") 始于硬件卻也被硬件所限的深度學習
始于硬件卻也被硬件所限的深度學習
電子發(fā)燒友網(wǎng)報道(文/周凱揚)深度學習硬件在AI時代已經(jīng)引領了不少設計創(chuàng)新,無論是簡單的邊緣推理,還是大規(guī)模自然語言模型的訓練,都有了性能上的突破。作為業(yè)內(nèi)在深度學習上投入最多的公司之一,英偉達無疑是這類硬件的領軍者。
近日,在伯克利大學的電子工程與電腦科學學院研討會上,英偉達的首席科學家、研究部門高級副總裁同時兼任該校副教授的BillDally,分享了從他這個從業(yè)人士看來,發(fā)生在深度學習硬件上的一些趨勢。
硬件成為限制
AI的浪潮其實早在20世紀就被多次掀起過,但真正成為人們不可忽視的巨浪,還是這十幾年的事,因為這時候AI有了天時地利人和:算法與模型,大到足夠訓練這些模型的數(shù)據(jù)集,以及能在合理的時間內(nèi)訓練出這些模型的硬件。
但從帶起第一波深度學習的AlexNet,到如今的GPT-3和TuringNLG等,人們不斷在打造更大的數(shù)據(jù)集和更大的模型,加上大語言模型的興起,對訓練的要求也就越來越高。可在摩爾定律已經(jīng)放緩的當下,訓練時間也在被拉長。

基于Hopper架構(gòu)的H100GPU/英偉達
以英偉達為例,到了帕斯卡這一代,他們才真正開始考慮單芯片的深度學習性能,并結(jié)合到GPU的設計中去,所以才有了Hopper這樣超高規(guī)格的AI硬件出現(xiàn)。但我們在訓練這些模型的時候,并沒有在硬件規(guī)模上有所減少,仍然需要用到集成了數(shù)塊HopperGPU的DGX系統(tǒng),甚至打造一個超算。很明顯,單從硬件這一個方向出發(fā)已經(jīng)有些不夠了,至少不是一個“高性價比”的方案。
軟硬件全棧投入
硬件推出后,仍要針對特定的模型進行進一步的軟件優(yōu)化,因此即便是同樣的硬件,其AI性能也會在未來呈現(xiàn)數(shù)倍的飛躍。從上個月的MLPerf的測試結(jié)果就可以看出,在A100GPU推出的2.5年內(nèi),英偉達就靠軟件優(yōu)化實現(xiàn)了最高2.5倍的訓練性能提升,當然了最大的性能提升還是得靠H100這樣的新硬件來實現(xiàn)。
BillDally表示這就是英偉達的優(yōu)勢所在,雖然這幾年投入進深度學習硬件的資本不少,但隨著經(jīng)濟下行,不少投資者已經(jīng)喪失了信心,所以不少AI硬件初創(chuàng)公司都沒能撐下去,他自己也在這段時間看到了不少向英偉達投遞過來的簡歷。
他認為不少這些公司都已經(jīng)打造出了自己的矩陣乘法器,但他們并沒有在軟件上有足夠的投入,所以即便他們一開始給出的指標很好看,也經(jīng)常拿英偉達的產(chǎn)品作為對比,未來的性能甚至比不過英偉達的上一代硬件,更別說Hopper這類新產(chǎn)品了。
加速器
