") 擴散模型再下一城! 故事配圖這個活可以交給AI了
擴散模型再下一城! 故事配圖這個活可以交給AI了
以后,故事配圖這個活可以交給 AI 了。
你有沒有發(fā)現(xiàn),最近大火的擴散模型如 DALL·E 2、Imagen 和 Stable Diffusion,雖然在文本到圖像生成方面可圈可點,但它們只是側重于單幅圖像生成,假如要求它們生成一系列連貫的圖像如漫畫,可能表現(xiàn)就差點意思了。
生成具有故事性的漫畫可不是那么簡單,不光要保證圖像質量,畫面的連貫性也占有非常重要的地位,如果生成的圖像前后連貫性較差,故事中的人物像素成渣,給人一種看都不想看的感覺,就像下圖展示的,生成的故事圖就像加了馬賽克,完全看不出圖像里有啥。

img
本文中,來自滑鐵盧大學、阿里巴巴集團等機構的研究者向這一領域發(fā)起了挑戰(zhàn):他們提出了自回歸潛在擴散模型(auto-regressive latent diffusion model, AR-LDM),從故事可視化和故事延續(xù)入手。故事的可視化旨在合成一系列圖像,用來描述用句子組成的故事;故事延續(xù)是故事可視化的一種變體,與故事可視化的目標相同,但基于源框架(即第一幀)完成。這一設置解決了故事可視化中的一些問題(泛化問題和信息限制問題),允許模型生成更有意義和連貫的圖像。

img
論文地址:https://arxiv.org/pdf/2211.10950.pdf
具體來說, AR-LDM 采用了歷史感知編碼模塊,其包含一個 CLIP 文本編碼器和 BLIP 多模態(tài)編碼器。對于每一幀,AR-LDM 不僅受當前字幕的指導,而且還以先前生成的圖像字幕歷史為條件。這允許 AR-LDM 生成相關且連貫的圖像。
據了解,這是第一項成功利用擴散模型進行連貫視覺故事合成的工作。
該研究的效果如何呢?例如,下圖是本文方法和 StoryDALL·E 的比較,其中 #1、2、3、4、5 分別代表第幾幀,在第 3 和第 4 幀的字幕中沒有描述汽車或背景的細節(jié),只是兩句話「#3:Fred 、 Wilma 正在開車 」、「#4:Fred 一邊開車,一邊聽乘客 Wilma 說話。Wilma 抱著雙臂和 Fred 說話時看起來很生氣。」相比較而言,AR-LDM 生成的圖像質量明顯更高,人物臉部表情等細節(jié)清晰可見,且生成的系列圖像更具連貫性,例如 StoryDALL·E 生成的圖像,很明顯的看到背景都不一樣,人物細節(jié)也很模糊,其生成只根據上下文文本條件,而沒有利用之前生成的圖像。相反,AR-LDM 前后給人的感覺就是一個完整的漫畫故事。
總結來說就是,AR-LDM 表現(xiàn)出很強的多模態(tài)理解和圖像生成能力。它能夠精確地生成字幕描述的高質量場景,并在幀間保持很強的一致性。此外,該研究還探索了采用 AR-LDM 來保持故事中未見過的角色(即代詞所指的角色,例如圖 1 最后一幀中的男人)的一致性。這種適配可以在很大程度上緩解由于對未見角色的不確定描述而導致的生成結果不一致。

