 基于端到端的單噪聲圖像降噪和校正網絡實現高質量的車牌識別
基于端到端的單噪聲圖像降噪和校正網絡實現高質量的車牌識別
在本文中,我們提出了一種用于從真實世界中的低質量圖像中進行車牌識別的算法。我們的算法建立在降噪和校正的框架上,并且每個任務都是由卷積神經網絡來執行。在先前的研究中,降噪和校正任務分別被一個神經網絡來處理。不同以往,我們提出了一種可訓練的端到端的圖像恢復網絡,即“單噪聲圖像降噪和校正”網絡(SNIDER),致力于一起解決這兩個問題。此外,我們提出了一種利用輔助任務優化多任務訓練損失的方法。在兩個具有挑戰性的LPR數據集AOLP-RP和VTLPs進行了大量的實驗,證明了我們提出的方法的有效性,并且在從低質量的車牌圖像中恢復高質量的車牌圖像時本方法優于其他的SOAT方法。
一、研究背景
真實世界中的車牌識別(LPR)是多種智能運輸系統(ITS)應用程序,如車輛重識別,戶外場景理解,用于隱式保護的去識別等的基本問題之一。過去幾年,LPR已經在理論,實驗和數理方面得到了廣泛的研究,以提供魯棒的圖像特征表示。一些LPR方法可以捕獲圖像和噪聲的結構屬性,以進行嚴格的約束。雖然已經取得了一些成果,但由于外觀,噪聲,角度和光照的變化,在野外進行車牌識別仍不能取得令人滿意的效果。近年來,由于卷積神經網絡的發展,許多計算機視覺任務取得了很大進步例如目標檢測,語義分割,人臉識別等。同時CNN引導的LPR方法也被廣泛用于解決識別現實世界中捕獲的車牌。然而,現有的LPR方法仍然無法學習到野外所有類型的樣本,這些算法實際上是將高質量的圖像作為輸入。通常,在現實世界中收集的車牌可能包含質量很低的圖像,從而導致LPR性能下降。因此,在真實世界場景中開發魯棒的LPR框架是必要的。
在本文中,我們基于多個輔助任務設計了一個端到端的單噪聲圖像降噪和校正網絡(SNIDER)以實現更好的LPR。Figure1展示了我們的框架,其中SNIDER和預訓練的LPR網絡(這里是基于Darknet的YOLOV3網絡)相結合。SNIDER包括兩個子網絡:降噪網絡和校正網絡。基于U-Net在恢復圖像細節方面的成功,我們采用U-Net結構作為圖像恢復骨干網洛,嘗試從結構級別的細節中提取視覺內容。在去噪子網絡(DSN)中,我們嘗試將低質量的圖像直接逐像素地轉換為高質量的圖像。DSN可以懲罰噪聲和無噪聲圖像對之間的損失,從而獲得無噪和有精細紋理的輸出圖像。但僅僅使用DSN,去噪圖像仍不能令人滿意,因為圖像仍然具有隨機的幾何變化。因此,校正網絡(RSN)被提出用于校正去噪后車牌圖像的幾何畸變。此外,我們提出利用新的輔助任務進一步優化SNIDER的DSN和RSN網絡。一共有兩個輔助任務:一個文本計數模塊和一個分割預測模塊。具體來說,我們使用CNN作為編碼器來解決每個輔助模塊。計數模塊用來預測圖像中的文本數量,被當作分類問題。在此模塊中,盡管連續文本的邊界模糊,文本計數模塊仍可區分單個文本,從而使圖像質量更適合于文本檢測。在分割預測模塊中,我們提出了一種二值分割方法來強調前景而不是背景,生成的分割結果使得車牌更加干凈以進行文本識別。最后,學習輔助任務將引導圖像恢復網絡的中間特征,從而增加幾何變化和低質量信息等困難。更重要的是,我們引入了新的損失函數,用于訓練SNIDER和輔助任務,為LPR提供了更高質量的車牌數據。
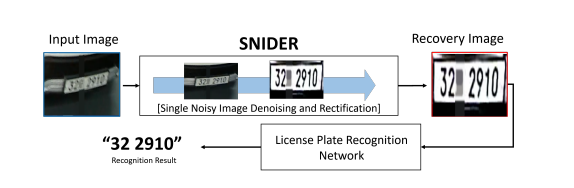
