") 高算力芯片未來(lái)技術(shù)發(fā)展途徑
高算力芯片未來(lái)技術(shù)發(fā)展途徑
面向未來(lái)高算力芯片需求,分析了國(guó)內(nèi)外高算力芯片發(fā)展趨勢(shì),提出由數(shù)據(jù)互連、單位晶體管提供的算力、晶體管密度和芯片面積構(gòu)成的芯片算力表達(dá)式。介紹了未來(lái)高算力芯片發(fā)展的關(guān)鍵技術(shù),并結(jié)合算力表達(dá)式論述相關(guān)技術(shù)如何發(fā)揮作用。從新材料、新器件、先進(jìn)工藝、新架構(gòu)、集成封裝等角度出發(fā),探討了集成電路先進(jìn)制造工藝、單片三維集成技術(shù)、領(lǐng)域?qū)S眉軜?gòu)、粗粒度可重構(gòu)架構(gòu)、存算一體技術(shù)、芯粒(Chiplet)技術(shù)和晶圓級(jí)集成等國(guó)內(nèi)外發(fā)展現(xiàn)狀及其對(duì)芯片算力的提升效果,并深入分析了各項(xiàng)技術(shù)的發(fā)展和挑戰(zhàn)。結(jié)合中國(guó)高算力芯片現(xiàn)狀和集成電路先進(jìn)制程發(fā)展受限,提出從“架構(gòu)+集成+系統(tǒng)”出發(fā),探索實(shí)現(xiàn)高算力芯片的一體化自主可控創(chuàng)新路徑,可以采用成熟制程,結(jié)合粗粒度可重構(gòu)和存算一體新型架構(gòu),采用基于先進(jìn)集成的芯粒技術(shù)實(shí)現(xiàn)總算力突破。 隨著信息社會(huì)數(shù)字化、智能化水平的不斷提高,人類(lèi)社會(huì)已進(jìn)入算力時(shí)代。當(dāng)前算力基礎(chǔ)設(shè)施主要以數(shù)據(jù)中心的形式實(shí)現(xiàn)高性能算力供應(yīng),其中,高算力芯片是算力的具體載體——提供超算算力、通用算力、智能算力和邊緣算力。數(shù)字經(jīng)濟(jì)時(shí)代,算力高低成為綜合國(guó)力強(qiáng)弱的重要指標(biāo)之一,高算力芯片技術(shù)是國(guó)家核心競(jìng)爭(zhēng)力的重要體現(xiàn)。本文將探討高算力芯片未來(lái)技術(shù)發(fā)展途徑。
數(shù)據(jù)是信息時(shí)代的“石油”,算力則將數(shù)據(jù)轉(zhuǎn)化為動(dòng)能,驅(qū)動(dòng)經(jīng)濟(jì)和科技的發(fā)展,是數(shù)字經(jīng)濟(jì)時(shí)代的引擎。數(shù)字經(jīng)濟(jì)轉(zhuǎn)型和新基建、“東數(shù)西算”等戰(zhàn)略工程驅(qū)動(dòng)中國(guó)實(shí)現(xiàn)算力基礎(chǔ)設(shè)施化。高算力芯片是算力載體,通過(guò)其提供的計(jì)算能力,支撐互聯(lián)網(wǎng)、金融、科技、制造業(yè)等各個(gè)行業(yè)的發(fā)展和數(shù)字化轉(zhuǎn)型,賦能人工智能、自動(dòng)駕駛、智能物聯(lián)網(wǎng)、高性能計(jì)算和元宇宙等應(yīng)用場(chǎng)景。現(xiàn)階段,5G、云計(jì)算、大數(shù)據(jù)、物聯(lián)網(wǎng)、人工智能等技術(shù)高速發(fā)展,數(shù)據(jù)爆炸式增長(zhǎng),算法復(fù)雜度不斷提高,加快高算力芯片發(fā)展,是中國(guó)打造數(shù)字經(jīng)濟(jì)新優(yōu)勢(shì)、提升國(guó)家整體競(jìng)爭(zhēng)力和國(guó)防安全的重要保障。
01高算力芯片國(guó)內(nèi)外發(fā)展態(tài)勢(shì)
1.1 科技發(fā)展對(duì)芯片算力的需求爆發(fā)式增長(zhǎng)
當(dāng)前,高算力芯片在典型應(yīng)用場(chǎng)景中呈現(xiàn)如下分布:以云端部署為主,并逐漸向邊緣端擴(kuò)散,最終在云、邊、端側(cè)形成分布式高算力網(wǎng)絡(luò)。在不同應(yīng)用場(chǎng)景中,衡量芯片算力的具體指標(biāo)會(huì)有相應(yīng)差異。對(duì)于高性能計(jì)算任務(wù),單位時(shí)間內(nèi)的高精度浮點(diǎn)計(jì)算峰值是重要指標(biāo),如64位雙精度浮點(diǎn);對(duì)于人工智能訓(xùn)練及推理任務(wù),只需關(guān)注較低精度數(shù)據(jù)的處理速度,如16位浮點(diǎn)或者8位整型精度;對(duì)于圖像處理任務(wù),系統(tǒng)運(yùn)行的幀率是關(guān)鍵指標(biāo)。但是,差異化任務(wù)場(chǎng)景背后的高算力技術(shù)是共性、通用的。本文采用TOPS(Tera Operations Per Second,萬(wàn)億次運(yùn)算每秒)作為算力指標(biāo),衡量典型高算力場(chǎng)景下的芯片算力需求。當(dāng)前,技術(shù)路線(xiàn)發(fā)展和多項(xiàng)應(yīng)用場(chǎng)景都提出了至少高于1000 TOPS的高算力芯片需求。
(1)數(shù)據(jù)中心和超算需要高于1000 TOPS的高算力芯片。當(dāng)前,超算中心算力已經(jīng)進(jìn)入E級(jí)算力(百億億次運(yùn)算每秒)時(shí)代,并正在向Z(千E)級(jí)算力發(fā)展。2022年5月登頂世界超算500強(qiáng)榜單的美國(guó)國(guó)防部橡樹(shù)嶺國(guó)家實(shí)驗(yàn)室Frontier超算中心,采用AMD公司MI250X高算力芯片(可提供383 TOPS算力),達(dá)到了1.1 EOPS雙精度浮點(diǎn)算力。
(2)新一代人工智能任務(wù)需要高于1000 TOPS的高算力芯片。深度學(xué)習(xí)興起帶來(lái)了人工智能的新一輪繁榮。當(dāng)前,深度學(xué)習(xí)發(fā)展逐步進(jìn)入大模型、大數(shù)據(jù)階段,模型參數(shù)和數(shù)據(jù)量呈爆發(fā)式增長(zhǎng),引發(fā)的算力需求平均每2年超過(guò)算力實(shí)際增長(zhǎng)速度的375倍,因此底層硬件算力難以滿(mǎn)足算法需求。以2020年發(fā)布的GPT3預(yù)訓(xùn)練語(yǔ)言模型為例,其擁有1750億個(gè)參數(shù),使用1000億個(gè)詞匯的語(yǔ)料庫(kù)訓(xùn)練,采用1000塊當(dāng)時(shí)最先進(jìn)的英偉達(dá)A100 GPU(圖形處理器,624 TOPS)訓(xùn)練仍需要1個(gè)月。