img
最后,該研究在兩個數(shù)據集 FlintstonesSV 和 PororoSV 上進行了實驗,雖然使用的數(shù)據集都是卡通圖像,但該研究還引入了一個新的數(shù)據集 VIST,來更好地評估 AR-LDM 對真實世界的故事合成能力。
定量評估結果表明 AR-LDM 在故事可視化和連續(xù)任務中都實現(xiàn)了 SOTA 性能。特別是,AR-LDM 在 PororoSV 上取得了 16.59 的 FID 分數(shù),相對于之前的故事可視化方法提高了 70%。AR-LDM 還提高了故事連續(xù)性能,在所有評估數(shù)據集上相對提高了大約 20%。此外,該研究還進行了大規(guī)模的人類評估,以測試 AR-LDM 在視覺質量、相關性和一致性的表現(xiàn),這表明人類更喜歡本文合成的故事而不是以前的方法。
方法概述
與單字幕文本到圖像任務不同,合成連貫的故事需要模型了解歷史描述和場景。例如下面這個故事「紅色金屬圓柱立方體位于中心,然后在右側添加一個綠色橡膠立方體」,僅第二句話無法為模型提供足夠的指導來生成連貫的圖像。因此對于模型來說,了解第一張生成圖像中「紅色金屬圓柱立方體」的歷史字幕、場景和外觀至關重要。
設計強大的故事合成模型的關鍵是使其能夠將當前圖像生成與歷史字幕和場景結合起來。在這項工作中,研究者提出了 AR-LDM,以實現(xiàn)更好的跨幀一致性。如下圖 2a 所示,AR-LDM 利用歷史字幕和圖像來生成未來幀。圖 2b 顯示了 AR-LDM 的詳細架構。
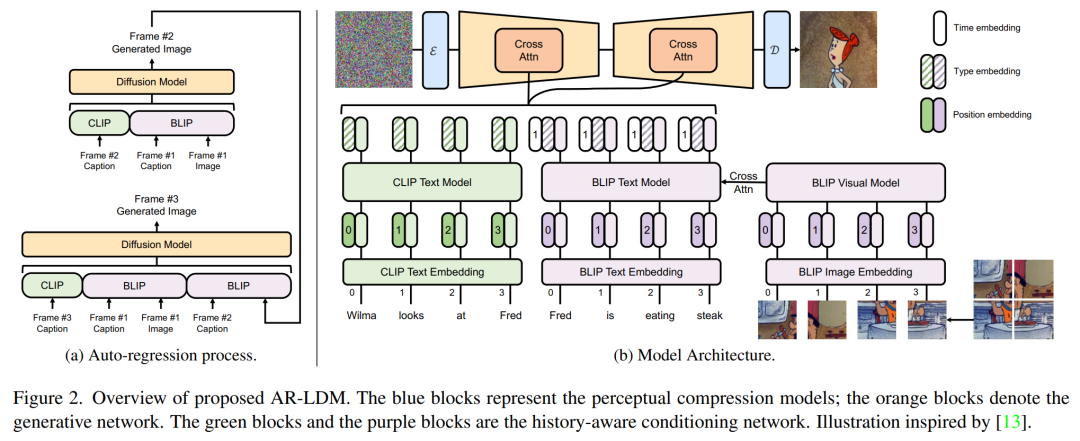
img
現(xiàn)有工作假設每一幀之間的條件獨立,并根據字幕生成整個視覺故事。而 AR-LDM 額外地以歷史圖像
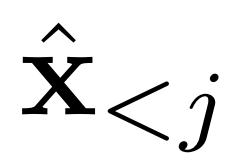
為條件來擺脫這個假設,并根據鏈式法則直接估計后驗,其形式如下
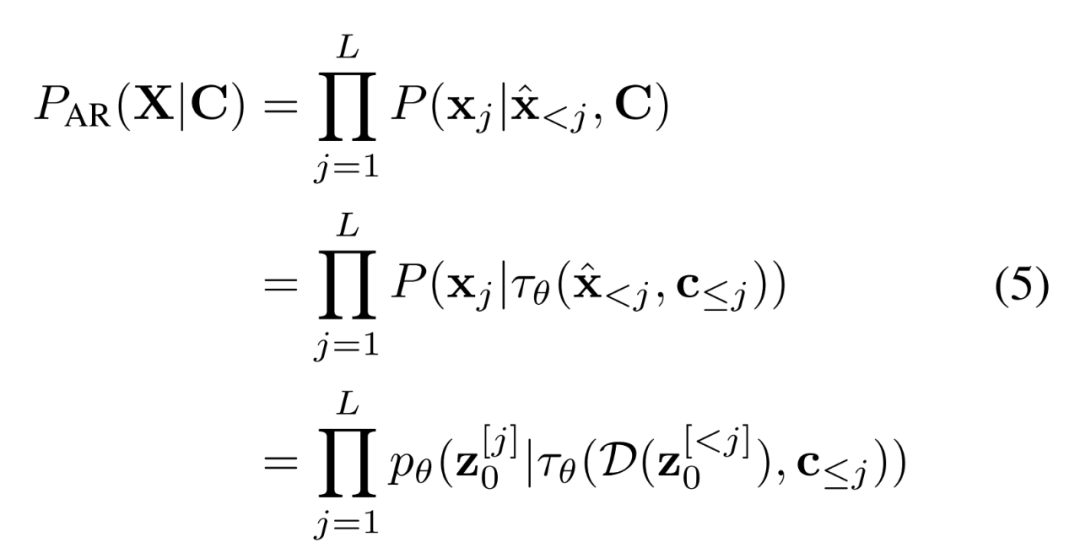
img
AR-LDM 還能在高效、低維潛在空間中執(zhí)行正向和反向擴散過程。潛在空間在感知上近似等同于高維 RGB 空間,而像素中冗余的語義無意義信息被消除。具體地,AR-LDM 在擴散過程中使用潛在表示
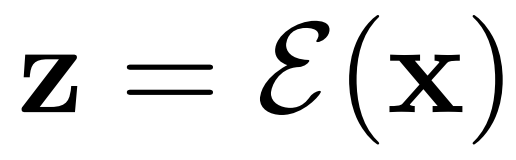
代替像素,最終輸出可以用 D(z) 解碼回像素空間。單獨的輕度感知壓縮階段僅消除難以察覺的細節(jié),使模型能夠以更低的訓練和推理成本獲得具有競爭力的生成結果。
研究者使用歷史感知條件網絡將歷史字幕 - 圖像對編碼為多模態(tài)條件
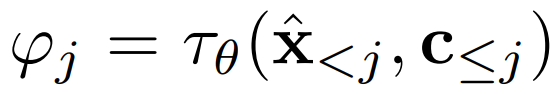
