 深度解析MiddleBurry立體匹配數據集
深度解析MiddleBurry立體匹配數據集
現在,我們知道立體匹配在實際應用中會有各種各樣困難的問題需要解決,例如之前提到過的光照、噪聲、鏡面反射、遮擋、重復紋理、視差不連續等等導致的匹配錯誤或缺失。于是人們就創造了各種各樣的算法來解決這些問題。我們不禁要問一個問題:我們如何公平的比較這些算法的優劣呢?這就是我在這篇文章中想要闡述的內容。讓我們先從評價方法的直覺理解開始,然后進入到科學的部分。
一. 視差結果的評價方法
立體匹配里面提到的最基礎的固定窗口法的匹配結果: 我們可以明顯的看到這個視差圖中有一些錯誤,比如臺燈支架斷裂了,視差圖上部分區域是黑色的,還有背景出現不正常的亮區,同時物體的邊界和原圖的邊界似乎無法對應上(比如臺燈燈罩等)。但如何量化的說明錯誤的量呢?如果能夠將錯誤量化,似乎就可以公平的比較各個算法了。我想你也已經想到,要想量化錯誤,就需要有標準的視差圖作為參考,只需要比較算法的結果和標準視差圖,并計算不一樣的像素的比例,就可以進行評價了。這個領域的先驅們也正是這樣做的,其中奠基性的成果就是MiddleBurry大學的Daniel Scharstein和微軟的Richard Szeliski在2002年發表的下面這篇文章:
我們可以明顯的看到這個視差圖中有一些錯誤,比如臺燈支架斷裂了,視差圖上部分區域是黑色的,還有背景出現不正常的亮區,同時物體的邊界和原圖的邊界似乎無法對應上(比如臺燈燈罩等)。但如何量化的說明錯誤的量呢?如果能夠將錯誤量化,似乎就可以公平的比較各個算法了。我想你也已經想到,要想量化錯誤,就需要有標準的視差圖作為參考,只需要比較算法的結果和標準視差圖,并計算不一樣的像素的比例,就可以進行評價了。這個領域的先驅們也正是這樣做的,其中奠基性的成果就是MiddleBurry大學的Daniel Scharstein和微軟的Richard Szeliski在2002年發表的下面這篇文章: 作者們提出的第一種評價方案是構造具有理想視差圖的參考圖像集,并利用下面兩大指標來評價各種立體匹配算法的優劣:
作者們提出的第一種評價方案是構造具有理想視差圖的參考圖像集,并利用下面兩大指標來評價各種立體匹配算法的優劣:- 均方根誤差(RMS Error),這里N是像素總數
 2.錯誤匹配像素比例
2.錯誤匹配像素比例 除了在整體圖像上計算上述兩個指標,他們還將參考圖像和視差圖進行預先分割,從而得到三個特殊的區域,在這些區域上利用上述指標進行更細節的比較。1. 無紋理區域:這是在原始參考圖像上計算每個像素固定大小鄰域窗口內的水平梯度平均值。如果這個值的平方低于某個閾值,就認為它是無紋理區域。2. 遮擋區域:這個容易理解,在73. 三維重建8-立體匹配4中我介紹了如何獲取到遮擋區域,一般可以利用左右一致性檢測得到。只不過這里記住是利用參考圖像和理想視差值進行計算得到遮擋區域的。3. 深度不連續區域:如果某像素的鄰域內像素的視差值差異大于了某個閾值,那么這個像素就位于深度不連續區域內。下面是示意圖:
除了在整體圖像上計算上述兩個指標,他們還將參考圖像和視差圖進行預先分割,從而得到三個特殊的區域,在這些區域上利用上述指標進行更細節的比較。1. 無紋理區域:這是在原始參考圖像上計算每個像素固定大小鄰域窗口內的水平梯度平均值。如果這個值的平方低于某個閾值,就認為它是無紋理區域。2. 遮擋區域:這個容易理解,在73. 三維重建8-立體匹配4中我介紹了如何獲取到遮擋區域,一般可以利用左右一致性檢測得到。只不過這里記住是利用參考圖像和理想視差值進行計算得到遮擋區域的。3. 深度不連續區域:如果某像素的鄰域內像素的視差值差異大于了某個閾值,那么這個像素就位于深度不連續區域內。下面是示意圖: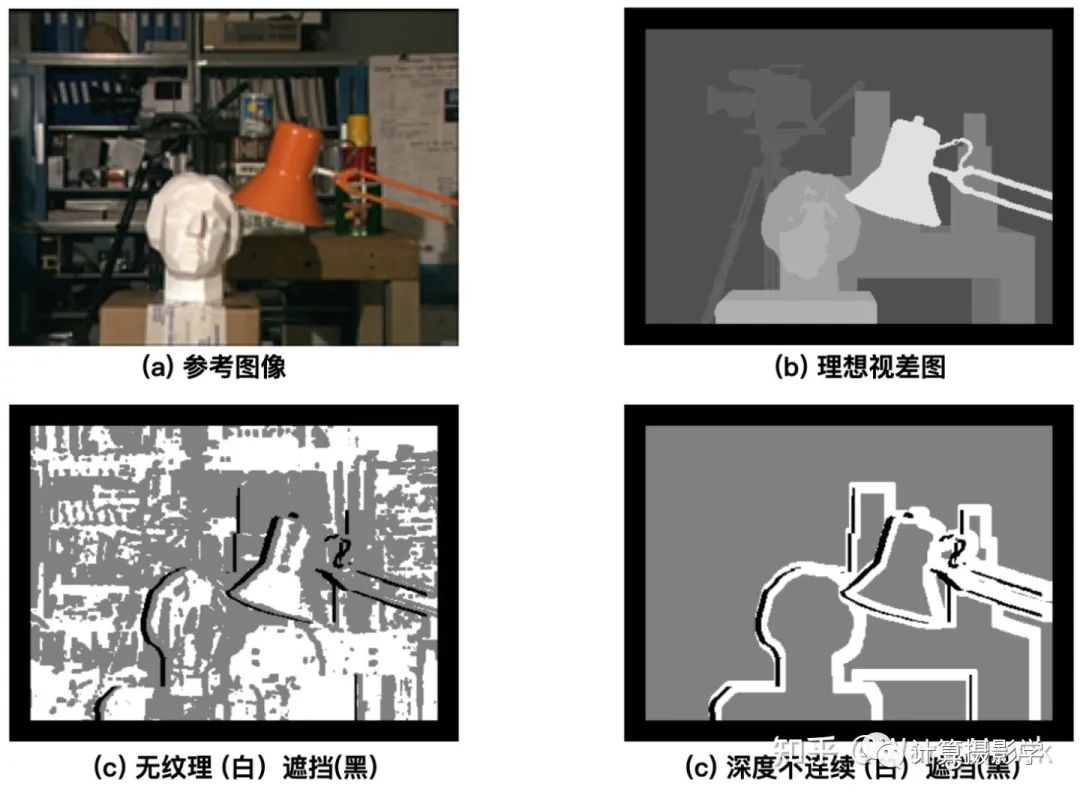 于是作者就會在上面三個區域,以及無紋理區域和遮擋區域的補集,計算均方根誤差及錯誤像素比例這兩個指標。