") 目前HD地圖構(gòu)建的四種主流方案的優(yōu)勢與不足對比
目前HD地圖構(gòu)建的四種主流方案的優(yōu)勢與不足對比
高精度(High-Definition, HD)語義地圖是目前自動(dòng)駕駛領(lǐng)域的一個(gè)重要研究方向,近年隨著Transformer和BEV的大火,很多大佬團(tuán)隊(duì)都開展了HD語義地圖構(gòu)建相關(guān)的工作。2021年7月,清華大學(xué)MARS實(shí)驗(yàn)室提出了HDMapNet。緊隨其后,同一團(tuán)隊(duì)又在今年6月公開了后續(xù)工作VectorMapNet。同時(shí),MIT和上海交通大學(xué)也在今年5月提出了BEVFusion。今年11月底的時(shí)候,蘇黎世聯(lián)邦理工學(xué)院、毫末、國防科大、阿爾托大學(xué)又聯(lián)合開發(fā)了SuperFusion。這四種方案基本上就是目前HD地圖構(gòu)建的主流方案。
本文將帶領(lǐng)讀者深入探討這四種方案的優(yōu)勢與不足,通過對比方案來思考HD地圖構(gòu)建的重點(diǎn)與難點(diǎn)。當(dāng)然筆者水平有限,如果有理解錯(cuò)誤的地方歡迎大家一起討論,共同學(xué)習(xí)。 溫馨提示,本文討論的方案都是開源的,各位讀者可以在這些工作的基礎(chǔ)上開展自己的研究!文末附原文鏈接和代碼鏈接!
1. 為什么自動(dòng)駕駛都要做BEV感知?
先說答案:因?yàn)樽詣?dòng)駕駛要求的是空間感知單純的前視攝像頭輸入,看到的只是有限視角內(nèi)的畫面。而自動(dòng)駕駛?cè)蝿?wù)要求的是對車輛周圍整體空間范圍內(nèi)的感知,因此往往需要對輸入的環(huán)視相機(jī)/激光雷達(dá)進(jìn)行投影,轉(zhuǎn)到BEV視角下進(jìn)行HD地圖的構(gòu)建。 那么BEV感知的難點(diǎn)是什么呢? 在自動(dòng)駕駛的車道線檢測、可行駛區(qū)域檢測等任務(wù)中,都是針對前視攝像頭輸入進(jìn)行逐像素的分割/檢測,每個(gè)輸入像素都對應(yīng)一個(gè)輸出類別。這種一一對應(yīng)的關(guān)系使得我們可以很容易得應(yīng)用CNN/Transformer模型進(jìn)行分割/檢測。 但自動(dòng)駕駛BEV感知已經(jīng)不僅僅是2D感知問題,在空間變換的過程中像素很有可能發(fā)生畸變!比如,前視攝像頭中的車輛,轉(zhuǎn)換到BEV視角下可能已經(jīng)不是車輛的形狀了!再比如,前視攝像頭中相鄰很近的兩個(gè)物體,轉(zhuǎn)換到BEV視角下變得相隔很遠(yuǎn)。
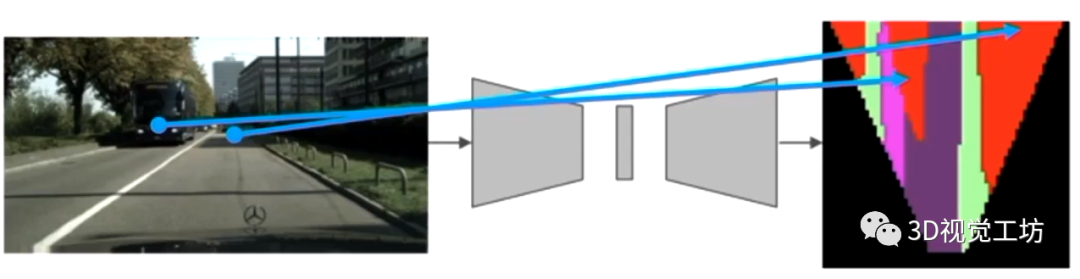
既然如此,可不可以先針對圖像進(jìn)行分割處理,然后再投影到BEV視角呢? 理論上來說這是一個(gè)很好的解決思路,避免了三維物體在投影過程中產(chǎn)生的畸變,但在實(shí)際操作過程中,會(huì)發(fā)現(xiàn)很容易造成多相機(jī)之間的不一致問題!

因此,需要直接針對BEV空間進(jìn)行處理以構(gòu)建HD地圖!此外,BEV空間也使得相機(jī)和雷達(dá)的融合變得簡單。
2. 傳統(tǒng)的HD語義地圖構(gòu)建有什么問題?
