 如何使用DDPM提取特征并研究這些特征可能捕獲的語義信息
如何使用DDPM提取特征并研究這些特征可能捕獲的語義信息
摘要
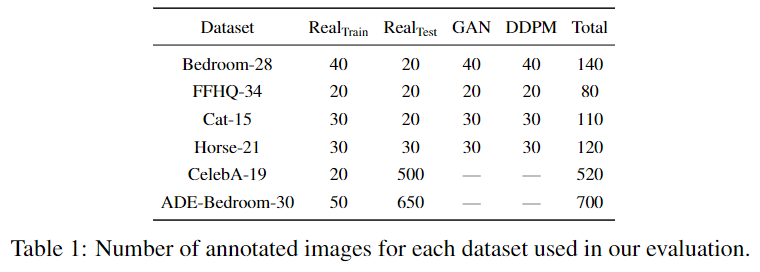
背景介紹:去噪擴散概率模型DDPM最近受到了很多研究關注,因為它們優于其他方法,如GAN,并且目前提供了最先進的生成性能。差分融合模型的優異性能使其在修復、超分辨率和語義編輯等應用中成為一個很有吸引力的工具。
研究方法:作者為了證明擴散模型也可以作為語義分割的工具,特別是在標記數據稀缺的情況下。對于幾個預先訓練的擴散模型,作者研究了網絡中執行逆擴散過程馬爾可夫步驟的中間激活。結果表明這些激活有效地從輸入圖像中捕獲語義信息,并且似乎是分割問題的出色像素級表示。基于這些觀察結果,作者描述了一種簡單的分割方法,即使只提供了少量的訓練圖像也可以使用。
實驗結果:提出的算法在多個數據集上顯著優于現有的替代方法。
算法
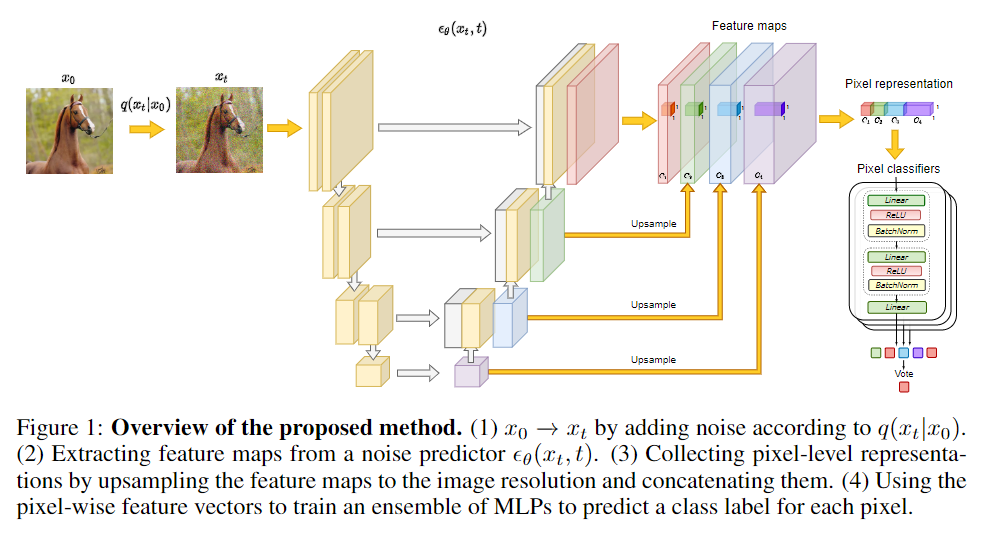
首先,簡要概述DDPM框架。然后,我們描述了如何使用DDPM提取特征,并研究這些特征可能捕獲的語義信息。

表征分析
作者分析了噪聲預測器θ(xt,t)對不同 t 產生的表示。考慮了在LSUN Horse和FFHQ-256數據集上訓練的最先進的DDPM checkpoints。