(3)高性能移動(dòng)端應(yīng)用,如自動(dòng)駕駛?cè)蝿?wù)需要高于1000 TOPS的高算力芯片。追求更高算力是當(dāng)下自動(dòng)駕駛領(lǐng)域發(fā)展的一大趨勢(shì),高階自動(dòng)駕駛對(duì)算力需求呈指數(shù)級(jí)上升。L2、L3、L4和L5級(jí)自動(dòng)駕駛至少需要10、100、400、3000 TOPS的算力。中國(guó)智己L7整車(chē)達(dá)到1070 TOPS,蔚來(lái)ET7整車(chē)達(dá)到1016 TOPS,背后均搭載了254 TOPS的英偉達(dá)Orin X高算力芯片。預(yù)計(jì)2025年,英偉達(dá)公司將發(fā)布1000 TOPS的Atlan高算力芯片。
綜合考慮集成電路技術(shù)發(fā)展下的芯片算力現(xiàn)狀和未來(lái)人工智能、數(shù)據(jù)中心、自動(dòng)駕駛等領(lǐng)域的發(fā)展趨勢(shì),未來(lái)高算力芯片需要不低于1000 TOPS的算力水平。
1.2中國(guó)高算力芯片發(fā)展仍落后于算力產(chǎn)業(yè)發(fā)展
根據(jù)2022年《中國(guó)算力白皮書(shū)》,2022年中國(guó)整體算力達(dá)到150 EOPS,占全球總算力的31%,在全世界僅落后于美國(guó)(36%),中國(guó)算力產(chǎn)業(yè)發(fā)展對(duì)高算力芯片需求強(qiáng)勁。一方面,高算力芯片作為底層算力池,賦能萬(wàn)千行業(yè)和新興產(chǎn)業(yè),市場(chǎng)發(fā)展造成了對(duì)高算力芯片的強(qiáng)勁需求;另一方面,國(guó)家布局和政策引導(dǎo)也推動(dòng)了高算力芯片的需求。除了“東數(shù)西算”工程外,“十四五”規(guī)劃和2035年遠(yuǎn)景目標(biāo)綱要明確提出要“建設(shè)若干國(guó)家樞紐節(jié)點(diǎn)和大數(shù)據(jù)中心集群,建設(shè)E級(jí)和10E級(jí)超算計(jì)算中心”,國(guó)家發(fā)展和改革委員會(huì)也出臺(tái)了一系列政策文件,全國(guó)多個(gè)地區(qū)進(jìn)行數(shù)據(jù)中心建設(shè)和布局。市場(chǎng)發(fā)展和政策實(shí)施都對(duì)大力發(fā)展高算力芯片技術(shù)提出需求。
然而,中國(guó)高算力芯片的發(fā)展從知識(shí)產(chǎn)權(quán)、市場(chǎng)占有率與自主制造角度依然面臨嚴(yán)峻挑戰(zhàn)。浪潮、華為、新華三、聯(lián)想等國(guó)產(chǎn)服務(wù)器品牌位居中國(guó)服務(wù)器市場(chǎng)前5名,整體份額達(dá)到74%,然而底層的通用高算力芯片卻嚴(yán)重依賴(lài)進(jìn)口。在以中央處理器(CPU)為核心的通用數(shù)據(jù)中心產(chǎn)業(yè),仍以美國(guó)英特爾和AMD主導(dǎo)的x86架構(gòu)CPU主導(dǎo),市場(chǎng)占比超過(guò)96%。華為鯤鵬系列服務(wù)器芯片是中國(guó)自主研發(fā)的基于ARM指令集的高性能芯片,但是高度依賴(lài)先進(jìn)制造工藝。在智能芯片領(lǐng)域,GPU仍是智能數(shù)據(jù)中心的主流算力芯片,2020年中國(guó)智能數(shù)據(jù)中心約95%的市場(chǎng)份額由美國(guó)英偉達(dá)的芯片占據(jù)。近年來(lái),中國(guó)涌現(xiàn)了壁仞、天數(shù)智芯、沐曦、摩爾線(xiàn)程等國(guó)產(chǎn)GPU產(chǎn)品以及華為昇騰、寒武紀(jì)思元、百度昆侖芯、燧原等自主人工智能(Artificial Intelligence, AI)芯片產(chǎn)品,但都過(guò)度依靠國(guó)內(nèi)尚無(wú)法自主可控的先進(jìn)制造工藝。
因此,亟須探索符合國(guó)情的高算力芯片的創(chuàng)新發(fā)展途徑,保障中國(guó)產(chǎn)業(yè)戰(zhàn)略布局實(shí)施,助推數(shù)字經(jīng)濟(jì)發(fā)展。
1.3 高算力芯片技術(shù)發(fā)展途徑
芯片算力由數(shù)據(jù)互連、單位晶體管提供的算力(通常由架構(gòu)決定)、晶體管密度和芯片面積共同決定。
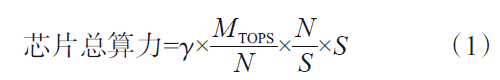
式中,γ為互連系數(shù),既包括存儲(chǔ)和計(jì)算單元之間的互連帶寬,也包括計(jì)算單元之間的互連帶寬,取值為0~1。MTOPS為以TOPS為單位的算力,N為晶體管數(shù)目,S為芯片面積。
自集成電路興起的60多年來(lái),算力芯片的發(fā)展主要依賴(lài)于摩爾定律指引下的工藝制程進(jìn)步和體系架構(gòu)改進(jìn)。然而,隨著器件尺寸逼近物理極限,芯片集成度遵循摩爾定律發(fā)展的趨勢(shì)逐漸變緩,先進(jìn)工藝成本增加,同時(shí)單片芯片的面積有限,這些因素共同導(dǎo)致很難繼續(xù)通過(guò)提升芯片面積和晶體管集成度來(lái)增加算力。現(xiàn)有計(jì)算平臺(tái)主要基于馮·諾依曼架構(gòu),存儲(chǔ)單元和計(jì)算單元彼此分離,任務(wù)處理需要數(shù)據(jù)頻繁在存儲(chǔ)單元和數(shù)據(jù)單元間搬移,消耗在搬移過(guò)程中的延時(shí)和功耗成為系統(tǒng)性能瓶頸,造成“存儲(chǔ)墻”和“功耗墻”。同時(shí)芯片的I/O引腳有限,I/O數(shù)據(jù)傳輸速度匹配不上計(jì)算速度,也會(huì)造成“I/O墻”,和“存儲(chǔ)墻”一起限制了互連系數(shù)γ的提高。這些挑戰(zhàn)制約了計(jì)算芯片算力的進(jìn)一步提升。
本文將從算力表達(dá)式出發(fā),通過(guò)分析新型材料器件、架構(gòu)、工藝和集成方案,探討有望打破算力瓶頸的新興高算力芯片技術(shù)。
02后摩爾時(shí)代的晶體管密度提升途徑
2.1 先進(jìn)制造工藝帶來(lái)的算力提升
