 在DeepStream上使用自己的Pytorch模型
在DeepStream上使用自己的Pytorch模型
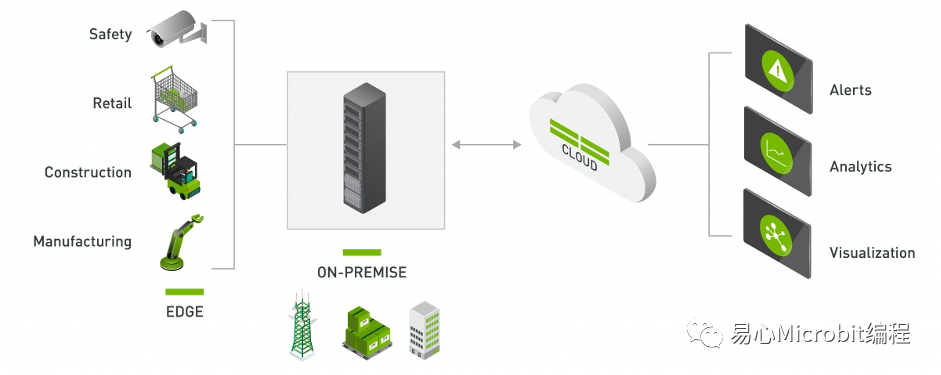
DeepStream是NVIDIA專為處理多個串流影像,并進行智能辨識而整合出的強大工具。開發語言除了原先的C++,從DeepStream SDK 5.1也支持基于原先安裝,再掛上Python套件的方式,讓較熟悉Python程序語言的使用者也能使用DeepStream。
本文主要將其應用在Jetson Nano上,并于DeepStream導入自己的模型執行辨識。
在Jetson Nano上面安裝DeepStream
筆者使用的硬件為Jetson Nano 2GB/4GB,參照官方提供的步驟與對應的版本,幾乎可以說是無痛安裝。對比同樣采用干凈映像檔,使用源碼或是Docker安裝的JetBot與Jetson Inference要快上許多。
執行官方范例
DeepStream有提供不少范例,不論是從CSI或USB接口的攝影機取得畫面,或是多影像辨識結果顯示,都能經由查看這些范例,學習如何設定。
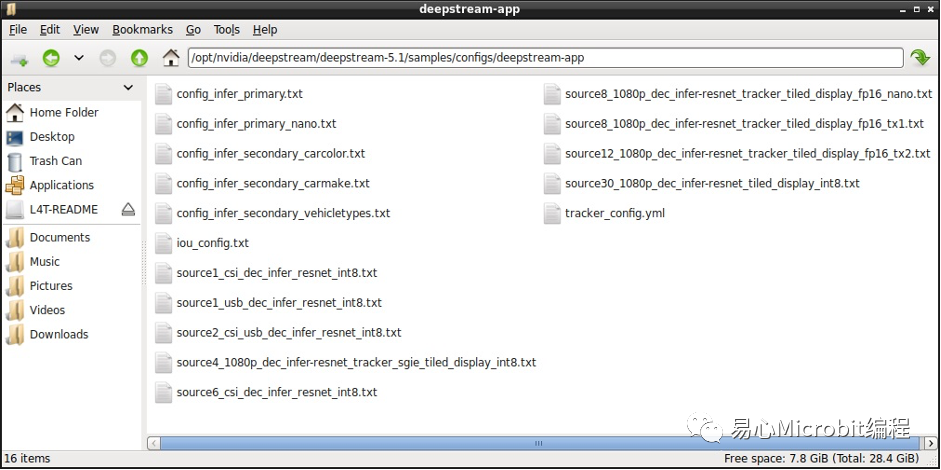
透過下列指令執行一個配置文件,查看DeepStream是否安裝成功,這個配置文件會開啟一部mp4影片,并模擬產生8個輸入來源,經模型推論處理過后于同一個畫面顯示,點擊單一個區塊可以顯示該來源的詳細信息。實際應用上可以將各部攝影機的畫面同時輸出并進行處理。
deepstream-app -c source8_1080p_dec_infer-resnet_tracker_tiled_display_fp16_nano.txt