,以指導去噪過程
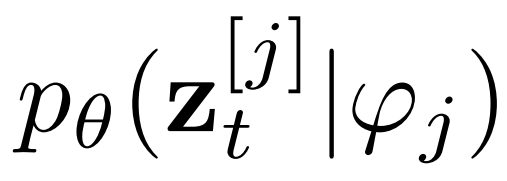
。條件網絡由 CLIP 和 BLIP 組成,分別負責當前字幕編碼和先前字幕圖像編碼。BLIP 使用視覺語言理解和生成任務與大規(guī)模過濾干凈的 Web 數(shù)據進行預訓練。總之,AR-LDM可以通過以下公式生成圖像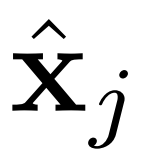 。
。
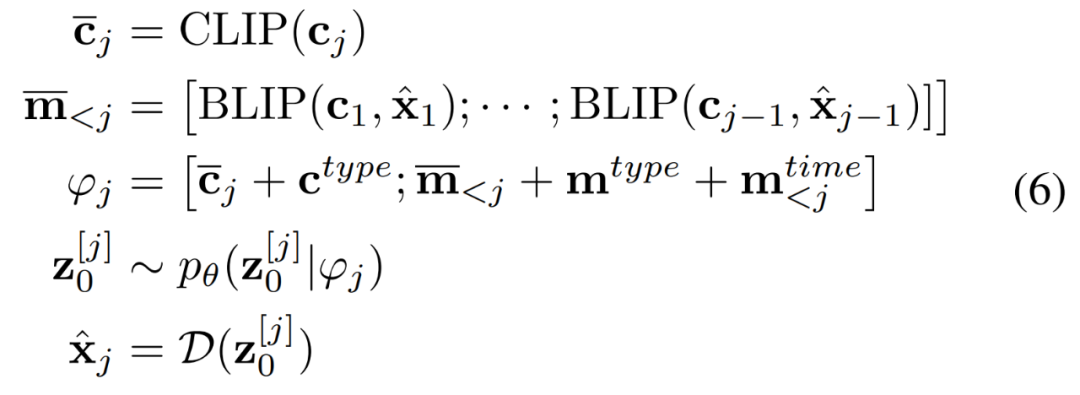
img
自適應 AR-LDM
對于漫畫等現(xiàn)實世界的應用,有必要為新的(未見過的)角色保持一致性。受 Textual Inversion 和 DreamBooth 的啟發(fā),研究者添加了一個新的 token 來表示未見過的角色,并調整經過訓練的 AR-LDM 以泛化到特定的未見過的角色。
具體來說,新 token 的嵌入由類似的現(xiàn)有單詞初始化,如「man」或「woman」。研究者只需要角色的 4-5 張圖像組成一個故事作為訓練數(shù)據集,并使用 1e-5 的相同學習率對經過 100 個 epoch 的 AR-LDM 進行微調。他們發(fā)現(xiàn)微調 AR-LDM 的整個參數(shù)(僅編碼器 和解碼器 D 除外)獲得了更好的性能。
和解碼器 D 除外)獲得了更好的性能。
實驗結果
研究者使用三個數(shù)據集作為測試平臺,分別是 PororoSV、FlintstonesSV 和 VIST。這三個數(shù)據集中的每個故事都包含 5 個連續(xù)的幀。對于故事可視化,研究者從字幕中預測全部的 5 幀。對于故事連貫性,第一幀被指定為源幀,并參考源幀生成其余 4 幀。他們在 8 塊 NVIDIA A100-80GB GPU 上對 AR-LDM 訓練了 50 個 epoch,用時兩天。
研究者使用兩種設置評估 AR-LDM,其一是使用自動度量 FID 分數(shù)進行定量評估,其二是關于視覺質量、相關性和一致性的大規(guī)模人工評估。
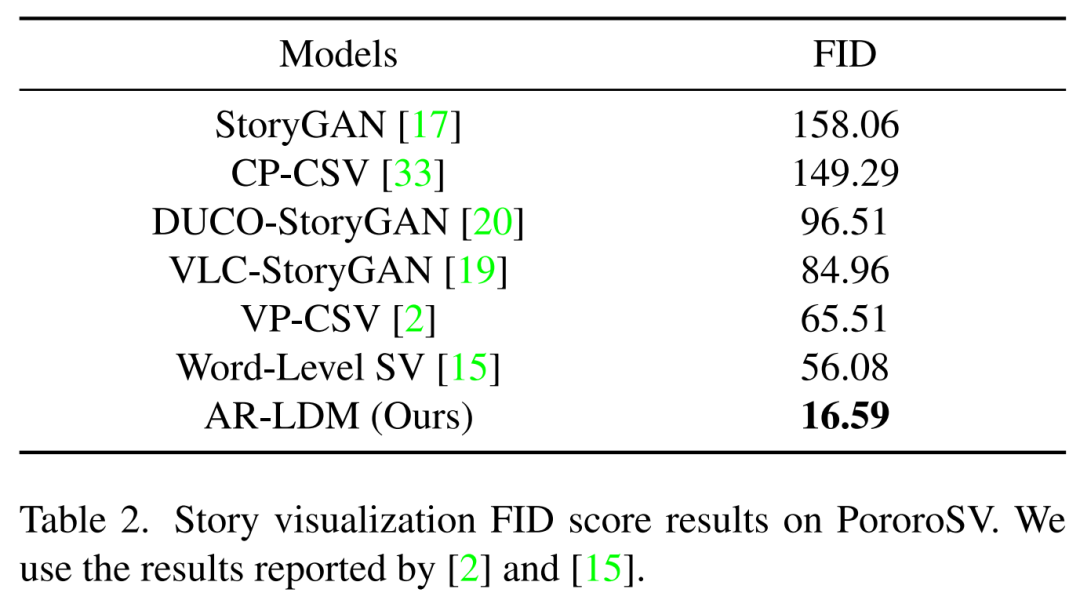
下表 2 展示了在 PororoSV 上的故事可視化結果,其中 AR-LDM 取得了重大進步,SOTA FID 分數(shù)得分為 16.59,大大低于以前的方法。
img
下圖 4a 中,AR-LDM 能夠生成高質量、連貫的視覺故事,同時忠實地再現(xiàn)角色細節(jié)和背景。圖 4b 中,AR-LDM 可以通過自回歸生成保留場景,例如左側示例中最后兩幀的背景,以及右側示例中第三和第四幀中的塊。