按照摩爾定律經(jīng)驗(yàn),集成電路上可以容納的晶體管數(shù)目每18個(gè)月便會(huì)提升1倍。集成電路制造工藝按照摩爾定律不斷發(fā)展,目前先進(jìn)制程已進(jìn)入3 nm節(jié)點(diǎn)。摩爾定律下的集成電路尺寸微縮能帶來(lái)單位面積算力的指數(shù)提升,不僅可以提升單位面積的晶體管數(shù)目,還能通過(guò)提升時(shí)鐘頻率來(lái)提升單位晶體管算力,從而提高芯片總算力(式(1))。圖1統(tǒng)計(jì)了英偉達(dá)GPU算力與工藝制程的關(guān)系。圖1(a)顯示GPU單位面積芯片算力隨工藝節(jié)點(diǎn)的進(jìn)步而提升,橫坐標(biāo)為不同工藝制程節(jié)點(diǎn),縱坐標(biāo)為對(duì)數(shù)坐標(biāo)下的歸一化單位面積算力。圖1(a)內(nèi)表格對(duì)比了65 nm和90 nm制程下的帕斯卡(Pascal)架構(gòu)GPU,可以看到,先進(jìn)工藝節(jié)點(diǎn)晶體管密度和工作頻率均顯著提高,從而帶來(lái)芯片整體算力的提升。圖1(b)對(duì)應(yīng)總結(jié)了GPU歸一化芯片算力與歸一化晶體管數(shù)目和時(shí)鐘頻率乘積的關(guān)系,表明先進(jìn)工藝是芯片算力提升的關(guān)鍵推動(dòng)力。近年來(lái),英偉達(dá)、超威、蘋(píng)果的高算力芯片均采用7、5 nm先進(jìn)制程實(shí)現(xiàn)。
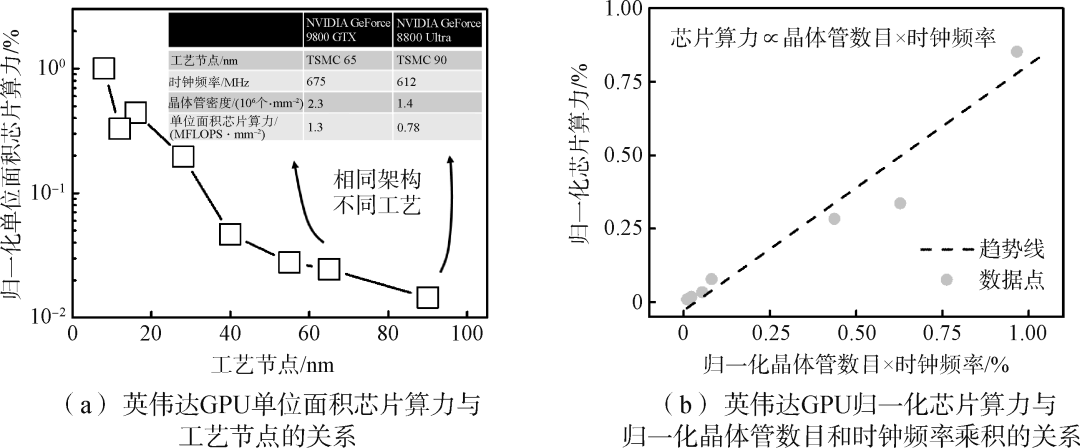
圖1英偉達(dá)GPU算力與工藝制程的關(guān)系
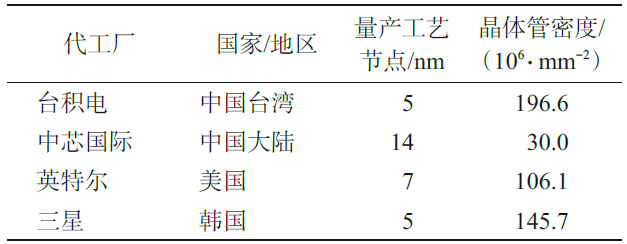
中國(guó)集成電路制造起步較晚,且受出口管制影響,雖然制程發(fā)展迅速,但整體水平相對(duì)落后。表1展示了全球主要集成電路制造廠的量產(chǎn)工藝節(jié)點(diǎn)及晶體管密度。中國(guó)臺(tái)灣積體電路制造股份有限公司(簡(jiǎn)稱(chēng)臺(tái)積電)和三星均已量產(chǎn)5 nm工藝節(jié)點(diǎn),英特爾也量產(chǎn)了7 nm工藝節(jié)點(diǎn),晶體管密度均超過(guò)了1億個(gè)/mm2,大陸代工廠中芯國(guó)際打通了14 nm工藝節(jié)點(diǎn),晶體管密度達(dá)到3000萬(wàn)個(gè)/mm2。
表1全球主要集成電路制造廠的量產(chǎn)工藝節(jié)點(diǎn)及晶體管密度
2.2 摩爾定律發(fā)展的挑戰(zhàn)與機(jī)遇
隨著集成電路工藝節(jié)點(diǎn)的不斷進(jìn)步,摩爾定律發(fā)展受到非理想物理效應(yīng)和工藝成本等諸多限制,其中主要的挑戰(zhàn)一方面在于光刻技術(shù),另一方面在于器件的短溝道效應(yīng)。
光刻是集成電路制造的核心工藝,決定了器件的空間尺度。為滿(mǎn)足先進(jìn)制程需求,將采用極紫外(Extreme Ultra-Violet, EUV)光刻機(jī)。EUV直接將光源波長(zhǎng)從193 nm縮短至13.5 nm,通過(guò)將整個(gè)光路放置在真空環(huán)境下,把透鏡組變成反射鏡組等方式,減小了短波長(zhǎng)光在光路中的損耗。采用EUV結(jié)合各種先進(jìn)工藝技術(shù),實(shí)現(xiàn)3 nm工藝節(jié)點(diǎn)沒(méi)有障礙,但面臨成本控制、光源波長(zhǎng)縮短和光源穩(wěn)定性問(wèn)題。
短溝道效應(yīng)是指隨器件尺寸微縮達(dá)到物理極限,量子效應(yīng)和非理想因素將逐漸顯現(xiàn),影響器件性能,包括閾值電壓降低、漏致勢(shì)壘降低、載流子表面散射和熱電子效應(yīng)等。增加?xùn)趴啬芰κ且种贫虦系佬?yīng)的關(guān)鍵,為此,集成電路制造已從平面工藝發(fā)展為鰭式場(chǎng)效應(yīng)晶體管(Fin Field-Effect Transistor, FinFET)工藝,通過(guò)增加?xùn)艠O維度改善柵控效果。隨著工藝節(jié)點(diǎn)往3、2 nm發(fā)展,將需要全新器件結(jié)構(gòu)實(shí)現(xiàn)更強(qiáng)的柵控,基于環(huán)柵場(chǎng)效應(yīng)晶體管(Gate-All-Around Field-Effect Transistor, GAAFET)和多橋通道場(chǎng)效應(yīng)晶體管(Multi-Bridge-Channel Field-Effect Transistor, MBCFET)器件結(jié)構(gòu)的制造流程將成為主流(圖2)。
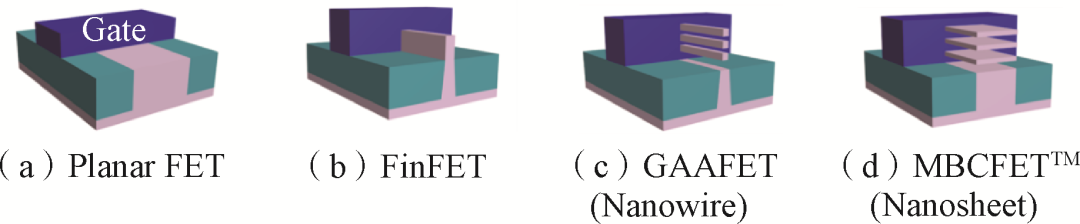
圖2工藝制程發(fā)展中的不同器件結(jié)構(gòu)
2.3 單片三維集成技術(shù)
在二維空間實(shí)現(xiàn)高密度晶體管集成的手段已經(jīng)逐步逼近極限,未來(lái)摩爾定律的發(fā)展可通過(guò)單片三維集成實(shí)現(xiàn)。通過(guò)在垂直方向堆疊晶體管和其他邏輯、存儲(chǔ)器件,進(jìn)一步提升單位面積的晶體管數(shù)目和數(shù)據(jù)通信效率,實(shí)現(xiàn)提高芯片算力。斯坦福大學(xué)教授Phillip Wong團(tuán)隊(duì)通過(guò)評(píng)估表明,單片三維集成芯片相對(duì)于傳統(tǒng)二維芯片,具有1000倍以上的功耗延時(shí)乘積優(yōu)勢(shì)。該技術(shù)發(fā)展需要克服工藝兼容、散熱、良率和可靠性問(wèn)題。異質(zhì)單片三維集成技術(shù)是現(xiàn)在研究的前沿?zé)狳c(diǎn),斯坦福大學(xué)、麻省理工學(xué)院和清華大學(xué)、北京大學(xué)都在進(jìn)行深入研究。2021年國(guó)際電子器件會(huì)議(IEDM)上,清華大學(xué)錢(qián)鶴、吳華強(qiáng)研究團(tuán)隊(duì)展示了一個(gè)集內(nèi)容尋址和存算單元核心于一體的單片三維集成系統(tǒng),該系統(tǒng)與傳統(tǒng)芯片相比擁有2個(gè)量級(jí)的能耗優(yōu)勢(shì)(圖3)。
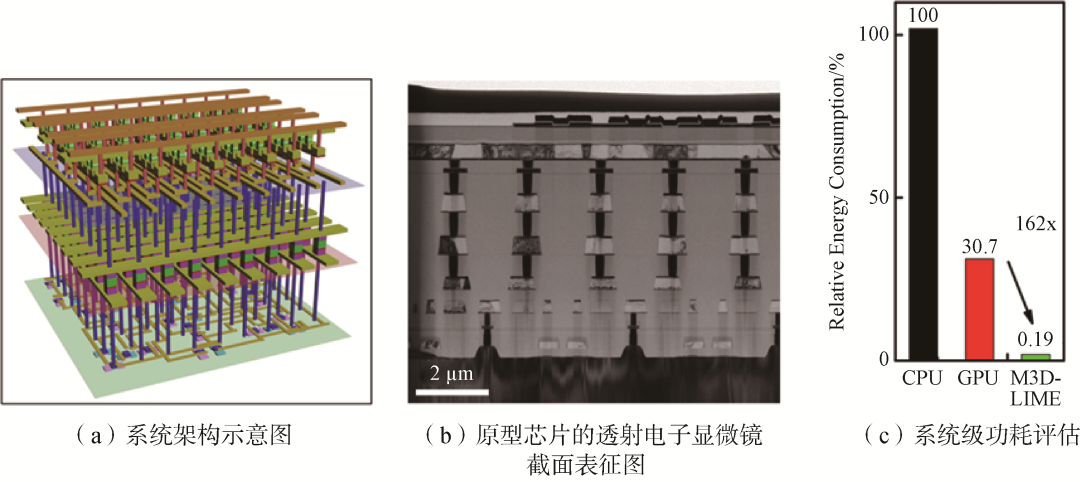
圖3碳、硅和憶阻器單片三維異質(zhì)集成系統(tǒng)
03基于新型計(jì)算架構(gòu)的算力提升途徑
