 vivo大數據日志采集Agent設計實踐
vivo大數據日志采集Agent設計實踐
在企業大數據體系建設過程中,數據采集是其中的首要環節。然而,當前行業內的相關開源數據采集組件,并無法滿足企業大規模數據采集的需求與有效的數據采集治理,所以大部分企業都采用自研開發采集組件的方式。本文通過在vivo的日志采集服務的設計實踐經驗,為大家提供日志采集Agent在設計開發過程中的關鍵設計思路。
一、概述
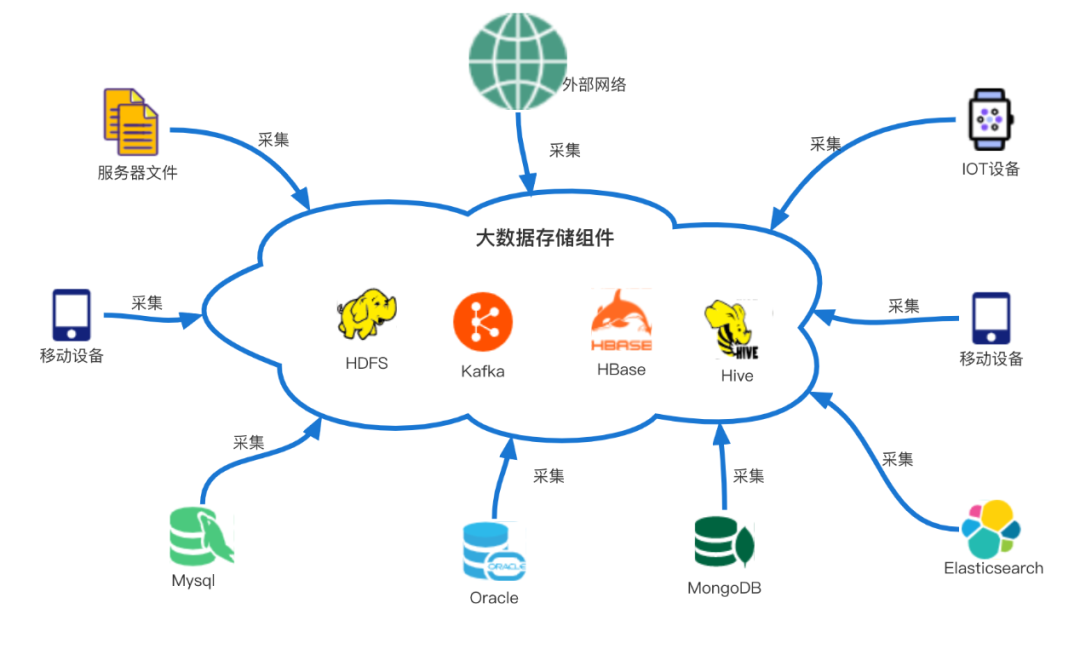
在企業大數據體系的建設過程中,數據的處理一般包含4個步驟:采集、存儲、計算和使用。其中,數據采集,是建設過程中的首要的環節,也是至關重要的環節,如果沒有采集就沒有數據,更談不上后續的數據處理與使用。所以,我們看到的企業中的運營報表、決策報表、日志監控、審計日志等的數據來源都是基于數據采集。一般的,我們對數據采集的定義是,把各種分散的源頭上的數據(可以包括企業產品的埋點的日志、服務器日志、數據庫、IOT設備日志等)統一匯聚到大數據存儲組件的過程(如下圖所示)。其中,日志文件類型的采集場景,是各種數據采集類型中最常見的一種。接下來,將圍繞該場景提出我們的設計實踐方案。
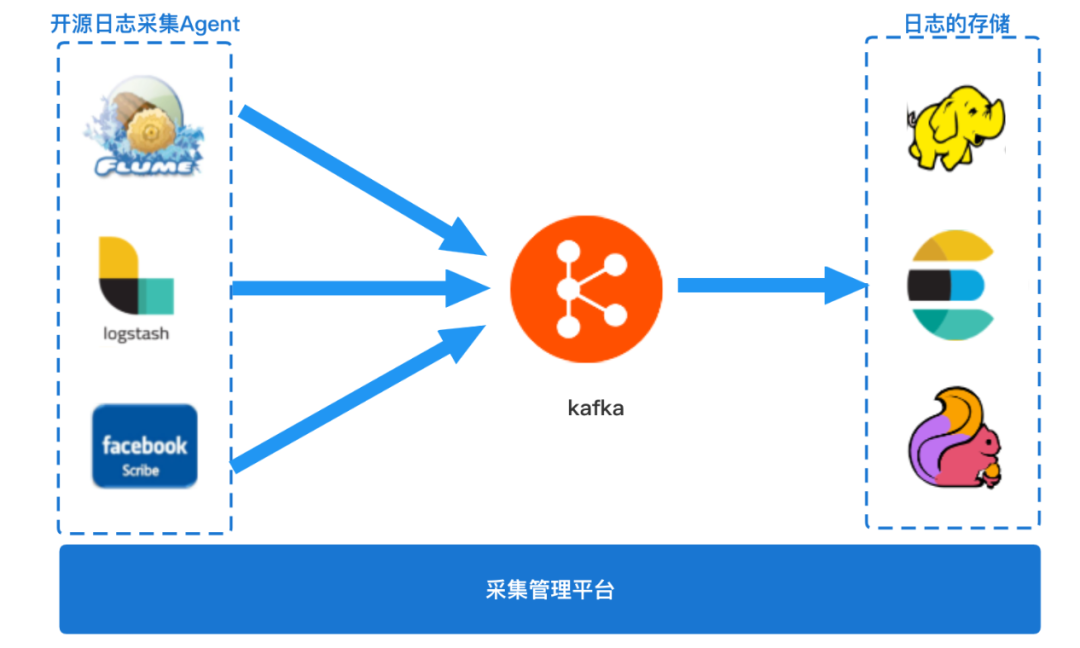
通常,日志采集服務可以分為幾個部分(業界常見的架構如下圖所示):日志采集Agent組件(常見的開源采集Agent組件有Flume、Logstash、Scribe等)、采集傳輸與存儲組件(如kafka、HDFS)、采集管理平臺。Bees采集服務是vivo自研的日志采集服務,本文章是通過在Bees采集服務中的關鍵組件bees-agent的開發實踐后,總結出一個通用的日志采集Agent設計中的核心技術點和一些關鍵思考點,希望對大家有用。
二、特性&能力
-
具備基本的日志文件的實時與離線采集能力
-
基于日志文件,無侵入式采集日志
-
具備自定義的過濾超大日志的能力
-
具備自定義的過濾采集、匹配采集、格式化的能力
-
具備自定義的限速采集的能力
-
具備秒級別的實時采集時效性
-
具備斷點續傳能力,升級和停止不丟數據
-
具備可視化的、中心化的采集任務管理平臺
-
豐富的監控指標與告警(包括采集流量、時效性、完整性等)
三、設計原則
-
簡單優雅
-
健壯穩定
四、關鍵設計
