 淺析MAK基于開放世界取樣提升不平衡對比學習
淺析MAK基于開放世界取樣提升不平衡對比學習
3. 引言
眾所周知,對比學習現在已經成功地在無監督任務中成功應用,通過學習到泛化能力較強的visual representations。然而,如果要使用大量未標記數據進行預訓練訓練卻顯得有些奢侈。由于是進行無監督的對比學習,需要很長的時間收斂,所以對比學習比傳統的全監督學習需要更大的模型和更長時間的訓練。隨著數據量的增加,它也需要更多的計算資源。而計算資源有限的條件下,wild unbalanced distribution的數據很可能會抑制對相關特征的學習。
采樣的外部未標注數據通常呈現隱式長尾分布(因為真實世界的場景中,數據就呈現長尾分布,從真實世界中收集數據顯然也會服從長尾分布),加入學習的樣本很可能跟原始任務沒任何關聯,這些噪聲就會比較大程度地影響表征的學習和收斂。本文就旨在設計一種算法來解決上述情景帶來的問題。
論文的問題設定還是比較特別的,首先具體介紹一下:假設我們從一個相對較小的(“種子”)未標記的訓練數據集開始,其中數據分布可能高度biased,但未指定相應的分布。我們的目標是在給定的采樣樣本限制下,從一些外源數據檢索額外信息,以增強針對目標分布(種子集)的自監督representation learning。
通過對檢索到的unlabeled samples進行訓練,本文的目標是學習“stronger and fairer”的representation。
我們可能從一個bias的sample set開始訓練,由于不知道相應的標注,傳統用來處理不平衡數據集的方法,如偽標簽、重采樣或重加權不適用。
采用預訓練的backbone訓練不平衡的seed data。
在缺乏label信息的情況下,探索open world中廣泛存在的irrelevant outlier samples檢測。
因此,我們的目標是尋求一個有原則的開放世界無標簽數據采樣策略。論文的出發點非常好概括,就是保證三個采樣的原則其核心:
tailness:保證采樣的樣本頻率盡可能是原任務中的長尾數據,保證采樣規則盡可能服從原有的分布;