Figure 1
二、相關工作
在本節中,我們簡要回顧與這項工作最相關的低質量圖像恢復方法和車牌識別方法。
2.1低質量圖像恢復
為了獲得高質量的圖像,大多數現有的方法都依賴于這樣的假設:信號和噪聲都是通過手工算法從特定的統計規律中產生。此外,一些非參數模型被開發來模擬圖像噪聲,但由于有限的觀測結果,它們對野外不受約束的環境并不具有魯棒性。近來,由于深度學習的發展,大多數降噪算法都是采用深度神經網絡體系結構和數據驅動的方法設計的,而非依靠先驗技術。盡管文本分類器對于清晰圖像很有用,但由于文本幾何形狀不規則,因此仍難以識別。與現有方法不同,我們使用基于U-Net的CNN對圖像進行去噪和校正。據我們所知,我們的研究可能是首個將上訴兩個模塊同時應用于LPR。
2.2 車牌識別
在深度學習出現之前,大多數傳統的LPR方法都采用雙階段的處理流程,包括文本檢測和文本識別。隨著深度學習的發展,許多方法采用了單階段流程即不進行文本檢測。Li等通過將RNN與LSTM結合來提取深層特征表示,以獲取車牌的連續特征。Bulan等基于完全卷積網絡估計目標域和多個原域之間的域轉換,以產生具有最佳識別性能的域。但這些方法僅考慮高質量的車牌圖像,這容易導致模型在現實場景中性能下降。而且這些方法很少努力去改善圖像樣本質量,同時也占用了大量計算力。在我們的工作中,我們在真實場景中采用低質量圖像恢復以提升LPR的性能。這是我們首次應用復雜的圖像恢復技術來處理有挑戰的真實環境,雖然有額外恢復模塊,但我們的方法仍具有較高的計算效率和實時識別能力。
三、方法
我們提出的方法由三部分組成:1)主任務預測網絡包括去噪網絡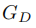 和校正網絡
和校正網絡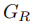 。2)輔助任務預測網絡包括文本計數分類網絡
。2)輔助任務預測網絡包括文本計數分類網絡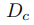 和分割網絡
和分割網絡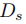 。3)用于文本檢測和分類的網絡LPR。整個框架可以用Figure2來表示。
。3)用于文本檢測和分類的網絡LPR。整個框架可以用Figure2來表示。
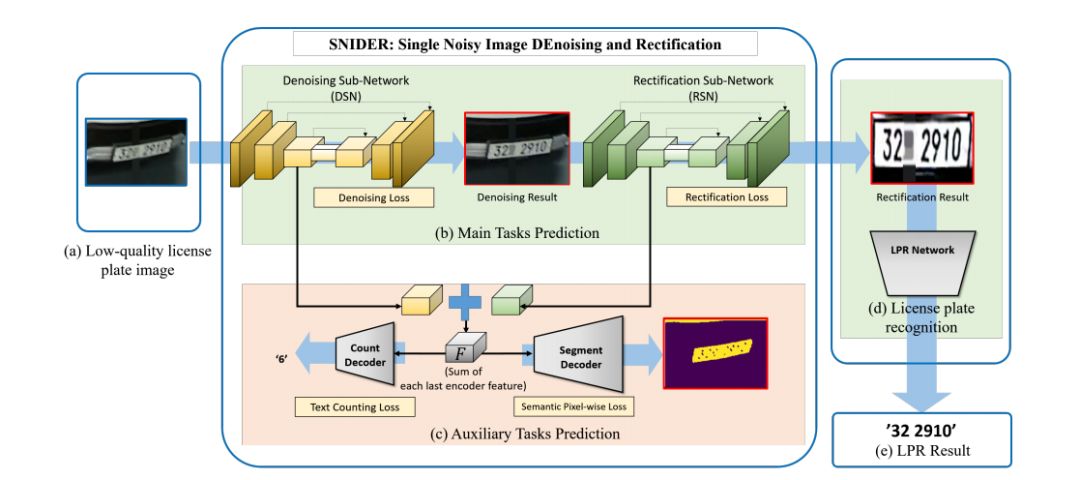
Figure 2
在訓練中,用于主任務和輔助任務的數據集可以通過簡單旋轉(用于校正)和縮小尺寸(用于降噪)獲得,如圖Figure3所示。
Figure 3具體來說,一張原始圖像 通過旋轉不同的角度可以產生四張訓練圖像,其中
通過旋轉不同的角度可以產生四張訓練圖像,其中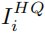 用于,
用于,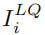 用于,
用于,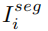 用于,c用于,
用于,c用于,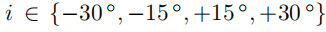 ,主任務的和網絡從輸入圖像