作者還指出了評價算法優劣的第二種方案:如果我們有多個視角的原始圖像,那么可以通過把原始圖像通過視差圖進行變換到其它的視角,并和其他視角已知的圖像做對比,來量化所謂的預測誤差.這也是一種評價算法優劣的方式,理論上算法計算出的視差圖越精準,預測誤差越小。比如下面這組圖,其中中間是原始參考圖像,通過和目標圖像一起做立體匹配,可以得到1個視差圖。通過此視差圖,我們能將參考圖像中的點投影到三維空間,然后再投影到不同的視角下。這里左起第1/2/4/5幅圖,就是投影的結果,其中第4幅對應原目標圖像所在的視角。如果原本在這幾個視角有實拍的圖像,就可以和投影的結果作對比,對比的結果可以用于計算預測誤差。這種方式被作者稱為前向變換,圖中粉色的像素是在投影后沒有信息來填充的像素——這是因為不同視角的遮擋及視差圖中的錯誤導致的。
于是作者就會在上面三個區域,以及無紋理區域和遮擋區域的補集,計算均方根誤差及錯誤像素比例這兩個指標。作者還指出了評價算法優劣的第二種方案:如果我們有多個視角的原始圖像,那么可以通過把原始圖像通過視差圖進行變換到其它的視角,并和其他視角已知的圖像做對比,來量化所謂的預測誤差.這也是一種評價算法優劣的方式,理論上算法計算出的視差圖越精準,預測誤差越小。比如下面這組圖,其中中間是原始參考圖像,通過和目標圖像一起做立體匹配,可以得到1個視差圖。通過此視差圖,我們能將參考圖像中的點投影到三維空間,然后再投影到不同的視角下。這里左起第1/2/4/5幅圖,就是投影的結果,其中第4幅對應原目標圖像所在的視角。如果原本在這幾個視角有實拍的圖像,就可以和投影的結果作對比,對比的結果可以用于計算預測誤差。這種方式被作者稱為前向變換,圖中粉色的像素是在投影后沒有信息來填充的像素——這是因為不同視角的遮擋及視差圖中的錯誤導致的。 另外一種投影方式被作者稱為反向變換。比如下面這組圖,中間是原始參考圖像。而其他的圖像,是在各個視角拍攝的圖像通過三維重投影變換到參考圖像所在視角后的結果。這里面粉色像素代表因為遮擋導致的無法填充的結果。
另外一種投影方式被作者稱為反向變換。比如下面這組圖,中間是原始參考圖像。而其他的圖像,是在各個視角拍攝的圖像通過三維重投影變換到參考圖像所在視角后的結果。這里面粉色像素代表因為遮擋導致的無法填充的結果。 根據作者描述,反向變換帶來的渲染問題更少,更加適合作為計算預測誤差所需。所以后面的指標都采用了反向變換。我們總結下作者給出的各種評價指標吧:1. 在全圖上計算視差圖和理想視差圖之間的均方根誤差,及錯誤像素占比2. 在無紋理區域,有紋理區域,遮擋區域,非遮擋區域,深度不連續區域共5個區域計算和理想視差圖之間的均方根誤差,及錯誤像素占比3. 在不同視角下進行反向變換,計算變換后的投影誤差,即所謂預測誤差于是在論文中就有了一張很復雜的表格,主要就在說明我剛提到的幾種指標。
根據作者描述,反向變換帶來的渲染問題更少,更加適合作為計算預測誤差所需。所以后面的指標都采用了反向變換。我們總結下作者給出的各種評價指標吧:1. 在全圖上計算視差圖和理想視差圖之間的均方根誤差,及錯誤像素占比2. 在無紋理區域,有紋理區域,遮擋區域,非遮擋區域,深度不連續區域共5個區域計算和理想視差圖之間的均方根誤差,及錯誤像素占比3. 在不同視角下進行反向變換,計算變換后的投影誤差,即所謂預測誤差于是在論文中就有了一張很復雜的表格,主要就在說明我剛提到的幾種指標。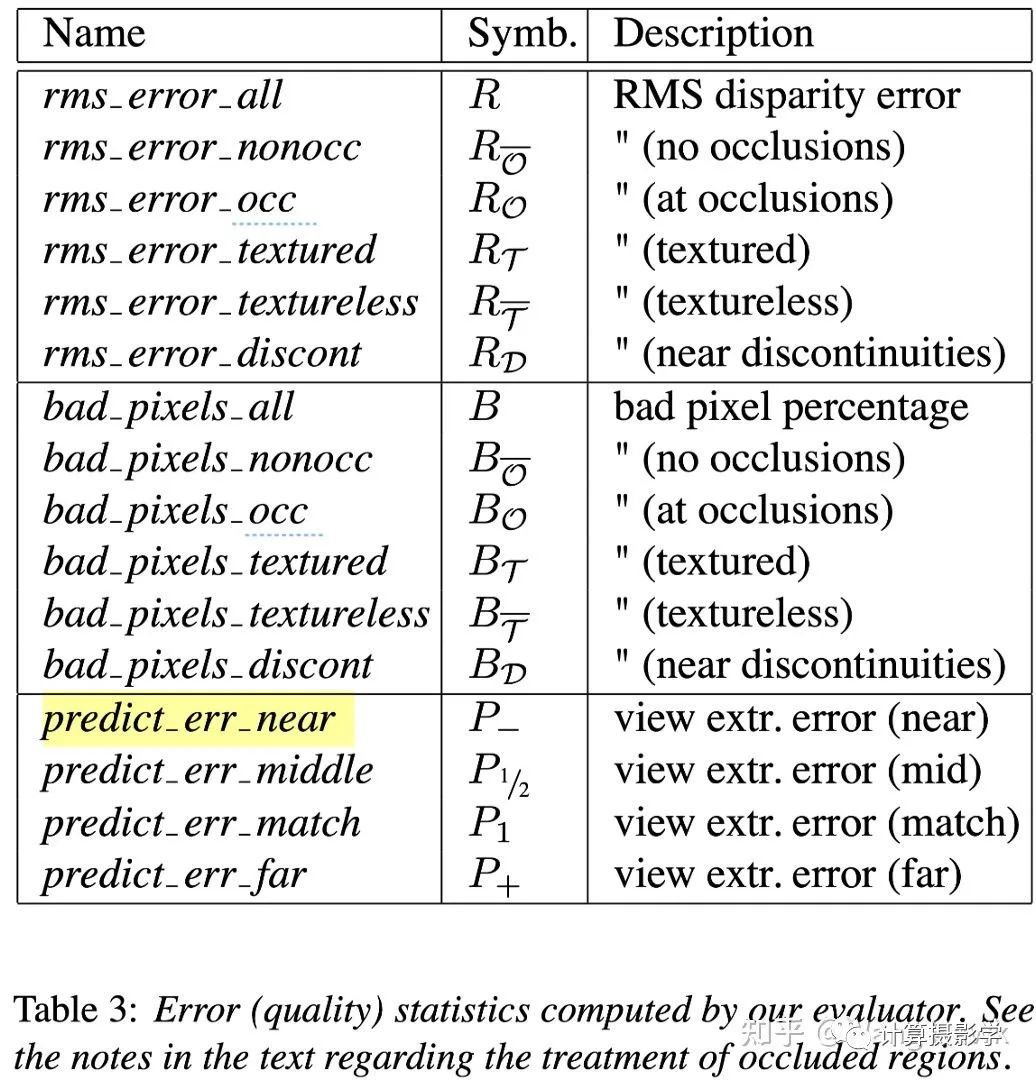 各種視差精度評價指標我們很明顯能看到,為了計算上述的指標,我們的測試數據集中需要包含下面兩類信息中至少一種:1. 輸入的兩視角原始圖像,及對應的理想視差圖2. 輸入的多視角圖像那么,作者是如何構造這樣的測試圖集呢?