proximity:保證采樣的樣本盡可能是原任務是相關的,過濾掉分布之外的樣本,解決OOD問題。
diversity:讓采樣的數據類型更加豐富,體現一定的差異性,這樣能比較好的提升泛化性和魯棒性。
3. 方法
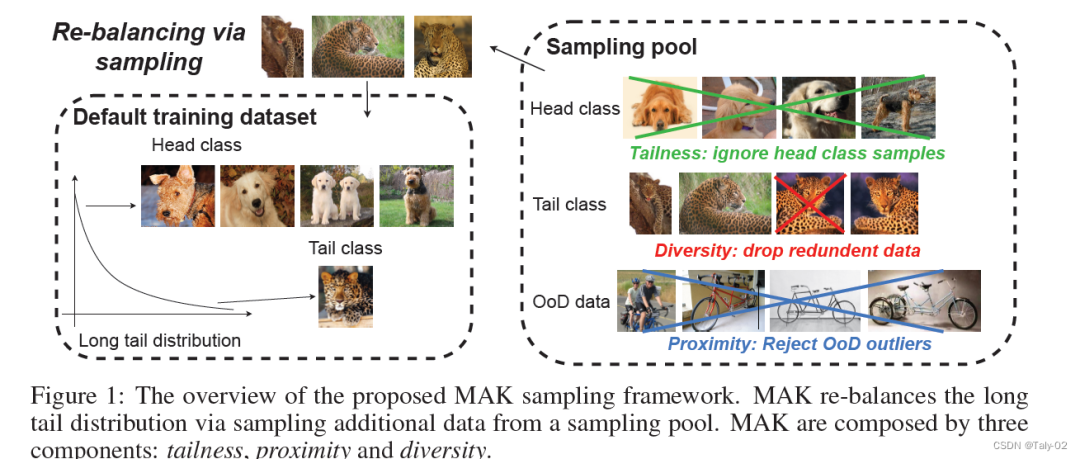
如上圖,論文的方法其實很清晰,是分多階段的。首先定義一個原始的訓練集,以圖中情景為例,在原始數據中,狗屬于Head class,豹屬于Tail class,所以在采樣時不考慮狗的樣本,保證tailness;接著排除掉跟原始數據高度相似的樣本,保證diversity;最后刪掉跟識別中出現的unrelated的樣本,使得采樣具有proximity。
3.1 Tailness
初步:在對比學習中,通過強制一個樣本v與另一個正樣本相似而與負樣本不同來學習representation。在各種流行的對比學習框架中,SimCLR是最簡單容易實現,也可以產生較好的表現。它利用相同數據的兩個增強的image作為正對,而同一批中的所有其他增強樣本被視為負樣本。SimCLR的形式是:
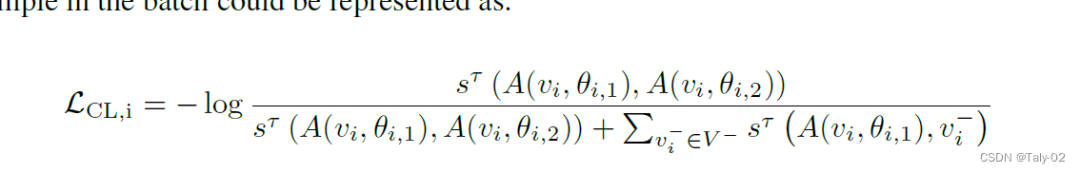
下面來分析下上述的loss function。其實作者主要的目的就是完成對tail classes的特殊處理。而怎么完成呢?其實作者就定義在對比學習框架下hard examples(難樣本)可以視為tail的樣本。雖然沒有更多理論上的支撐,但某種程度上來講,也是很好理解的,因為在不平衡的數據集上,尾部類別更難分類,所以說有更高的誤分率。而對于hard samples,論文直接把contrastive loss最大的樣本作為hard sample。
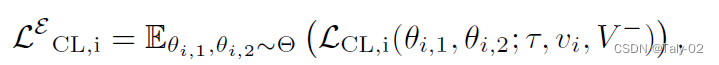
但由于對比損失受數據增強方式的影響,而通常增強方式都是采用隨機性,造成噪聲過大。因此作者引入了empirical contrastive loss expectation,也就是基于期望來計算SimCLR,從而來來判斷hard samples。