計(jì)算架構(gòu)的好壞影響了芯片單位晶體管能提供的算力水平,是決定芯片算力的本質(zhì)因素。架構(gòu)設(shè)計(jì)需要在通用性和高效性間平衡,以適應(yīng)不同的應(yīng)用場(chǎng)景。圖4展示了傳統(tǒng)計(jì)算芯片的架構(gòu)特點(diǎn)。傳統(tǒng)計(jì)算硬件以CPU和通用圖形處理器(GPGPU)為代表,基于馮·諾依曼架構(gòu)完成通用計(jì)算。CPU使用了復(fù)雜的流水線(xiàn)和控制邏輯,并依托指令集實(shí)現(xiàn)硬件開(kāi)發(fā)和軟件編程解耦,具有高度可編程性,是最通用、最靈活的計(jì)算芯片。雖然軟件生態(tài)成熟,但無(wú)法兼顧高算力,因此性能受到限制。GPGPU則采用眾核架構(gòu),由眾多簡(jiǎn)單的并行計(jì)算單元提供算力支持,更加注重眾核的高性能,一般作為對(duì)高并行度任務(wù)的加速處理單元使用。此外,還有依托于現(xiàn)場(chǎng)可編程邏輯門(mén)陣列(Field-Programmable Gate Array, FPGA)和專(zhuān)用集成電路(Application Specific Integrated Circuit, ASIC)的計(jì)算芯片:ASIC是專(zhuān)用計(jì)算芯片,一般針對(duì)具體的應(yīng)用場(chǎng)景和算法,通過(guò)高度定制化來(lái)高效解決特定問(wèn)題,能實(shí)現(xiàn)較高的性能,但可編程性和通用性較差;FPGA是一類(lèi)基于現(xiàn)場(chǎng)可編程邏輯陣列的計(jì)算芯片,雖然不能做到GPU級(jí)別的并行加速或ASIC級(jí)別的能效比,但是可以提供硬件編程能力。
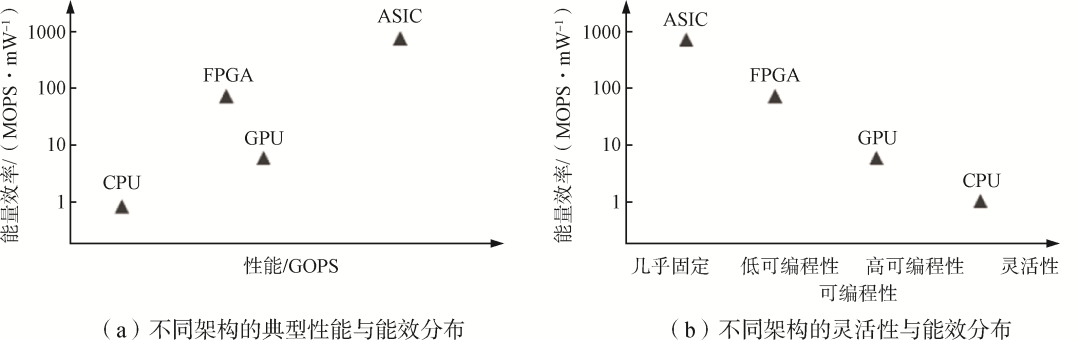
圖4傳統(tǒng)計(jì)算芯片的架構(gòu)特點(diǎn)
傳統(tǒng)架構(gòu)無(wú)法滿(mǎn)足未來(lái)高算力芯片的需求,設(shè)計(jì)具有通用性、靈活性的高算力芯片需要全新的架構(gòu)。為此,國(guó)內(nèi)外高校和企業(yè)持續(xù)進(jìn)行芯片架構(gòu)的研究與開(kāi)發(fā)。英偉達(dá)在GPGPU上迭代形成集成了張量核心(Tensor Core)的領(lǐng)域定制架構(gòu),2022年最新發(fā)布的H100 GPU基于4 nm工藝,可以提供2000 TFLOPS(萬(wàn)億次浮點(diǎn)運(yùn)算每秒)的算力。清華大學(xué)尹首一研究團(tuán)隊(duì)提出了多尺度可編程的粗粒度可重構(gòu)架構(gòu)和憶阻器存算一體架構(gòu),解決了硬件靈活性與利用率之間的固有矛盾。以下面向未來(lái)大算力應(yīng)用場(chǎng)景探索芯片新型架構(gòu),深入分析架構(gòu)設(shè)計(jì)思路與特性,總結(jié)未來(lái)高算力芯片架構(gòu)的發(fā)展趨勢(shì)。
3.1 領(lǐng)域?qū)S眉軜?gòu)
領(lǐng)域?qū)S眉軜?gòu)(Domain-Specific Architecture, DSA)是指為特定領(lǐng)域的一類(lèi)任務(wù)定制化設(shè)計(jì)的芯片架構(gòu),在解決該類(lèi)問(wèn)題時(shí)兼顧通用性和高性能。通常,DSA架構(gòu)進(jìn)行以下優(yōu)化:①定制化設(shè)計(jì)運(yùn)算電路和支持的數(shù)據(jù)類(lèi)型;②設(shè)計(jì)支持高并行度操作的硬件結(jié)構(gòu),用并行的方式接近線(xiàn)性地提升性能;③對(duì)存儲(chǔ)結(jié)構(gòu)進(jìn)行優(yōu)化,可以定制化片上靜態(tài)隨機(jī)存取存儲(chǔ)器(SRAM)存儲(chǔ);④往往會(huì)有強(qiáng)大的領(lǐng)域特定語(yǔ)言(Domian-Specific Language, DSL)編程語(yǔ)言支持,在應(yīng)用層面進(jìn)一步發(fā)揮硬件性能。DSA通用性大于ASIC芯片,并且在開(kāi)發(fā)成本上解決了ASIC芯片的一次性工程費(fèi)用(Non-Recurring Engineering, NRE)無(wú)法平攤、編程性差等缺點(diǎn),同時(shí)提供高算力和高能效。
3.1.1 粗粒度可重構(gòu)架構(gòu)
可重構(gòu)計(jì)算(Coarse-Grained Reconfigurable Architecture, CGRA)架構(gòu)是一種兼顧靈活性和高能效的高算力架構(gòu)。CGRA在硬件運(yùn)行時(shí)通過(guò)軟件定義來(lái)配置處理元素(Processing Element, PE)的功能和互聯(lián),使得芯片制造后仍然可以定制功能,提高靈活性。CGRA設(shè)計(jì)結(jié)合空域和時(shí)域——空域上通過(guò)PE的部署分配計(jì)算資源并構(gòu)建合理的互聯(lián)方式,避免了深度流水線(xiàn)和集中通信帶來(lái)的開(kāi)銷(xiāo);時(shí)域上通過(guò)時(shí)分復(fù)用充分利用計(jì)算資源,提高了面積效率。在編程模型上CGRA支持命令式編程、并行編程、透明編程等多種編程模式,通過(guò)編譯器產(chǎn)生配置控制/數(shù)據(jù)流圖,由配置和數(shù)據(jù)同時(shí)驅(qū)動(dòng)執(zhí)行。
CGRA架構(gòu)有效解決了ASIC的高NRE問(wèn)題,在實(shí)現(xiàn)高算力的同時(shí),兼顧靈活性、高精度和高能效。清華大學(xué)研究團(tuán)隊(duì)2022年在國(guó)際固態(tài)電路年度會(huì)議(ISSCC)上發(fā)表了面向云端深度學(xué)習(xí)任務(wù)的可重構(gòu)存算一體加速器——ReCIM,解決了浮點(diǎn)運(yùn)算中的功耗、數(shù)據(jù)類(lèi)型種類(lèi)、面積效率等問(wèn)題;清微智能的Thinker系列可重構(gòu)計(jì)算芯片產(chǎn)品在語(yǔ)音識(shí)別、圖像識(shí)別等多種應(yīng)用場(chǎng)景展現(xiàn)了性能和功耗優(yōu)勢(shì),即將推出的云端訓(xùn)練芯片TX8系列,單芯片能夠?qū)崿F(xiàn)256 TFLOPS算力,其基于粗粒度數(shù)據(jù)流架構(gòu)具有較強(qiáng)的橫向擴(kuò)展能力,單服務(wù)器可實(shí)現(xiàn)8 POPS算力。
3.1.2 基于張量核心的GPGPU架構(gòu)
英偉達(dá)GPGPU是傳統(tǒng)高算力芯片,為滿(mǎn)足后摩爾時(shí)代更高的算力需求,在兼顧通用性和編程性的同時(shí),英偉達(dá)引入了基于張量核心的新型GPGPU架構(gòu)。2017年發(fā)布的V100 GPU搭載640個(gè)張量核心,實(shí)現(xiàn)了125 TFLOPS的算力;2020年發(fā)布的A100 GPU搭載432個(gè)張量核心,算力達(dá)到312 TFLOPS。高算力GPGPU芯片廣泛應(yīng)用于阿里、百度、騰訊等眾多國(guó)內(nèi)互聯(lián)網(wǎng)公司的云服務(wù)器中。
