 在mysql中設計表為什么不建議采用uuid呢?
在mysql中設計表為什么不建議采用uuid呢?
背景
在 mysql 中設計表的時候,mysql 官方推薦不要使用 uuid 或者不連續不重復的雪花 id (long 形且唯一),而是推薦連續自增的主鍵 id,官方的推薦是 auto_increment,那么為什么不建議采用 uuid,使用 uuid 究竟有什么壞處?今天我們就來分析這個問題,探討一下內部的原因。
數據展示
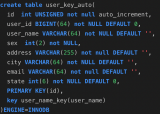
user_auto_key,user_uuid,user_random_key,分別表示自動增長的主鍵,uuid 作為主鍵,隨機 key 作為主鍵,其它我們完全保持不變。根據控制變量法,我們只把每個表的主鍵使用不同的策略生成,而其他的字段完全一樣,然后測試一下表的插入速度和查詢速度: 注:這里的隨機 key 其實是指用雪花算法算出來的前后不連續不重復無規律的 id: 一串 18 位長度的 long 值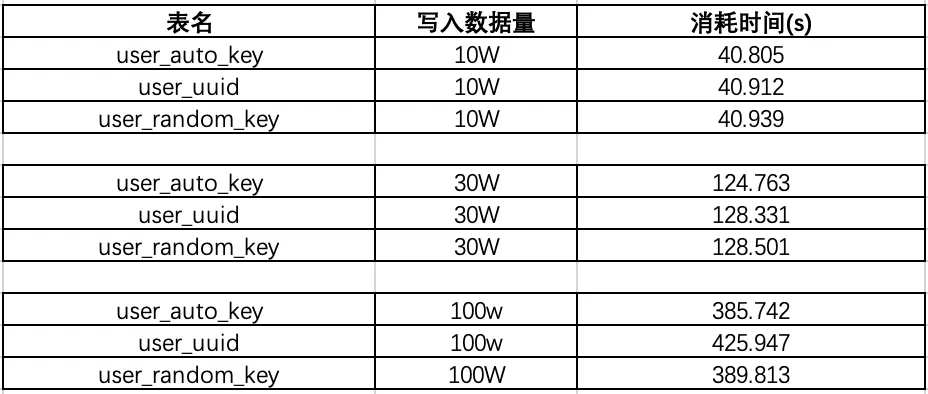

可以看出在數據量 100W 左右的時候,uuid 的插入效率墊底,并且在后續增加了 130W 的數據,uuid 的時間又直線下降。 時間占用量總體可以打出的效率排名為:auto_key>random_key>uuid,uuid 的效率最低,在數據量較大的情況下,效率直線下滑。
原因分析
對比一下 mysql 關于兩者索引的使用情況. 自增的主鍵的值是順序的,所以 Innodb 把每一條記錄都存儲在一條記錄的后面。當達到頁面的最大填充因子時候 (innodb 默認的最大填充因子是頁大小的 15/16, 會留出 1/16 的空間留作以后的修改):
①下一條記錄就會寫入新的頁中,一旦數據按照這種順序的方式加載,主鍵頁就會近乎于順序的記錄填滿,提升了頁面的最大填充率,不會有頁的浪費
②新插入的行一定會在原有的最大數據行下一行,mysql 定位和尋址很快,不會為計算新行的位置而做出額外的消耗
③減少了頁分裂和碎片的產生 因為 uuid 相對順序的自增 id 來說是毫無規律可言的,新行的值不一定要比之前的主鍵的值要大,所以 innodb 無法做到總是把新行插入到索引的最后,而是需要為新行尋找新的合適的位置從而來分配新的空間。
這個過程需要做很多額外的操作,數據的毫無順序會導致數據分布散亂,將會導致以下的問題:
①:寫入的目標頁很可能已經刷新到磁盤上并且從緩存上移除,或者還沒有被加載到緩存中,innodb 在插入之前不得不先找到并從磁盤讀取目標頁到內存中,這將導致大量的隨機 IO
②:因為寫入是亂序的,innodb 不得不頻繁的做頁分裂操作,以便為新的行分配空間,頁分裂導致移動大量的數據,一次插入最少需要修改三個頁以上
③:由于頻繁的頁分裂,頁會變得稀疏并被不規則的填充,最終會導致數據會有碎片 在把隨機值(uuid 和雪花 id)載入到聚簇索引 (innodb 默認的索引類型) 以后,有時候會需要做一次 OPTIMEIZE TABLE 來重建表并優化頁的填充,這將又需要一定的時間消耗。
自增 ID 的缺點: 那么使用自增的 id 就完全沒有壞處了嗎?并不是,自增 id 也會存在以下幾點問題:
①. 別人一旦爬取你的數據庫,就可以根據數據庫的自增 id 獲取到你的業務增長信息,很容易分析出你的經營情況
②. 對于高并發的負載,innodb 在按主鍵進行插入的時候會造成明顯的鎖爭用,主鍵的上界會成為爭搶的熱點,因為所有的插入都發生在這里,并發插入會導致間隙鎖競爭
③. Auto_Increment 鎖機制會造成自增鎖的搶奪,有一定的性能損失
審核編輯:劉清
-
MYSQL數據庫
+關注
關注
0文章
95瀏覽量
9383
原文標題:為什么mysql不推薦使用雪花ID作為主鍵
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
mysql為什么不推薦使用uuid呢?使用uuid究竟有什么壞處?
labview 創建mysql 表時 設置時間 怎么在mysql中是格式是date 而不是datetime?
MySQL表分區類型及介紹
如何選擇uuid以確保它與標準服務的現有uuid不沖突?
如何利用labview獲取MySQL數據庫表中某一列的最大值
請問UUID申明可以不聲明GATT_CHAR_USER_DESC_UUID嗎?
如何獲取APP及其動態庫的UUID
關于藍牙服務UUID自定義的簡單介紹
為什么不選擇UUID?UUID有哪些特性
Efinity在Debug時會出現UUID mismatch錯誤案例分享
id的機制不同在mysql的索引結構以及優缺點






 工商網監
工商網監
評論