先說說傳統(tǒng)的HD地圖構(gòu)建方案: 基本上目前SLAM的落地方案都是分成兩部分,一個(gè)是配備高精度傳感器的地圖采集車,用于對環(huán)境信息進(jìn)行高精度的采集和處理,一個(gè)是乘用車,也就是大家所熟知的SLAM中的僅定位。 具體思路是,首先利用高精度傳感器(雷達(dá)/IMU/相機(jī)/GPS/輪速計(jì))在園區(qū)上來回往復(fù)運(yùn)行,得到帶有回環(huán)的軌跡以后基于SLAM方法獲得全局一致性地圖,后面交友標(biāo)注員進(jìn)行手工處理,得到靜態(tài)HD地圖。后面的乘用車就是將自身提取到的特征和前面構(gòu)建的HD地圖進(jìn)行特征匹配,進(jìn)行僅定位。這么做有什么問題呢?(1) 整體的Pipeline非常長,導(dǎo)致工藝流程非常繁瑣。 (2) 手工標(biāo)注需要消耗大量人力。不知道大家有沒有手動(dòng)打深度學(xué)習(xí)標(biāo)簽的經(jīng)歷,真的是非常痛苦。 (3) 需要在實(shí)際運(yùn)行過程中更新地圖。我認(rèn)為這也是最重要的一點(diǎn),上述基于手工方法構(gòu)建的HD地圖是完全的靜態(tài)地圖,但實(shí)際運(yùn)行場景必然與之前構(gòu)建的地圖有所區(qū)別(比如某個(gè)車移動(dòng)了位置,某個(gè)箱子轉(zhuǎn)運(yùn)到了其他位置)。所以乘用車在實(shí)際運(yùn)行過程中需要實(shí)時(shí)更新并存儲(chǔ)HD地圖,這也是個(gè)非常繁瑣的課題。但基于學(xué)習(xí)的端到端的方案是可以解決這一問題的,雖然從目前來看基于學(xué)習(xí)的方案在精度上還稍有不足,但相信這一問題可以很快被解決。
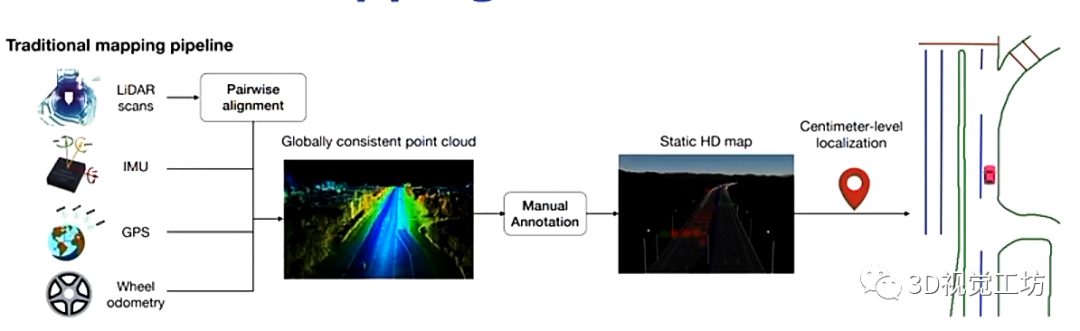
我們希望實(shí)現(xiàn)什么效果呢?(1) 簡單,最好是端到端的網(wǎng)絡(luò)架構(gòu)。 (2) 自動(dòng)、在線得構(gòu)建HD地圖。 (3) 能夠不受動(dòng)態(tài)環(huán)境影響,直接構(gòu)建HD地圖。
