") 基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線
基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線
科學(xué)與技術(shù)
實(shí)時(shí) AI 視頻分析是一種基于人工智能的技術(shù),可分析視頻流以檢測(cè)特定行為和事件。這種類型的系統(tǒng)通過人工智能機(jī)器學(xué)習(xí)引擎檢查來自監(jiān)控?cái)z像頭的視頻流來進(jìn)行相關(guān)工作。該引擎使用一系列深度學(xué)習(xí)算法和程序來理解數(shù)據(jù),并將數(shù)據(jù)轉(zhuǎn)換為可理解的、有意義的信息。
以車輛檢測(cè)這是任務(wù)為例,我們可以把 AI 視頻分析分為以下幾個(gè)通用步驟:
1.視頻流拉流
2.媒體解碼
3.圖像前處理縮放
4.深度學(xué)習(xí)推理,識(shí)別車輛
5.后處理畫框
6.媒體編碼傳輸
7.分析結(jié)果可視化呈現(xiàn)
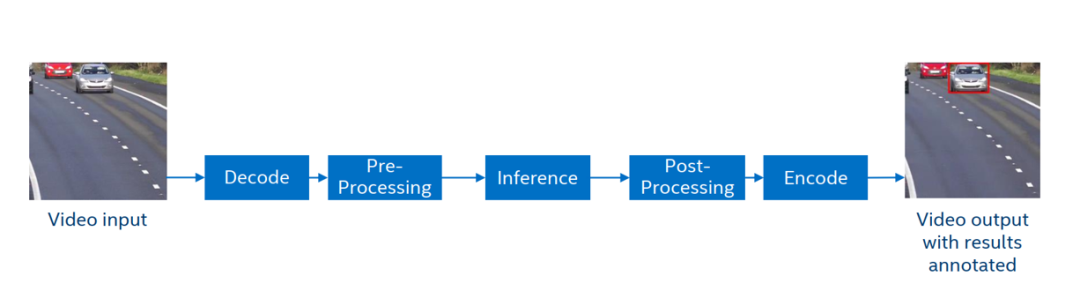
圖:通用 AI 視頻分析流程
隨著邊緣計(jì)算技術(shù)的日漸成熟,我們逐步將 AI 算力與分析服務(wù)下沉到邊緣設(shè)備側(cè),以獲取更好的實(shí)時(shí)性,并減少視頻流傳輸對(duì)于帶寬資源的占用。此時(shí),AI Box 邊緣計(jì)算設(shè)備將作為媒體數(shù)據(jù)分析的核心節(jié)點(diǎn),直接接入并讀取 IP 攝像頭編碼后的視頻流數(shù)據(jù),進(jìn)行實(shí)時(shí)的解碼和推理工作,并將結(jié)果數(shù)據(jù)推送至后端機(jī)房。后續(xù)配合視頻監(jiān)控服務(wù)機(jī)完成對(duì)推理結(jié)果的后處理分析與告警,以及將編碼后的事件關(guān)鍵幀留存,以供人工追溯。
鑒于邊緣測(cè)的算力資源有限,大家不難發(fā)現(xiàn)這個(gè)流程中性能的瓶頸往往會(huì)發(fā)生在 AI Box 的視頻解碼或者是推理任務(wù)中。同時(shí)出于方案成本的考慮,我們也希望可以用相同的硬件資源,接入更多路的視頻流分析業(yè)務(wù),因此如何進(jìn)一步優(yōu)化這部分的工作流程,便成為了本示例希望分享的核心重點(diǎn)。
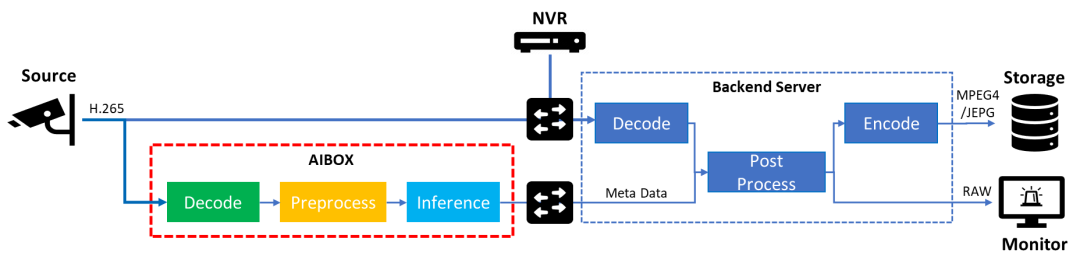
圖:邊緣 AI 視頻分析架構(gòu)
1.OpenVINO工具套件簡(jiǎn)介
用于高性能深度學(xué)習(xí)的英特爾發(fā)行版 OpenVINO工具套件基于 oneAPI 而開發(fā),以期在從邊緣到云的各種英特爾平臺(tái)上,幫助用戶更快地將更準(zhǔn)確的真實(shí)世界結(jié)果部署到生產(chǎn)系統(tǒng)中。通過簡(jiǎn)化的開發(fā)工作流程,OpenVINO工具套件可賦能開發(fā)者在現(xiàn)實(shí)世界中部署高性能應(yīng)用程序和算法。