img
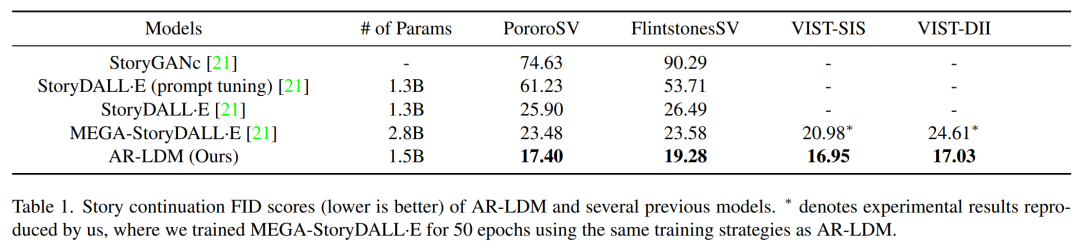
研究者測試了 AR-LDM 的故事連貫性,結果如下表 1 所示。AR-LDM 在所有四個數(shù)據集上都獲得新的 SOTA FID 分數(shù)。值得一提的是,AR-LDM 憑借大約一半的參數(shù)優(yōu)于 MEGA-StoryDALL·E。
img
下圖 5 顯示了 FlintstonesSV 和 VIST-SIS 數(shù)據集上的更多示例,可以觀察到跨幀的場景一致性,例如左上角示例中第三幀和第四幀的窗戶,左下角示例中的海岸場景。