使用自己的模型
如果您與筆者一樣是NVIDIA官方課程小粉絲,從擁有Jetson Nano開始,就按部就班的跟著課程學習,那您一定看過下列三種不同主題的課程。
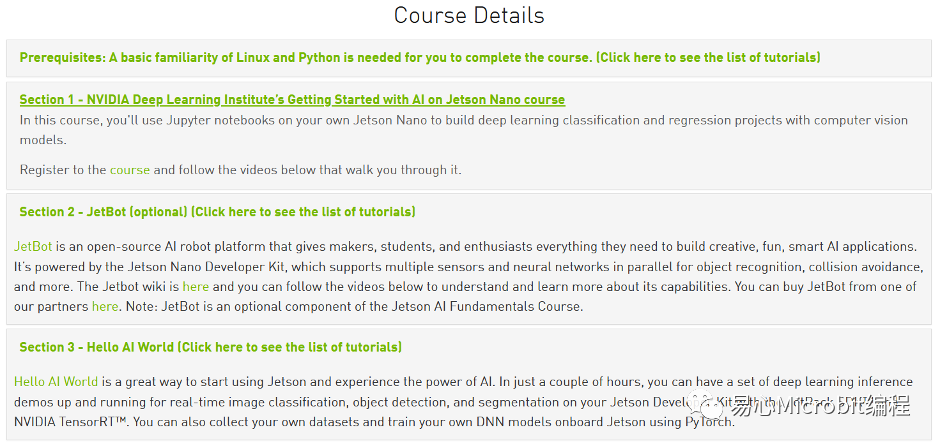
從入門的Section 1開始,到執行Section 2的JetBot自駕車項目,最后Section 3 Hello AI World。經過三個Section,您應該稍微熟悉Pytorch,并且也訓練了不少自己的模型,特別是在Hello AI World有訓練了Object Detection模型。既然都有自己的模型,何不放到DeepStream上面制作專屬的串流辨識項目,針對想要辨識的項目導入適合的模型。
在Hello AI World項目訓練Object Detection模型的時候,我們使用的是SSD-Mobilenet,在DeepStream的對象辨識范例中有提供使用自己的SSD模型方法,可在下列路徑找到參考文件,文件中使用的例子是使用coco數據集預訓練的SSD-Inception。
/opt/nvidia/deepstream/deepstream-5.1/sources/objectDetector_SSD
可惜的是文件中使用的是從Tensorflow訓練的模型,經由轉換.uff再喂給DeepStream,與官方課程使用的Pytorch是不同路線。筆者在網上尋找解決方法,看是否有DeepStream使用Pytorch模型的方案,也于NVIDIA開發者論壇找到幾個同樣的提問,但最終都是導到上述提到的參考文件。