在推理后端,得益于 OpenVINO 工具套件提供的“一次編寫,隨處部署”特性,轉(zhuǎn)換后的模型能夠在不同的英特爾硬件平臺(tái)上運(yùn)行,無需重新構(gòu)建,有效簡(jiǎn)化了構(gòu)建與遷移過程。此外,為了支持更多的異構(gòu)加速單元,OpenVINO 工具套件的 runtime api 底層采用了插件式的開發(fā)架構(gòu),基于 oneAPI 中的 MKL-DNN、oneDNN 等函數(shù)計(jì)算加速庫(kù),針對(duì)通用指令集進(jìn)行優(yōu)化,為不同的硬件執(zhí)行單元分別實(shí)現(xiàn)了一套完整的高性能算子庫(kù),提升模型在推理運(yùn)行時(shí)的整體性能表現(xiàn)。
這里值得提一句的是,目前 OpenVINO 2022.2版本可以直接支持英特爾最新的獨(dú)立顯卡產(chǎn)品(dGPU)執(zhí)行推理任務(wù)。
可以參考文章:
官宣:支持英特爾獨(dú)立顯卡的OpenVINO 2022.2新版本來啦
2. 英特爾 oneAPI 簡(jiǎn)介
英特爾 oneAPI 是一項(xiàng)行業(yè)倡議,旨在創(chuàng)建一個(gè)開放、基于標(biāo)準(zhǔn)的跨架構(gòu)編程模型,在面對(duì)大量跨各種架構(gòu)(CPU、GPU、FPGA 和其他加速器)的工作負(fù)載時(shí)簡(jiǎn)化開發(fā)工作。它包括跨架構(gòu)語言 Data Parallel C ++(基于 ISO C ++ 和 Khronos Group 的 SYCL)、高級(jí)庫(kù)和社區(qū)擴(kuò)展。許多公司、研究機(jī)構(gòu)和大學(xué)均支持 oneAPI。
作為 oneAPI 中最重要的高級(jí)庫(kù)組件之一,oneVPL (Intel oneAPI Video Processing Library)可以在英特爾的 CPU、GPU 等硬件平臺(tái)上實(shí)現(xiàn)對(duì)視頻數(shù)據(jù)的解碼,編碼與處理功能,支持 AVI,H.256 (HEVC),H.264 (AVC),MPEG-2,VP9 等多種媒體標(biāo)準(zhǔn)的硬件解碼能力。目前 oneVPL 已經(jīng)適配以下型號(hào)的 GPU 硬件:
11thgeneration Intel Core processors with XeArchitecture GPUs
Intel Iris XeMAX
Intel Arc A-series graphics
Intel Data Center GPU Flex Series
Upcoming GPU platforms
更多關(guān)于英特爾硬件編解碼格式的支持可以參考
任務(wù)開發(fā)流程
該方案將依托于英特爾的 GPU 設(shè)備執(zhí)行視頻分析業(yè)務(wù),主要有以下幾個(gè)原因:
通常情況下,在性能和功耗等方面,相較 CPU 的軟解碼,GPU 中專用編解碼器往往可以提供更強(qiáng)大的硬件解碼能力,輸入視頻的分辨率越高,這里的性能差異也越明顯。
此外鑒于 GPU 設(shè)備在并行能力上的優(yōu)勢(shì),OpenVINO在調(diào)用英特爾最新的集成顯卡 iGPU 和獨(dú)立顯卡 dGPU 推理時(shí),也能發(fā)揮出比較優(yōu)異的吞吐量表現(xiàn)。