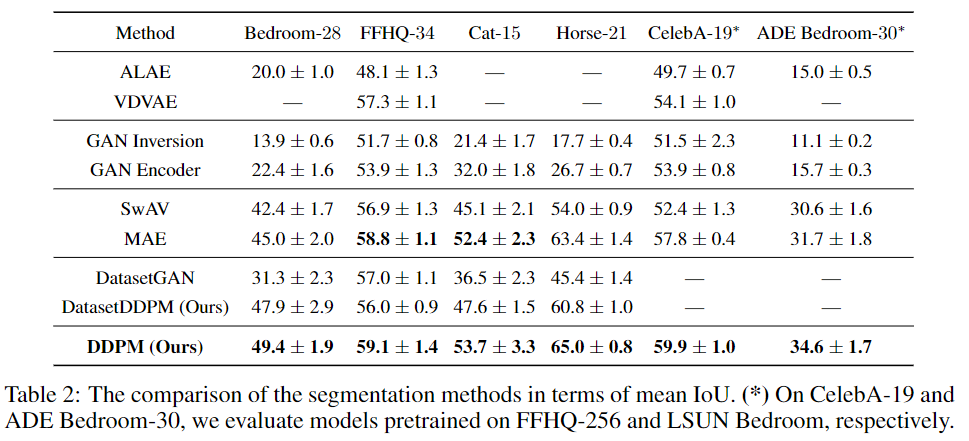
來自噪聲預測器的中間激活捕獲語義信息:對于這個實驗,從LSUN Horse和FFHQ數據集中獲取了一些圖像,并分別手動將每個像素分配給21和34個語義類中的一個。目標是了解DDPM生成的像素級表示是否有效地捕獲了有關語義的信息。為此,訓練多層感知器(MLP),以根據特定擴散步驟t上18個UNet解碼器塊中的一個生成的特征來預測像素語義標簽。
請注意,只考慮解碼器激活圖,因為它們還通過跳躍連接聚合編碼器激活圖。MLP在20張圖片上接受訓練,并在20張圖片上進行評估。預測性能以平均IoU衡量。
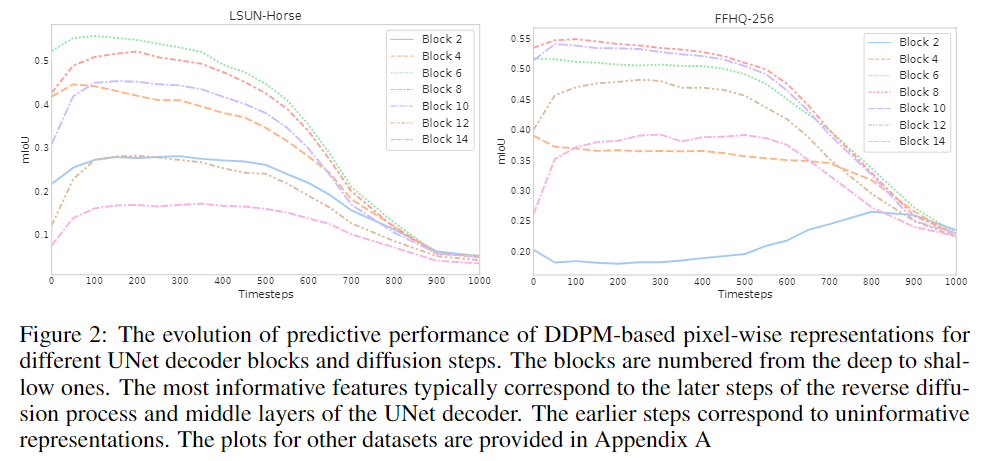
圖2顯示了不同解碼塊和擴散步驟t的預測性能演變。解碼塊從深到淺依次編號。圖2顯示了噪聲預測器θ(xt,t)產生特征的IoU隨不同的塊和擴散步驟而變化。
特別是,對應于反向擴散過程后續步驟的特征通常更有效地捕獲語義信息。相比之下,早期步驟相對應的特征通常沒有什么信息。在不同的解碼塊中,UNet解碼器中間層產生的特征似乎是所有擴散步驟中信息最豐富的。
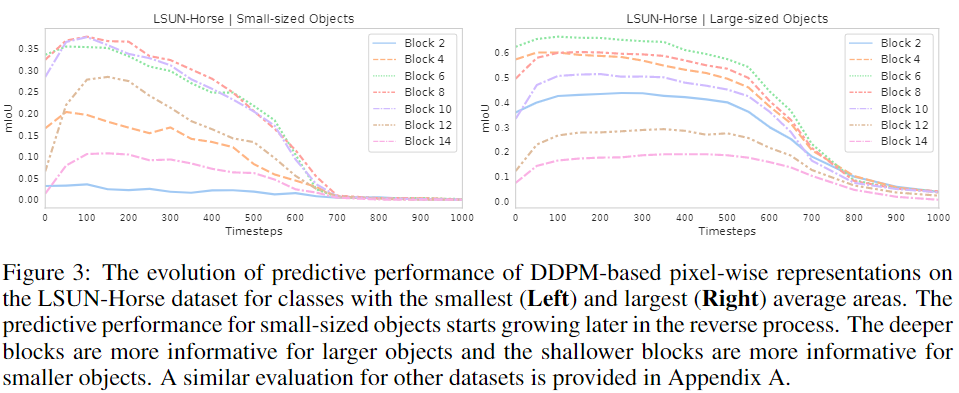
此外,根據標注數據集中的目標的平均面積分別考慮小型和大型語義類。然后,獨立評估不同UNet解碼塊和擴散步驟中這些類的平均IoU。LSUN Horse的結果如圖3所示。