張量核心作為核心算力單元,針對(duì)張量運(yùn)算定制的高并行度計(jì)算單元和控制邏輯,定制化的數(shù)據(jù)類(lèi)型和運(yùn)算規(guī)模,以及關(guān)鍵算法的硬件化(如結(jié)構(gòu)化稀疏),是其設(shè)計(jì)的核心理念。在Volta架構(gòu)中,張量核心每個(gè)周期完成一個(gè)4×4×4的矩陣乘法操作(A×B+C=D)。張量核心的具體行為由指令控制,數(shù)據(jù)總線(xiàn)將操作數(shù)送入張量核心,在其中分組并行通過(guò)浮點(diǎn)乘加單元進(jìn)行矩陣運(yùn)算,再通過(guò)總線(xiàn)寫(xiě)回。張量核心架構(gòu)自身也在不斷迭代和改進(jìn),Ampere架構(gòu)中,根據(jù)實(shí)際神經(jīng)網(wǎng)絡(luò)應(yīng)用場(chǎng)景,引入對(duì)TF32和BF16數(shù)據(jù)類(lèi)型以及結(jié)構(gòu)化稀疏的支持。
3.1.3 數(shù)據(jù)中心處理單元
數(shù)據(jù)中心對(duì)于高算力的應(yīng)用場(chǎng)景,數(shù)據(jù)處理的流程往往是龐大且復(fù)雜的,數(shù)據(jù)通信也逐漸成為實(shí)現(xiàn)高算力系統(tǒng)的瓶頸。基于異構(gòu)多核架構(gòu)的新一代智能高算力數(shù)據(jù)處理單元(Data Processing Units, DPU)應(yīng)運(yùn)而生。傳統(tǒng)網(wǎng)絡(luò)接口控制器(Network Interface Controller, NIC)負(fù)責(zé)進(jìn)行數(shù)據(jù)交互,將用戶(hù)傳輸?shù)臄?shù)據(jù)格式轉(zhuǎn)換成網(wǎng)絡(luò)設(shè)備能夠識(shí)別的格式;智能網(wǎng)卡在此基礎(chǔ)上融合了可編程、可加速的功能,實(shí)現(xiàn)部分任務(wù)卸載(如虛擬化等網(wǎng)絡(luò)服務(wù)、遠(yuǎn)程存儲(chǔ)等存儲(chǔ)服務(wù)、加解密安全服務(wù)等);DPU作為下一代智能網(wǎng)卡,采用異構(gòu)多核集成和軟硬件結(jié)合的方式,搭載CPU和多種加速處理單元。英偉達(dá)發(fā)布的第三代DPU產(chǎn)品BlueField-3支持InfiniBand,帶寬達(dá)到400 Gb/s。該架構(gòu)包含16個(gè)Arm A78核心,多個(gè)高速外圍接口、數(shù)據(jù)通路加速模塊和AI/HPC任務(wù)加速模塊。
3.2 近存計(jì)算和存算一體
傳統(tǒng)馮·諾依曼架構(gòu)中,存算分離的方式使得數(shù)據(jù)搬運(yùn)成為系統(tǒng)性能的瓶頸,不適合大數(shù)據(jù)場(chǎng)景下的高算力應(yīng)用。近存計(jì)算架構(gòu)和存算一體架構(gòu)將從減少數(shù)據(jù)訪(fǎng)存開(kāi)銷(xiāo)出發(fā),實(shí)現(xiàn)高算力、高能效芯片。
3.2.1 近存計(jì)算
近存計(jì)算通過(guò)縮短計(jì)算單元和存儲(chǔ)單元的距離,從而緩解訪(fǎng)存帶寬瓶頸,提升數(shù)據(jù)的互連系數(shù),有效提高受限于帶寬的芯片算力。近存計(jì)算往往通過(guò)在計(jì)算芯片內(nèi)部集成更多的存儲(chǔ)單元,或者增加存儲(chǔ)單元和計(jì)算單元的帶寬,來(lái)降低數(shù)據(jù)搬移的開(kāi)銷(xiāo)。英偉達(dá)和AMD的高性能GPGPU均采用高帶寬內(nèi)存(High Bandwidth Memory, HBM)技術(shù),通過(guò)堆疊高帶寬內(nèi)存,實(shí)現(xiàn)高效數(shù)據(jù)傳輸;新型高算力AI芯片,如Graphcore和Cerebras WSE(Wafer Scale Engine),通過(guò)片上集成更多SRAM單元實(shí)現(xiàn)高算力人工智能加速器;三星通過(guò)在動(dòng)態(tài)隨機(jī)存取存儲(chǔ)器(DRAM)存儲(chǔ)單元內(nèi)部集成計(jì)算邏輯來(lái)實(shí)現(xiàn)近存計(jì)算;阿里達(dá)摩院和紫光同芯合作,通過(guò)3D混合鍵合的方式將計(jì)算邏輯和存儲(chǔ)單元垂直集成在一起,實(shí)現(xiàn)高算力。
3.2.2 存算一體
存算一體,特別是基于憶阻器的存算一體技術(shù),能在近存計(jì)算的基礎(chǔ)上更進(jìn)一步實(shí)現(xiàn)計(jì)算和存儲(chǔ)的器件級(jí)融合,存儲(chǔ)單元同時(shí)也是執(zhí)行單元。構(gòu)成存算一體的底層器件包括阻變式隨機(jī)存取存儲(chǔ)器(RRAM)、SRAM、相變隨機(jī)存取存儲(chǔ)器(PCRAM)、磁性隨機(jī)存取存儲(chǔ)器(MRAM)等多種存儲(chǔ)器件,其中RRAM具有非易失、高存儲(chǔ)密度、功耗低以及互補(bǔ)金屬氧化物半導(dǎo)體(Complementary Metal-Oxide-Semiconductor, CMOS)工藝兼容等優(yōu)勢(shì),基于RRAM構(gòu)建交叉陣列,在本地完成高并行的模擬計(jì)算(圖5),實(shí)現(xiàn)算力突破。清華大學(xué)錢(qián)鶴、吳華強(qiáng)團(tuán)隊(duì)積極布局,研發(fā)28 nm憶阻器產(chǎn)線(xiàn),發(fā)布了首顆全系統(tǒng)集成的憶阻器存算一體原型芯片和軟件工具棧,能效比GPGPU提高2個(gè)數(shù)量級(jí);北京大學(xué)、中國(guó)科學(xué)院、復(fù)旦大學(xué)、浙江大學(xué)等也在器件、算法和模型等方面有所突破。國(guó)外國(guó)際商業(yè)機(jī)器公司(IBM)、惠普和英特爾等公司,以及麻省理工學(xué)院、斯坦福大學(xué)、加州大學(xué)伯克利分校等高校,從器件、架構(gòu)和工具鏈出發(fā),布局存算一體高算力芯片研究。
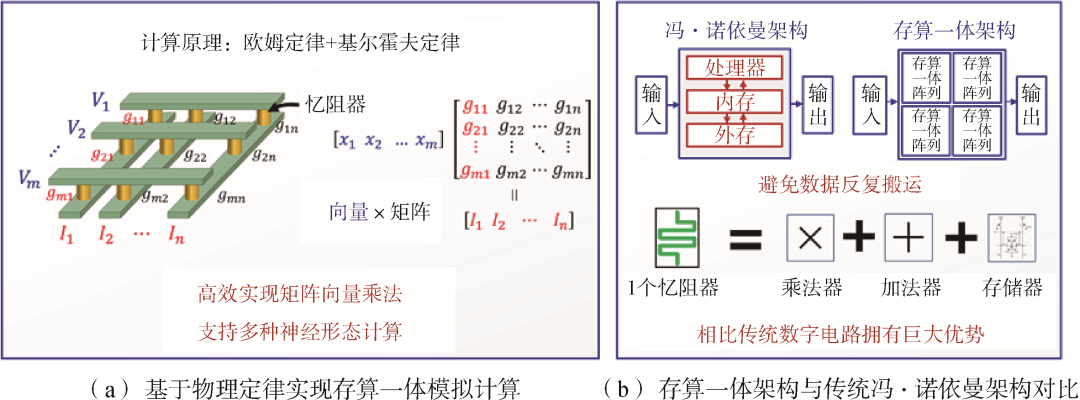
圖5基于憶阻器的存算一體技術(shù)原理
04基于芯粒技術(shù)的
晶體管數(shù)目持續(xù)提升途徑
4.1 芯粒技術(shù)及其現(xiàn)狀
Chiplet通常譯作芯粒或小芯片,美國(guó)國(guó)防部高級(jí)研究計(jì)劃局(DARPA)在2017年的“通用異構(gòu)集成和知識(shí)產(chǎn)權(quán)復(fù)用策略”項(xiàng)目(CHIPS)中明確提到,“旨在開(kāi)發(fā)模塊化芯片設(shè)計(jì),通過(guò)集成知識(shí)產(chǎn)權(quán)(Intellectual Property, IP)模塊,以預(yù)制芯粒的形式進(jìn)行快速組裝和重新配置”。芯粒通過(guò)把不同功能芯片模塊化,利用新的設(shè)計(jì)、互連、封裝等技術(shù),在1顆芯片產(chǎn)片中使用來(lái)自不同技術(shù)、不同制程甚至不同工廠的芯片(圖6)。