最后調(diào)用 GPU 推理也能最大化提升英特爾架構(gòu)的資源利用率,在邊緣計(jì)算的任務(wù)架構(gòu)中,系統(tǒng)不需要 GPU 來處理圖像的渲染業(yè)務(wù),而 CPU 往往需要承擔(dān)更多資源調(diào)度方面的工作,通過將視頻分析任務(wù)搬運(yùn)到 CPU 自帶的集成顯卡中,不光能充分利用這部分閑置的資源,并且可以減輕 CPU 上的工作負(fù)載,進(jìn)一步優(yōu)化方案成本。
因此我們要確保在整個(gè)視頻流分析鏈路中,中間數(shù)據(jù)可以被“保留”在 GPU 的內(nèi)存中,避免與 host 之間額外的傳輸開銷,同時(shí)也減少在同一設(shè)備中的數(shù)據(jù)搬運(yùn),也就是所謂的“零拷貝”,從而實(shí)現(xiàn) GPU 處理性能的最大化。
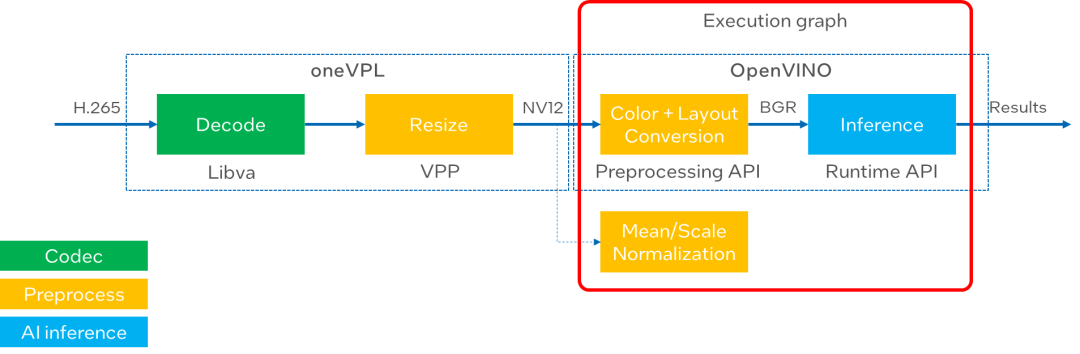
圖:GPU 視頻分析流水線
接下來我們就通過一個(gè)簡(jiǎn)單的單通道示例,還看下如何優(yōu)化 GPU 上的視頻分析服務(wù)。在這個(gè)示例中,輸入數(shù)據(jù)是一段 H.265 的視頻文件,我們可以把整個(gè)流水線分成以下4個(gè)部分,分別對(duì)應(yīng) oneVPL 和 OpenVINO工具套件中不同的組件接口。
1.視頻解碼 (Libva)
oneVPL依賴于Libva庫(kù),通過對(duì)VA-API (Video Acceleration API)接口的上層封裝,實(shí)現(xiàn)了 GPU 硬件編解碼能力。在這個(gè)示例中關(guān)于解碼部分可以有以下幾個(gè)步驟被抽象出來:
利用 MFXVideoDECODE_Init 接口,通過 oneVPL session 初始化解碼模塊:
sts = MFXVideoDECODE_Init(session, &mfxDecParams);
向右滑動(dòng)查看完整代碼
讀取視頻流,并封裝到 bitstream buffer 中:
sts = ReadEncodedStream(bitstream, source);
向右滑動(dòng)查看完整代碼
調(diào)用 MFXVideoDECODE_DecodeFrameAsync 接口執(zhí)行解碼任務(wù),將解碼后的數(shù)據(jù)寫入 pmfxDecOutSurfac 地址
sts=MFXVideoDECODE_DecodeFrameAsync(session, (isDrainingDec)?NULL:&bitstream, NULL, &pmfxDecOutSurface, &syncp);
向右滑動(dòng)查看完整代碼
2.圖像縮放(VPP):
接下來使用 oneVPL 中的 VPP(Video processing functions)模塊來實(shí)現(xiàn)對(duì)于圖像的縮放處理,首先我們需要定義一些關(guān)鍵參數(shù),例如輸出圖像的色彩通道與縮放后的圖像尺寸,這里為了能實(shí)現(xiàn)編碼輸出與推理輸入的零拷貝共享,我們需要將輸出的色彩格式設(shè)置為 NV12:
mfxVPPParams.vpp.Out.FourCC = MFX_FOURCC_NV12; mfxVPPParams.vpp.Out.ChromaFormat=MFX_CHROMAFORMAT_YUV420; mfxVPPParams.vpp.Out.Width=ALIGN16(vppOutImgWidth); mfxVPPParams.vpp.Out.Height=ALIGN16(vppOutImgHeight);
