") 使用MAX78000進(jìn)行人臉識(shí)別
使用MAX78000進(jìn)行人臉識(shí)別
MAX78000為超低功耗卷積神經(jīng)網(wǎng)絡(luò)(CNN)推理引擎,用于在物聯(lián)網(wǎng)的微小邊緣運(yùn)行人工智能(AI)計(jì)算。然而,該設(shè)備可以執(zhí)行許多復(fù)雜的網(wǎng)絡(luò),以實(shí)現(xiàn)關(guān)鍵和流行的應(yīng)用。本文介紹一種在MAX78000上運(yùn)行人臉識(shí)別(FaceID)的方法,該方法使用Maxim在PyTorch上的開(kāi)發(fā)流程構(gòu)建模型,使用不同的開(kāi)放數(shù)據(jù)集進(jìn)行訓(xùn)練,并部署在MAX78000評(píng)估板上。
介紹
40多年來(lái),人臉識(shí)別系統(tǒng)一直是研究的主題。機(jī)器學(xué)習(xí)的最新進(jìn)展導(dǎo)致了研究的急劇增加和許多成功方法的出現(xiàn)。面部識(shí)別或識(shí)別技術(shù)今天比過(guò)去任何時(shí)候都更加重要,因?yàn)樗浅F毡椋⑶乙肓擞嘘P(guān)如何捕獲和共享面部信息的隱私問(wèn)題。除了隱私問(wèn)題外,這些應(yīng)用程序的延遲和功耗對(duì)于許多移動(dòng)或物聯(lián)網(wǎng)設(shè)備也很重要。
本應(yīng)用筆記研究了使用MAX78000 CNN推理引擎在邊緣運(yùn)行人臉識(shí)別(FaceID)以最小的延遲和優(yōu)化的功耗。該應(yīng)用面臨的挑戰(zhàn)是設(shè)計(jì)具有高性能的CNN架構(gòu),同時(shí)保持網(wǎng)絡(luò)中的系數(shù)數(shù)量比許多尖端的深人臉識(shí)別網(wǎng)絡(luò)(即DeepFace)少300倍。[1].
卷積神經(jīng)網(wǎng)絡(luò)(CNN)非常有用,因?yàn)樗鼈冊(cè)试S從輸入數(shù)據(jù)中學(xué)習(xí)位置和尺度無(wú)關(guān)的特征。卷積內(nèi)核的長(zhǎng)度一般較小,即 3 × 3、7 × 7 等,提供了極大的內(nèi)存效率。隨著許多不同的研究表明所提供的性能提升以及模型大小的減小,對(duì)這些網(wǎng)絡(luò)的興趣有所增加。這種架構(gòu)的缺點(diǎn)是計(jì)算負(fù)載較高,可能會(huì)產(chǎn)生高能耗和延遲。本研究通過(guò)MAX78000的獨(dú)特設(shè)計(jì)克服了這些問(wèn)題。
本文簡(jiǎn)要介紹MAX78000 CNN推理引擎,并介紹開(kāi)發(fā)模型以識(shí)別適合芯片的人臉的方法。然后描述所開(kāi)發(fā)模型的綜合,并解釋MAX78000評(píng)估板的應(yīng)用軟件。
CNN 推理引擎 – MAX78000
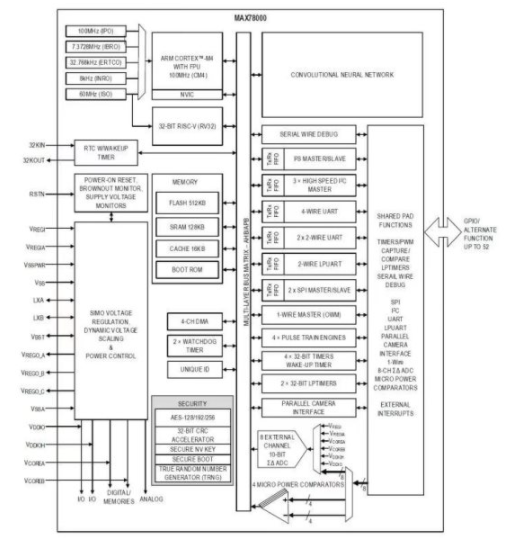
The MAX78000[2]是一種新型人工智能 (AI) 微控制器,旨在使神經(jīng)網(wǎng)絡(luò)能夠以超低功耗執(zhí)行并生活在物聯(lián)網(wǎng)邊緣。該產(chǎn)品將最節(jié)能的AI處理與Maxim經(jīng)過(guò)驗(yàn)證的超低功耗微控制器相結(jié)合。基于硬件的 CNN 加速器使電池供電的應(yīng)用程序能夠執(zhí)行 AI 推理,同時(shí)僅消耗微焦耳的能量。這使其成為能源關(guān)鍵型應(yīng)用的理想架構(gòu)。MAX78000具有帶浮點(diǎn)單元(FPU)CPU的Arm Cortex-M4,通過(guò)超低功耗深度神經(jīng)網(wǎng)絡(luò)加速器實(shí)現(xiàn)高效的系統(tǒng)控制。圖1.MAX78000的結(jié)構(gòu)顯示了MAX78000的頂層架構(gòu)。??