3. 清華大學(xué)開源HDMapNet
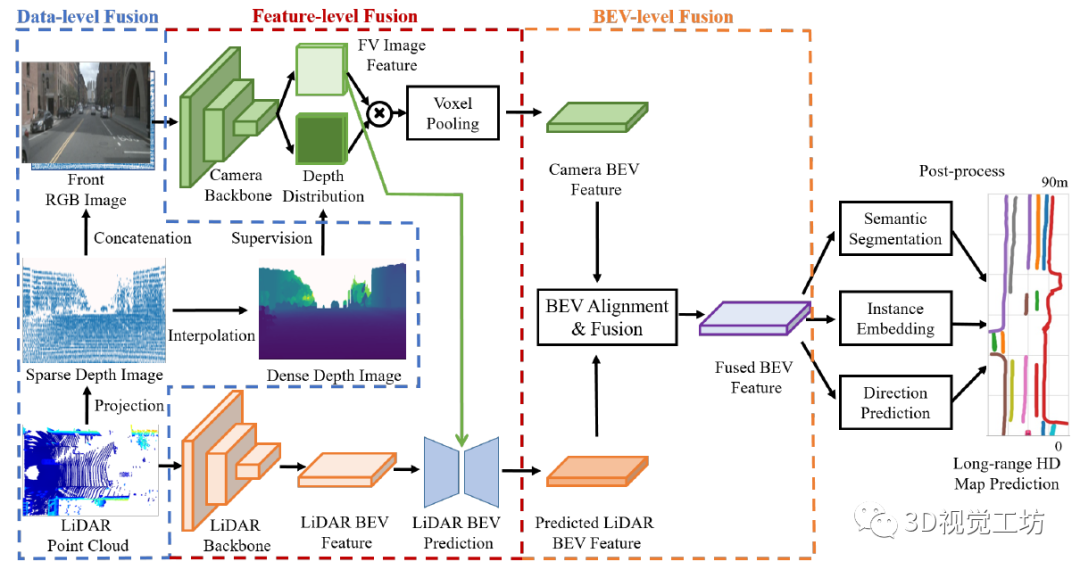
清華大學(xué)2021年7月開源的HDMapNet,其主要思路是輸入環(huán)視相機(jī)和雷達(dá)點(diǎn)云,將相機(jī)和雷達(dá)點(diǎn)云分別進(jìn)行特征提取后投影到BEV空間,在BEV空間里進(jìn)行特征融合。注意,在BEV空間里進(jìn)行特征融合是非常有優(yōu)勢的!之后,便是在BEV空間內(nèi)進(jìn)行解碼。解碼器共有三個(gè)輸出,第一是地圖的語義分割結(jié)果,里面包含了地圖里哪個(gè)是車道線、哪個(gè)是路標(biāo)、哪個(gè)是人行橫道線。第二是實(shí)例Embedding,里面包含了實(shí)例信息,主要表達(dá)車道線和車道線直接、路標(biāo)和路標(biāo)之間的實(shí)例區(qū)分。第三是方向信息,主要表達(dá)了HD地圖中每條線的方向。最后,語義分割HD地圖首先和實(shí)例Embedding進(jìn)行融合,得到實(shí)例化的HD地圖,并融合方向信息以及NMS得到矢量化的HD地圖。
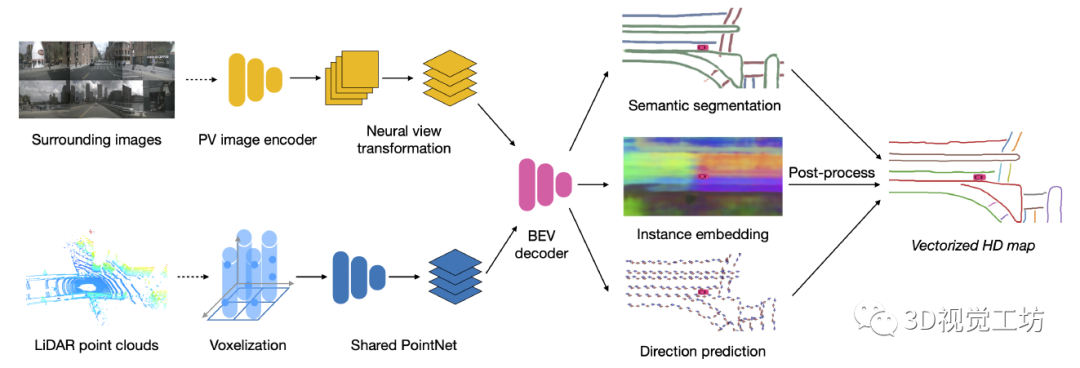
需要特別注意的是,HDMapNet并不一定需要做多傳感器融合,純相機(jī)或者純雷達(dá)也是可以基于HDMapNet構(gòu)建HD地圖,只是效果相對要弱一些。HDMapNet的結(jié)果顯示,相機(jī)對于車道線、人行橫道線這種視覺紋理豐富的特征識別的較好,雷達(dá)對于路沿這種物理邊界的效果更好。 但純相機(jī)或純雷達(dá)的操作真的給一些經(jīng)費(fèi)受限的小伙伴帶來了福音!

一句話總結(jié):HDMapNet實(shí)現(xiàn)了多模態(tài)BEV視角下的HD地圖構(gòu)建!
