") CPU Cache偽共享問題
CPU Cache偽共享問題
先看下這兩段代碼:
代碼段1:
const int row = 10240; const int col = 10240; int matrix[row][col]; int TestRow() { //按行遍歷 int sum_row = 0; for (int r = 0; r < row; r++) { for (int c = 0; c < col; c++) { sum_row += matrix[r][c]; } } return sum_row; }
代碼段2:
int TestCol() {
//按列遍歷
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
return sum_col;
}
兩段代碼的目的相同,都是為了計(jì)算矩陣中所有元素的總和。
但有些區(qū)別:一個(gè)是按行遍歷元素做計(jì)算,一個(gè)是按列遍歷元素做計(jì)算。
它倆的運(yùn)行速度有什么區(qū)別嗎?
如圖:


圖中可以看到,行遍歷的代碼速度比列遍歷的代碼速度快很多。
為什么按行遍歷的代碼比按列遍歷的代碼速度快?這里就是CPU Cache在起作用。
什么是CPU Cache?
可以先看下這個(gè)存儲(chǔ)器相關(guān)的金字塔圖:

從下到上,空間雖然越來越小,但是處理速度越來越快,相應(yīng)的,設(shè)備價(jià)格也越來越貴。
圖中的寄存器和主存估計(jì)大家都知道,那中間的L1 、L2、L3是什么?它們起到了什么作用?
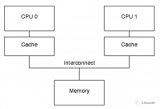
它們就是CPU 的Cache,如下圖:

可以理解為CPU Cache就是CPU與主存之間的橋梁。
當(dāng)CPU想要訪問主存中的元素時(shí),會(huì)先查看Cache中是否存在,如果存在(稱為Cache Hit),直接從Cache中獲取,如果不存在(稱為Cache Miss),才會(huì)從主存中獲取。Cache的處理速度比主存快得多。
所以,如果每次訪問數(shù)據(jù)時(shí),都能直接從Cache中獲取,整個(gè)程序的性能肯定會(huì)更高。
那,如何提高CPU Cache的命中率?
但CPU Cache這里還有個(gè)小問題,看下這兩段代碼:
代碼段1:
struct Point {
std::atomic x;
// char a[128];
std::atomic y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
代碼段2:
struct Point {
std::atomic x;
char a[128];
std::atomic y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
兩端代碼的核心邏輯都是對Point結(jié)構(gòu)體中的x和y不停+1。只有一點(diǎn)區(qū)別就是在中間塞了128字節(jié)的數(shù)組。
它們的執(zhí)行速度卻相差很大。