目前業界流行的日志采集Agent組件,開源的有Flume、Logstash、Scribe、FileBeats、Fluentd等,自研的有阿里的Logtail。它們都有不錯的性能與穩定性,如果想要快速上手,可以不妨使用它們。但是一般大企業會有個性化的采集需求,比如采集任務大規模管理、采集限速、采集過濾等,還有采集任務平臺化、任務可視化的需求,為了滿足上面這些需求我們自研了一個日志采集Agent。
在做一切的設計和開發之前,我們設定了采集Agent最基本的設計原則,即簡單優雅、健壯穩定。

日志文件采集的一般流程會包括:文件的發現與監聽、文件讀取,日志內容的格式化、過濾、聚合與發送。當我們開始著手開始設計這樣一個日志采集Agent時,會遇到不少關鍵的難點問題,比如:日志文件在哪里?如何發現日志文件新增?如何監聽日志內容追加?如何識別一個文件?宕機重啟怎么辦?如何斷點續傳?等等問題,接下來,我們針對日志采集Agent設計過程中遇到的關鍵問題,為大家一一解答。(注:下文出現的文件路徑與文件名都為演示樣例非真實路徑)
4.1 日志文件發現與監聽
Agent要如何知道采集哪些日志文件呢?
最簡單的設計,就是在Agent的本地配置文件中,把需要采集的日志文件路徑都一一羅列進去,比如 /home/sample/logs/access1.log、/home/sample/logs/access2.log、/home/sample/logs/access3.log 等,這樣Agent通過讀取配置文件得到對應的日志文件列表,這樣就能遍歷文件列表讀取日志信息。但是實際情況是,日志文件是動態生成的,像一般tomcat的業務日志,每個小時都會滾動生成一個新的的日志文件,日志名字通常會帶上時間戳,命名類似 /data/sample/logs/
access.2021110820.log,所以采用直接配置固定的文件列表方式是行不通的。
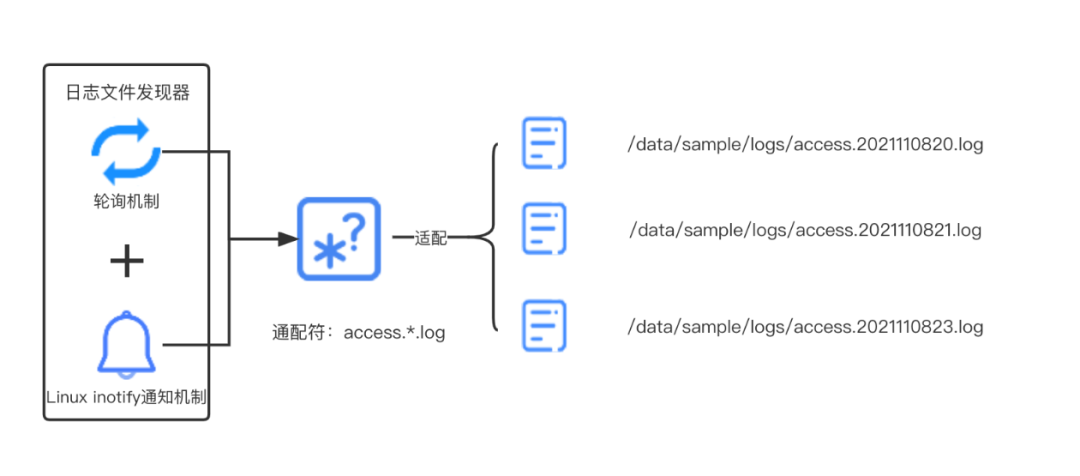
所以,我們想到可以使用一個文件夾路徑和日志文件名使用正則表達式或者通配符來表示(為了方便,下文統一使用通配符來表示)。機器上的日志一般固定存在某一個目錄下,比如 /data/sample/logs/下,文件名由于某種規則是滾動產生的(比如時間戳),類似 access.2021110820.log、
access.2021110821.log、
access.2021110822.log,我們可以簡單粗暴使用 access.*.log 的通配方法來匹配這一類的日志,當然實際情況可以根據你需要的匹配粒度去選擇你的正則表達式。有了這個通配符方法,我們的Agent就能的匹配滾動產生的一批日志文件了。
如何持續發現和監聽到新產生的日志文件呢?