向右滑動(dòng)查看完整代碼
利用 MFXVideoVPP_Init 接口,初始化 VPP 模塊:
sts = MFXVideoVPP_Init(session, &mfxVPPParams);
向右滑動(dòng)查看完整代碼
將解碼后的輸出數(shù)據(jù)地址送入 MFXVideoVPP_ProcessFrameAsync 接口,進(jìn)行圖像縮放處理,并以指定的色彩通道輸出:
MFXVideoVPP_ProcessFrameAsync(session, pmfxDecOutSurface, &pmfxVPPSurfacesOut);
向右滑動(dòng)查看完整代碼
3.色彩空間與數(shù)據(jù)排布轉(zhuǎn)換(OpenVINO Preprocessing API):
Preprocessing API 是OpenVINO 2022.1版本中新增加的一個(gè)功能,可以實(shí)現(xiàn)將一些常規(guī)的前處理操作以 node 節(jié)點(diǎn)的形式集成到OpenVINO模型的 runtime 執(zhí)行圖中,從而實(shí)現(xiàn)將這部分計(jì)算過程加載到指定的硬件平臺(tái)進(jìn)行執(zhí)行,同時(shí)利用 OpenVINO 強(qiáng)大的模型加速能力,提升前處理任務(wù)性能,這里可以被支持的前處理任務(wù)包含:
精度轉(zhuǎn)換:U8 buffer to FP32
Layout轉(zhuǎn)換:Transform to planar format: from {1, 480, 640, 3} to {1, 3, 480, 640}
Resize :640x480 to 224x224
色彩空間轉(zhuǎn)換:BGR->RGB
Normalization:mean/scale
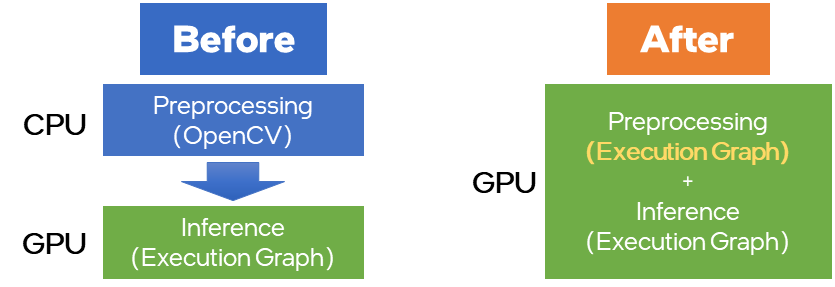
圖:Preprocessing API 功能示意
這里我們將部分 VPP 不支持的前處理算子,通過 Preprocessing API 的方式將他們放到 GPU 上去執(zhí)行,一方面可以減少 CPU 上任務(wù)的負(fù)載,一方面可以避免額外的 Device to Host 內(nèi)存拷貝。查詢 Open Model Zoo 的預(yù)訓(xùn)練模型說明可知,本示例用到車輛檢測(cè)模型的輸入數(shù)據(jù)通道要求為 BGR,數(shù)據(jù)排布為 NCHW,因此在調(diào)用 Preprocessing API 時(shí),我們需要實(shí)現(xiàn)這兩種格式的轉(zhuǎn)換:

圖:vehicle-detection-0200 模型輸入要求說明
回到代碼部分,我們調(diào)用 pre_post_process 頭文件中的相應(yīng)函數(shù)實(shí)現(xiàn)對(duì) VPP 輸出數(shù)據(jù)的色彩空間轉(zhuǎn)換(YUV->BGR)和排布轉(zhuǎn)換(NHWC->NCHW),并且最終通過 build 方法,將這部分前處理任務(wù)集成到原始模型的執(zhí)行圖中,生成新的 model 對(duì)象:
autop=PrePostProcessor(model); p.input().tensor().set_element_type(ov::u8) //YUVimagescanbesplitintoseparateplanes .set_color_format(ov::NV12_TWO_PLANES,{"y","uv"}) .set_memory_type(ov::surface); //Changecolorformat p.input().preprocess().convert_color(ov::BGR);//Changelayout p.input().model().set_layout("NCHW"); model=p.build();
向右滑動(dòng)查看完整代碼
此處,NV12 會(huì)被拆分為 Y 和 UV 兩個(gè)分量,如果不執(zhí)行 NCHW 的轉(zhuǎn)換,運(yùn)行時(shí)會(huì)由于通道維度不匹配而報(bào)錯(cuò)。
4. 模型推理(OpenVINO runtime):
為了實(shí)現(xiàn)零拷貝的訴求,該示例中用到的 OpenVINO的“Remote Tensor API of GPU Plugin”相關(guān)接口,以實(shí)現(xiàn)與 VA-API 組件對(duì)于 GPU 內(nèi)存中視頻數(shù)據(jù)的共享。具體步驟如下:
創(chuàng)建 GPU 中共享內(nèi)存的上下文:
auto shared_va_context = ov::VAContext(core, lvaDisplay);
向右滑動(dòng)查看完整代碼
獲取VPP輸出結(jié)果的句柄,并通過 create_tensor_nv12 接口將 VA-API surface 轉(zhuǎn)化并封裝成 OpenVINO的 tensor 內(nèi)存對(duì)象:
lvaSurfaceID=*(VASurfaceID*)lresource; //WrapVPPoutputintoremoteblobsandsetitasinferenceinput autonv12_blob=shared_va_context.create_tensor_nv12(height,width,lvaSurfaceID);
向右滑動(dòng)查看完整代碼
在推理請(qǐng)求中載入該內(nèi)存對(duì)象,并執(zhí)行推理:
infer_request.set_tensor(new_input0->get_friendly_name(),nv12_blob.first); infer_request.set_tensor(new_input1->get_friendly_name(),nv12_blob.second); //startinferenceonGPU infer_request.start_async(); infer_request.wait();
向右滑動(dòng)查看完整代碼
可以發(fā)現(xiàn),不同于原始模型,這里輸入數(shù)據(jù)變成兩份,原因是在上一步調(diào)用 Preprocessing API 的過程中,我們將 NV12 還原到 Y 和 UV 兩個(gè)分量,所以原始模型的輸入數(shù)據(jù)數(shù)也要做相應(yīng)調(diào)整。