各種視差精度評價指標我們很明顯能看到,為了計算上述的指標,我們的測試數據集中需要包含下面兩類信息中至少一種:1. 輸入的兩視角原始圖像,及對應的理想視差圖2. 輸入的多視角圖像那么,作者是如何構造這樣的測試圖集呢?二. 最早期的測試圖集(2001年及以前)
在第1節提到的論文中,作者說明了測試數據集的構成,這些數據集就是MiddleBurry立體匹配數據集網站上的2001版數據集。第一類:平面場景數據集在vision.middlebury.edu/s上,你可以看到作者制作的6組平面場景數據。 每一組數據由9張彩色圖像,和2張理想視差圖構成。作者通過將相機擺放在水平導軌上,然后通過移動相機拍攝了這9幅彩色圖像,并進行了仔細的立體校正。而視差圖則是由第3張和第7張圖像進行立體匹配,并分別作為參考圖像得到的。這些圖像的尺寸比較小,例如Sawtooth的視差圖尺寸是434x380像素。我們來看看其中兩組圖像:Sawtooth及Venus。這里第1列是參考圖像,其中作者擺放的都是平面的海報、繪畫等,而第2列是對參考圖像做手動標記分割為幾個部分的結果,屬于同一個平面的像素被標為同樣的顏色。第3列就是理想視差圖。由于現在場景里面都是平面的物體,因此可以通過特征點匹配的方式計算穩定的匹配點對,再利用平面擬合技術,很準確的計算出每個像素的視差。
每一組數據由9張彩色圖像,和2張理想視差圖構成。作者通過將相機擺放在水平導軌上,然后通過移動相機拍攝了這9幅彩色圖像,并進行了仔細的立體校正。而視差圖則是由第3張和第7張圖像進行立體匹配,并分別作為參考圖像得到的。這些圖像的尺寸比較小,例如Sawtooth的視差圖尺寸是434x380像素。我們來看看其中兩組圖像:Sawtooth及Venus。這里第1列是參考圖像,其中作者擺放的都是平面的海報、繪畫等,而第2列是對參考圖像做手動標記分割為幾個部分的結果,屬于同一個平面的像素被標為同樣的顏色。第3列就是理想視差圖。由于現在場景里面都是平面的物體,因此可以通過特征點匹配的方式計算穩定的匹配點對,再利用平面擬合技術,很準確的計算出每個像素的視差。 第二組圖像是從別的數據集中獲得的。這里有Tsukuba大學的著名數據"Head and Lamp"。這組數據有5x5=25張彩色圖像,在不同視角拍攝。以中間圖像作為參考圖像,人工標注了每個像素的視差,下面展示了其中1張視差圖。
第二組圖像是從別的數據集中獲得的。這里有Tsukuba大學的著名數據"Head and Lamp"。這組數據有5x5=25張彩色圖像,在不同視角拍攝。以中間圖像作為參考圖像,人工標注了每個像素的視差,下面展示了其中1張視差圖。 另外還有早期由作者之一Szeliski和另外一位先驅Zabih制作的單色的Map數據集,長下面這個樣子。這也是1個平面物體構成的場景,所以理想視差圖也用上面提到的平面擬合的方式得到。
另外還有早期由作者之一Szeliski和另外一位先驅Zabih制作的單色的Map數據集,長下面這個樣子。這也是1個平面物體構成的場景,所以理想視差圖也用上面提到的平面擬合的方式得到。 我們看到,早期的這些數據集都比較簡單,而且數量有限。大多數是平面物體構成的場景,像Head and Lamp這樣的數據,雖然由人工標注了視差圖,但最大視差值比較小,難度較低。盡管如此,這對于當時缺乏標準數據集的立體匹配研究來說,已經是一個里程碑式的事件了。在第一節開篇提到的論文中,作者就是利用這樣的數據集和評價指標進行了大量客觀的比較,得出了很多重要的結論。
我們看到,早期的這些數據集都比較簡單,而且數量有限。大多數是平面物體構成的場景,像Head and Lamp這樣的數據,雖然由人工標注了視差圖,但最大視差值比較小,難度較低。盡管如此,這對于當時缺乏標準數據集的立體匹配研究來說,已經是一個里程碑式的事件了。在第一節開篇提到的論文中,作者就是利用這樣的數據集和評價指標進行了大量客觀的比較,得出了很多重要的結論。三. 2003年開始,引入結構光技術
正如上一節提出的,2001版的數據太簡單了,導致后面一些改進后的算法很容易就能匹配上前述數據集中大多數像素,按照現在流行的說法:過擬合了。于是,前面兩位作者采用了新的方法制作更接近真實場景,更加具有挑戰性的數據集。這次的數據集主要包括下面兩個更加復雜的場景:Cones和Teddy, 你可以看到現在不再是平面目標構成的場景了,而是具有更加復雜的表面特征,以及陰影和更多深度不連續的區域。不僅如此,此次提供的圖像的尺寸也很大,完整尺寸是1800x1500,另外還提供了900x750及450x375兩種版本。同時,還包括了遮擋區域、無紋理區域、深度不連續區域的掩碼圖像,用于各種指標的計算。Cones: Teddy:
Teddy: 在2003年CVPR中他們發表了下面這篇文章,闡述了新數據集的制作方法:
在2003年CVPR中他們發表了下面這篇文章,闡述了新數據集的制作方法: 我們從標題就可以看出,這次他們采用了結構光技術自動的計算出每組圖像的高精度稠密視差圖作為理想參考。下面是他們的實驗設置。這里采用的相機是Canon G1,它被安裝在水平導軌上,這樣就可以以固定間隔移動拍攝不同視角的圖像,對于同一個場景作者會拍攝9個不同視角的圖像,并用其中第3和第7張來產生理想視差圖。與此同時,有1個或多個投影儀照亮場景。