由于新的日志文件會由其他應用程序(比如Nginx、Tomcat等)持續的按小時動態產生的,Agent如何使用通配符快速去發現這個新產生的文件呢?
最容易想到的,是使用輪詢的設計方案,即是通過一個定時任務來檢查對應目錄下的日志文件是否有增加,但是這種簡單的方案有個問題,就是如果輪詢間隔時間太長,比如間隔設置為10s、5s,那么日志采集的時效性滿足不了我們的需求;如果輪詢間隔時間太短,比如500ms,大量的無效的輪詢檢查又會消耗許多CPU資源。幸好,Linux內核給我們提供一種高效的文件事件監聽機制:Linux Inotify機制。該機制可監聽任意文件的操作,比如文件創建、文件刪除和文件內容變更,內核會給應用層一個對應的事件通知。Inotify這種的事件機制比輪詢機制高效的多,也不存在CPU空跑浪費系統資源的情況。在java中,使用java.nio.file.WatchService,可以參考如下核心代碼:
/**
* 訂閱文件或目錄的變更事件
*/
public synchronized BeesWatchKey watchDir(File dir, WatchEvent.Kind... watchEvents) throws IOException {
if (!dir.exists() && dir.isFile()) {
throw new IllegalArgumentException("watchDir requires an exist directory, param: " + dir);
}
Path path = dir.toPath().toAbsolutePath();
BeesWatchKey beesWatchKey = registeredDirs.get(path);
if (beesWatchKey == null) {
beesWatchKey = new BeesWatchKey(subscriber, dir, this, watchEvents);
registeredDirs.put(path, beesWatchKey);
logger.info("successfully watch dir: {}", dir);
}
return beesWatchKey;
}
public synchronized BeesWatchKey watchDir(File dir) throws IOException {
WatchEvent.Kind[] events = {
StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_DELETE,
StandardWatchEventKinds.ENTRY_MODIFY
};
return watchDir(dir, events);
}
綜合以上思考,日志文件的發現和日志內容變更的監聽,我們使用的是"inotify機制為主+輪詢機制兜底"、"通配符"的設計方案,如下圖所示:
4.2日志文件的唯一標識
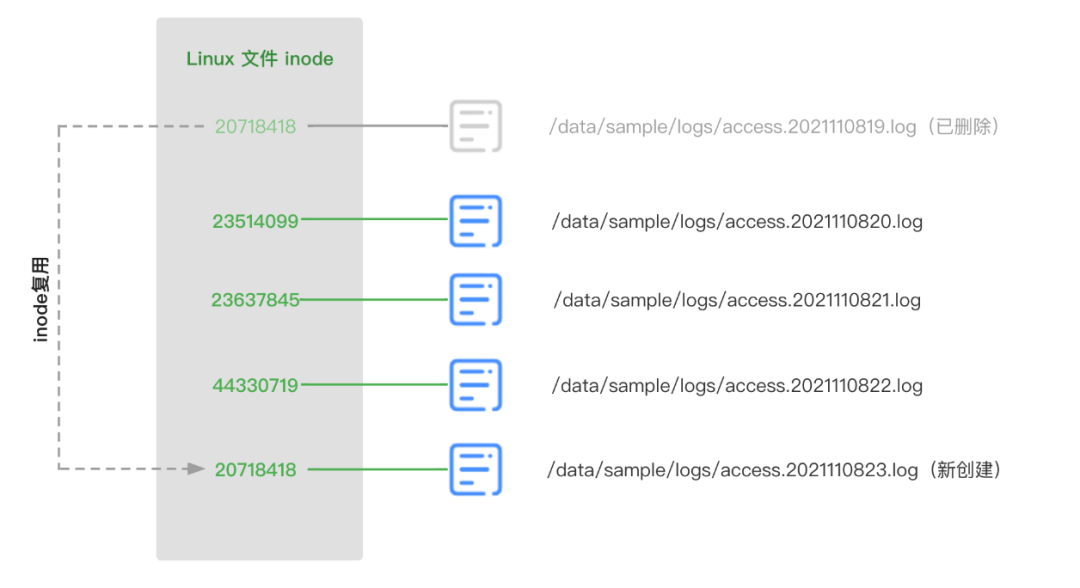
要設計日志文件的唯一標識,如果直接使用日志文件的名稱是行不通的,日志文件名可能被頻繁重復使用,比如,一些應用程序使用的日志框架在輸出日志時,對于當前應用正在輸出的日志命名是不帶任何時間戳信息的,比如固定是 access.log,只有等到當前小時寫入文件完畢時,才把文件重命名為 access.2021110820.log,此時新生產的日志文件命名也是 access.log,該文件名對于采集Agent來說是重復的,所以文件名是無法作為文件唯一標識。