參考示例使用方法
本示例已在 Ubuntu20.04 及第十一代英特爾酷睿 iGPU 及A RCA380dGPU 環(huán)境下進(jìn)行了驗(yàn)證。
1.下載示例 
2.安裝相應(yīng)組件和依賴
可以參考該示例倉(cāng)庫(kù)中的README文檔進(jìn)行環(huán)境安裝:
https://github.com/OpenVINO-dev-contest/decode-infer-on-GPU
3.下載預(yù)訓(xùn)練模型
這個(gè)示例中我們用到了 Open Model Zoo 的 vehicle-detection-0200 模型用于對(duì)視頻流中的車輛進(jìn)行檢測(cè),具體下載命令如下:
 ? 4.編譯并執(zhí)行推理任務(wù)
? 4.編譯并執(zhí)行推理任務(wù)

5.運(yùn)行輸出
最終效果如下:
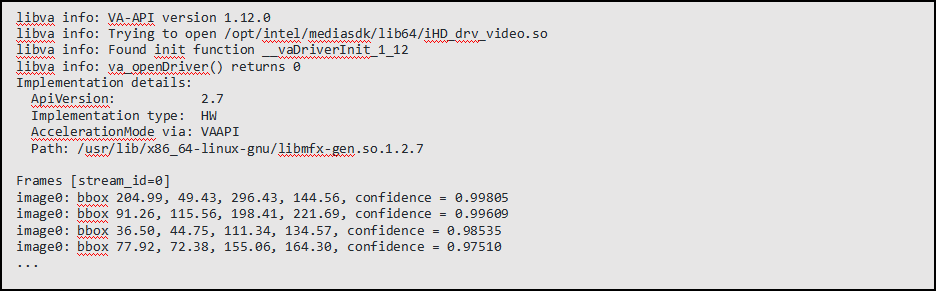
該示例會(huì)輸出每一幀畫面中被檢測(cè)到車輛的置信度,以及在畫面中的坐標(biāo)信息等。
結(jié)論
利用 oneAPI 的 oneVPL 組件,以及 OpenVINO的 Preprocessing API 和 remote tensor 接口,我們可以在英特爾 GPU 硬件單元上構(gòu)建從解碼,前處理,推理的視頻分析全流程應(yīng)用,且沒有額外的內(nèi)存拷貝,大大提升對(duì) GPU 資源的利用率。隨著越來越多的英特爾獨(dú)立顯卡系列產(chǎn)品的推出,相信這樣一套參考設(shè)計(jì)幫助開發(fā)者在 GPU 平臺(tái)上實(shí)現(xiàn)更出色的性能表現(xiàn)。
審核編輯:湯梓紅
-
英特爾
+關(guān)注
關(guān)注
60文章
9886瀏覽量
171502 -
gpu
+關(guān)注
關(guān)注
28文章
4700瀏覽量
128703 -
AI
+關(guān)注
關(guān)注
87文章
30143瀏覽量
268411 -
人工智能
+關(guān)注
關(guān)注
1791文章
46857瀏覽量
237552 -
視頻分析
+關(guān)注
關(guān)注
0文章
27瀏覽量
10832
原文標(biāo)題:基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線
文章出處:【微信號(hào):英特爾物聯(lián)網(wǎng),微信公眾號(hào):英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
FPGA中的流水線設(shè)計(jì)
周期精確的流水線仿真模型
流水線中的相關(guān)培訓(xùn)教程[1]
流水線ADC的行為級(jí)仿真
淺談GPU的渲染流水線實(shí)現(xiàn)
FPGA之流水線練習(xí)(3):設(shè)計(jì)思路
FPGA之為什么要進(jìn)行流水線的設(shè)計(jì)
各種流水線特點(diǎn)及常見流水線設(shè)計(jì)方式
如何選擇合適的LED生產(chǎn)流水線輸送方式
嵌入式_流水線






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論