img
下圖 6 中,與其他方法相比,具有自回歸生成方式的 AR-LDM 可以更好地跨幀保留背景和場景視圖。

img
下圖 7 中,所有帶下劃線的文本都指的是同一個角色(即源幀中戴粉色帽子的男人),而描述不一致。因此,AR-LDM 根據每一個描述生成三個不同的角色。在對 3-5 幅圖像進行微調后,自適應 AR-LDM 可以生成一致的角色,并如字幕所描述的那樣忠實地合成場景和角色。

img
審核編輯 :李倩
-
AI
+關注
關注
87文章
30164瀏覽量
268428 -
模型
+關注
關注
1文章
3174瀏覽量
48716 -
可視化
+關注
關注
1文章
1177瀏覽量
20890
原文標題:擴散模型再下一城! 故事配圖這個活可以交給 AI 了
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦


助力榮耀MagicBook Pro 16,芯海科技EC芯片再下一城

芯海科技PC生態(tài)再下一城 EC產品助力榮耀首款AI PC火熱上市!

芯海科技PC生態(tài)再下一城 EC產品助力榮耀首款AI PC火熱上市!

防止AI大模型被黑客病毒入侵控制(原創(chuàng))聆思大模型AI開發(fā)套件評測4
主板用STM32H7B3I-DK然后配一個普通的攝像頭,可以實現(xiàn)視覺AI嗎?
谷歌推出AI擴散模型Lumiere
基于DiAD擴散模型的多類異常檢測工作









 工商網監(jiān)
工商網監(jiān)
評論