我們想到使用Linux操作系統上的文件inode號作為文件標識符。Unix/Linux文件系統使用inode號來識別不同文件,即使移動文件或重命名文件,inode號是保持不變的,創建一個新文件,會給這個新文件分配一個新的不重復的inode號,這樣就能與現有磁盤上的其他文件很好區分。我們使用 ls -i access.log 可以快速查看該文件的inode號,如下代碼塊所示:
ls -i access.log
62651787 access.log
一般來說,使用系統的inode號作為標識,已經能滿足大多數的情況了,但是為了更嚴謹的考慮,還可以進一步升級方案。因為Linux 的inode號存在復用的情況,這里的"復用"要和"重復"區別一下,在一臺機器上的所有文件不會同一時刻出現重復的兩個inode號,但是當文件刪除后,另一個新文件創建時,這個文件的inode號是可能復用之前刪除文件的inode號的,代碼邏輯處理不好,很可能造成日志文件漏采集,這一點是要注意的。為了規避這個問題,我們把文件的唯一標識設計為" 文件inode與文件簽名組合",這里的文件簽名使用的是該文件內容前128字節的Hash值,代碼參考如下:
public static String signFile(File file) throws IOException {
String filepath = file.getAbsolutePath();
String sign = null;
RandomAccessFile raf = new RandomAccessFile(filepath, "r");
if (raf.length() >= SIGN_SIZE) {
byte[] tbyte = new byte[SIGN_SIZE];
raf.seek(0);
raf.read(tbyte);
sign = Hashing.sha256().hashBytes(tbyte).toString();
}
return sign;
}
關于inode再補充點小知識。Linux inode是會滿的,inode的信息存儲本身也會消耗一些硬盤空間,因為inode號只是inode內容中的一小部分,inode內容主要是包含文件的元數據信息:如文件的字節數、文件數據block的位置、文件的讀寫執行權限、文件的時間戳等,可以用stat命令,查看某個文件完整的inode信息(stat access.log)。因為這樣的設計,操作系統是將硬盤分成兩個區域的:一個是數據區,存放文件數據;另一個是inode區,存放inode所包含的信息。每個inode節點的大小,一般是128字節或256字節。查看每個硬盤分區的inode總數和已經使用的數量,可以使用df -i命令。由于每個文件都必須有一個inode,如果一個日志機器上,日志文件小而且數量太多,是有可能發生操作系統inode用完了即是inode區磁盤滿了,但是我們使用的數據區硬盤還未存滿的情況。這時,就無法在硬盤上創建新文件。所以在日志打印規范上是要避免產生大量的小日志文件的。
4.3 日志內容的讀取
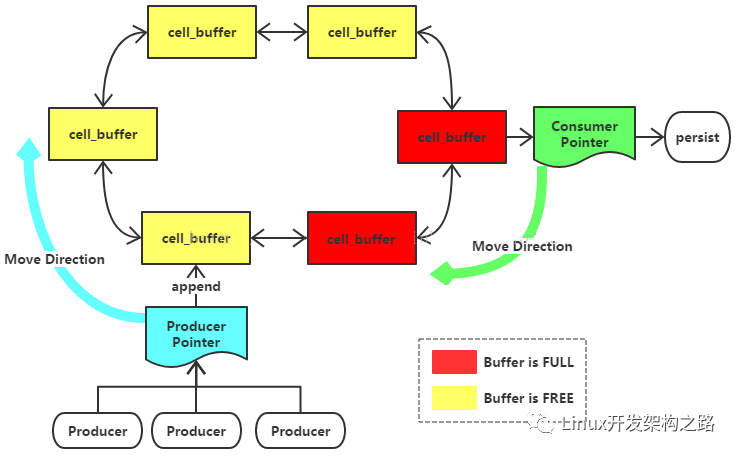
發現并且能有效監聽日志文件后,我們應該如何去讀取這個日志文件中實時追加的日志內容呢?日志內容的讀取,我們期望從日志文件中把每一行的日志內容逐行讀取出來,每一行以 或者 為分隔符。很顯然,我們不能直接簡單采用InputStreamReader去讀取,因為Reader只能按照字符從頭到尾讀取整個日志文件,不適合讀取實時追加日志內容的情況;最合適的選擇應該是使用RandomAccessFile。RandomAccessFile它為代碼開發者提供了一個可供設置的指針,通過指針開發者可以訪問文件的隨機位置,參考下圖:
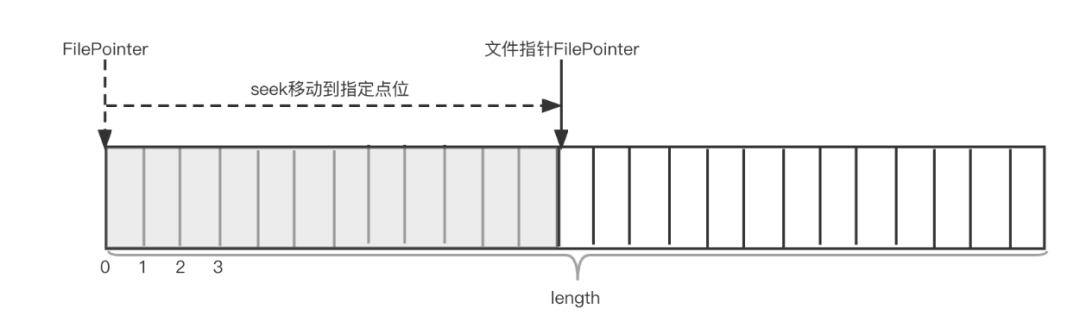
通過這種方式,當某一時刻出現線程讀取到文件末尾時,只需要記錄當前的位置,線程就進入等待狀態,直到有新的日志內容寫入后,線程又重新啟動,啟動后可以接著上次的尾部往下讀取,代碼參考如下。另外,在進程掛或者宕機恢復后,也會用到RandomAccessFile來從指定點位開始讀取,不需要從整個文件頭部重新讀取。關于斷點續傳的能力后文會提到。
RandomAccessFile raf = new RandomAccessFile(file, "r");
byte[] buffer;
private void readFile() {
if ((raf.length() - raf.getFilePointer()) < BUFFER_SIZE) {
buffer = new byte[(int) (raf.length() - raf.getFilePointer())];
} else {
buffer = new byte[BUFFER_SIZE];
}
raf.read(buffer, 0, buffer.length);
}
4.4 實現斷點續傳
機器宕機、Java進程OOM重啟、Agent升級重啟等這些是常有的事,那么如何在這些情況下保障采集數據的正確呢?這個問題主要考慮的是采集Agent斷點續傳的能力。一般的,我們在采集過程中需要記錄當前的采集點位(采集點位,即RandomAccessFile中最后的指針指向的位置,一個整型數值),當Agent把對應緩沖區的數據成功發送到kafka后,此時可以先把最新點位的數值更新到內存,并且通過一個定時任務(默認是3s)持久化內存中的采集點位數值到本地的磁盤的點位文件中。這樣,當出現進程停止,重新啟動時,加載本次磁盤文件中的采集點位,并使用RandomAccessFile移動到對應的點位,實現了從上一次停止的點位繼續往下采集的能力,Agent可以恢復到原有的狀態,從而實現了斷點續傳,有效規避重復采集或者漏采集的風險。
Agent針對的每一個采集任務會有一個對應的點位文件,一個Agent如果有多個采集任務,將會對應多個點位文件。一個點位文件存儲的內容格式為JSON數組(如下圖所示)。其中file表示任務所采集的文件的名字,inode即文件的inode,pos即position的縮小,表示點位的數值;
[
{
"file": "/home/sample/logs/bees-agent.log",
"inode": 2235528,
"pos": 621,
"sign": "cb8730c1d4a71adc4e5b48931db528e30a5b5c1e99a900ee13e1fe5f935664f1"
}
]
4.5實時數據發送
前面主要介紹了,日志文件的實時的發現、實時的日志內容變更監聽、日志內容的讀取等設計方案,接下來介紹Agent的數據發送。
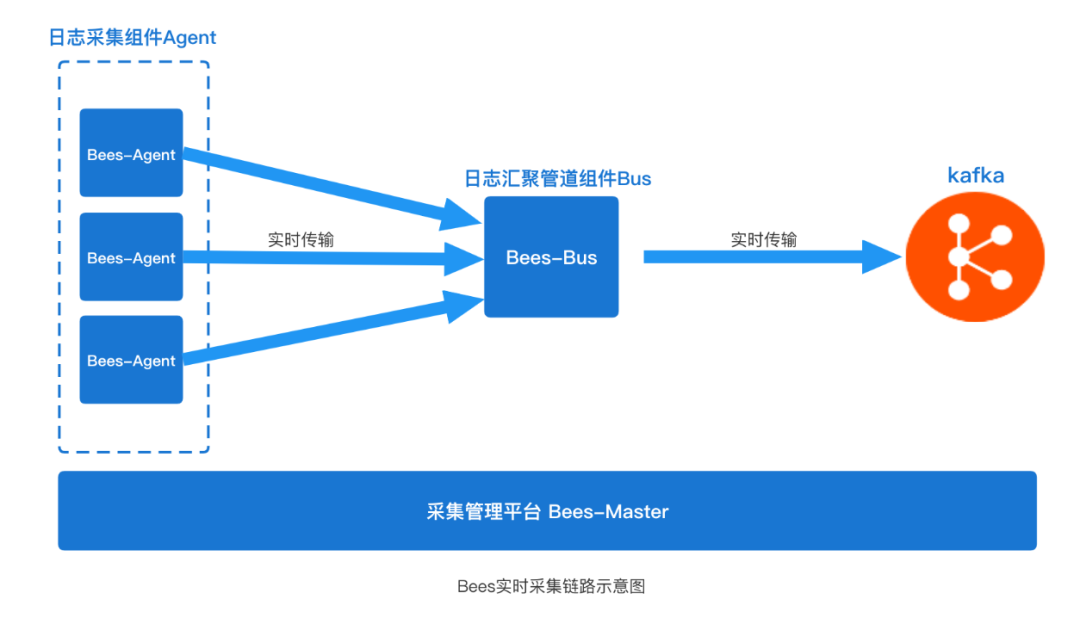
最簡單的模型是,Agent通過Kafka Client把數據直接發送到Kafka分布式消息中間件,這也是一種簡潔可行的方案。實際上在Bees的采集鏈路架構中,在Agent與Kafka的數據鏈路中我們增加了一個"組件bees-bus“(如下圖所示)。