4. 清華大學(xué)后續(xù)工作VectorMapNet
我們可以發(fā)現(xiàn),HDMapNet的重點(diǎn)在于BEV空間下的特征提取。 但問題是,這個(gè)Pipeline仍然有點(diǎn)長了,有沒有更加端到端的方案?也就是說,直接輸入圖像和雷達(dá),經(jīng)過某個(gè)深度神經(jīng)網(wǎng)絡(luò),直接輸出HD地圖。為解決這個(gè)問題,清華大學(xué)MARS實(shí)驗(yàn)室今年6月又開源了新的工作VectorMapNet。他們的思路是啥? (1) 需要找到一種更合適的圖形來表示HD地圖,MARS實(shí)驗(yàn)室認(rèn)為折線更有利于HD地圖的表達(dá)。此外,谷歌2020年的CVPR論文VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation也提出了這種用折線來表達(dá)HD地圖的方案,谷歌官方?jīng)]有開源,但Github上有Pytorch實(shí)現(xiàn)https://github.com/Henry1iu/TNT-Trajectory-Prediction,感興趣的小伙伴可以復(fù)現(xiàn)一下,但目前該網(wǎng)絡(luò)仍然需要非常大的顯存(128G+)。 (2) 之前的HDMapNet還是處理的分割問題,但如果將分割問題轉(zhuǎn)換為檢測問題,會(huì)更有利于矢量地圖的構(gòu)建。 (3) 基于DETR進(jìn)行開發(fā)有利于HD地圖的構(gòu)建。
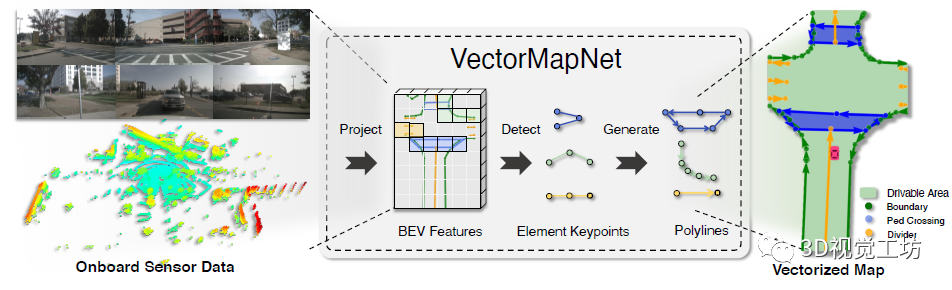
其實(shí),VectorMapNet的網(wǎng)絡(luò)架構(gòu)就是三個(gè)部分:投影、檢測、生成。投影就類似HDMapNet,將輸入的相機(jī)和雷達(dá)轉(zhuǎn)換到BEV視角,得到BEV特征圖。檢測就是提取HD地圖元素,具體來說就是基于Query來提取關(guān)鍵點(diǎn),這里的關(guān)鍵點(diǎn)可以是車道線的起點(diǎn)、終點(diǎn)、中間點(diǎn)。這個(gè)檢測的思想其實(shí)非常巧妙,它沒有在中間過程就得到非常多的輸出點(diǎn),而是選取了更簡潔更統(tǒng)一化的表示!生成就是指得到折線化矢量化的HD地圖,也是一個(gè)自回歸模型,具體思路也是基于Transformer回歸每個(gè)頂點(diǎn)坐標(biāo)。 