圖6芯粒系統(tǒng)芯片分解圖
后摩爾時(shí)代,先進(jìn)工藝流片成本不降反升,傳統(tǒng)馮·諾依曼架構(gòu)瓶頸下,計(jì)算系統(tǒng)算力同時(shí)受“功耗墻”“存儲(chǔ)墻”和“I/O墻”制約(圖7),集成電路發(fā)展需要新思路和新動(dòng)力。芯粒技術(shù)成為學(xué)術(shù)界和產(chǎn)業(yè)界普遍看好的關(guān)鍵突破方向之一。通過(guò)將芯片設(shè)計(jì)中不同功能模塊切割劃分為多顆芯粒,采用各自最適合的工藝節(jié)點(diǎn)生產(chǎn)制備,而不必統(tǒng)一采用先進(jìn)制程,實(shí)現(xiàn)有效降低流片開(kāi)銷(xiāo);各顆芯粒面積較小,有利于良率提升,進(jìn)一步降低成本。芯粒通過(guò)像“樂(lè)高積木”一樣搭建芯片系統(tǒng),復(fù)用設(shè)計(jì)縮短開(kāi)發(fā)周期,促進(jìn)集成電路形成全新的設(shè)計(jì)流程和產(chǎn)業(yè)模式。
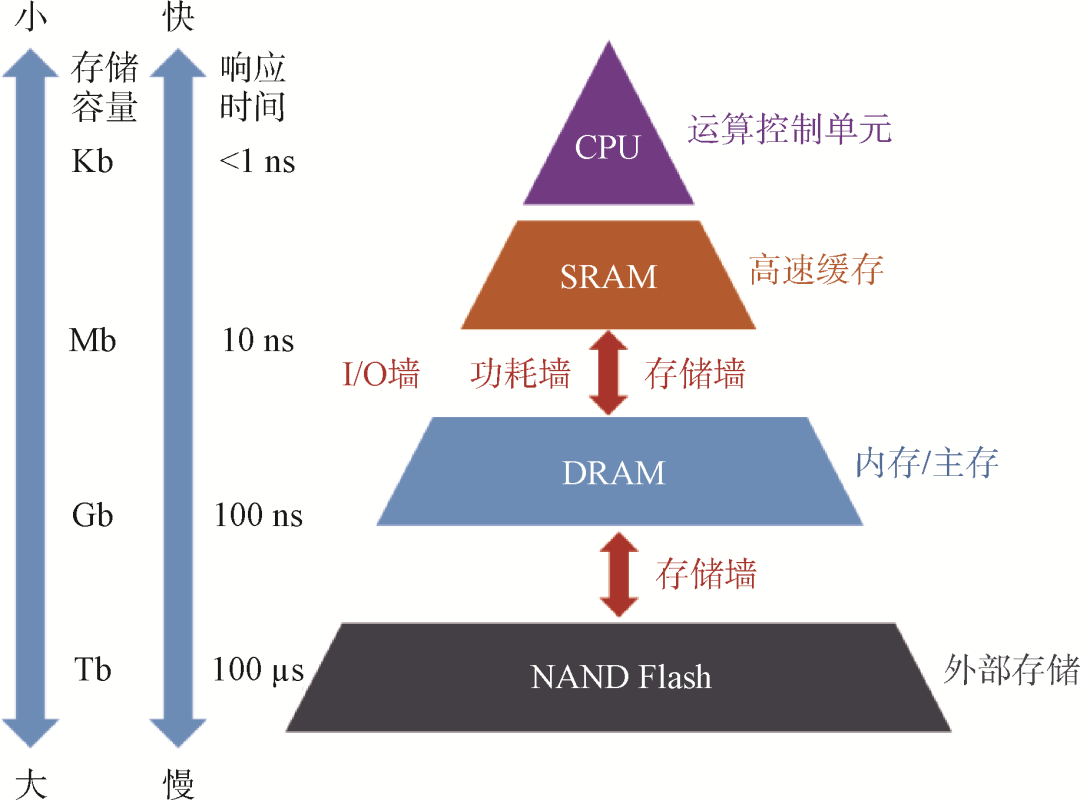
圖7馮·諾依曼架構(gòu)瓶頸和“三墻”問(wèn)題
芯粒技術(shù)是未來(lái)高算力芯片的關(guān)鍵支撐。當(dāng)前,單芯片受步進(jìn)式光刻機(jī)單次曝光區(qū)域限制,極限面積通常為800~900 mm2,制約了芯片總算力的提升。采用芯粒技術(shù),將多顆芯粒通過(guò)封裝技術(shù)在基板上進(jìn)行2.5D/3D集成,將突破單芯片的面積限制,形成高算力芯片系統(tǒng)。芯粒核心是封裝、互連技術(shù)以及全新的系統(tǒng)設(shè)計(jì)方法學(xué),采用高密度、高速的封裝和互連設(shè)計(jì),還可以提升計(jì)算和存儲(chǔ)、計(jì)算和計(jì)算之間的通信帶寬,進(jìn)一步提升芯片算力。
英特爾在2022年發(fā)布Ponte Vecchio (PVC),算力達(dá)到1468 TOPS,它通過(guò)嵌入式多芯片互連橋接(Embedded Multi-die Interconnect Bridge, EMIB)技術(shù)與Foveros 3D技術(shù)實(shí)現(xiàn)了分屬于5個(gè)工藝節(jié)點(diǎn)的47顆功能芯粒的集成——包括16顆Xe-HPC架構(gòu)的計(jì)算芯粒、8顆蘭博緩存(Rambo Cache芯粒、8顆HBM芯粒、2顆英特爾7 nm節(jié)點(diǎn)的Xe基礎(chǔ)芯粒、以及11顆EMIB互連芯粒和2顆Xe-Link I/O芯粒。同年,蘋(píng)果發(fā)布M1 Ultra,基于臺(tái)積電3D Fabric平臺(tái)將2顆完全一致的M1 Max芯片集成在統(tǒng)一封裝體內(nèi),并通過(guò)集成扇出型封裝-局部硅互連(InFO Local Silicon Interconnect, InFO-LSI)技術(shù)在2顆M1 Max芯片間實(shí)現(xiàn)了2.5 TB/s的高帶寬互連。
4.2 芯粒支撐技術(shù):封裝與互連
4.2.1 先進(jìn)封裝技術(shù)
芯粒封裝技術(shù)中,按照封裝結(jié)構(gòu)可以分為2D、2.5D和3D。不通過(guò)額外中介層,直接在有機(jī)基板上互連芯片的形式稱(chēng)為2D封裝,該方案成本低,但互連線(xiàn)的密度不高,采用高速串行互連技術(shù)一定程度上可以彌補(bǔ)低帶寬問(wèn)題。
臺(tái)積電的基板上晶圓上的芯片(Chip on Wafer on Substrate, CoWoS)技術(shù)是典型的2.5D封裝技術(shù),即通過(guò)硅轉(zhuǎn)接板實(shí)現(xiàn)多顆芯片的互連和集成(圖8)。封裝體內(nèi)多顆芯片水平排布通過(guò)倒裝互連在硅轉(zhuǎn)接板上,并在硅轉(zhuǎn)接板上完成高密度金屬互連線(xiàn),隨后通過(guò)硅通孔(Through Silicon Via, TSV)將信號(hào)引出至封裝基板。目前主流的2.5D先進(jìn)封裝技術(shù)還包括以英特爾的EMIB技術(shù)為代表的硅橋衍生技術(shù)等。2.5D封裝中,硅轉(zhuǎn)接板上互連線(xiàn)密度更高,距離更短,速度更快,但是成本也較高,且存在應(yīng)力問(wèn)題。
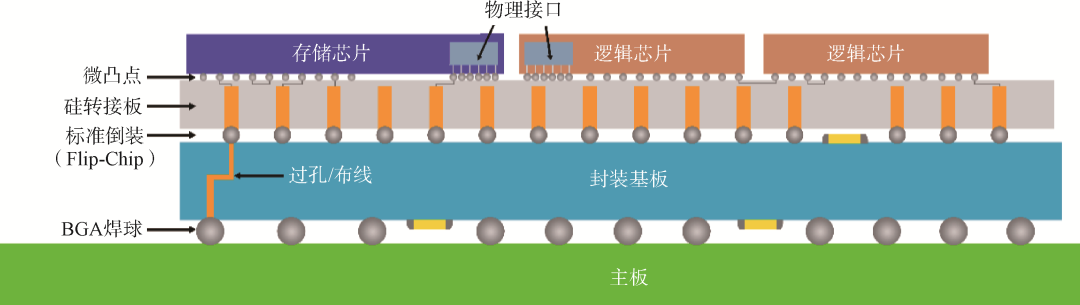
圖82.5D封裝示意圖
3D封裝是指2顆或多顆芯粒通過(guò)硅通孔、以面對(duì)背(Face-to-Back)的形式,或通過(guò)微凸點(diǎn)或混合鍵合技術(shù)、以面對(duì)面(Face-to-Face)的形式,在垂直方向直接堆疊,并實(shí)現(xiàn)芯粒間和對(duì)外界的信號(hào)連接的技術(shù)(圖9)。目前主流的3D封裝技術(shù)主要包括臺(tái)積電的系統(tǒng)整合芯片(System on Integrated Chip, SoIC)技術(shù)和英特爾的Foveros 3D封裝技術(shù)等。3D封裝互連密度更高,距離更短,速度更快,但是成本更高且存在散熱和應(yīng)力等問(wèn)題。
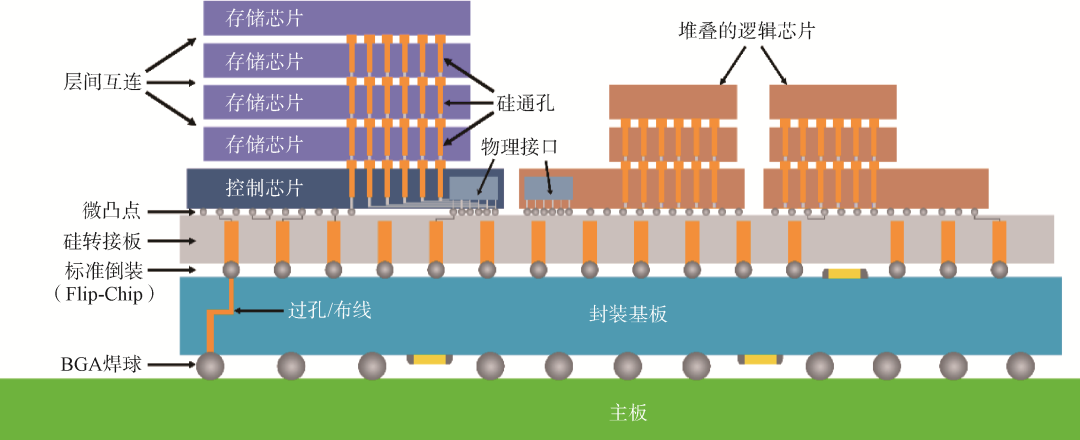
圖93D封裝示意圖
基于芯粒技術(shù)實(shí)現(xiàn)有競(jìng)爭(zhēng)力的高算力芯片,離不開(kāi)先進(jìn)封裝技術(shù)的支持。在不改變軟件和芯片內(nèi)核的情況下,Graphcore發(fā)布的新一代智能處理單元(Intelligence Processing Unit, IPU)產(chǎn)品Bow通過(guò)采用SoIC-WoW 3D封裝技術(shù)即可實(shí)現(xiàn)40%的性能提升。當(dāng)前,臺(tái)積電、英特爾、三星是先進(jìn)封裝領(lǐng)域的核心競(jìng)爭(zhēng)者。
4.2.2 互連和通信
芯粒之間互連通信可分為2類(lèi):串行互連和并行互連。互連性能指標(biāo)通常包括傳輸距離、傳輸能耗、傳輸帶寬及帶寬密度等。串行接口包括長(zhǎng)/中/短距離的SerDes(LR/MR/VSR SerDes),超短距離(Extra Short Reach, XSR)SerDes和極短距離(Ultra Short Reach, USR)SerDes,其中USR Serdes的設(shè)計(jì)主要用于實(shí)現(xiàn)多芯粒系統(tǒng)內(nèi)裸片到裸片的極短距離高速通信。由于通信距離短,USR可以利用高級(jí)編碼、多比特傳輸?shù)认冗M(jìn)技術(shù)提供更高效的解決方案,實(shí)現(xiàn)更好的性能功耗比和可擴(kuò)展性。