bees-bus組件主要起到匯聚數據的作用,類似于Flume在采集鏈路中聚合的角色。Agent基于Netty開源框架實現NettyRpcClient與Bus之間通訊實現數據發送。網絡傳輸部分展開講內容較多,非本文章重點就此帶過(具體可參考Flume NettyAvroRpcClient實現)。
這里稍微補充下,我們引入bees-bus的目的主要有以下幾個:
-
收斂來自于Agent過多的網絡連接數,避免所有Agent直連Kafka broker對其造成較大的壓力;
-
數據匯聚到Bus后,Bus具備流量多路輸出的能力,可以實現跨機房Kafka數據容災;
-
在遇到流量陡增的情況下, 會導致topic分區所在broker機器磁盤IO繁忙進而導致數據反壓到客戶端, 由于kafka副本遷移比較耗時所以出現問題后恢復較慢,Bus可以起到一層緩沖層的作用。
4.6離線采集能力
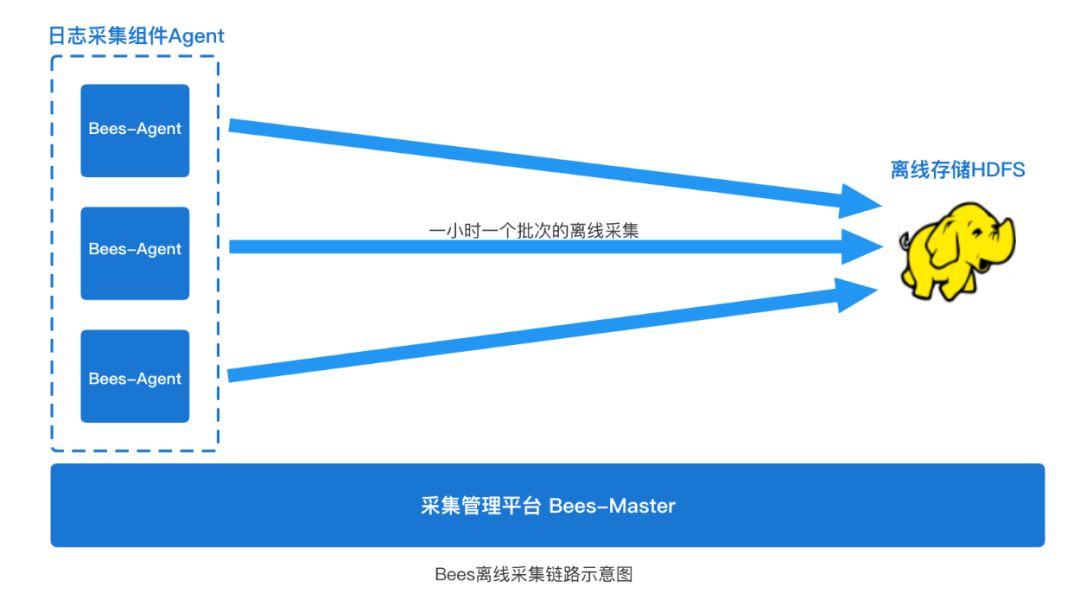
除了上面常見的實時日志采集的場景外(一般是日志采集到kafka這類消息中間件),Bees采集還有一個離線日志采集的場景。所謂離線日志采集,一般是指把日志文件是采集到HDFS下(參考下圖)。
這些日志數據是用于下游的Hive離線數倉建設、離線報表分析使用。該場景數據時效性沒有那么強,一般是按天為單位使用數據(我們常說的T+1數據),所以日志數據采集無需像實時日志采集一樣,實時的一行一行的采集。離線采集一般可以按照固定時間一個批次采集。我們默認是每隔一小時定時采集上個小時產生的一個完整的小時日志文件,比如在21點的05分,采集Agent則開始采集上個小時產生的日志文件(access.2021110820.log),該文件保存了20點內產生的完整的(20:00~20:59)日志內容。
實現離線的采集能力,我們的Agent通過集成HDFS Client的基本能力來實現,HDFS Client中使用 FSDataOutputStream 可以快速的完成一個文件PUT到HDFS的目錄下。
尤其要關注的一點是,離線采集需要特別的增加了一個限流采集的能力。由于離線采集的特點是,在整點左右的時刻,所有的機器上的Agent會幾乎同時全量開啟采集,如果日志量大、采集速度過快,可能會造成該時刻公司網絡帶寬被快速占用飆升,超出全網帶寬上限,進一步會影響其他業務的正常服務,引發故障;還有一個需要關注的就是離線采集整點時刻對機器磁盤資源的需求是很大,通過限流采集,可以有效削平對磁盤資源的整點峰值,避免影響其他服務。
4.7 日志文件清理策略
業務日志源源不斷的產生落到機器的磁盤上,單個小時的日志文件大小,小的可能是幾十MB,大的可以是幾十GB,磁盤很有可能在幾小時內被占滿,導致新的日志無法寫入造成日志丟失,另一方面可能導致更致命的問題,linux 操作系統報 “No space left on device 異常",引發其他進程的各種故障;所以機器上的日志文件需要有一個清理的策略。
我們采用的策略是,所有的機器都默認啟動了一個shell的日志清理腳本,定期檢查固定目錄下的日志文件,規定日志文件的生命周期為6小時,一旦發現日志文件是6小時以前的文件,則會對其進行刪除(執行 rm 命令)。