雖然整體來看架構(gòu)有些復(fù)雜,但這個(gè)網(wǎng)絡(luò)是直接端到端的,有利于訓(xùn)練和應(yīng)用。筆者個(gè)人感覺,VectorMapNet的一個(gè)更有意思的點(diǎn)在于,它是一個(gè)端到端的多階段網(wǎng)絡(luò)。也就是說,網(wǎng)絡(luò)不再是一個(gè)完全的黑盒子。如果網(wǎng)絡(luò)的輸出結(jié)果出現(xiàn)漏檢/誤檢,那么我們可以打印出中間的關(guān)鍵點(diǎn),看看具體是哪一個(gè)階段出現(xiàn)了問題。
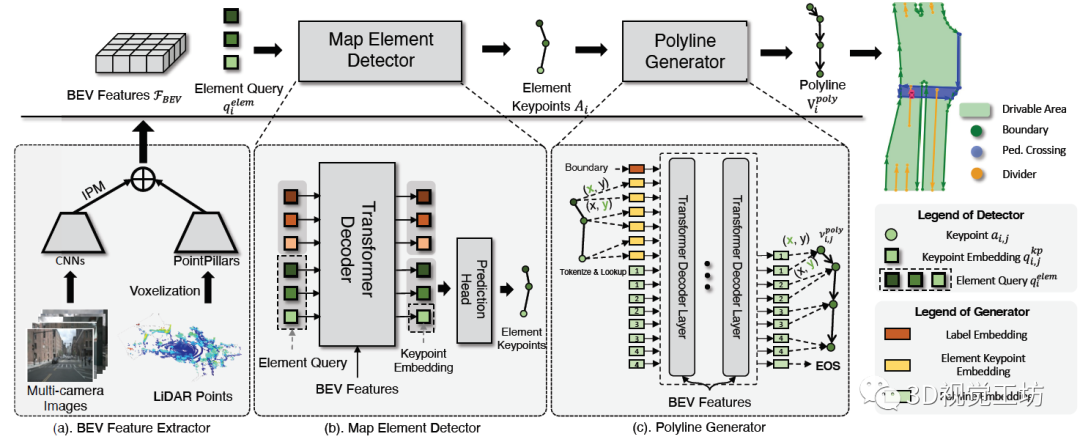
結(jié)果顯示,VectorMapNet這種基于檢測的方案性能遠(yuǎn)超HDMapNet。例如在人行橫道上的預(yù)測AP提升了幾乎32個(gè)點(diǎn),在整體的mAP上也提升了22.7個(gè)點(diǎn)。
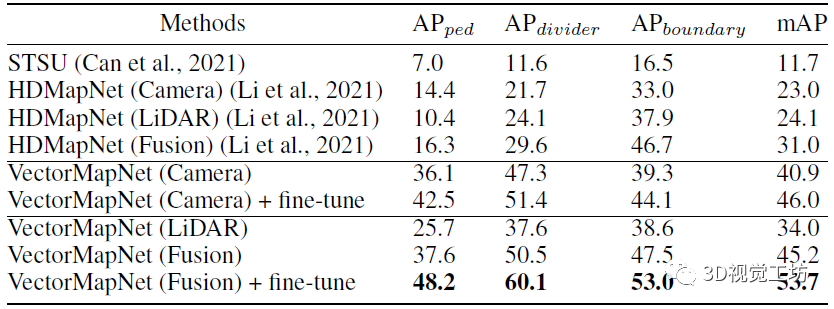
從定性結(jié)果也可以看出,VectorMapNet對于細(xì)節(jié)的把握是非常好的。HDMapNet和STSU經(jīng)常出現(xiàn)漏檢,但VectorMapNet很少。在Ground Truth上的車道線有時(shí)會(huì)出現(xiàn)一些細(xì)小的波折,HDMapNet和STSU很難檢測出來,但VectorMapNet提取的HD地圖輪廓與真值更吻合。 說到這里,也肯定有小伙伴關(guān)心VectorMapNet端到端方案和HDMapNet后處理方案之間的優(yōu)劣。可以發(fā)現(xiàn)的是,HDMapNet在進(jìn)行一些后處理時(shí),很容易將一條檢測線檢測為兩條,這主要是由于分割過程中對于車道線的分割結(jié)果過寬導(dǎo)致的。在實(shí)際使用中,這種將一條車道線檢測為兩條的結(jié)果會(huì)導(dǎo)致很嚴(yán)重的問題。這也說明了基于檢測的HD地圖方案要優(yōu)于基于分割的HD地圖方案。
不僅如此,VectorMapNet更強(qiáng)大的地方在于,它甚至可以檢測出來未標(biāo)注的車道線!從下圖可以看出,在原始的數(shù)據(jù)集中漏標(biāo)了一條車道線,HDMapNet無法檢測出來,但VectorMapNet卻輸出了這一結(jié)果。
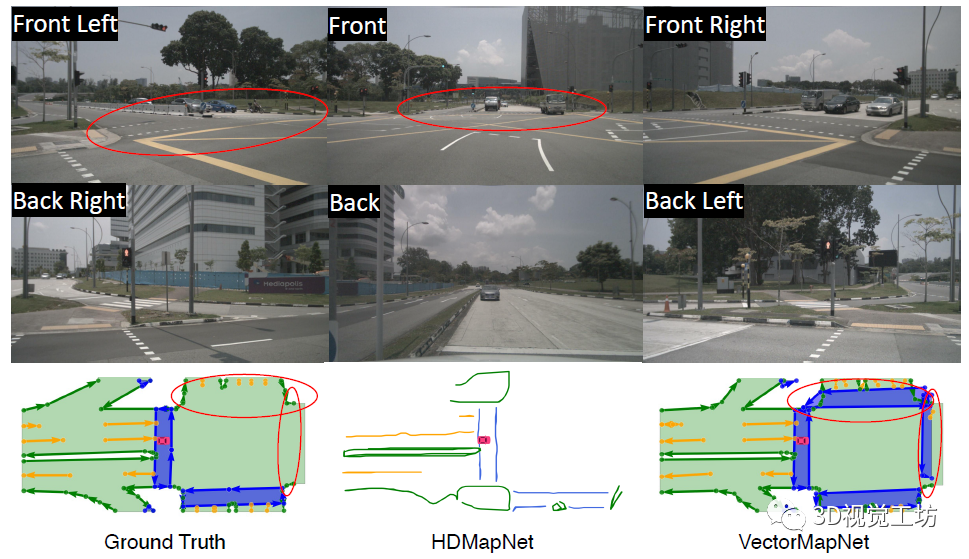
一句話總結(jié):VectorMapNet基于檢測思路優(yōu)化了HDMapNet!