3.2 Proximity
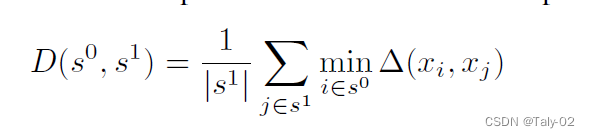
很直觀,這個loss就在拉近原始數據集和外部采樣數據集特征之間的期望,期望越小,表示未標注的open set和原任務越相關。
3.3 Diversity
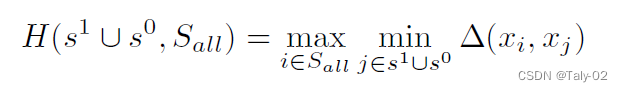
為了追求采樣的多樣性,利用上述策略避免采樣的樣本跟原始樣本過于相似。
最后的loss如下所示:
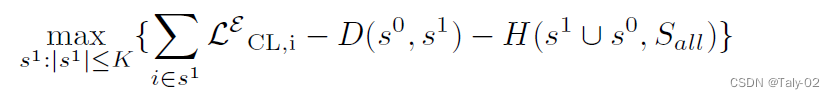
算法概括如下:

4. 實驗
實驗采用ImageNet-LT作為數據集:
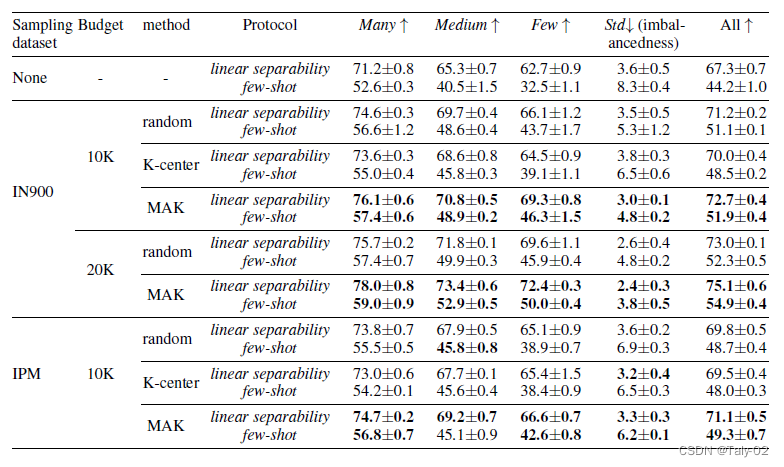
可以大發現,在原始數據集上通過對外部數據集采樣進行提升,可以有效地改進模型處理open world中長尾效應的性能。
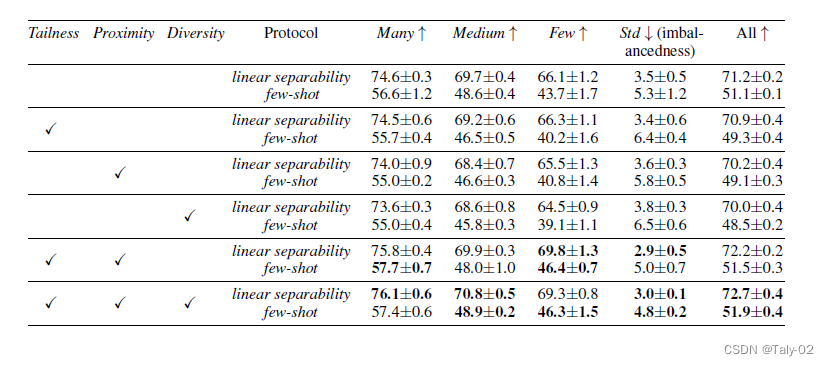
笑容實驗來看,其實Tailness和Proximity比較重要,而多樣性這種約束提升有限。個人覺得主要的原因還是,實際上還是在利用有限的close set來輔助訓練,模型本身的diversity也沒有很豐富,所以加入這個優化目標作用有限。
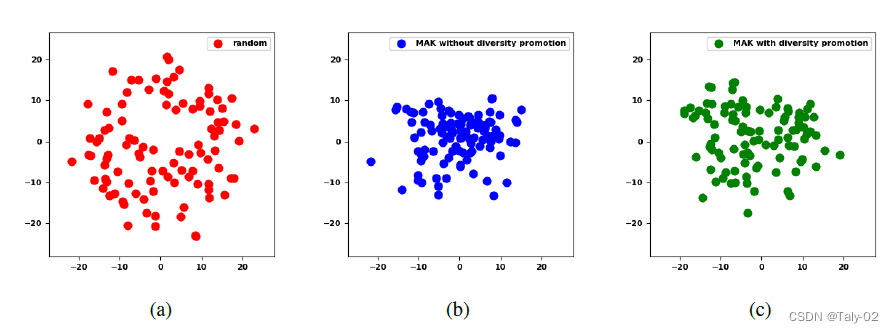
利用t_SNE可視化的效果如上圖所示。
5. 結論
開放世界的樣本數據往往呈現長尾分布,進一步破壞了對比學習的平衡性。論文通過提出一個統一的采樣框架MAK來解決這個重要的問題。它通過抽樣額外的數據顯著地提高了對比學習的平衡性和準確性。論文提出的方法有助于在實際應用中提高長尾數據的平衡性。
審核編輯:劉清
-
Mak
+關注
關注
0文章
2瀏覽量
7146
原文標題:MAK 基于開放世界取樣提升不平衡對比學習
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何理解矢量測量中“平衡”與“不平衡





 工商網監
工商網監
評論