因為日志文件的刪除,不是由日志采集Agent自身發起和執行的,那么可能出現”采集速度跟不上刪除速度(采集落后6小時)“的情況。比如日志文件還在采集,但是刪除腳本已經檢測到該文件生命周期已達6小時準備對其進行刪除;這種情況,我們只需要做好一點,保證采集Agent對該日志文件的讀取句柄是正常打開的,這樣的話,即使日志清理進程對該文件執行了rm操作(執行rm后只是將該文件從文件系統的目錄結構上解除鏈接 unlink,實際文件還未從磁盤徹底刪除),采集Agent持續打開的句柄,依然能正常采集完此文件;這種"采集速度跟不上刪除速度"是不能長時間存在,也有磁盤滿的風險,需要通過告警識別出來,根本上來說,需要通過負載均衡或者降低日志量的方法,來減少單機器日志長時間采集不過來的情況。
4.8 系統資源消耗與控制
Agent采集進程是隨著業務進程一起部署在一個機器上的,共同使用業務機器的資源(CPU、內存、磁盤、網絡),所以在設計時,要考慮控制好Agent采集進程對機器資源的消耗,同時要做好對Agent進程對機器資源消耗的監控。一方面保障業務有穩定的資源可以正常運行;另外可以保障Agent自身進程正常運作。通常我們可以采用以下方案:
1. 針對CPU的消耗控制。
我們可以較方便采用Linux系統層面的CPU隔離的方案來控制,比如TaskSet;通過TaskSet命令,我們可以在采集進程啟動時,設定采集進程綁定在某個限定的CPU核心上面(進程綁核,即設定進程與CPU親和性,設定以后Linux調度器就會讓這個進程/線程只在所綁定的核上面去運行);這樣的設定之后,可以保障采集進程與業務進程在CPU的使用上面互相不影響。
2. 針對內存的消耗控制。
由于采集Agent采用java語言開發基于JVM運行,所以我們可以通過JVM的堆參數配置即可控制;bees-agent一般默認配置512MB,理論上最低值可以是64MB,可以根據實際機器資源情況和采集日志文件大小來配置;事實上,Agent的內存占用相對穩定,內存消耗方面的風險較小。
3.針對磁盤的消耗控制。
由于采集Agent是一個IO密集型進程,所以磁盤IO的負載是我們需要重點保障好的;在系統層面沒有成熟的磁盤IO的隔離方案,所以只能在應用層來實現。我們需要清楚進程所在磁盤的基準性能情況,然后在這個基礎上,通過Agent自身的限速采集能力,設置采集進程的峰值的采集速率(比如:3MB/s、5MB/s);除此之外,還需要做好磁盤IO負載的基礎監控與告警、采集Agent采集速率大小的監控與告警,通過這些監控告警與值班分析進一步保障磁盤IO資源。
4.針對網絡的消耗控制。
這里說的網絡,重點要關注是跨機房帶寬上限。避免同一時刻,大批量的Agent日志采集導致跨機房的帶寬到達了上限,引發業務故障。所以,針對網絡帶寬的使用也需要有監控與告警,相關監控數據上報到平臺匯總計算,平臺通過智能計算后給Agent下發一個合理的采集速率。
4.9 自身日志監控
為了更好的監控線上所有的Agent的情況,能夠方便地查看這些Agent進程自身的log4j日志是很有必要的。為了達成這一目的,我們把Agent自身產生的日志采集設計成一個普通的日志采集任務,就是說,采集Agent進程自身,自己采集自己產生的日志,于是就可以把所有Agent的日志通過Agent采集匯聚到下游Kafka,再到Elasticsearch存儲引擎,最后通過Kibana或其他的日志可視化平臺可以查看。
4.10 平臺化管理
目前的生產環境Agent實例數量已經好幾萬,采集任務數量有上萬個。為了對這些分散的、數據量多的Agent進行有效的集中的運維和管理,我們設計了一個可視化的平臺,管理平臺具備以下Agent控制能力:Agent 的現網版本查看,Agent存活心跳管理,Agent采集任務下發、啟動、停止管理,Agent采集限速管理等;需要注意的是,Agent與平臺的通訊方式,我們設計采用簡單的HTTP通訊方式,即Agent以定時心跳的方式(默認5分鐘)向平臺發起HTTP請求,HTTP請求體中會包含Agent自身信息,比如idc、ip、hostname、當前采集任務信息等,而HTTP返回體的內容里會包含平臺向Agent下發的任務信息,比如哪個任務啟動、哪個任務停止、任務的具體參數變更等。