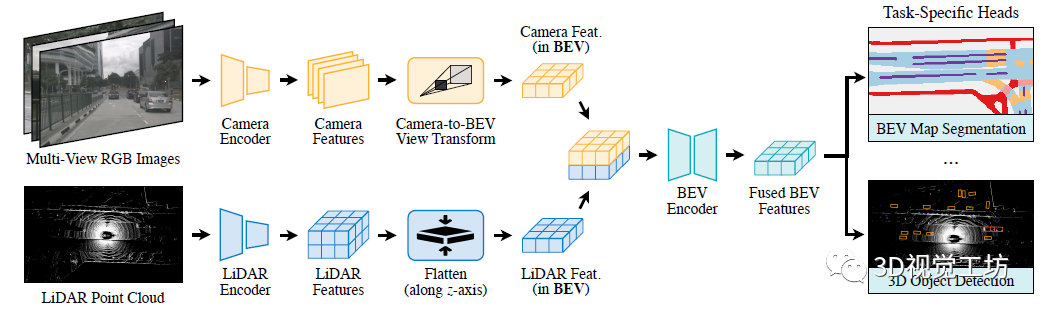
5. MIT&上交&OmniML開源BEVFusion
這篇文章大家就都比較熟悉了, MIT韓松團(tuán)隊(duì)開源的BEVFusion,文章題目是BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation。注意和NeurIPS 2022論文BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework要區(qū)分開。 單從網(wǎng)絡(luò)架構(gòu)上來看,感覺和HDMapNet原理非常類似,都是先從相機(jī)、雷達(dá)輸入分別提取特征并投影到BEV空間,然后做BEV視角下的解碼,輸出結(jié)果不太相同,BEVFusion除了HD地圖外還輸出了3D目標(biāo)檢測的結(jié)果。 這篇文章其實(shí)解答了困惑我很久的一個(gè)問題,就是為什么不先把圖像投影到雷達(dá),或者雷達(dá)投影到圖像,然后再一起轉(zhuǎn)到BEV空間下,而是要分別提取特征再到BEV空間下進(jìn)行特征融合。這是因?yàn)橄鄼C(jī)到激光雷達(dá)的投影丟掉了相機(jī)特征的語義密度,對于面向語義的任務(wù)(如三維場景分割)有非常大的影響。

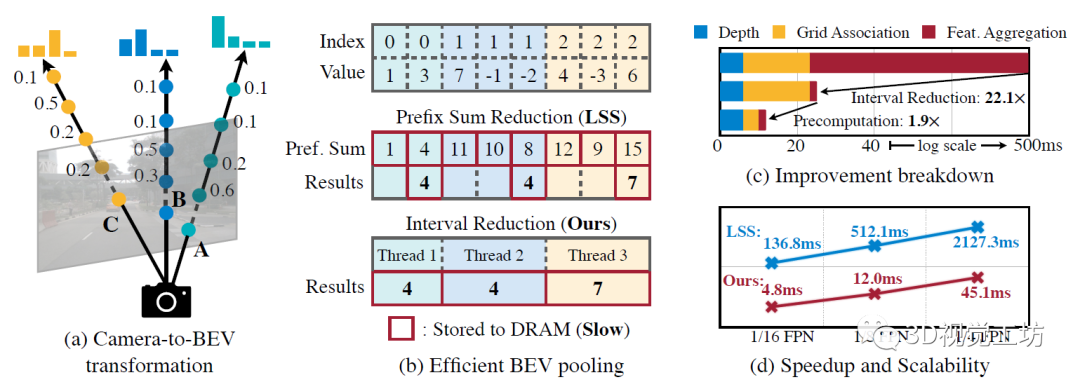
感覺BEVFusion的主要?jiǎng)?chuàng)新點(diǎn)還是基于BEV池化提出了兩個(gè)效率優(yōu)化方法:預(yù)計(jì)算與間歇降低。預(yù)計(jì)算:BEV池化的第一步是將攝像頭特征點(diǎn)云的每個(gè)點(diǎn)與BEV網(wǎng)格相關(guān)聯(lián)。與激光雷達(dá)點(diǎn)云不同,攝像頭特征點(diǎn)云的坐標(biāo)是固定的。基于此,預(yù)計(jì)算每個(gè)點(diǎn)的3D坐標(biāo)和BEV網(wǎng)格索引。還有根據(jù)網(wǎng)格索引對所有點(diǎn)進(jìn)行排序,并記錄每個(gè)點(diǎn)排名。在推理過程中,只需要根據(jù)預(yù)計(jì)算的排序?qū)λ刑卣鼽c(diǎn)重排序。這種緩存機(jī)制可以將網(wǎng)格關(guān)聯(lián)的延遲從17ms減少到4ms。間歇降低: 網(wǎng)格關(guān)聯(lián)后,同一BEV網(wǎng)格的所有點(diǎn)將在張量表征中連續(xù)。BEV池化的下一步是通過一些對稱函數(shù)(例如,平均值、最大值和求和)聚合每個(gè)BEV網(wǎng)格內(nèi)的特征。現(xiàn)有的實(shí)現(xiàn)方法首先計(jì)算所有點(diǎn)的前綴和,然后減去索引發(fā)生變化的邊界值。然而,前綴和操作,需要在GPU進(jìn)行樹縮減(tree reduction),并生成許多未使用的部分和(因?yàn)橹恍枰吔缰担@兩種操作都是低效的。為了加速特征聚合,BEVFusion里實(shí)現(xiàn)一個(gè)專門的GPU內(nèi)核,直接在BEV網(wǎng)格并行化:為每個(gè)網(wǎng)格分配一個(gè)GPU線程,該線程計(jì)算其間歇和(interval sum)并將結(jié)果寫回。該內(nèi)核消除輸出之間的依賴關(guān)系(因此不需要多級樹縮減),并避免將部分和寫入DRAM,從而將特征聚合的延遲從500ms減少到2ms。 通過優(yōu)化的BEV池化,攝像頭到BEV的轉(zhuǎn)換速度提高了40倍:延遲從500ms減少到12ms(僅為模型端到端運(yùn)行時(shí)間的10%),并且可以在不同的分特征辨率之間很好地?cái)U(kuò)展。
輸出結(jié)果也很漂亮:聯(lián)合實(shí)現(xiàn)了3D目標(biāo)檢測和語義地圖構(gòu)建。

一句話總結(jié):BEVFusion大幅降低了計(jì)算量!