從Hello AI World訓練的Object Detection模型,經過執行推論的步驟,您應該會有三個與模型有關的檔案,分別是用Pytorch訓練好的.pth,以及為了使用TensorRT加速而將.pth轉換的.onnx,最后是執行過程中產生的.engine。既然Pytorch模型找不到解決方案,那就從ONNX模型下手吧,所幸經過一番折騰,終于讓筆者找到方法。
https://github.com/neilyoung/nvdsinfer_custom_impl_onnx
neilyoung提供的方法主要是能產生動態函式庫,以便我們能在DeepStream使用ONNX模型,除了準備好自己訓練的ONNX模型檔案與Labels檔案,只要再新增設定模型路徑與類型的config檔案,與deepstream配置文件就能實現使用自己的模型進行推論啰!
STEP 1:
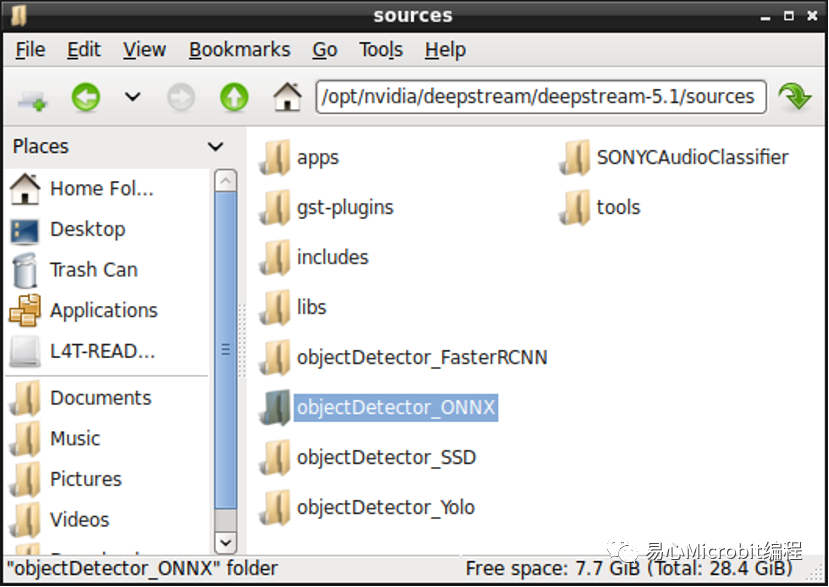
首先于以下路徑底下新增執行ONNX項目的文件夾,筆者命名為objectDetector_ONNX。
/opt/nvidia/deepstream/deepstream-5.1/sources
STEP 2:
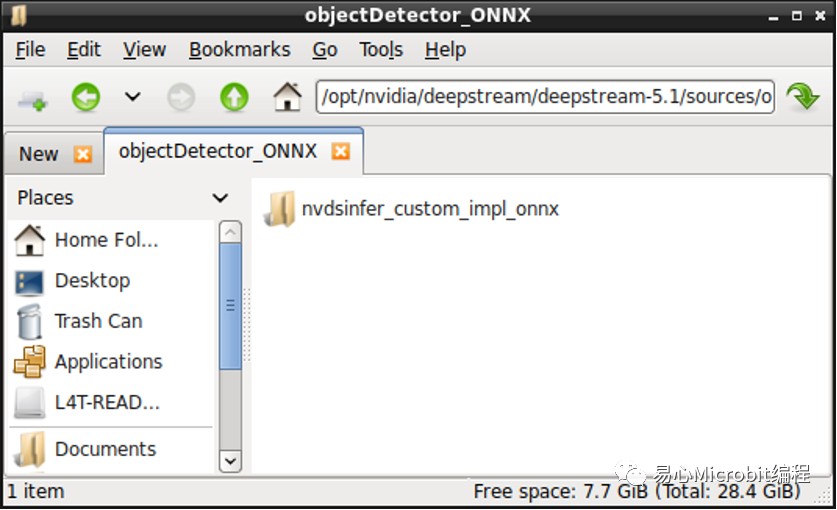
新增專案文件夾后,請clone方才的nvdsinfer_custom_impl_onnx專案到文件夾內。
STEP 3:
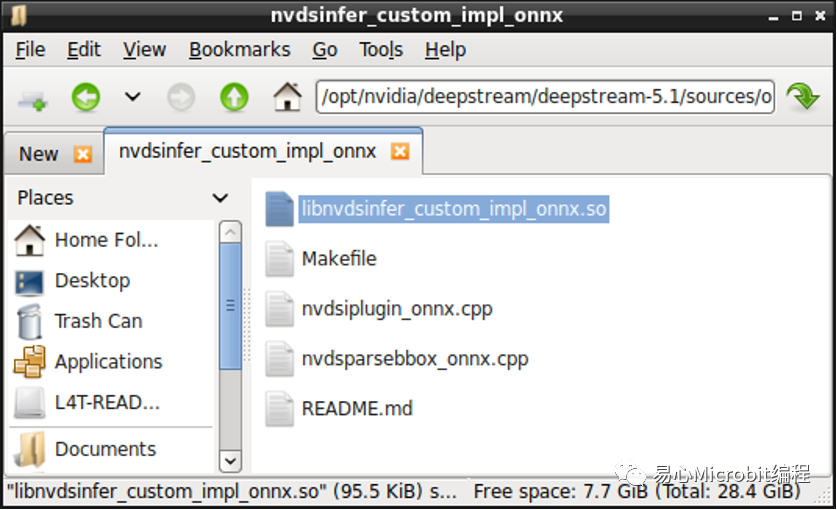
打開Terminal進到nvdsinfer_custom_impl_onnx項目里面,透過sudo make指令產生動態函式庫。
STEP 4:
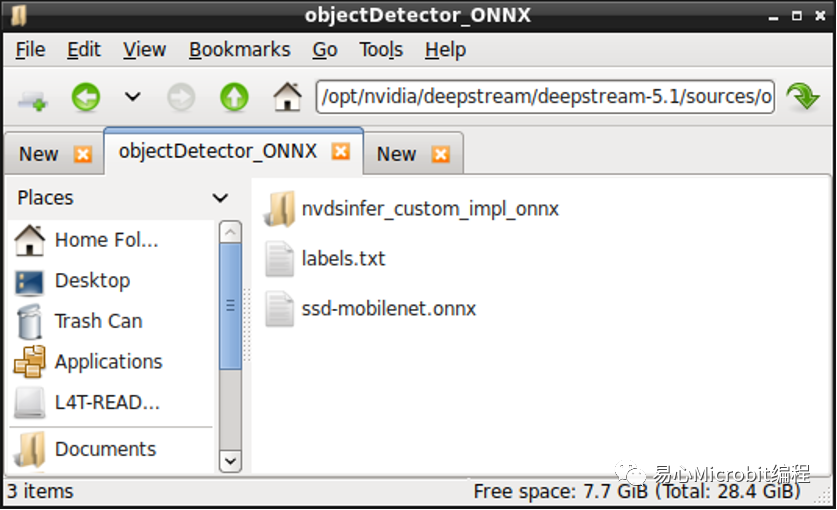