我們從標題就可以看出,這次他們采用了結構光技術自動的計算出每組圖像的高精度稠密視差圖作為理想參考。下面是他們的實驗設置。這里采用的相機是Canon G1,它被安裝在水平導軌上,這樣就可以以固定間隔移動拍攝不同視角的圖像,對于同一個場景作者會拍攝9個不同視角的圖像,并用其中第3和第7張來產生理想視差圖。與此同時,有1個或多個投影儀照亮場景。 比如在拍攝Cones場景時,就用了1個投影儀從斜上方照亮場景,這樣大部分區域都可以照亮,除了畫面右上方的格子間有一些陰影,由于陰影前方是平面的柵格,所以這些陰影區域的視差值能夠通過插值算法恢復出來。
比如在拍攝Cones場景時,就用了1個投影儀從斜上方照亮場景,這樣大部分區域都可以照亮,除了畫面右上方的格子間有一些陰影,由于陰影前方是平面的柵格,所以這些陰影區域的視差值能夠通過插值算法恢復出來。 而在拍攝Teddy場景時,則是采用了兩個投影儀從不同的方向打光照亮場景,盡量減少陰影。不過,由于Teddy場景更加復雜,即便是用了兩個方向的照明,依然會有少量的區域位于陰影中(沒有任何1個投影儀能照亮),使得這些區域的視差不可知。
而在拍攝Teddy場景時,則是采用了兩個投影儀從不同的方向打光照亮場景,盡量減少陰影。不過,由于Teddy場景更加復雜,即便是用了兩個方向的照明,依然會有少量的區域位于陰影中(沒有任何1個投影儀能照亮),使得這些區域的視差不可知。 這里面,投影儀會按次序發出N個結構光圖像照亮場景,相機則把這一系列圖像拍攝下來。注意看論文中的示意圖。這里用到的是一種叫做格雷碼的圖案(Gray-Code),是一種黑白條紋圖案。
這里面,投影儀會按次序發出N個結構光圖像照亮場景,相機則把這一系列圖像拍攝下來。注意看論文中的示意圖。這里用到的是一種叫做格雷碼的圖案(Gray-Code),是一種黑白條紋圖案。 為了理解作者是如何獲取高精度視差圖的,我們需要先理解下結構光三維重建的原理。這里我用投影儀發出最簡單的黑白條紋圖像來做一點點介紹,之后我會寫更詳細的文章來介紹結構光三維重建。我們看下面這個場景,投影儀向場景按時間順序投出7個圖像,并被相機拍攝下來。
為了理解作者是如何獲取高精度視差圖的,我們需要先理解下結構光三維重建的原理。這里我用投影儀發出最簡單的黑白條紋圖像來做一點點介紹,之后我會寫更詳細的文章來介紹結構光三維重建。我們看下面這個場景,投影儀向場景按時間順序投出7個圖像,并被相機拍攝下來。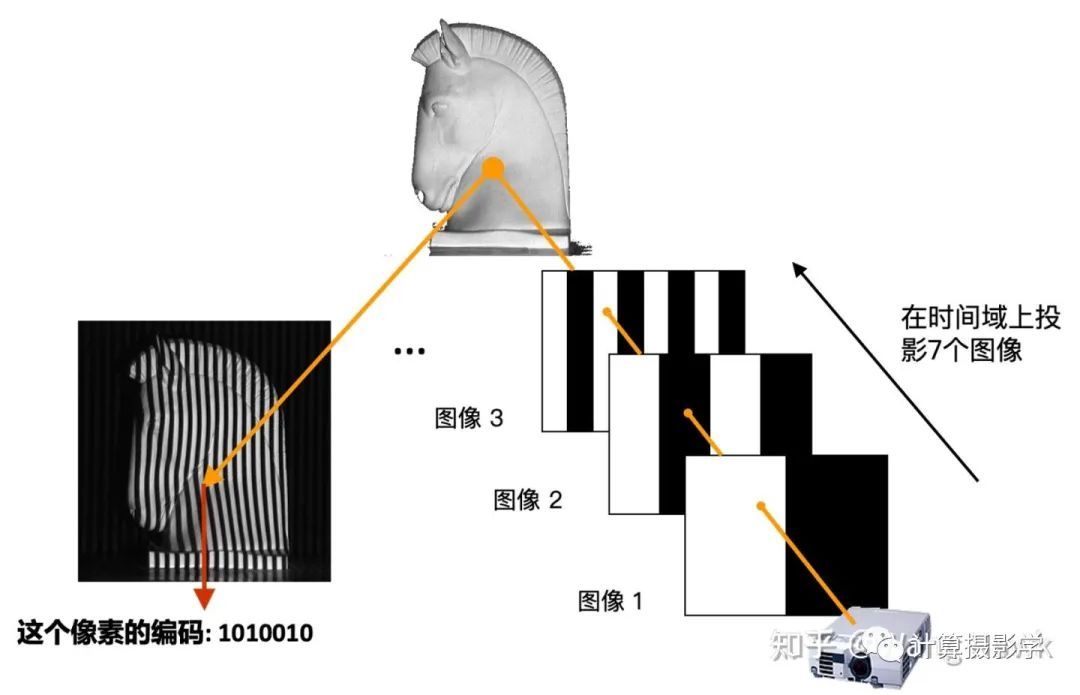 拍下來的系列圖像是這樣的:
拍下來的系列圖像是這樣的: 我們在時空兩個維度上觀察接受到的圖像,就會發現每個場景位置處的信息形成了獨特的編碼。
我們在時空兩個維度上觀察接受到的圖像,就會發現每個場景位置處的信息形成了獨特的編碼。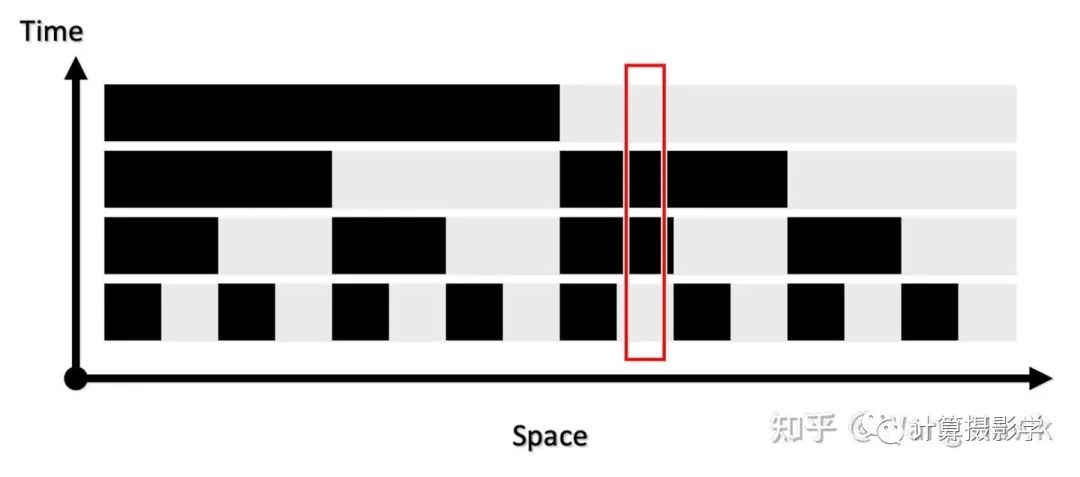 比如上面箭頭所指像素的編碼就是1010010,而且在兩個視角下對應像素的編碼是一致的,這就給了我們精確尋找兩個圖像的對應像素的方法——我們只需要尋找相同編碼的像素即可。這里編碼有7位,意味著我們可以為128列像素指定不同的編碼。如果再發出的是水平條紋,那么可以為128行像素指定不同的編碼。這樣,就可以支撐尺寸為128x128的像素陣列的視差計算了。如果編碼長度變為10位,那么就可以支持精確計算出1024x1024的視差圖。現在我們回到Daniel Scharstein和Richard Szeliski的研究,他們確實是采用了類似原理,通過發出水平和垂直的條紋結構光來精確的尋找兩個視角下圖像間的對應關系的。作者用的投影儀是Sony VPL-CX10,投出的圖案是1024x768像素,所以用10位編碼足夠了,也就是投出10個水平序列圖案和10個垂直序列圖案。下面展示了其發出的水平和垂直結構光經過閾值分割后的黑白條紋的狀態。
比如上面箭頭所指像素的編碼就是1010010,而且在兩個視角下對應像素的編碼是一致的,這就給了我們精確尋找兩個圖像的對應像素的方法——我們只需要尋找相同編碼的像素即可。這里編碼有7位,意味著我們可以為128列像素指定不同的編碼。如果再發出的是水平條紋,那么可以為128行像素指定不同的編碼。這樣,就可以支撐尺寸為128x128的像素陣列的視差計算了。如果編碼長度變為10位,那么就可以支持精確計算出1024x1024的視差圖。現在我們回到Daniel Scharstein和Richard Szeliski的研究,他們確實是采用了類似原理,通過發出水平和垂直的條紋結構光來精確的尋找兩個視角下圖像間的對應關系的。作者用的投影儀是Sony VPL-CX10,投出的圖案是1024x768像素,所以用10位編碼足夠了,也就是投出10個水平序列圖案和10個垂直序列圖案。下面展示了其發出的水平和垂直結構光經過閾值分割后的黑白條紋的狀態。 通過這種方法,就可以得到精確的視差圖了,作者把此時得到的視差圖稱為View Disparity。這個過程可以圖示如下:
通過這種方法,就可以得到精確的視差圖了,作者把此時得到的視差圖稱為View Disparity。這個過程可以圖示如下: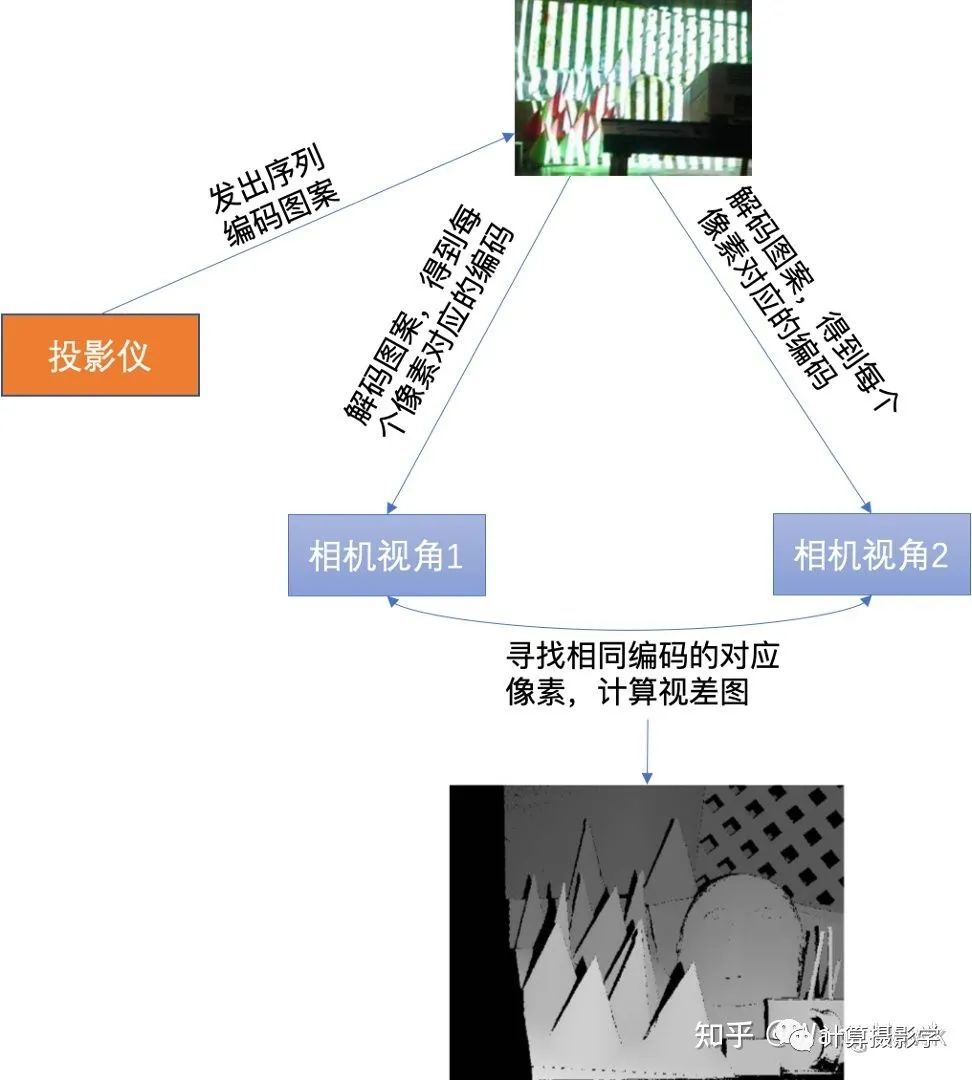 你可以看到,View Dispariy中存在大量的黑色像素,這是怎么回事呢?這里主要由這么幾種情況導致:
你可以看到,View Dispariy中存在大量的黑色像素,這是怎么回事呢?這里主要由這么幾種情況導致:- 遮擋,部分像素只在1個視角可見,在另外1個視角不可見
- 陰影或反射,導致部分像素的編碼不可靠,使得匹配失敗。
- 在匹配時,因為相機分辨率和投影儀分辨率不一致,因此所需的插值或者混疊導致了一些像素無法完美匹配,從而在左右一致性檢查時失敗。
- 同樣,因為投影儀分辨率不足,導致相機成像時多個像素對應同一個投影儀像素。這可能導致一個視角下的1個像素可能和另外一個視角下多個像素匹配上,從而在左右一致性檢查時失敗。
- 還有,就是當采用多個不同的光源方向時,不同光源方向照明時得到的視差圖不一致。這種不一致的像素也會被標記為黑色像素。
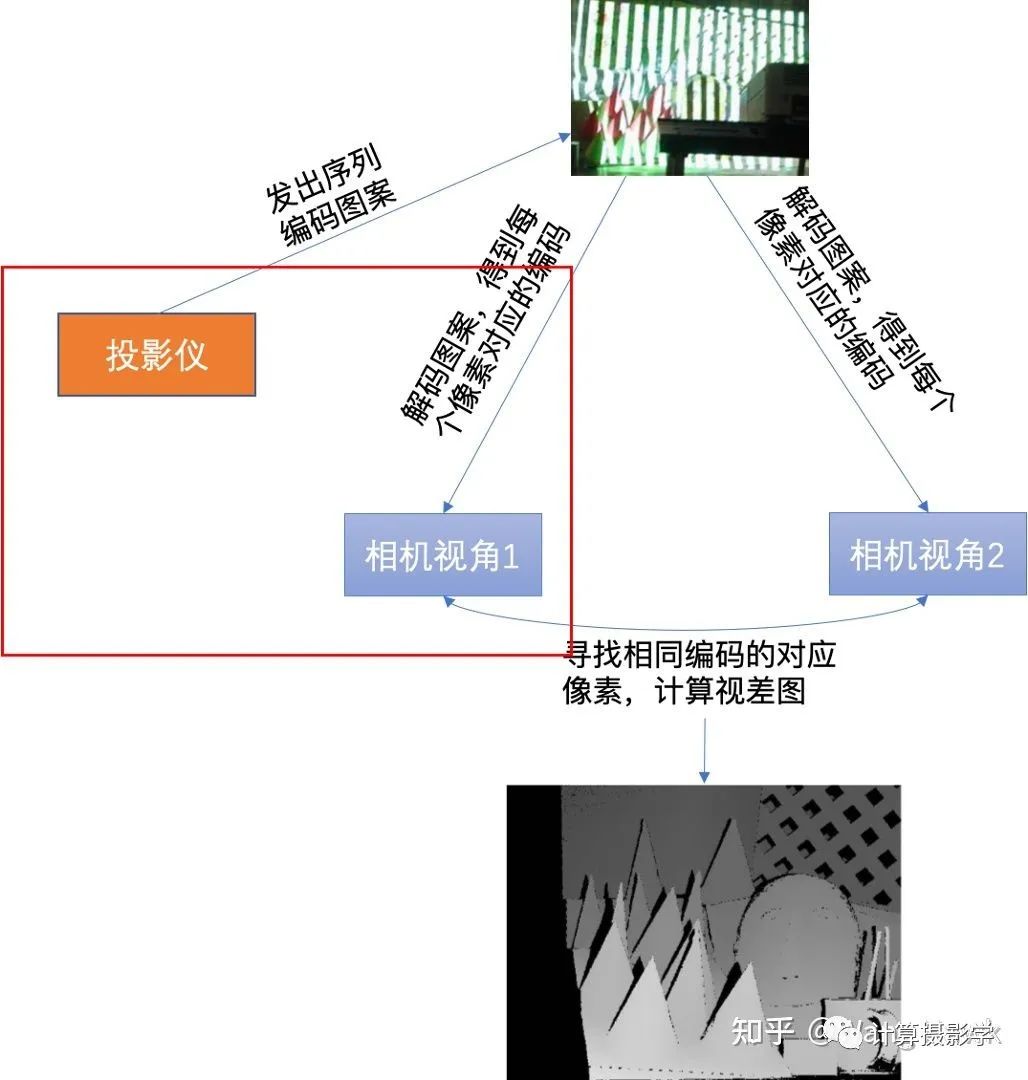 這里,我們注意到當相機視角1下的圖像點和投影儀上的圖案點之間是有明顯的投影關系的。
這里,我們注意到當相機視角1下的圖像點和投影儀上的圖案點之間是有明顯的投影關系的。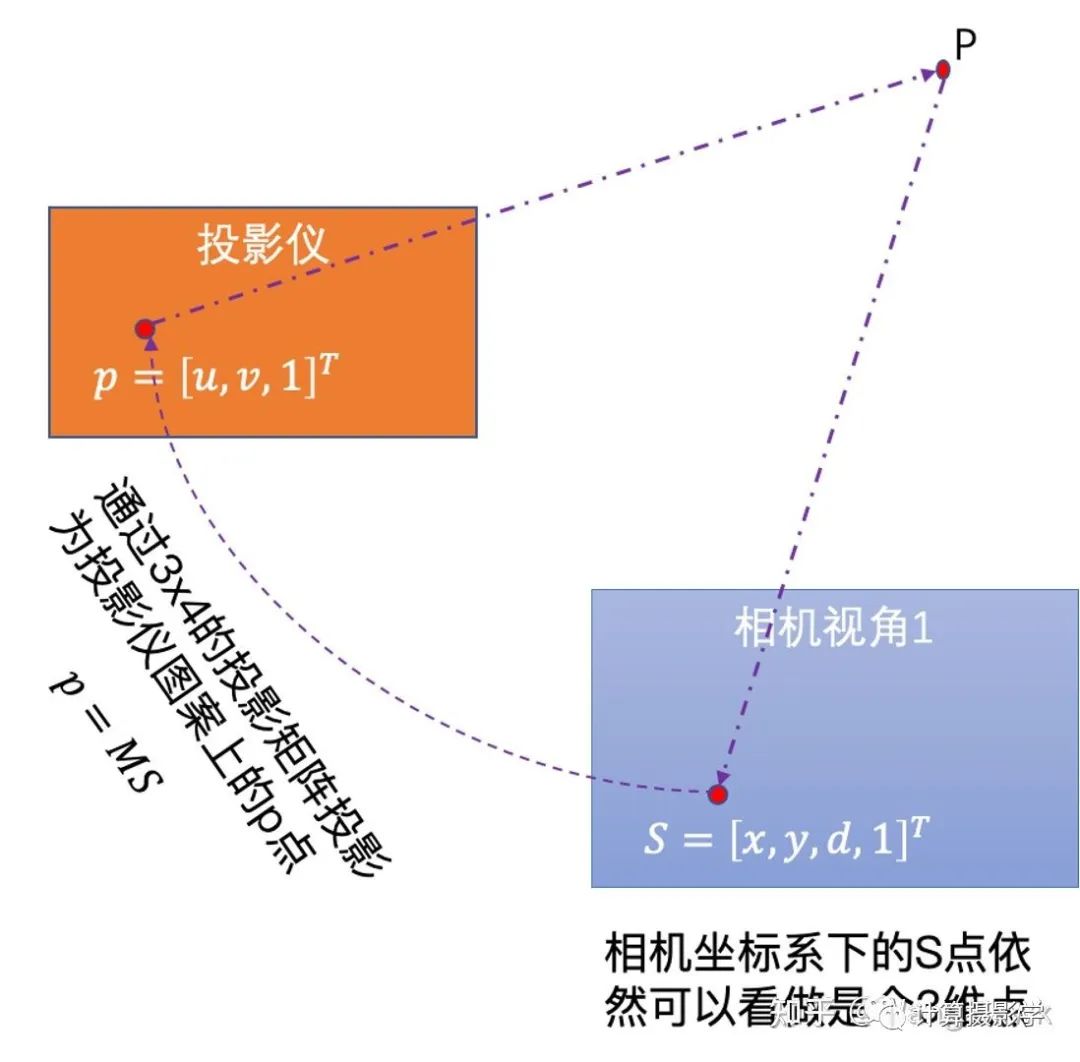 我們有大量的通過前述過程已知視差值d的像素點,因此可以按照上圖建立起超定方程組,并用迭代式的方式求取穩定的投影矩陣M。當M已求得后,就可以將M當成已知量,再次套用p = MS這個式子,求得每個像素的視差值——即使這個像素在此前的view disparity計算過程中因為種種原因被標為了黑色也沒關系,只要投影儀能夠照亮的像素都可以計算出一個視差值,作者把這種方式計算出來的視差值稱為illumination disparities。由于1個投影儀可以和左右相機都計算出這樣的視差圖,所以我們可以得到2張illumination disparity圖。下面是個示例圖,(a)是拍攝的序列圖像中的一張,(b)是參考圖像的所謂View Disparity (c)就是Illumination disparitiy。你可以看到,這里標為黑色的像素明顯少了很多,大部分都是投影儀無法照亮的像素。(d)則是將(b)和(c)合并的結果。
我們有大量的通過前述過程已知視差值d的像素點,因此可以按照上圖建立起超定方程組,并用迭代式的方式求取穩定的投影矩陣M。當M已求得后,就可以將M當成已知量,再次套用p = MS這個式子,求得每個像素的視差值——即使這個像素在此前的view disparity計算過程中因為種種原因被標為了黑色也沒關系,只要投影儀能夠照亮的像素都可以計算出一個視差值,作者把這種方式計算出來的視差值稱為illumination disparities。由于1個投影儀可以和左右相機都計算出這樣的視差圖,所以我們可以得到2張illumination disparity圖。下面是個示例圖,(a)是拍攝的序列圖像中的一張,(b)是參考圖像的所謂View Disparity (c)就是Illumination disparitiy。你可以看到,這里標為黑色的像素明顯少了很多,大部分都是投影儀無法照亮的像素。(d)則是將(b)和(c)合并的結果。 如果有多個投影儀,那么每個投影儀都可以計算一次對應的Illumination Disparity,而且是左右圖都可以計算出自己的Illumination Disparity,最后將所有計算出的視差圖合并起來即可。如果我們有N個投影儀,那么對應于左圖的右圖共有2N個Illumination Disparities,再加上view disparities 2張,一共就需要合并2N+2張視差圖。比如Teddy場景,有兩個投影儀,就會有6張視差圖需要合并,下圖是示例,展示了部分視差圖和最終合并的結果。
如果有多個投影儀,那么每個投影儀都可以計算一次對應的Illumination Disparity,而且是左右圖都可以計算出自己的Illumination Disparity,最后將所有計算出的視差圖合并起來即可。如果我們有N個投影儀,那么對應于左圖的右圖共有2N個Illumination Disparities,再加上view disparities 2張,一共就需要合并2N+2張視差圖。比如Teddy場景,有兩個投影儀,就會有6張視差圖需要合并,下圖是示例,展示了部分視差圖和最終合并的結果。 通過上述過程,就可以得到精度非常高的視差圖了,這就會被作為最終的理想視差圖。Daniel Scharstein和Richard Szeliski采用的這個方案精度非常高,非常適合制作立體匹配的理想參考數據集,于是2005年,MiddleBurry的Anna Blasiak, Jeff Wehrwein和Daniel Scharstein又用此方法構造了更多高精度的數據集,共9組,下面是一些例子,我想很多人都看到過第1組。這次采集數據時,每組數據有7個視角,3種照明,還有3種不同的曝光設置。視差圖基于第2視角和第6視角計算,完整的圖像尺寸大概在1300x1100。