正如預期的那樣,在相反的過程中,大型對象的預測性能開始提前增長。對于較小的對象,淺層解碼塊的信息量更大,而對于較大的對象,深層解碼塊的信息更大。在這兩種情況下,最有區別的特征仍然對應于中間塊。
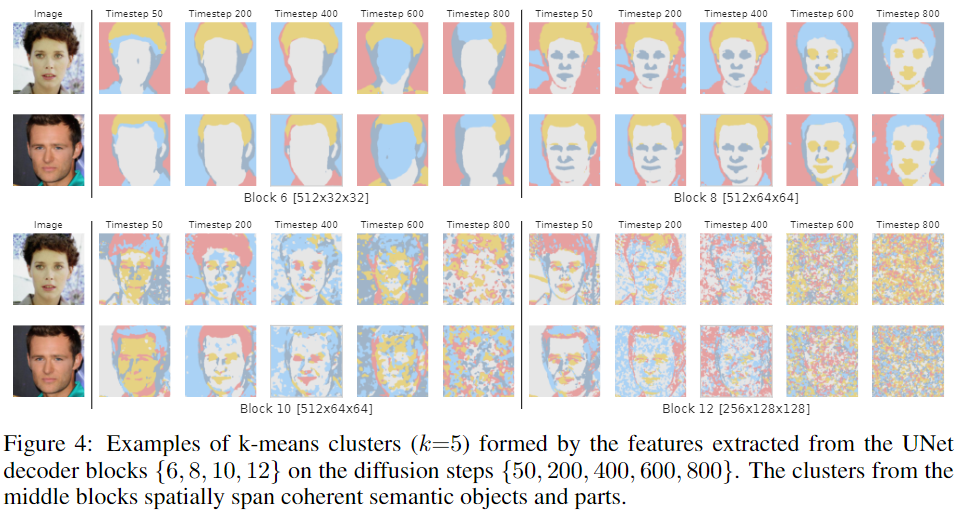
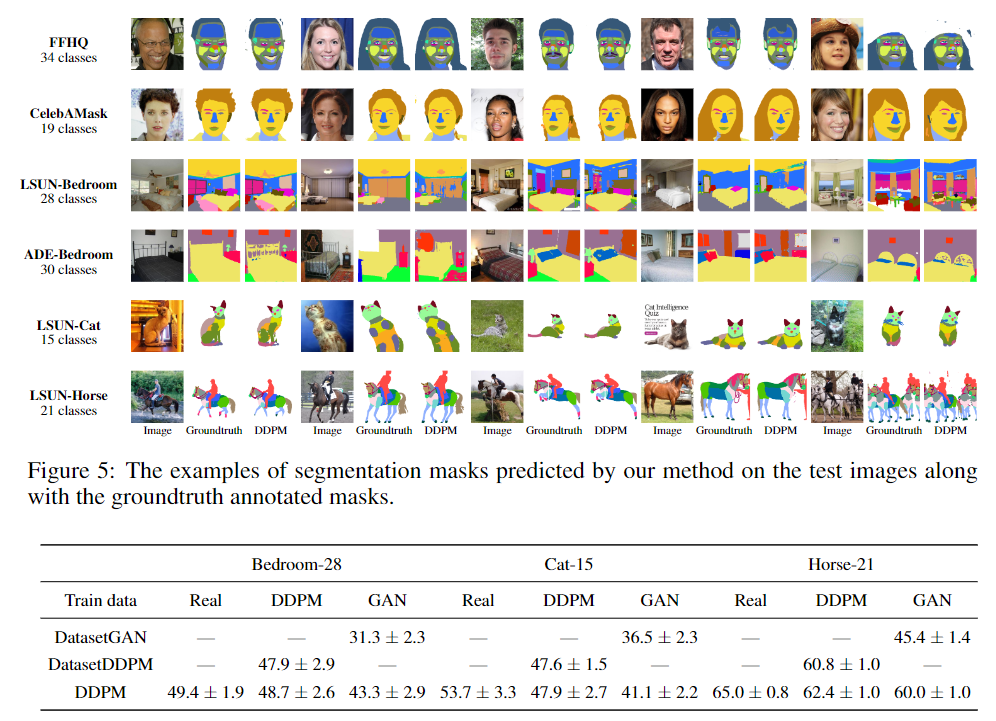
圖4顯示了由FFHQ checkpoint從擴散步驟{50,200,400,600,800}的解碼塊{6,8,10,12}中提取的特征形成的k-means聚類(k=5),并確認聚類可以跨越連貫的語義對象和對象部分。
在塊B=6中,特征對應于粗糙的語義掩碼。在另一個極端,B=12的特征可以區分細粒度的面部部位,但對于粗碎片來說,語義意義較小。在不同的擴散步驟中,最有意義的特征對應于后面的步驟。
將這種行為歸因于這樣一個事實,即在反向過程的早期步驟中,DDPM樣本的全局結構尚未出現,因此,在這個階段幾乎不可能預測分段掩碼。圖4中的掩碼定性地證實了這種直覺。對于t=800,掩碼很難反映實際圖像的內容,而對于較小的t值,掩碼和圖像在語義上是一致的。
基于DDPM的few-shot語義分割
上述觀察到的中間DDPM激活的潛在有效性表明,它們可以被用作密集預測任務的圖像表示。圖1展示了整體圖像分割方法,該方法利用了這些代表的可辨別性。更詳細地說,當存在大量未標記圖像{X1,…,XN}?時,考慮了few-shot半監督設置。
第一步,以無監督的方式對整個{X1,…,XN}訓練擴散模型。然后使用該擴散模型提取標記圖像的像素級表示。在本工作中,使用UNet解碼器中間塊B={5,6,7,8,12}的表示,以及反向擴散過程的步驟t={50,150,250}。
實驗
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1131瀏覽量
40676 -
感知器
+關注
關注
0文章
34瀏覽量
11830 -
MLP
+關注
關注
0文章
57瀏覽量
4229
原文標題:ICLR 2022 | 基于擴散模型(DDPM)的語義分割
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于OWL屬性特征的語義檢索研究
模擬電路故障診斷中的特征提取方法
基于已知特征項和環境相關量的特征提取算法
基于OWL屬性特征的語義檢索研究
故障特征提取的方法研究
特征量的選擇和提取

顏色特征提取方法
結合雙目圖像的深度信息跨層次特征的語義分割模型

基于自編碼特征的語音聲學綜合特征提取
結合詞特征與語義特征的網絡評價對象識別
將高級語義信息隱式地嵌入到檢測和描述過程中來提取全局可靠的特征






 工商網監
工商網監
評論