與使用XSR SerDes的串行互連相比,并行互連技術(shù)設(shè)計(jì)復(fù)雜度低,每比特能耗更低(1/6~1/10),帶寬可高10倍以上,且延遲更小。目前可用于芯粒裸片互連的通用并行接口協(xié)議主要有英特爾的AIB/MDIO、OCP的BoW、臺(tái)積電的LIPINCON等。并行互連技術(shù)適合應(yīng)用在對(duì)訪(fǎng)問(wèn)延時(shí)要求較高的存儲(chǔ)類(lèi)接口上,如HBM系列接口即為典型的并行接口。
各種互連接口相互之間并不兼容,缺乏一個(gè)被廣泛接受的接口總線(xiàn)標(biāo)準(zhǔn)。2022年3月,英特爾、高通、臺(tái)積電等10家半導(dǎo)體產(chǎn)業(yè)上下游企業(yè)組成通用芯粒高速互連(Universal Chiplet Interconnect Express, UCIe)聯(lián)盟,意欲推動(dòng)芯粒互連標(biāo)準(zhǔn)規(guī)范化、共建開(kāi)放生態(tài)。UCIe是一種分層協(xié)議,物理層負(fù)責(zé)電信號(hào)、時(shí)鐘、鏈路訓(xùn)練、邊帶等。晶粒到晶粒(Die-to-Die)適配器為芯粒提供鏈路狀態(tài)管理和參數(shù)協(xié)商,當(dāng)支持多種協(xié)議時(shí),它定義了底層的仲裁機(jī)制。
4.3 芯粒技術(shù)未來(lái)發(fā)展
基于芯粒搭建高算力計(jì)算系統(tǒng),是一種全新的設(shè)計(jì)模式,需要上下游產(chǎn)業(yè)鏈共同努力形成生態(tài)。當(dāng)前芯粒面臨設(shè)計(jì)工具、制造材料、成本等多方面挑戰(zhàn)。芯粒技術(shù)需要基于成本考慮選擇合適的集成工藝方案,整體所獲得的收益一定要大于額外代價(jià)。未來(lái),需要上下游產(chǎn)業(yè)和電子設(shè)計(jì)自動(dòng)化(Electronic Design Automation, EDA)廠商、代工廠等深度合作,制定互連標(biāo)準(zhǔn)來(lái)推動(dòng)該技術(shù)的普及應(yīng)用;同時(shí),引入新的工具和設(shè)計(jì)、驗(yàn)證、測(cè)試方法。隨著封裝技術(shù)的發(fā)展和互連方案的統(tǒng)一,芯粒技術(shù)有望形成全新的集成電路商業(yè)模式,徹底變革計(jì)算領(lǐng)域。
05基于晶圓級(jí)集成技術(shù)的
超高算力實(shí)現(xiàn)途徑
根據(jù)芯片算力表達(dá)式,芯片的算力提升除了架構(gòu)優(yōu)化、采用先進(jìn)制程外,增大芯片面積也是重要手段。根據(jù)近40年來(lái)芯片面積的變化趨勢(shì),可以看出隨著高算力芯片的不斷發(fā)展,面積也持續(xù)增大,當(dāng)前已接近單片集成的面積極限。晶圓級(jí)集成技術(shù)即是一種新興擴(kuò)大集成面積,實(shí)現(xiàn)高算力芯片的途徑。
基于常規(guī)芯片進(jìn)行集群式算力擴(kuò)展的方式已無(wú)法彌合常規(guī)芯片尺寸受限帶來(lái)的天然性能鴻溝。近期出現(xiàn)的晶圓級(jí)(Wafer-scale)AI芯片及計(jì)算系統(tǒng),通過(guò)打破光刻工藝中的光罩限制,探索超越光罩面積的計(jì)算架構(gòu),在硅晶圓上構(gòu)建跨越光刻機(jī)光罩單次曝光區(qū)域的高密度金屬互連線(xiàn),將多個(gè)管芯組合成為硅晶圓尺寸的超大計(jì)算系統(tǒng),實(shí)現(xiàn)晶體管與互連資源2個(gè)數(shù)量級(jí)以上的提升。
目前工業(yè)界最主要的晶圓級(jí)集成產(chǎn)品以Cerebras的WSE(Wafer Scale Engine)系列芯片為代表。WSE第一代芯片采用臺(tái)積電16 nm工藝制程,裸片尺寸達(dá)46225 mm2,包含超過(guò)1.2萬(wàn)億個(gè)晶體管,擁有高達(dá)18 GB的片上內(nèi)存和9 PB/s的內(nèi)存帶寬。單顆芯片上集成了40萬(wàn)個(gè)稀疏線(xiàn)性代數(shù)內(nèi)核,相當(dāng)于數(shù)百個(gè)GPU集群的算力。WSE第二代芯片采用臺(tái)積電7 nm工藝制程,得益于工藝的進(jìn)步,單片集成晶體管數(shù)目達(dá)到2.6萬(wàn)億個(gè),單芯片集成了40 GB SRAM,存儲(chǔ)帶寬達(dá)到20 PB/s。
晶圓級(jí)集成涉及芯片設(shè)計(jì)、制造、封裝和散熱等眾多技術(shù)。設(shè)計(jì)方面,將整個(gè)晶圓看作1顆芯片,必然要考慮制造良率問(wèn)題,因此需要在架構(gòu)和電路上進(jìn)行冗余設(shè)計(jì)和容錯(cuò)設(shè)計(jì)。制造方面,如何實(shí)現(xiàn)相鄰光刻區(qū)域的金屬互連線(xiàn)的精確連接且電連通也是一個(gè)需要解決的工程問(wèn)題。封裝方面,由于晶圓級(jí)芯片面積遠(yuǎn)遠(yuǎn)大于普通芯片,需要開(kāi)發(fā)配套專(zhuān)用的先進(jìn)封裝技術(shù)。此外,晶圓級(jí)集成的芯片功耗往往非常大,對(duì)散熱提出了重大考驗(yàn),需要設(shè)計(jì)專(zhuān)門(mén)的散熱模塊,例如使用金屬導(dǎo)熱加水冷等方式進(jìn)行散熱。
作為人工智能新時(shí)代顛覆性的算力解決方案,晶圓級(jí)芯片已經(jīng)得到了美國(guó)科技公司巨頭及國(guó)家實(shí)驗(yàn)室的重視。該領(lǐng)域處于起步階段,且晶圓級(jí)芯片可以不依賴(lài)于傳統(tǒng)先進(jìn)光刻工藝,而是基于對(duì)高端光刻機(jī)不敏感的先進(jìn)封裝集成工藝進(jìn)行實(shí)現(xiàn),可以基于國(guó)內(nèi)較完善的封裝集成產(chǎn)業(yè)基礎(chǔ)進(jìn)行全自主技術(shù)攻關(guān)。
06基于新材料和新器件的算力提升途徑
除了架構(gòu)改進(jìn),通過(guò)提高晶體管的工作速度提升“TOPS/晶體管數(shù)”,是實(shí)現(xiàn)高算力芯片的重要方法。在商用CMOS工藝節(jié)點(diǎn)進(jìn)入深亞微米后,各種非理想效應(yīng)——短溝道效應(yīng)、熱載流子效應(yīng)等嚴(yán)重影響了小尺寸CMOS器件的工作狀態(tài),晶體管速度提升受限。基于新材料構(gòu)建新晶體管器件,有望打破傳統(tǒng)限制。