通過上述過程,就可以得到精度非常高的視差圖了,這就會被作為最終的理想視差圖。Daniel Scharstein和Richard Szeliski采用的這個方案精度非常高,非常適合制作立體匹配的理想參考數據集,于是2005年,MiddleBurry的Anna Blasiak, Jeff Wehrwein和Daniel Scharstein又用此方法構造了更多高精度的數據集,共9組,下面是一些例子,我想很多人都看到過第1組。這次采集數據時,每組數據有7個視角,3種照明,還有3種不同的曝光設置。視差圖基于第2視角和第6視角計算,完整的圖像尺寸大概在1300x1100。 這個數據集相比之前的數據集更加有挑戰性,因為圖像中包括了更大的視差,更多的平坦區域。到了2006年,還是MiddleBurry大學,Brad Hiebert-Treuer, Sarri Al Nashashibi 以及 Daniel Scharstein一起又制作了21組雙目數據。跟2005年一樣,依然是7個視角,3種照明,3種曝光設置。這次的完整圖像尺寸大概是1380x1100。這次的數據很多人都看過,比如下面幾張就非常出名。
這個數據集相比之前的數據集更加有挑戰性,因為圖像中包括了更大的視差,更多的平坦區域。到了2006年,還是MiddleBurry大學,Brad Hiebert-Treuer, Sarri Al Nashashibi 以及 Daniel Scharstein一起又制作了21組雙目數據。跟2005年一樣,依然是7個視角,3種照明,3種曝光設置。這次的完整圖像尺寸大概是1380x1100。這次的數據很多人都看過,比如下面幾張就非常出名。 我們可看到,這些數據是越來越有挑戰性,具有豐富的種類,且更多困難的區域,非常適合對各種立體匹配算法進行量化的評價。
我們可看到,這些數據是越來越有挑戰性,具有豐富的種類,且更多困難的區域,非常適合對各種立體匹配算法進行量化的評價。四. 2014年,更加復雜的制作技術
前面講的數據集在立體匹配的研究中起了非常大的作用,很多重要的方法都是在這時候的數據集上進行評價和改進的。然而,它們的數量有限,場景有限,人們認識到需要更多更復雜的場景,來促進立體匹配算法的進一步改進。于是,2011年到2013年間,MiddleBurry大學的Nera Nesic, Porter Westling, Xi Wang, York Kitajima, Greg Krathwohl, 以及Daniel Scharstein等人又制作了33組數據集,2014年大佬Heiko Hirschmüller完成了對這批數據集的優化。他們共同在GCPR2014發表了下面這篇文章,闡述了這批數據集的制作方案: 我截取幾組圖像如下,其中很多都是在立體匹配研究中經常用到的出名的場景,比如我就特別喜歡圖中那個鋼琴
我截取幾組圖像如下,其中很多都是在立體匹配研究中經常用到的出名的場景,比如我就特別喜歡圖中那個鋼琴 那么,這次的數據集制作方法相比以前的有什么貢獻呢?主要有下面這幾點:1. 作者采用的是可移動的雙目系統,包括兩個單反相機,兩個數碼相機,以及相應的導軌和支架構成。這樣就可以在實驗室外拍攝更加豐富的場景。所以最后的數據集里面就包括了各種各樣豐富的、更加真實的場景。而且,這次作者的光照條件更加豐富,有4種,而曝光設置則有8種。為了能夠重現照明情況,還單獨拍攝了環境圖像。下面是論文中的一個示意圖,你可以看到,摩托車表面可能會有高反射區域,為了能夠準確的獲取這些區域的理想視差圖,作者在車身表面噴涂了特殊的材質,我想應該是為了減少反光,使得匹配能成功。
那么,這次的數據集制作方法相比以前的有什么貢獻呢?主要有下面這幾點:1. 作者采用的是可移動的雙目系統,包括兩個單反相機,兩個數碼相機,以及相應的導軌和支架構成。這樣就可以在實驗室外拍攝更加豐富的場景。所以最后的數據集里面就包括了各種各樣豐富的、更加真實的場景。而且,這次作者的光照條件更加豐富,有4種,而曝光設置則有8種。為了能夠重現照明情況,還單獨拍攝了環境圖像。下面是論文中的一個示意圖,你可以看到,摩托車表面可能會有高反射區域,為了能夠準確的獲取這些區域的理想視差圖,作者在車身表面噴涂了特殊的材質,我想應該是為了減少反光,使得匹配能成功。 2. 更加復雜的處理流程,得到高精度的數據集:
2. 更加復雜的處理流程,得到高精度的數據集: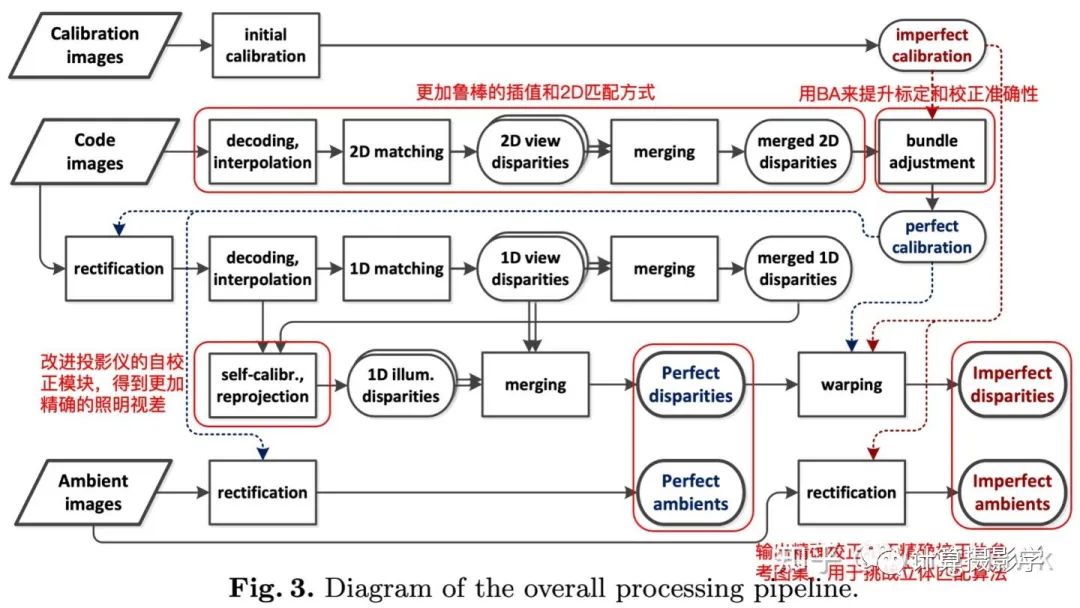 這里我們看到:1. 2003年的方法沒有很好的處理標定和校正帶來的誤差,事實上這樣的誤差會影響到最終生成的理想視差圖的精度。這里的新方案采用了Bundle Adjustment來減小標定和校正的誤差,進一步提升了精度。2. 相比2003年的方法,這里采用了更加魯棒的方式來解碼結構光信息,并用更好的方法來進行2D匹配,這樣就可以更準確的進行立體校正。在采用了這兩個優化點后,立體校正的精度和穩定性都提升了很多:
這里我們看到:1. 2003年的方法沒有很好的處理標定和校正帶來的誤差,事實上這樣的誤差會影響到最終生成的理想視差圖的精度。這里的新方案采用了Bundle Adjustment來減小標定和校正的誤差,進一步提升了精度。2. 相比2003年的方法,這里采用了更加魯棒的方式來解碼結構光信息,并用更好的方法來進行2D匹配,這樣就可以更準確的進行立體校正。在采用了這兩個優化點后,立體校正的精度和穩定性都提升了很多: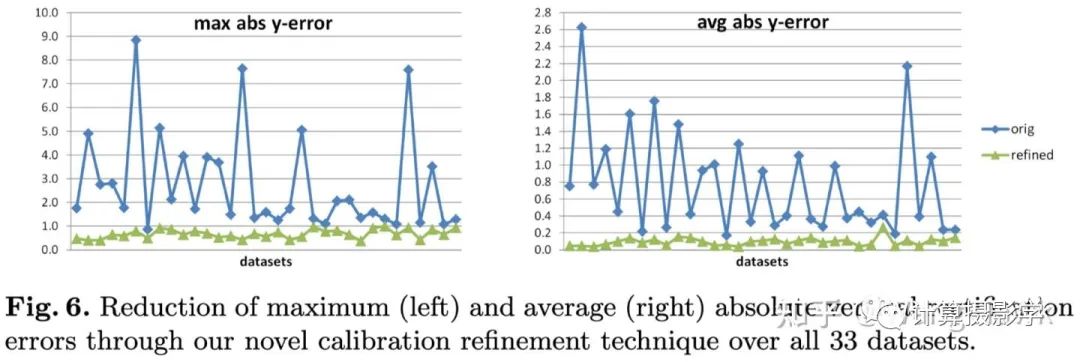 3. 前面我們提到了Illumination Disparity(照明視差)很重要,因此這里引入了更好的自校正模塊,可以得到更好的照明視差4. 另外,為了挑戰立體匹配算法在輸入圖沒有精確rectify的表現,這里還輸出了兩種圖集。一種是經過精確rectify的,保證滿足對極線水平對齊。另外一種則是沒有經過精確rectify的,對算法的挑戰更大。