,主任務的和網絡從輸入圖像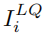 恢復為高質量圖像。然后,LPR網絡獲取
恢復為高質量圖像。然后,LPR網絡獲取
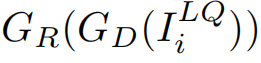
進行文本檢測和識別。
3.1去噪和校正網絡
我們的主任務網絡包括兩個子網絡(即去噪子網絡和校正子網絡),第一個子網絡以低質量圖像為輸入,輸出為恢復圖像。在本文中,我們設計了校正網絡對來自降噪網絡的輸出結果進行校正。圖像恢復結果[15]顯示了U-Net的有效性,因為它可以提升圖像中目標的細節信息,而不會對圖像生成產生負面影響。因此,我們采用基于U-Net的結構,同時添加了跳躍連接,可以共享圖像低級語義信息。
為了實現主任務,我們首先將輸入到網絡產生去噪后的結果。給定一對輸入圖像和未校正的去噪標簽圖像
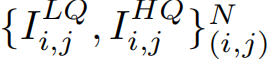
,的損失函數是逐像素的MSE損失,如等式(1)所示:
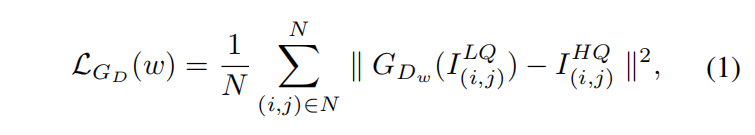
其中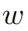 是去噪網絡的參數。這種損失函數讓網絡不僅能提取輸入圖像語義信息也能生成像素級的高質量圖像。然后校正網絡從的輸出開始處理,產生校正后的高質量圖像,以更有利于LPR網絡進行文本識別。訓練圖像對用
是去噪網絡的參數。這種損失函數讓網絡不僅能提取輸入圖像語義信息也能生成像素級的高質量圖像。然后校正網絡從的輸出開始處理,產生校正后的高質量圖像,以更有利于LPR網絡進行文本識別。訓練圖像對用
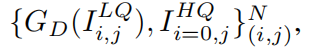
表示,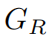 網絡使用L1損失函數,如等式(2)所示:
網絡使用L1損失函數,如等式(2)所示:
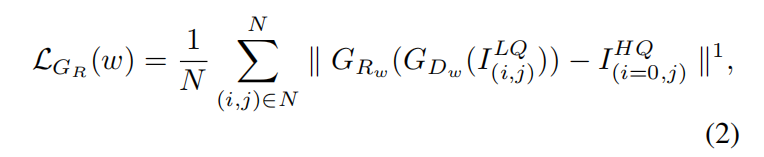
其中w是校正網絡的參數。
和L2損失不同,像素級別的L1損失有助于保留目標的外觀,例如圖像顏色,亮度等。因此,在校正過程中,我們只會進行幾何變換而不會對圖像造成外觀損傷,這對識別器是有用的。
3.2輔助任務預測
由于真實環境的復雜性,如文本的幾何形態及其不規則,圖像背景很復雜等導致車牌的二值化信息往往存在噪聲。盡管我們希望和可以捕獲魯棒的特征來進行圖像恢復,但是這種結構的結果并不能總是保證有良好的圖像質量提升輸出。因此,我們使用了兩個輔助任務,即二值分割和計數估計,這將有助于我們的主任務網絡產生更具區分性的代表特征。針對這個問題,我們將編碼器最后一層的權值相加,以指導輔助任務網絡更有效地從低質量圖像中提取關鍵信息。
對于二值分割任務,我們介紹基于U-Net結構的分割解碼器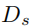 。的細節如Table1所示:
。的細節如Table1所示:

接收主任務編碼器求和后的特征集F并輸出車牌分割結果,每個像素位置的值代表該像素值屬于車牌區域的概率。此外,用于分割的標簽樣本可以使用論文[4]中的OTSU算法得到,如Figure3所示。雖然[4]中的分割注釋不能完全反映圖像的實際細節,但我們的實驗表明,這種輔助學習的策略在圖像恢復方面取得了有效的進展。給定F和語義分割標簽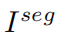 ,的損失函數為二元交叉熵損失,如公式(3)所示:
,的損失函數為二元交叉熵損失,如公式(3)所示:
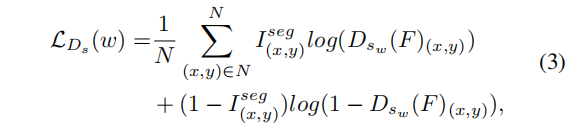
其中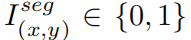 代表是否屬于車牌區域。
代表是否屬于車牌區域。
同時,我們發現恢復的樣本通常不能區分連續的文本。所以我們增加了一個計數解碼器來預測圖像中字符的個數。因此,我們的扮演兩個角色,第一個是使得相鄰字符之間的分割更加清晰,另外一個角色是促進每個主任務的編碼器產生更高質量的圖像。的損失函數為L2損失,如公式(4)所示:
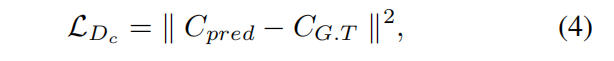
其中,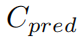 是預測值,
是預測值,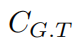 是標簽。
是標簽。
最終網絡訓練的損失函數如公式(5)所示:
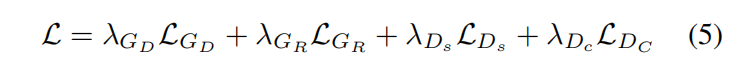
優化此損失函數更新網絡的參數即可。
四、結果
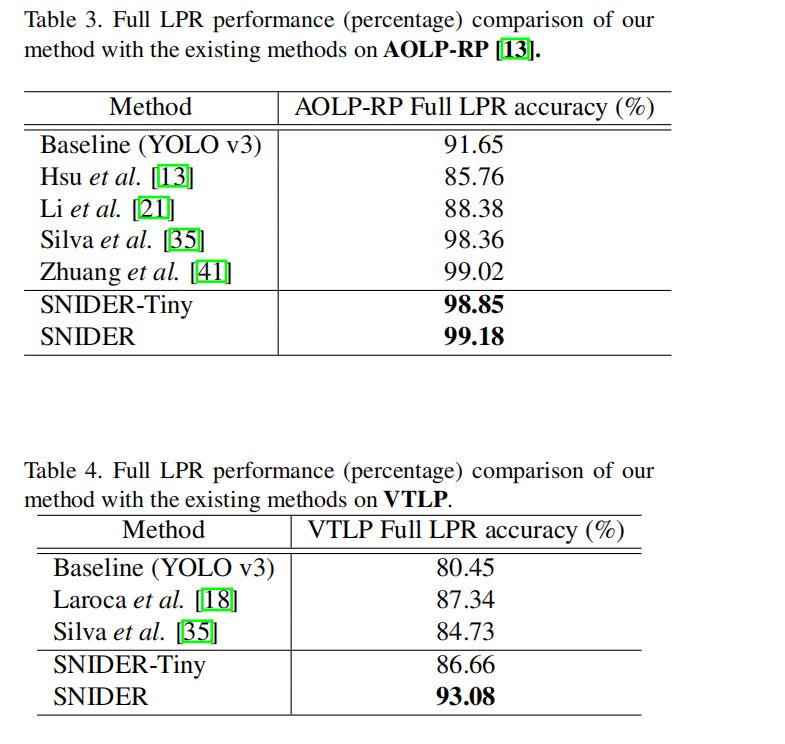
我們在兩個大型的車牌數據集AOLP-RP和VTLPs上測試了我們的算法,我們在AOLP數據集上達到了驚人的99.18%的準確率,相比于直接使用YOLOV3做檢測提升了近10個點,證明了我們算法的魯棒性和有效性。在兩個數據集上的測試結果如表Table3和Table4所示:
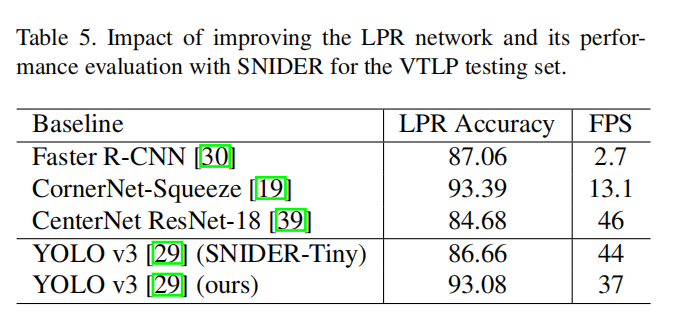
我們的算法在精度SOAT的同時,速度也可以達到實時,具有較好的實用價值。測試結果如圖Table5所示:
五、結論
本文提出了一種新的端到端的可訓練的圖像恢復方法用于真實世界中的車牌識別。我們提出的恢復網絡由兩個子網絡組成,即去噪子網絡和校正子網絡。特別地,我們設計了使用兩個輔助任務來協助車牌圖像恢復網絡,從而使得恢復網絡提取的特征更加魯棒,以對抗現實場景中的幾何變化和模糊數據。此外,一個新的損失函數被引入到骨干網絡中,以提供正則化影響和提高恢復圖像質量。在各種數據集上進行的廣泛實驗證明了在車牌恢復和識別方面的卓越性能。審核編輯:郭婷
-
車牌識別
+關注
關注
5文章
82瀏覽量
15636 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998
原文標題:用于提高車牌識別的單幅噪聲圖像去噪和校正
文章出處:【微信號:www_51qudong_com,微信公眾號:機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
移動端安卓車牌識別
源碼交流=圖像處理 實現夜間車牌識別、提取車牌圖像[已測試]
XMOS推出用于高質量音頻再現的端對端數字iPhone 底座

移動端車牌識別技術,實現手機攝像頭掃描識別車牌
一種新型的移動端車牌識別技術,可支持Android、iOS平臺

基于生成式對抗網絡的端到端圖像去霧模型






 工商網監
工商網監
評論