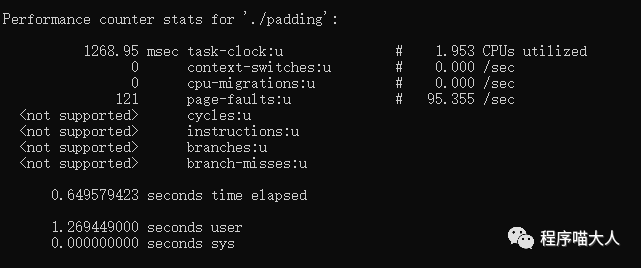
帶128的比不帶128的代碼,執(zhí)行速度快很多。
為什么?
看過我上面文章的同學(xué)應(yīng)該就知道,每個(gè)CPU都有自己的L1和L2 Cache,而Cache line的大小一般是64字節(jié),如果x和y之間沒有128字節(jié)的填充,它倆就會(huì)在同一個(gè)Cache line上。
代碼中開了兩個(gè)線程,兩個(gè)線程大概率會(huì)運(yùn)行在不同的CPU上,每個(gè)CPU有自己的Cache。
當(dāng)CPU1操作x時(shí),會(huì)把y裝載到Cache中,其他CPU對應(yīng)的的Cache line失效。
然后CPU2加載y,會(huì)觸發(fā)Cache Miss,它后面又把x裝載到了自己的Cache中,其他CPU對應(yīng)的Cache line失效。
然后CPU1操作x時(shí),又觸發(fā)Cache Miss。
它倆就會(huì)是大體這個(gè)流程:
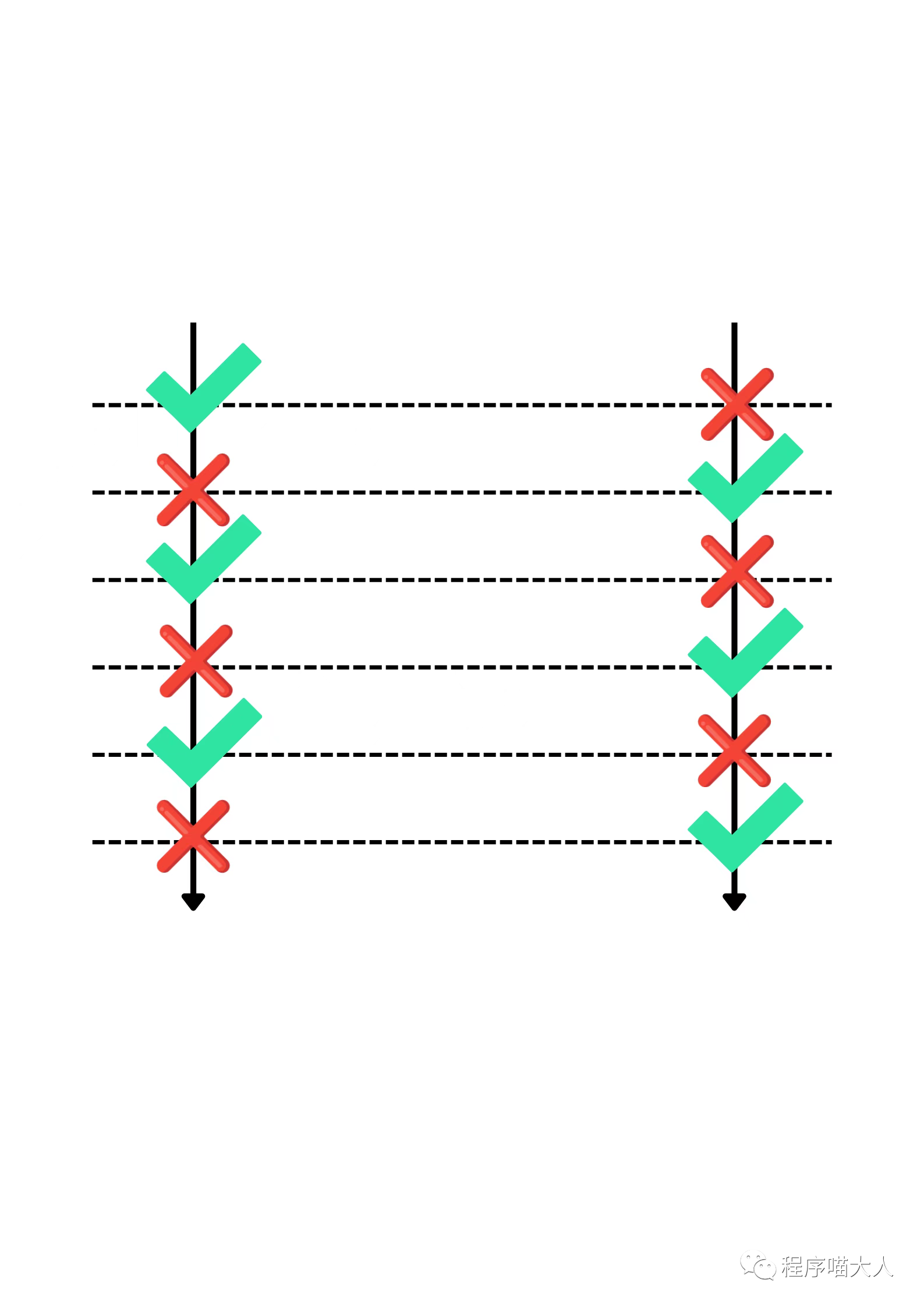
頻繁的觸發(fā)Cache Miss,導(dǎo)致程序的性能相當(dāng)差。
而如果x和y中間加了128字節(jié)的填充,x和y不在同一個(gè)Cache line上,不同CPU之前不會(huì)影響,它倆都會(huì)頻繁的命中自己的Cache,整個(gè)程序性能就會(huì)很高,這就是傳說中的False Sharing問題。
所以我們寫代碼時(shí),可以基于此做深一層思考,如果我們寫單線程程序,最好保證訪問的數(shù)據(jù)能夠相鄰,在一個(gè)Cache line上,可以盡可能的命中Cache。
如果寫多線程程序,最好保證訪問的數(shù)據(jù)有間隔,讓它們不在一個(gè)Cache line上,減少False Sharing的頻率。
審核編輯:郭婷
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7452瀏覽量
163605 -
cpu
+關(guān)注
關(guān)注
68文章
10825瀏覽量
211146
原文標(biāo)題:CPU Cache偽共享問題
文章出處:【微信號:程序喵大人,微信公眾號:程序喵大人】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
OPA1642做一個(gè)差分和偽差分輸出轉(zhuǎn)換的電路,在偽差分的情況下遇到的問題求解
Cache和內(nèi)存有什么區(qū)別
德國進(jìn)口蔡司工業(yè)CT去散射偽影技術(shù)

解析Arm Neoverse N2 PMU事件L2D_CACHE_WR

什么是CPU緩存?它有哪些作用?
Cortex R52內(nèi)核Cache的具體操作(2)

Cortex R52內(nèi)核Cache的相關(guān)概念(1)
CortexR52內(nèi)核Cache的具體操作

為什么HAL庫在操作Flash erase的時(shí)候,需要把I-Cache和D-Cache關(guān)閉呢?
請問STM32MP13X的MMU和Cache如何使能?
先楫 HPM片上 Cache使用指南

先楫HPM片上Cache使用指南經(jīng)驗(yàn)分享
深入理解Linux RCU:從硬件說起之內(nèi)存屏障
buffer和cache的區(qū)別
CPU Cache是如何保證緩存一致性的?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論