因為篇幅原因,我就不詳細暫開講解了。總之,這33組數據集中,10組釋放出來供大家做訓練,10組用于測試(理想視差圖未公開),其他的數據用于公開研究。這些數據完整的尺寸甚至達到了3000x2000,最大視差有達到800像素的!不僅僅如此,在MiddleBurry官網上還提供了完善的工具,可以加載、評估、分析這些數據,可以在此處訪問:vision.middlebury.edu/s
3. 前面我們提到了Illumination Disparity(照明視差)很重要,因此這里引入了更好的自校正模塊,可以得到更好的照明視差4. 另外,為了挑戰立體匹配算法在輸入圖沒有精確rectify的表現,這里還輸出了兩種圖集。一種是經過精確rectify的,保證滿足對極線水平對齊。另外一種則是沒有經過精確rectify的,對算法的挑戰更大。
因為篇幅原因,我就不詳細暫開講解了。總之,這33組數據集中,10組釋放出來供大家做訓練,10組用于測試(理想視差圖未公開),其他的數據用于公開研究。這些數據完整的尺寸甚至達到了3000x2000,最大視差有達到800像素的!不僅僅如此,在MiddleBurry官網上還提供了完善的工具,可以加載、評估、分析這些數據,可以在此處訪問:vision.middlebury.edu/s 比如其中有個叫plyv的工具,實現了視角合成功能,便于我們可以從各個視角來觀察場景:
比如其中有個叫plyv的工具,實現了視角合成功能,便于我們可以從各個視角來觀察場景:
五. 2021年,增加用移動設備拍攝的數據集
之前的數據集都是用單反相機作為主要成像設備的,因此圖像的質量非常高。2019年到2021年間,Guanghan Pan, Tiansheng Sun, Toby Weed, 和Daniel Scharstein嘗試了用移動設備來拍攝立體匹配數據集。這里他們采用的是蘋果的iPod Touch 6G,它被安裝到一個機械臂上,在不同視角下拍攝場景。視差圖的生成還是用了上一章介紹的方法,只不過做了適當的裁剪。這批數據一共24組,每個場景會有1到3組數據,下面是例子: 不過我看這里的視差圖依然是用較大差異的兩視角生成的,對于當今手機上的小基距雙攝系統來說,這個數據集的參考價值沒有那么大,畢竟當前手機上的兩個攝像頭之間基距大概就10mm左右,與這里的情況差距較大。
不過我看這里的視差圖依然是用較大差異的兩視角生成的,對于當今手機上的小基距雙攝系統來說,這個數據集的參考價值沒有那么大,畢竟當前手機上的兩個攝像頭之間基距大概就10mm左右,與這里的情況差距較大。六. 總結
這篇文章里,我為你介紹了幾種核心的立體匹配評價指標,以及MiddleBurry大學的幾代立體匹配數據集的制作方式。現在做相關研究的人確實應該感謝包括Daniel Scharstein、Richard Szeliski和Heiko Hirschmüller在內的先驅們,他們創建的MiddleBurry立體匹配數據集及評價系統極大地推動了這個領域的發展。到了今年,一些計算機視覺界的頂會論文依然會描述自己在MiddleBurry 立體匹配數據集上的評價結果。目前排名第1的算法是曠視研究院今年推出的CREStereo,相關成果也發表到了CVPR2022,并會做口頭報告,我之后如有時間也會撰文加以講解。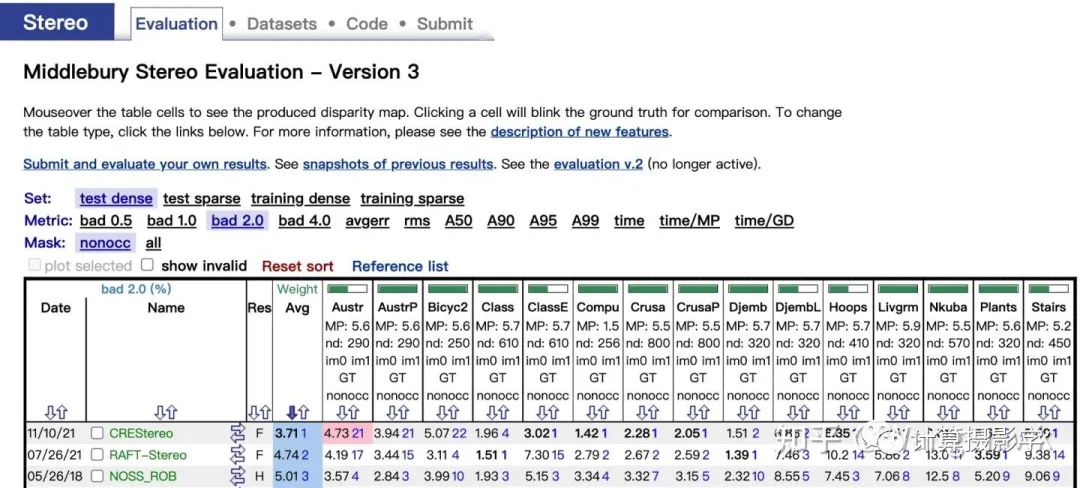 總之,立體匹配算法要繼續發展,需要大量符合真實場景復雜性的高精度數據集,我們學習前人的做法,是為了能夠找出更好的方法,制作更多的數據。我還會在接下來的文章中,給你介紹其他著名的數據集,敬請期待。
總之,立體匹配算法要繼續發展,需要大量符合真實場景復雜性的高精度數據集,我們學習前人的做法,是為了能夠找出更好的方法,制作更多的數據。我還會在接下來的文章中,給你介紹其他著名的數據集,敬請期待。七. 參考資料
1、MiddleBurry雙目數據集2、D. Scharstein and R. Szeliski.A taxonomy and evaluation of dense two-frame stereo correspondence algorithms.International Journal of Computer Vision, 47(1/2/3):7-42, April-June 20023、D. Scharstein and R. Szeliski.High-accuracy stereo depth maps using structured light. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2003),volume 1, pages 195-202, Madison, WI, June 2003.4、D. Scharstein and C. Pal.Learning conditional random fields for stereo. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007),Minneapolis, MN, June 2007.5、H. Hirschmüller and D. Scharstein.Evaluation of cost functions for stereo matching. InIEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007),Minneapolis, MN, June 2007.6、D. Scharstein, H. Hirschmüller, Y. Kitajima, G. Krathwohl, N. Nesic, X. Wang, and P. Westling.High-resolution stereo datasets with subpixel-accurate ground truth. InGerman Conference on Pattern Recognition (GCPR 2014), Münster, Germany,September 2014.7、CMU 2021 Fall Computational Photography Course 15-463, Lecture 18
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
算法
+關注
關注
23文章
4599瀏覽量
92643 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:深度解析MiddleBurry立體匹配數據集
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
立體視覺新手必看:英特爾? 實感? D421深度相機模組
英特爾首款一體化立體深度模組,旨在將先進的深度感應技術帶給更廣泛的受眾 2024年9月24日?—— 英特爾? 實感? 技術再次突破界限,推出全新的英特爾? 實感? 深度相機模組D421

深度神經網絡(DNN)架構解析與優化策略
堆疊多個隱藏層,逐步提取和轉化輸入數據的特征,最終實現復雜的預測和分類任務。本文將對DNN的架構進行詳細解析,并探討其優化策略,以期為相關研究和應用提供參考。
PyTorch如何訓練自己的數據集
PyTorch是一個廣泛使用的深度學習框架,它以其靈活性、易用性和強大的動態圖特性而聞名。在訓練深度學習模型時,數據集是不可或缺的組成部分。然而,很多時候,我們可能需要使用自己的
請問NanoEdge AI數據集該如何構建?
我想用NanoEdge來識別異常的聲音,但我目前沒有辦法生成模型,我感覺可能是數據集的問題,請問我該怎么構建數據集?或者生成模型失敗還會有哪些原因?
發表于 05-28 07:27
深度解析電化學儲能最新官方數據
深度解析電化學儲能最新官方數據 近日,中國電力企業聯合會發布了《2023年度電化學儲能電站行業統計數據》(以下簡稱“統計數據”),
發表于 05-20 11:29
?523次閱讀

機器學習模型偏差與方差詳解
數據集的任何變化都將提供一個不同的估計值,若使用統計方法過度匹配訓練數據集時,這些估計值非常準確。一個一般規則是,當統計方法試圖更緊密地
發表于 03-26 11:18
?900次閱讀

arcgis空間參考與數據框不匹配如何解決
當使用ArcGIS軟件進行空間數據處理時,經常會遇到空間參考與數據框不匹配的問題。這種不匹配可能導致數據顯示不正確,分析結果不準確,甚至引發
大模型數據集:力量的源泉,進步的階梯
一、引言 在? ? 的繁榮發展中,大模型數據集的作用日益凸顯。它們如龐大的知識庫,為AI提供了豐富的信息和理解能力。本文將用一種獨特的風格來探討大模型數據集的魅力和潛力。 二、大模型
大模型數據集:構建、挑戰與未來趨勢
隨著深度學習技術的快速發展,大型預訓練模型如GPT-4、BERT等在各個領域取得了顯著的成功。這些大模型背后的關鍵之一是龐大的數據集,為模型提供了豐富的知識和信息。本文將探討大模型數據
機器視覺檢測發展的幾個歷程和趨勢
主要針對光學成像的逆問題,是由能從二維光強度陣列恢復三維可見表面物理性質的一系列處理過程組成。這里各過程的輸入數據及計算目的都是能夠明確描述的,如邊緣檢測、立體匹配、由運動恢復結構等方法。
速銳得如何破解大眾朗逸電動汽車智能網聯應用中儀表CAN總線數據呢
隨著汽車電子進入電動化+智能網聯的時代,新能源、車聯網、智能化、電動化四個領域帶來了CAN數據的需求,企業車隊管理需要數據,汽車運營需要數據,改裝、解碼、匹配工具打造需要
速銳得破解大眾朗逸電動汽車智能網聯應用中儀表CAN總線數據
隨著汽車電子進入電動化+智能網聯的時代,新能源、車聯網、智能化、電動化四個領域帶來了CAN數據的需求,企業車隊管理需要數據,汽車運營需要數據,改裝、解碼、匹配工具打造需要
天線與饋線匹配中的平衡與不平衡以及造成的影響解析
天線與饋線匹配中的平衡與不平衡以及造成的影響解析? 天線與饋線的匹配是無線電通信中非常重要的一環。平衡與不平衡是兩種不同的天線與饋線匹配方式,它們對通信系統的性能有著不同的影響。 所謂
基于RGM的魯棒且通用的特征匹配
在一對圖像中尋找匹配的像素是具有各種應用的基本計算機視覺任務。由于光流估計和局部特征匹配等不同任務的特定要求,以前的工作主要分為稠密匹配和稀疏特征匹配,側重于特定的體系結構和特定任務的





 工商網監
工商網監
評論