6. 蘇黎世聯(lián)邦理工開源SuperFusion
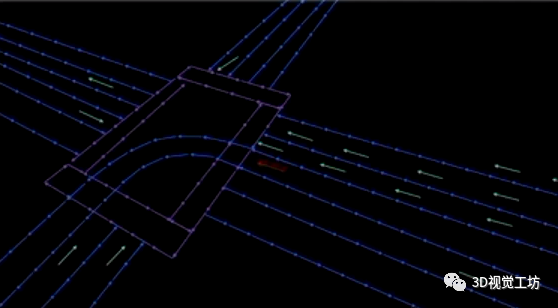
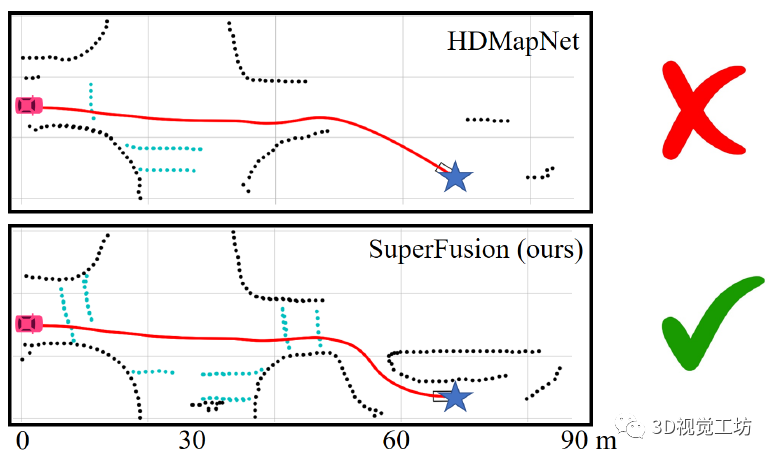
說實(shí)話,這項(xiàng)工作感覺非常驚艷! HDMapNet和VectorMapNet的指導(dǎo)老師趙行教授也表示過,現(xiàn)有的基于學(xué)習(xí)的HD地圖構(gòu)建方案的主要問題在于,所構(gòu)建的HD地圖仍然是短距離地圖,對于長距離表達(dá)還有一些不足。而SuperFusion這項(xiàng)工作就專門解決了這個(gè)長距離HD建模問題,它可以構(gòu)建90m左右的HD地圖,而同年提出的HDMapNet建模長度也不過30m。 如下圖所示,紅色汽車代表汽車當(dāng)前的位置,藍(lán)色星星代表目標(biāo)。結(jié)果顯示,SuperFusion在生成短程(30 m)的HD語義地圖基礎(chǔ)上,預(yù)測高達(dá)90 m距離的遠(yuǎn)程HD語義地圖。這給自動(dòng)駕駛下游路徑規(guī)劃和控制模塊提供了更強(qiáng)平穩(wěn)性和安全性。
SuperFusion整體的網(wǎng)絡(luò)結(jié)構(gòu)是利用雷達(dá)和相機(jī)數(shù)據(jù)在多個(gè)層面的融合。在SuperFusion中體現(xiàn)了三種融合策略: 數(shù)據(jù)層融合:融合雷達(dá)的深度信息以提高圖像深度估計(jì)的精度。 特征層融合:使用交叉注意力進(jìn)行遠(yuǎn)距離的融合,在特征引導(dǎo)下進(jìn)行BEV特征預(yù)測。 BEV級融合:對齊兩個(gè)分支,生成高質(zhì)量的融合BEV特征。 最后,融合后的BEV特征可以支持不同的頭部,包括語義分割、實(shí)例嵌入和方向預(yù)測,進(jìn)行后處理生成高清地圖預(yù)測。
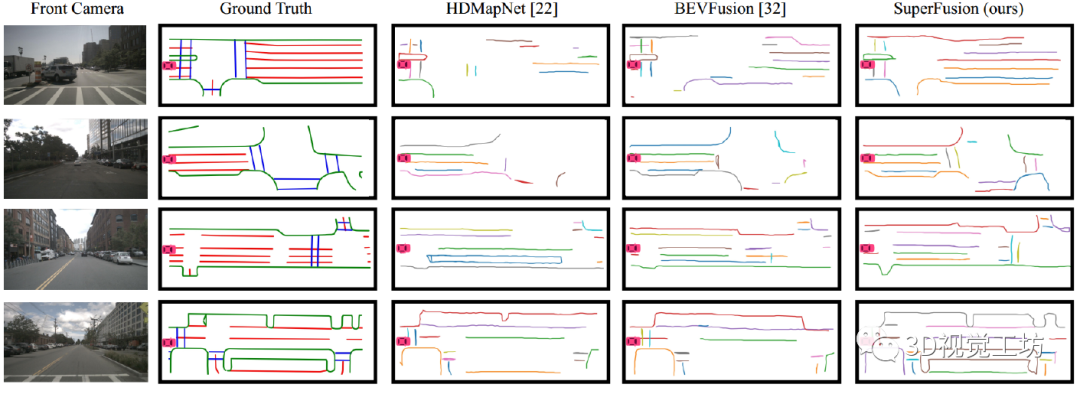
定性和定量結(jié)果也表明,SuperFusion相較于其他HD語義地圖構(gòu)建方案來說,性能提升很明顯,尤其是長距離建模。這種長距離建模能力使得SuperFusion更有利于自動(dòng)駕駛下游任務(wù)。

一句話總結(jié):SuperFusion實(shí)現(xiàn)了長距離HD語義地圖構(gòu)建!
7. 結(jié)論