目前,比較有代表性的路線(xiàn),一條是使用具有高遷移率的材料替代傳統(tǒng)的單晶硅材料,以保證晶體管具有足夠的驅(qū)動(dòng)能力。2020年,來(lái)自美國(guó)加利福尼亞大學(xué)洛杉磯分校(UCLA)的研究人員制備了溝道長(zhǎng)度為67 nm的石墨烯晶體管,其遷移率高于1000 cm2/Vs,大約是傳統(tǒng)單晶硅材料的15倍,同時(shí)其截止頻率可達(dá)427 GHz。另一條是使用對(duì)短溝道非理想效應(yīng)具有一定抗性的材料,緩解晶體管尺寸微縮過(guò)程中由于非理想因素導(dǎo)致的速度下降,例如采用MoS2等金屬硫化物作為溝道材料。基于石墨烯、MoS2等溝道材料的晶體管在學(xué)界已有長(zhǎng)足發(fā)展,但仍然需要繼續(xù)研發(fā)、改進(jìn)大規(guī)模生產(chǎn)工藝,例如均一化生長(zhǎng)工藝、鈍化工藝等,使其可以盡快落地。
另外,兼具高遷移率和對(duì)非理想效應(yīng)抗性的碳納米管晶體管(Carbon Nanotube Transistor, CNT)也備受關(guān)注。北京大學(xué)彭練矛團(tuán)隊(duì)制備了遷移率為1600 cm2/Vs的CNT晶體管;斯坦福大學(xué)與臺(tái)積電合作制備了溝道長(zhǎng)度為15 nm的CNT晶體管,亞閾值擺幅接近60 mV/dec,表現(xiàn)出對(duì)短溝道效應(yīng)的強(qiáng)抗性。
07結(jié)束語(yǔ)
算力在國(guó)家數(shù)字化轉(zhuǎn)型和經(jīng)濟(jì)發(fā)展中起到越來(lái)越重要的作用,作為算力載體和依托,必須重視高算力芯片的發(fā)展。通過(guò)分解芯片算力構(gòu)成,指出提升互連帶寬、單位晶體管算力、晶體管密度和芯片面積均可提升算力水平。在后摩爾時(shí)代,進(jìn)一步分析了未來(lái)提升芯片算力的關(guān)鍵技術(shù),探討了實(shí)現(xiàn)大于1000 TOPS以及更高算力芯片的發(fā)展路徑——應(yīng)繼續(xù)投入先進(jìn)制程實(shí)現(xiàn)尺寸微縮、布局芯粒技術(shù)和晶圓級(jí)集成、發(fā)力存算一體等新型計(jì)算架構(gòu)等,這些技術(shù)相對(duì)比較成熟,容易實(shí)現(xiàn);探究超越CMOS技術(shù)的新器件、新材料,也有望另辟蹊徑,推動(dòng)高算力芯片的發(fā)展(圖10)。除此之外,還有一些蓬勃發(fā)展的技術(shù),試圖通過(guò)探索新型計(jì)算范式實(shí)現(xiàn)算力飛躍,如類(lèi)腦計(jì)算、光計(jì)算和量子計(jì)算等,這些技術(shù)通過(guò)模仿人腦、設(shè)計(jì)光學(xué)結(jié)構(gòu)、實(shí)現(xiàn)量子邏輯等手段形成全新的計(jì)算系統(tǒng)。這類(lèi)新興的計(jì)算范式尚處于起步階段,與高算力芯片、系統(tǒng)的關(guān)系尚不明確,隨著技術(shù)的不斷成熟,有望在未來(lái)成為現(xiàn)有技術(shù)的重要補(bǔ)充。

圖10高算力芯片突破路徑
另外,現(xiàn)階段大國(guó)博弈加劇全球產(chǎn)業(yè)鏈、供應(yīng)鏈重構(gòu),同時(shí)中國(guó)集成電路先進(jìn)工藝的開(kāi)發(fā)受到制約,單純依靠先進(jìn)制程等技術(shù)的單點(diǎn)突破成本高、周期長(zhǎng)。因此,在補(bǔ)全產(chǎn)業(yè)鏈短板、攻堅(jiān)關(guān)鍵技術(shù)的同時(shí),還應(yīng)充分利用現(xiàn)有產(chǎn)業(yè)鏈和研究基礎(chǔ),從系統(tǒng)層次布局多途徑協(xié)同方案,采用國(guó)內(nèi)成熟、領(lǐng)先的技術(shù)和計(jì)算架構(gòu),摸索更加高效可行的技術(shù)路徑。為實(shí)現(xiàn)高算力芯片不斷突破,需要扎根于中國(guó)現(xiàn)有產(chǎn)業(yè)基礎(chǔ),探尋底層計(jì)算架構(gòu)的變革性方法,探索“架構(gòu)+集成+系統(tǒng)”協(xié)同一體的自主可控創(chuàng)新路徑。采用成熟制程和先進(jìn)集成,結(jié)合CGRA和存算一體等國(guó)內(nèi)領(lǐng)先的新型架構(gòu),在芯粒技術(shù)基礎(chǔ)上實(shí)現(xiàn)晶圓級(jí)的高算力芯片是一條可行的突破路徑,該路徑能夠利用現(xiàn)有優(yōu)勢(shì)技術(shù),在更低的成本投入下,更快地提升芯片算力。
審核編輯 :李倩
-
芯片
+關(guān)注
關(guān)注
454文章
50460瀏覽量
421971 -
數(shù)據(jù)中心
+關(guān)注
關(guān)注
16文章
4700瀏覽量
71971 -
人工智能
+關(guān)注
關(guān)注
1791文章
46896瀏覽量
237669
原文標(biāo)題:高算力芯片未來(lái)技術(shù)發(fā)展途徑
文章出處:【微信號(hào):算力基建,微信公眾號(hào):算力基建】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
華為發(fā)布數(shù)據(jù)通信未來(lái)技術(shù)趨勢(shì)報(bào)告
GPU算力開(kāi)發(fā)平臺(tái)是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】--全書(shū)概覽
AI網(wǎng)絡(luò)物理層底座: 大算力芯片先進(jìn)封裝技術(shù)
名單公布!【書(shū)籍評(píng)測(cè)活動(dòng)NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析
億鑄科技談大算力芯片面臨的技術(shù)挑戰(zhàn)和解決策略
IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書(shū)
算力中心:數(shù)字經(jīng)濟(jì)發(fā)展的新引擎

高算力芯片:未來(lái)科技的加速器?

智能算力規(guī)模超通用算力,大模型對(duì)智能算力提出高要求

是德科技智能算力‘芯’技術(shù)研討會(huì)回顧
慧能泰出席第十四屆亞洲電源技術(shù)發(fā)展論壇
大算力芯片里的HBM,你了解多少?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論