接著將自己從Hello AI World項目訓練的Object Detection模型與卷標復制到objectDetector_ONNX項目文件夾。
STEP 5:
從別的項目文件夾復制config檔案與deepstream配置文件到我們的文件夾內,這邊復制objectDetector_SSD,因為模型類型相近,只要稍微修改即可。
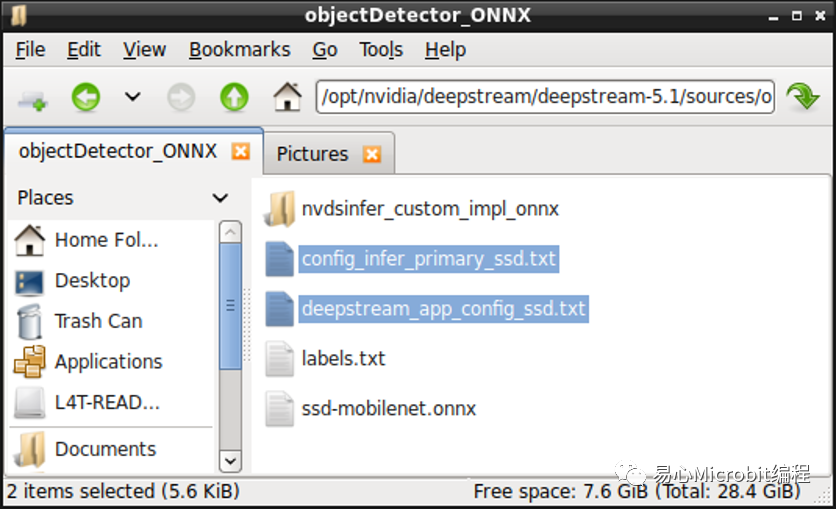
STEP 6:
首先修改config檔案,如下圖所示,將模型路徑與卷標路徑,修正為自己的模型與卷標名稱,engine檔案的部份與Hello AI World項目一樣,在執行ONNX檔案進行TensorRT加速時會自動產生,只需給路徑與名稱即可。對于classes的部份,切記在Hello AI World項目訓練的模型會加上BACKGROUND這一個類別,所以若是您辨識的對象有三種,就得在classes這邊填上3+1。
下方三項的設定則依照nvdsinfer_custom_impl_onnx項目github上的說明,記得動態函式庫的路徑請改成自己的路徑。
output-blob-names="boxes;scores"
parse-bbox-func-name="NvDsInferParseCustomONNX"
custom-lib-path="/path/to/lib/libnvdsinfer_custom_impl_onnx.so"
接著依照個人需求設定辨識的參數,例如希望信心指數達多少%才認定對象類別,可以修改threshold。
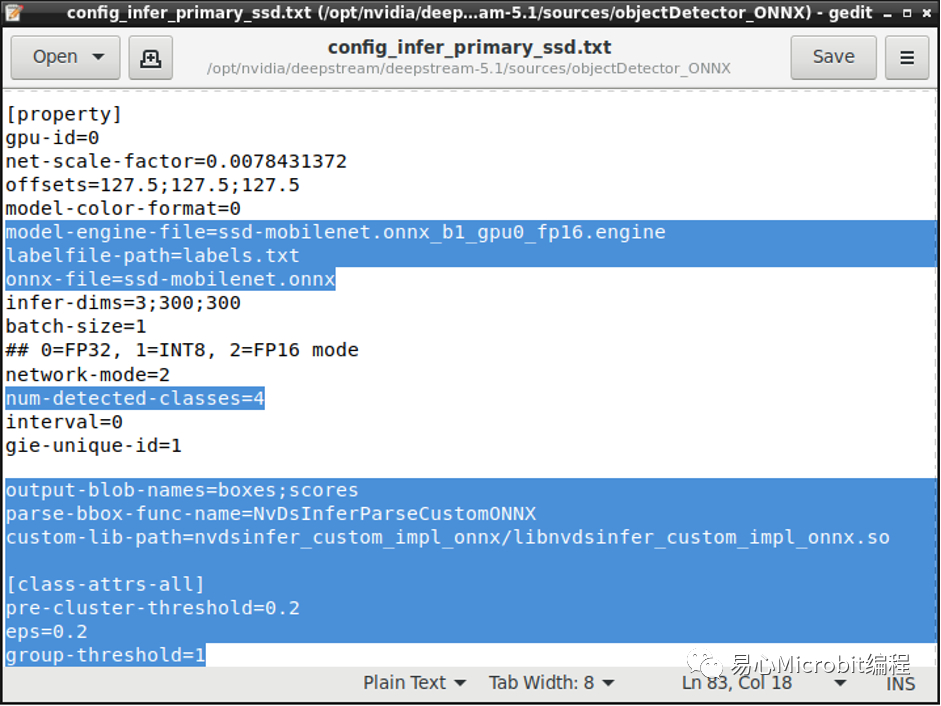
STEP 7:
接著修改deepstream配置文件,筆者在這邊設定為USB Webcam輸入,并輸出單一窗口顯示,除了正常調整輸入與輸出之外,請將config檔案與Labels檔案導引至自己的路徑,engine的部份與config設定相同即可,如下圖所示。
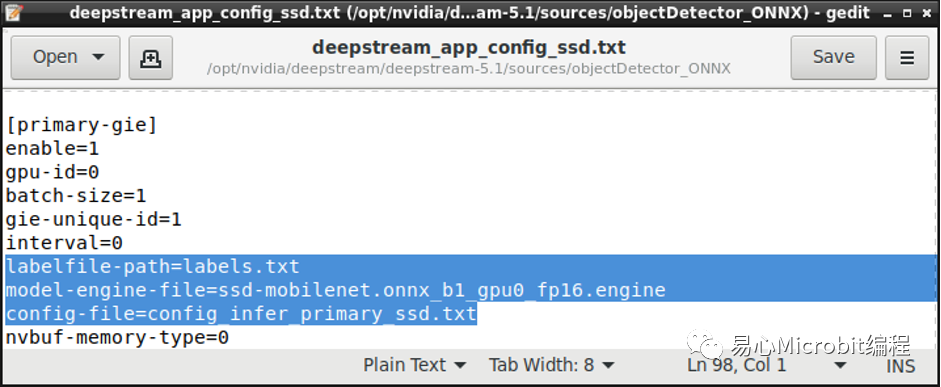
完成上述7步驟后,就能執行配置文件查看是否有正確執行我們的ONNX模型,第一次執行會較久,過程會產生engine檔案,一旦有了engine檔,之后執行就不會再重復產生。
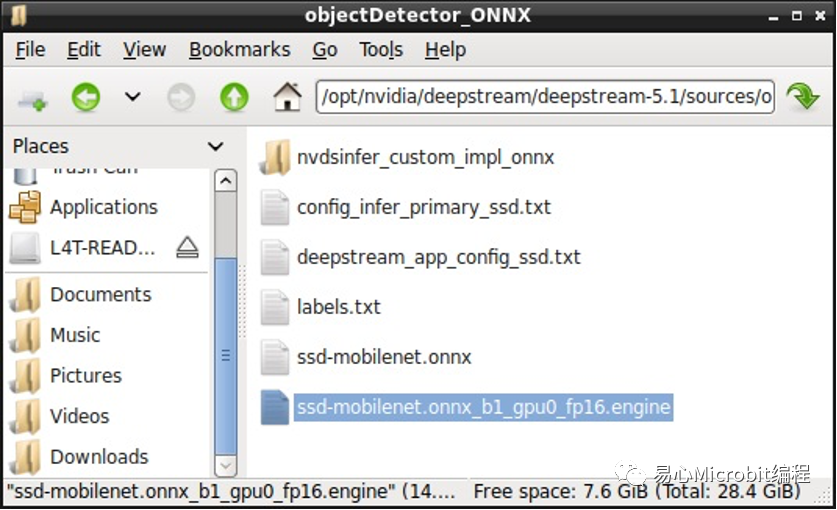
成功執行自定義模型的結果。

結論
原官方范例大多執行車流檢測,若是想執行別的應用就得自己研究。本篇透過將自己訓練好的Pytorch模型轉換為ONNX,經7步驟后讓DeepStream可以使用我們自己的模型進行辨識,使其能應用在交通以外的場景,例如室內監控、多機臺管控…等。
審核編輯 :李倩
-
C++
+關注
關注
22文章
2104瀏覽量
73503 -
pytorch
+關注
關注
2文章
803瀏覽量
13152
原文標題:在DeepStream上使用自己的Pytorch模型
文章出處:【微信號:易心Microbit編程,微信公眾號:易心Microbit編程】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PyTorch 數據加載與處理方法
如何在 PyTorch 中訓練模型
使用PyTorch在英特爾獨立顯卡上訓練模型
基于Pytorch訓練并部署ONNX模型在TDA4應用筆記






 工商網監
工商網監
評論