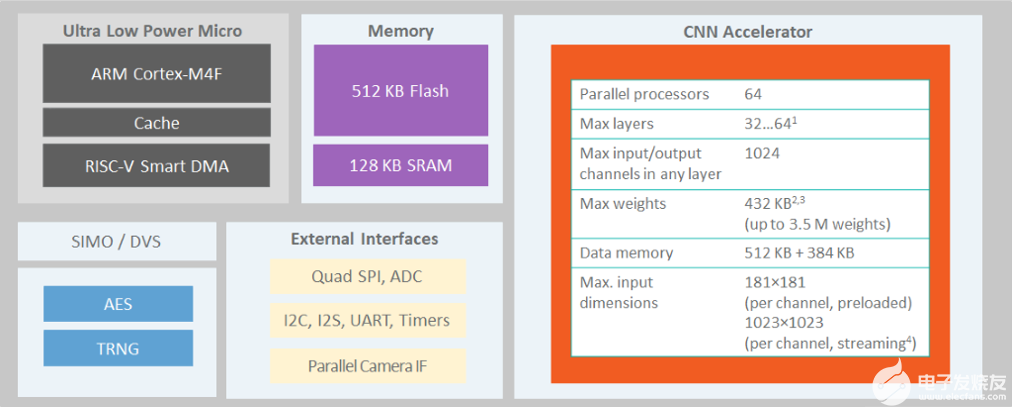
圖1.MAX78000的結(jié)構(gòu)
MAX78000評(píng)估板[3]提供一個(gè)平臺(tái),利用MAX78000的功能構(gòu)建新一代AI器件。評(píng)估板具有板載硬件,如數(shù)字麥克風(fēng)、串行端口、攝像頭模塊支持和3.5英寸觸摸彩色薄膜晶體管(TFT)顯示屏。
MAX78000開(kāi)發(fā)流程
PyTorch或TensorFlow-Keras工具鏈可用于開(kāi)發(fā)MAX78000的模型。該模型是使用一系列表示硬件的已定義子類(lèi)創(chuàng)建的。池化或激活等一些操作融合到 1D 或 2D 卷積層以及全連接層。還添加了舍入和剪裁以匹配硬件。
該模型使用浮點(diǎn)權(quán)重和訓(xùn)練數(shù)據(jù)進(jìn)行訓(xùn)練。權(quán)重可以在訓(xùn)練期間(量化感知訓(xùn)練)或訓(xùn)練后(訓(xùn)練后量化)量化。可以在評(píng)估數(shù)據(jù)集上評(píng)估量化結(jié)果,以檢查由于權(quán)重量化而導(dǎo)致的精度下降。
MAX78000合成器工具(ai8xize)接受PyTorch檢查點(diǎn)或TensorFlow導(dǎo)出的ONNX文件作為輸入,以及YAML格式的模型描述。輸入示例數(shù)據(jù)文件(.npy文件)也提供給合成器,以驗(yàn)證硬件上的合成模型。將此數(shù)據(jù)文件的推理結(jié)果與預(yù)合成模型的預(yù)期輸出進(jìn)行比較。
MAX78000頻率合成器自動(dòng)生成C代碼,可在MAX78000上編譯和執(zhí)行。C 代碼包括應(yīng)用程序編程接口 (API) 調(diào)用,用于將權(quán)重以及提供的示例數(shù)據(jù)加載到硬件,對(duì)示例數(shù)據(jù)執(zhí)行推理,并將分類(lèi)結(jié)果與預(yù)期結(jié)果進(jìn)行比較,作為通過(guò)/失敗健全性測(cè)試。此生成的 C 代碼可用作創(chuàng)建自定義應(yīng)用程序的示例。圖2所示為MAX78000的整體開(kāi)發(fā)流程。