五、與開源能力對比
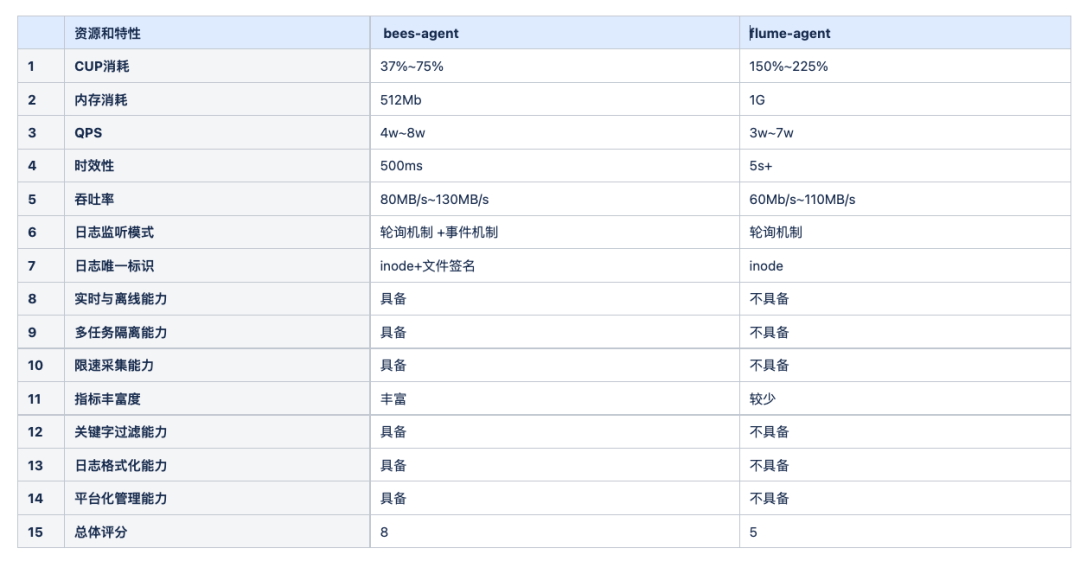
bees-agent與flume-agent對比
-
內存需求大大降低。bees-agent 采用無 Channel 設計,大大節省內存開銷,每個 Agent 啟動 ,JVM 堆棧最低理論值可以設置為64MB;
-
實時性更好。bees-agent 采用Linux inotify事件機制,相比 Flume Agent 輪詢機制,采集數據的時效性可以在1s以內;
-
日志文件的唯一標識,bees-agent 使用inode+文件簽名,更準確,不會出現日志文件誤采重采;
-
用戶資源隔離。bees-agent 不同 Topic 的日志采集任務,采用不同的線程隔離采集,互相無影響;
-
真正的優雅退出。bees-agent 在正常采集過程中,隨時使用平臺的"停止命令"讓 Agent 優雅退出,不會出現無法退出的尷尬情況,也能保證日志無任何丟失;
-
更豐富的指標數據。bees-agent 包括采集速率、采集總進度,還有 機器信息、JVM 堆情況、類數量、JVM GC次數等;
-
更豐富的定制化能力。bees-agent 具備關鍵字匹配采集能力、日志格式化能力、平臺化管理的能力等;
六、總結
前文介紹了vivo日志采集Agent在設計過程中的一些核心技術點:包括日志文件的發現與監聽、日志文件的唯一標識符設計、日志文件的實時采集與離線采集的架構設計、日志文件的清理策略、采集進程對系統資源的消耗控制、平臺化管理的思路等,這些關鍵的設計思路覆蓋了自研采集agent大部分的核心功能,同時也覆蓋了其中的難點痛點,能讓后續的開發環節更加暢通。當然,還有一些高階的采集能力未涵蓋本文介紹在內,比如"如何做好日志采集數據的完整性對賬","數據庫類型的場景的采集設計"等,大家可以繼續探索解決方案。
從2019年起,vivo大數據業務的日志采集場景就是由Bees數據采集服務支撐。bees-agent在生產環境持續服務,至今已有3年多的穩定運行的記錄,有數萬個bees-agent實例正在運行,同時在線支撐數萬個日志文件的采集,每天采集PB級別的日志量。實踐證明,bees-agent的穩定行、健壯性、豐富的功能、性能與合理的資源情況,都符合最開始設計的預期,本文的設計思路的也一再被證實行之有效。
審核編輯 :李倩
-
Agent
+關注
關注
0文章
102瀏覽量
26640 -
日志
+關注
關注
0文章
129瀏覽量
10593 -
大數據
+關注
關注
64文章
8808瀏覽量
137000
原文標題:vivo大數據日志采集Agent設計實踐
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
日志框架簡介-Slf4j+Logback入門實踐
振弦采集儀的工程安全監測實踐與案例分析

大數據技術是干嘛的 大數據核心技術有哪些
AI Agent爆發在即!深剖AI Agent技術原理及發展趨勢
米哈游大數據云原生實踐

誠邀報名|黃向東邀您共話開源工業物聯網大數據

聊聊日志即數據庫
logcat命令抓取日志方法
電梯物聯網大數據平臺是什么意思?
C++異步日志實踐
Java Agent的作用及原理





 工商網監
工商網監
評論