本文帶領(lǐng)讀者探討了自動(dòng)駕駛?cè)蝿?wù)中的HD語義地圖構(gòu)建的主要問題,并介紹了4種主流的HD語義地圖構(gòu)建方案,分別是清華大學(xué)開源的HDMapNet和VectorMapNet、MIT&上交開源的BEVFusion、蘇黎世聯(lián)邦理工&毫末&國防科大&阿爾托開源的SuperFusion。四種方案主要都是在nuScenes上進(jìn)行評估的,其中HDMapNet和VectorMapNet主要解決的是如何端到端的實(shí)現(xiàn)HD地圖構(gòu)建問題,BEVFusion主要解決的是計(jì)算效率問題,SuperFusion主要解決的是長距離HD地圖構(gòu)建問題。四種方案的底層架構(gòu)其實(shí)都是Transformer,這也說明了Transformer在多模態(tài)和CV領(lǐng)域的影響力越來越大了。其實(shí),現(xiàn)有的HD語義地圖中表達(dá)的語義信息也都是像車道線、人行橫道線的這種低級語義。作者個(gè)人認(rèn)為,在未來,HD語義地圖的發(fā)展趨勢是提取更高級別的語義,比如車輛識別到了一個(gè)正在橫穿馬路的行人,我們想知道的不僅僅是馬路上有個(gè)人,我們更想讓自動(dòng)駕駛車輛理解的是,這個(gè)人的具體意圖是什么。
審核編輯:郭婷
-
激光雷達(dá)
+關(guān)注
關(guān)注
967文章
3940瀏覽量
189602 -
自動(dòng)駕駛
+關(guān)注
關(guān)注
783文章
13687瀏覽量
166153
原文標(biāo)題:高精度語義地圖構(gòu)建的一點(diǎn)思考
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
雙軸測徑儀的四種樣式!
濾波電路的四種類型是什么
負(fù)反饋的四種類型是什么
探秘四大主流芯片架構(gòu):誰將主宰未來科技?

簡述四種基本觸發(fā)器及其功能
介紹MCUboot支持的四種升級模式(2)

電氣設(shè)備的狀態(tài)有哪四種
美團(tuán)取得構(gòu)建高精地圖專利
如何理解IGBT的四種SOA?
A/D轉(zhuǎn)換的四種誤差
電子負(fù)載的四種功能實(shí)現(xiàn)原理
四種霍爾元件的感應(yīng)方式分別是什么呢?
設(shè)備管理通道控制四種方式
四種半導(dǎo)體器件基本結(jié)構(gòu)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論