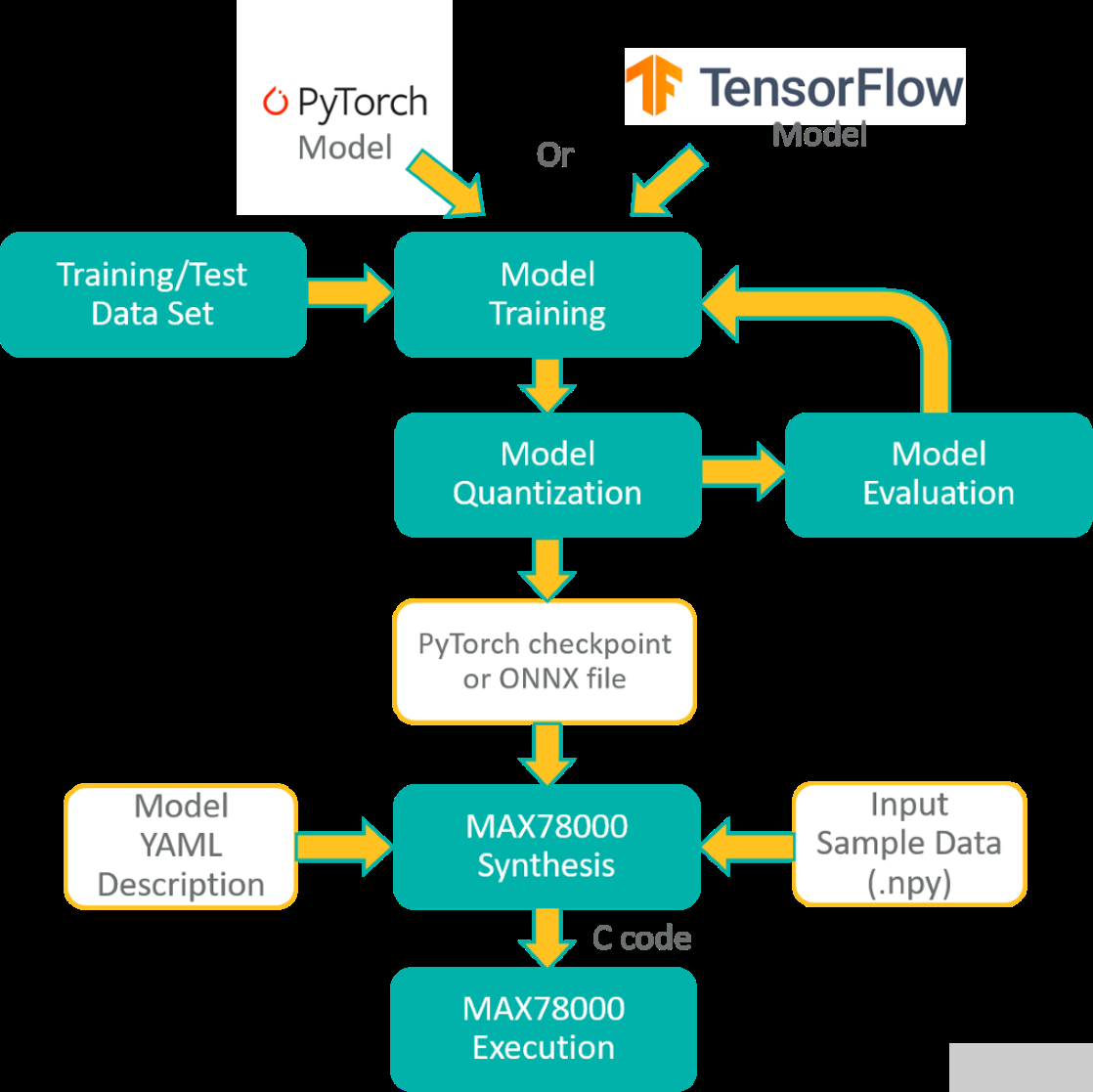
圖2.MAX78000的開(kāi)發(fā)流程
面容模型開(kāi)發(fā)方法
人臉識(shí)別問(wèn)題分三個(gè)主要步驟解決:
人臉提取:檢測(cè)圖像中的人臉以提取僅包含一個(gè)人臉的矩形子圖像。
面部對(duì)齊:確定子圖像中面部的旋轉(zhuǎn)角度(3D),以通過(guò)仿射變換補(bǔ)償其效果。
人臉識(shí)別:使用提取和對(duì)齊的子圖像識(shí)別人。
前兩個(gè)步驟有不同的方法。多任務(wù)級(jí)聯(lián)卷積神經(jīng)網(wǎng)絡(luò) (MTCNN)[4]解決人臉檢測(cè)和對(duì)齊步驟。人臉識(shí)別通常作為一個(gè)不同的問(wèn)題來(lái)研究,這是本次演示的重點(diǎn)。MAX78000評(píng)估板用于識(shí)別未裁剪的人臉,每張臉僅包含一個(gè)人臉。
所采用的方法基于為每個(gè)面部圖像學(xué)習(xí)簽名,即嵌入,其與另一個(gè)嵌入的距離可以衡量面部的相似性。預(yù)計(jì)可以觀察到同一個(gè)人的臉之間的距離很小,而不同人的臉之間的距離很大。
面網(wǎng)[5]是為基于嵌入的人臉識(shí)別方法開(kāi)發(fā)的最流行的基于 CNN 的模型之一。三重?fù)p失是其成功背后的關(guān)鍵。此損失函數(shù)采用三個(gè)輸入樣本:錨點(diǎn)、與定位點(diǎn)來(lái)自同一恒等的正樣本和來(lái)自不同恒等式的負(fù)樣本。當(dāng)錨點(diǎn)的距離接近正樣本而遠(yuǎn)離負(fù)樣本時(shí),三重?fù)p失函數(shù)給出較低的值(圖 3)。
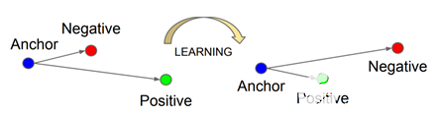