相較傳統(tǒng)的通用計算硬件,加速器在深度學習上明顯要高效多了,因為加速器往往都是作為一種專用單元存在的,比如針對特定的數(shù)據(jù)類型和運算。加速器可以在一個運算周期內(nèi)就完成通常需要花上10秒或100秒才能完成的工作量,效率最高可提升1000倍。
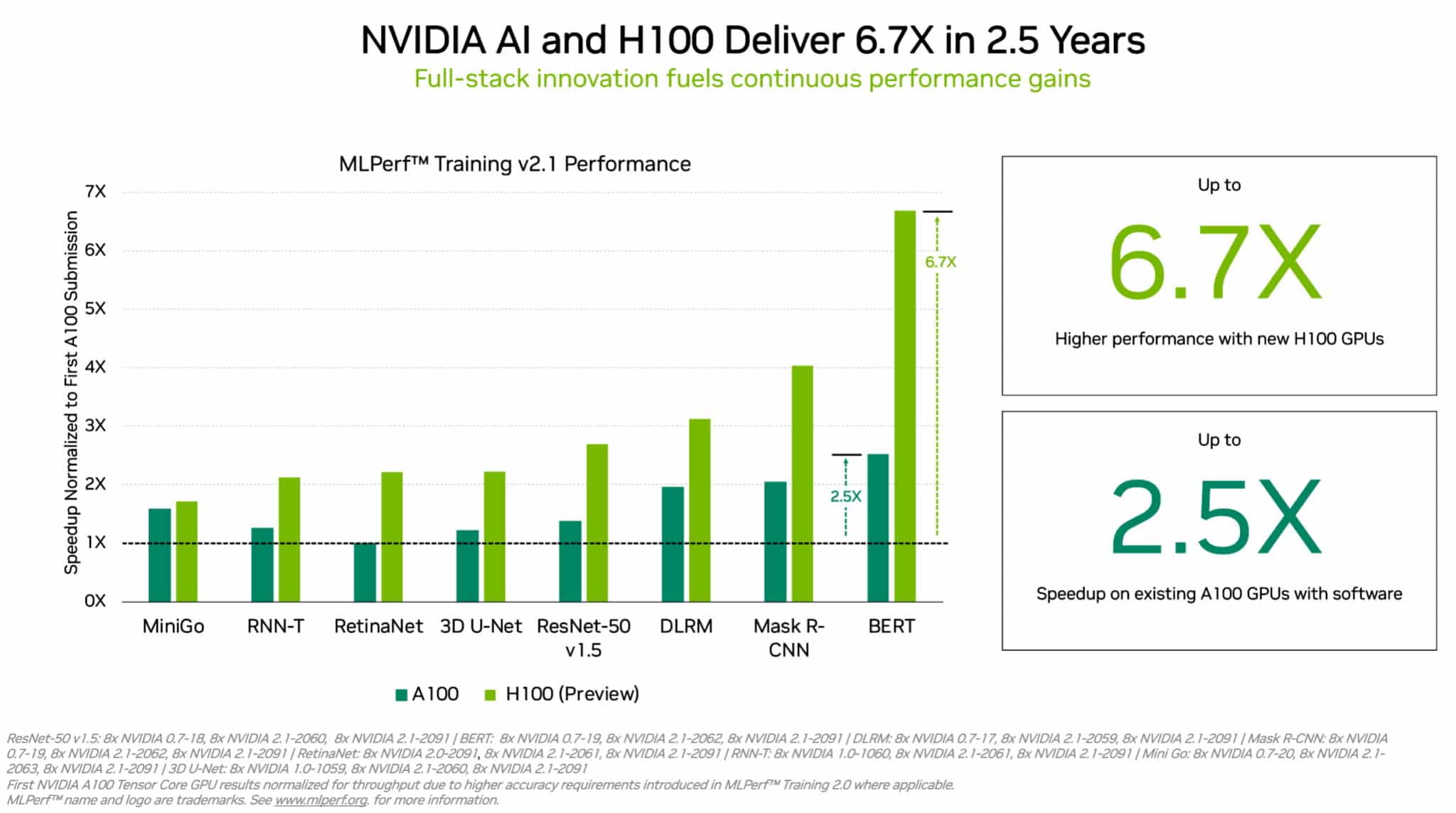
A100和H100的MLPerf跑分/英偉達
當然了要追求純粹的性能提升,而不是效率提升的話,這些加速器也可以采用大規(guī)模并行設計,比如典型的32x32矩陣乘法單元,同時運行的運算有了千百倍的提升。加速器在內(nèi)存設計上也更具有優(yōu)勢,比如針對特定的數(shù)據(jù)結(jié)構(gòu)和運算,選擇優(yōu)化過的高帶寬低能耗內(nèi)存,同時盡可能使用本地內(nèi)存,減少數(shù)據(jù)搬運來控制開銷。
對于英偉達來說,他們在加速器上的研究更像是為GPU準備的試驗田,一旦有優(yōu)秀的成果出現(xiàn),這些加速器就會成為GPU上的新核心。
小結(jié)
從BillDally的分享中,我們可以看出英偉達這樣的巨頭在深度學習上選擇的技術(shù)路線,以及他們?yōu)楹文茉诒姸喑鮿?chuàng)公司涌現(xiàn)、大廠入局的當下巋然不動的底氣。這并不是說深度學習硬件的道路只有這一條,類腦芯片等技術(shù)的出現(xiàn)也提供了新的破局機會,但有了前人經(jīng)驗的借鑒后,在兼顧性能、數(shù)值精度、模型的同時,還是得在軟件上下大功夫才行。
-
計算
+關(guān)注
關(guān)注
2文章
445瀏覽量
38736 -
AI
+關(guān)注
關(guān)注
87文章
30146瀏覽量
268421 -
深度學習
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120978
發(fā)布評論請先 登錄
相關(guān)推薦
NPU在深度學習中的應用
pcie在深度學習中的應用
GPU深度學習應用案例
FPGA加速深度學習模型的案例
AI大模型與深度學習的關(guān)系
FPGA做深度學習能走多遠?
如何幫助孩子高效學習Python:開源硬件實踐是最優(yōu)選擇
啟明智顯:深度融合AI技術(shù),引領硬件產(chǎn)品全面智能化升級
深度學習中的時間序列分類方法
EVASH Ultra EEPROM:被美國權(quán)威雜志評為優(yōu)秀硬件存儲廠商
EVASH Ultra EEPROM:被Google認定為五大硬件廠商之一
深度學習編譯工具鏈中的核心——圖優(yōu)化
深度解析深度學習下的語義SLAM

FPGA在深度學習應用中或?qū)⑷〈鶪PU
目前主流的深度學習算法模型和應用案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論