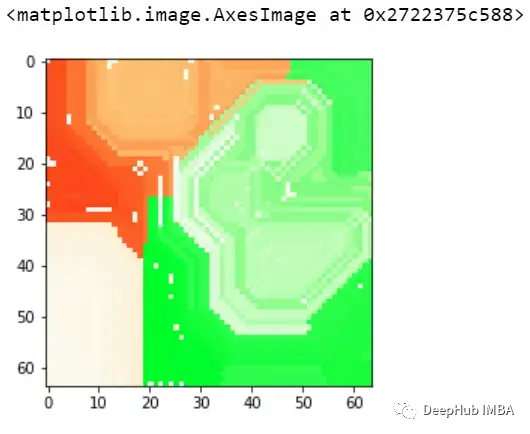
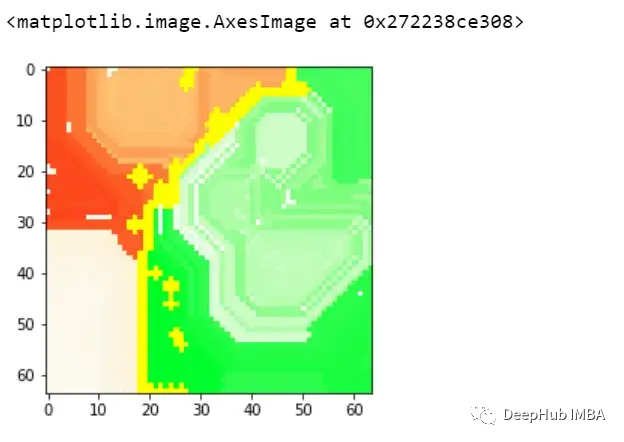
這樣我們就可以理解模型導致錯誤分類的實際問題是什么,這就是為什么可解釋和可解釋的人工智能如此重要。
END

(添加請備注公司名和職稱)
Imagination 基于 O3DE 引擎的光線追蹤 Demo 詳解

Imagination Technologies是一家總部位于英國的公司,致力于研發芯片和軟件知識產權(IP),基于Imagination IP的產品已在全球數十億人的電話、汽車、家庭和工作場所中使用。獲取更多物聯網、智能穿戴、通信、汽車電子、圖形圖像開發等前沿技術信息,歡迎關注 Imagination Tech!
原文標題:使用LIME解釋CNN
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
imagination
+關注
關注
1文章
570瀏覽量
61281
原文標題:使用LIME解釋CNN
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
cnn常用的幾個模型有哪些
CNN(卷積神經網絡)是一種深度學習模型,廣泛應用于圖像識別、自然語言處理等領域。以下是一些常用的CNN模型: LeNet-5:LeNet-5是最早的卷積神經網絡之一,由Yann LeCun等人于
圖像分割與語義分割中的CNN模型綜述
圖像分割與語義分割是計算機視覺領域的重要任務,旨在將圖像劃分為多個具有特定語義含義的區域或對象。卷積神經網絡(CNN)作為深度學習的一種核心模型,在圖像分割與語義分割中發揮著至關重要的作用。本文將從CNN模型的基本原理、在圖像分割與語義分割中的應用、以及具體的模型架構和調
CNN與RNN的關系?
在深度學習的廣闊領域中,卷積神經網絡(CNN)和循環神經網絡(RNN)是兩種極為重要且各具特色的神經網絡模型。它們各自在圖像處理、自然語言處理等領域展現出卓越的性能。本文將從概念、原理、應用場景及代碼示例等方面詳細探討CNN與RNN的關系,旨在深入理解這兩種網絡模型及其在
CNN在多個領域中的應用
,通過多層次的非線性變換,能夠捕捉到數據中的隱藏特征;而卷積神經網絡(CNN),作為神經網絡的一種特殊形式,更是在圖像識別、視頻處理等領域展現出了卓越的性能。本文旨在深入探究深度學習、神經網絡與卷積神經網絡的基本原理、結構特點及其在多個領域中的廣泛應用。
CNN的定義和優勢
卷積神經網絡(Convolutional Neural Networks, CNN)作為深度學習領域的核心成員,不僅在學術界引起了廣泛關注,更在工業界尤其是計算機視覺領域展現出了巨大的應用價值。關于
基于CNN的網絡入侵檢測系統設計
入侵檢測提供了新的思路和方法。卷積神經網絡(Convolutional Neural Network, CNN)作為深度學習的一種重要模型,以其強大的特征提取能力和模式識別能力,在網絡入侵檢測領域展現出巨大的潛力。
如何在TensorFlow中構建并訓練CNN模型
在TensorFlow中構建并訓練一個卷積神經網絡(CNN)模型是一個涉及多個步驟的過程,包括數據預處理、模型設計、編譯、訓練以及評估。下面,我將詳細闡述這些步驟,并附上一個完整的代碼示例。
如何利用CNN實現圖像識別
卷積神經網絡(CNN)是深度學習領域中一種特別適用于圖像識別任務的神經網絡結構。它通過模擬人類視覺系統的處理方式,利用卷積、池化等操作,自動提取圖像中的特征,進而實現高效的圖像識別。本文將從CNN的基本原理、構建過程、訓練策略以及應用場景等方面,詳細闡述如何利用
NLP模型中RNN與CNN的選擇
在自然語言處理(NLP)領域,循環神經網絡(RNN)與卷積神經網絡(CNN)是兩種極為重要且廣泛應用的網絡結構。它們各自具有獨特的優勢,適用于處理不同類型的NLP任務。本文旨在深入探討RNN與CNN
cnn卷積神經網絡分類有哪些
卷積神經網絡(CNN)是一種深度學習模型,廣泛應用于圖像分類、目標檢測、語義分割等領域。本文將詳細介紹CNN在分類任務中的應用,包括基本結構、關鍵技術、常見網絡架構以及實際應用案例。 引言 1.1
cnn卷積神經網絡三大特點是什么
卷積神經網絡(Convolutional Neural Networks,簡稱CNN)是一種深度學習模型,廣泛應用于圖像識別、視頻分析、自然語言處理等領域。CNN具有以下三大特點: 局部連接
CNN模型的基本原理、結構、訓練過程及應用領域
卷積神經網絡(Convolutional Neural Network,簡稱CNN)是一種深度學習模型,廣泛應用于圖像識別、視頻分析、自然語言處理等領域。CNN模型的核心是卷積層
卷積神經網絡cnn模型有哪些
卷積神經網絡(Convolutional Neural Networks,簡稱CNN)是一種深度學習模型,廣泛應用于圖像識別、視頻分析、自然語言處理等領域。 CNN的基本概念 1.1 卷積層
深度神經網絡模型cnn的基本概念、結構及原理
深度神經網絡模型CNN(Convolutional Neural Network)是一種廣泛應用于圖像識別、視頻分析和自然語言處理等領域的深度學習模型。 引言 深度學習是近年來人工智能領域的研究熱點
基于Python和深度學習的CNN原理詳解
卷積神經網絡 (CNN) 由各種類型的層組成,這些層協同工作以從輸入數據中學習分層表示。每個層在整體架構中都發揮著獨特的作用。





 工商網監
工商網監
評論