圖3.三重?fù)p耗使錨點(diǎn)和正極之間的距離最小化,并使錨點(diǎn)和負(fù)極之間的距離最大化[2].
但是,該型號(hào)有750萬(wàn)個(gè)參數(shù),對(duì)于MAX78000來(lái)說(shuō)太大了。它還需要 1.6G 浮點(diǎn)運(yùn)算,這使得該模型很難在許多移動(dòng)或物聯(lián)網(wǎng)設(shè)備上運(yùn)行。因此,設(shè)計(jì)了小于450k參數(shù)的新模型架構(gòu),以適應(yīng)MAX78000。
采用知識(shí)蒸餾方法來(lái)開(kāi)發(fā)FaceNet的這個(gè)更小的CNN模型,因?yàn)樗荈aceID應(yīng)用程序廣泛贊賞的神經(jīng)網(wǎng)絡(luò)。
機(jī)器學(xué)習(xí)中的知識(shí)蒸餾是將知識(shí)從大型模型轉(zhuǎn)移到較小模型的過(guò)程[6].大型模型比小型模型具有更高的知識(shí)容量。然而,這一能力可能沒(méi)有得到充分利用。因此,這里的目的是將大網(wǎng)絡(luò)的確切行為傳授給較小的網(wǎng)絡(luò)。
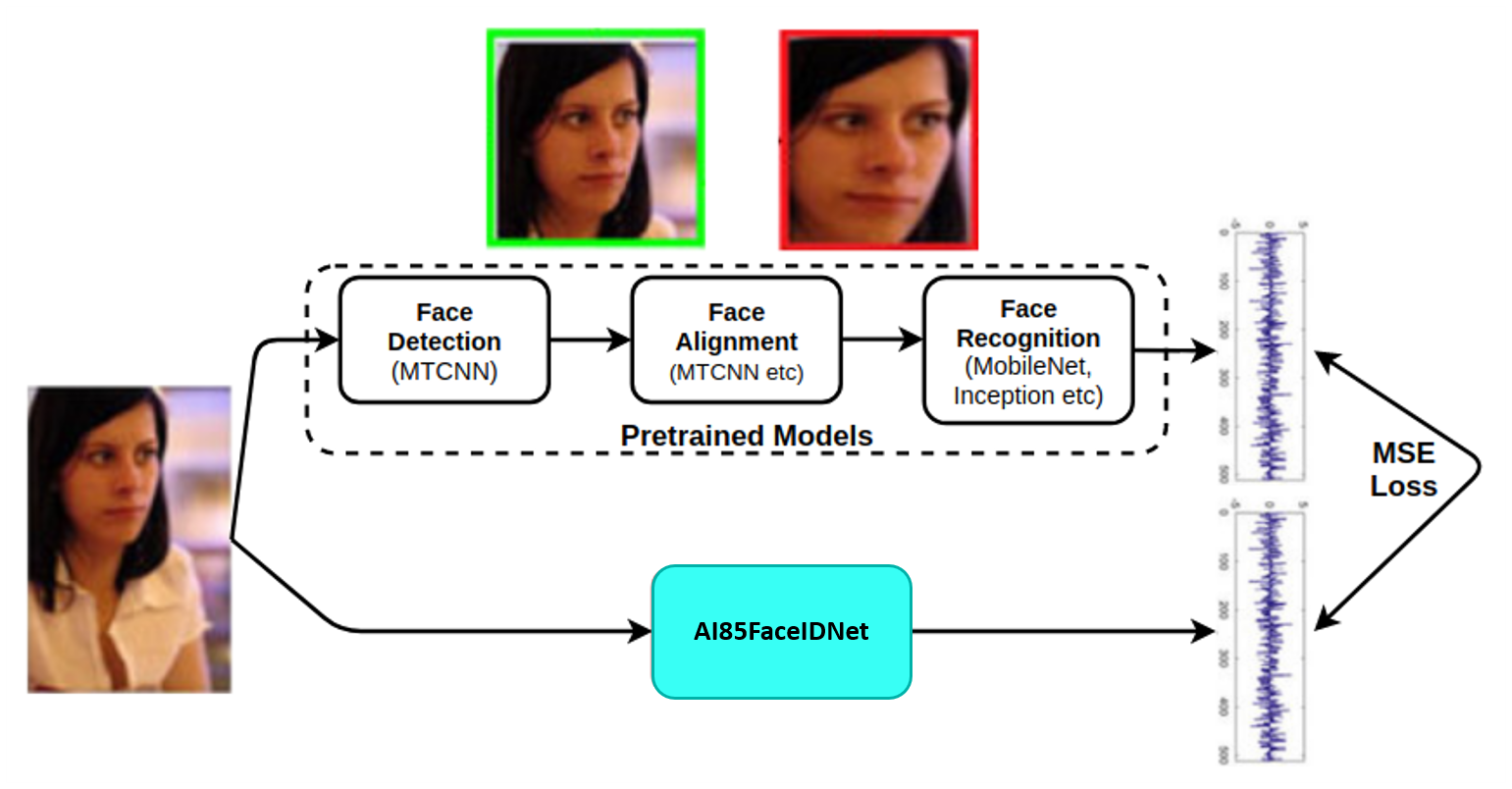
圖4.模型開(kāi)發(fā)的方法。
圖4.模型開(kāi)發(fā)方法總結(jié)了如何利用預(yù)訓(xùn)練的MTCNN和FaceNet模型來(lái)開(kāi)發(fā)緊湊的FaceID模型AI85FaceIdNet。嵌入FaceNet模型被用作AI85FaceIdNet的目標(biāo)。沒(méi)有中心損失、三重?fù)p失等,因?yàn)檫@些都由 FaceNet 模型覆蓋。模型開(kāi)發(fā)中使用的損失是目標(biāo)嵌入和預(yù)測(cè)嵌入之間的均方誤差 (MSE),這也是定義人臉相似性的距離。
數(shù)據(jù)
模型的訓(xùn)練是使用以下數(shù)據(jù)集完成的:
VGGFace-2 [7]:一個(gè)大規(guī)模的人臉識(shí)別數(shù)據(jù)集。
YouTube面孔[8]:旨在研究不受約束的人臉識(shí)別問(wèn)題的人臉視頻數(shù)據(jù)庫(kù)。
根據(jù)網(wǎng)絡(luò)上找到的六張圖像為選定的 15 位女性和 15 位男性名人創(chuàng)建一個(gè)數(shù)據(jù)集來(lái)測(cè)試模型。此數(shù)據(jù)集在本文檔的其余部分中稱為 MaximCeleb。
數(shù)據(jù)集生成和擴(kuò)充
數(shù)據(jù)集中的每個(gè)圖像隨機(jī)裁剪 120 × 160 × 3(寬度×高度×深度)子圖像。由預(yù)訓(xùn)練的MTCNN模型在子圖像中檢測(cè)到并對(duì)齊的人臉被饋送到預(yù)訓(xùn)練的FaceNet模型以創(chuàng)建嵌入。請(qǐng)注意,兩個(gè)重新訓(xùn)練的模型都取自[9].因此,生成的嵌入的長(zhǎng)度為 512。最后,將 120 × 160 個(gè) RGB 面部圖像與其所有者和嵌入一起存儲(chǔ),以便在訓(xùn)練期間使用。
面部在新圖像中的位置和方向各不相同。預(yù)計(jì)它應(yīng)該有一個(gè)模型,該模型對(duì)圖像中頭部的少量轉(zhuǎn)換具有魯棒性。
CNN 模型訓(xùn)練
MAX78000 FaceID型號(hào)AI85FaceIdNet由8個(gè)順序卷積模塊組成。圖7.AI85FaceIdNet網(wǎng)絡(luò)結(jié)構(gòu)顯示了CNN模型。某些圖層包括池化操作以減小輸入的大小。類(lèi)似地,將 512 × 5 × 3 大小的張量與 (5 × 3) 核平均,以獲得最后一層的 512 大小的嵌入。

圖7.AI85人臉網(wǎng)絡(luò)結(jié)構(gòu)。
使用以下命令使用Maxim工具對(duì)模型進(jìn)行訓(xùn)練:
train.py –epochs 100 –optimizer Adam –lr 0.001 –deterministic –compress schedule-faceid.yaml –model ai85faceidnet –dataset FaceID --batch-size 100 –device MAX78000 –regression
該腳本在訓(xùn)練過(guò)程結(jié)束時(shí)創(chuàng)建模型的檢查點(diǎn)文件,并在驗(yàn)證集上得分最高。然后,對(duì)浮點(diǎn)權(quán)重進(jìn)行量化,MAX78000為整數(shù)運(yùn)算器件。使用以下命令的Maxim工具進(jìn)行轉(zhuǎn)換也很簡(jiǎn)單:
./quantize.py --device MAX78000 -v -c networks/faceid.yaml –scale 1.05
模型性能
使用包含30位名人(15位女性和15位男性)面孔的MaximCeleb數(shù)據(jù)集分析模型的性能。
對(duì)于女性和男性數(shù)據(jù)集,通過(guò)使用其自身嵌入到其余89張圖像嵌入的距離,根據(jù)每個(gè)圖像的識(shí)別準(zhǔn)確性,分別評(píng)估模型的性能。用于定義最近嵌入的距離度量和算法也是應(yīng)用程序中的度量和算法。
在此分析中,選擇 L2(歐幾里得)范數(shù)作為嵌入之間的距離。提取所有主體的嵌入到給定圖像嵌入的平均距離,以確定最近的主體。然后,該算法返回其嵌入平均最接近給定嵌入的主題。表1顯示了MTCNN和FaceNet組合的性能,以及MAX78000上運(yùn)行的AI85FaceIdNet的性能。圖 8 和圖 9 顯示了每個(gè)數(shù)據(jù)集的混淆矩陣。
| 馬克西西勒布數(shù)據(jù)集 | ||||
| 女性 | 雄 | |||
| MTCNN+FACENET | AI85面孔 | MTCNN+FACENET | AI85面孔 | |
| 準(zhǔn)確度 (%) | 94.4 | 78.9 | 94.4 | 88.9 |
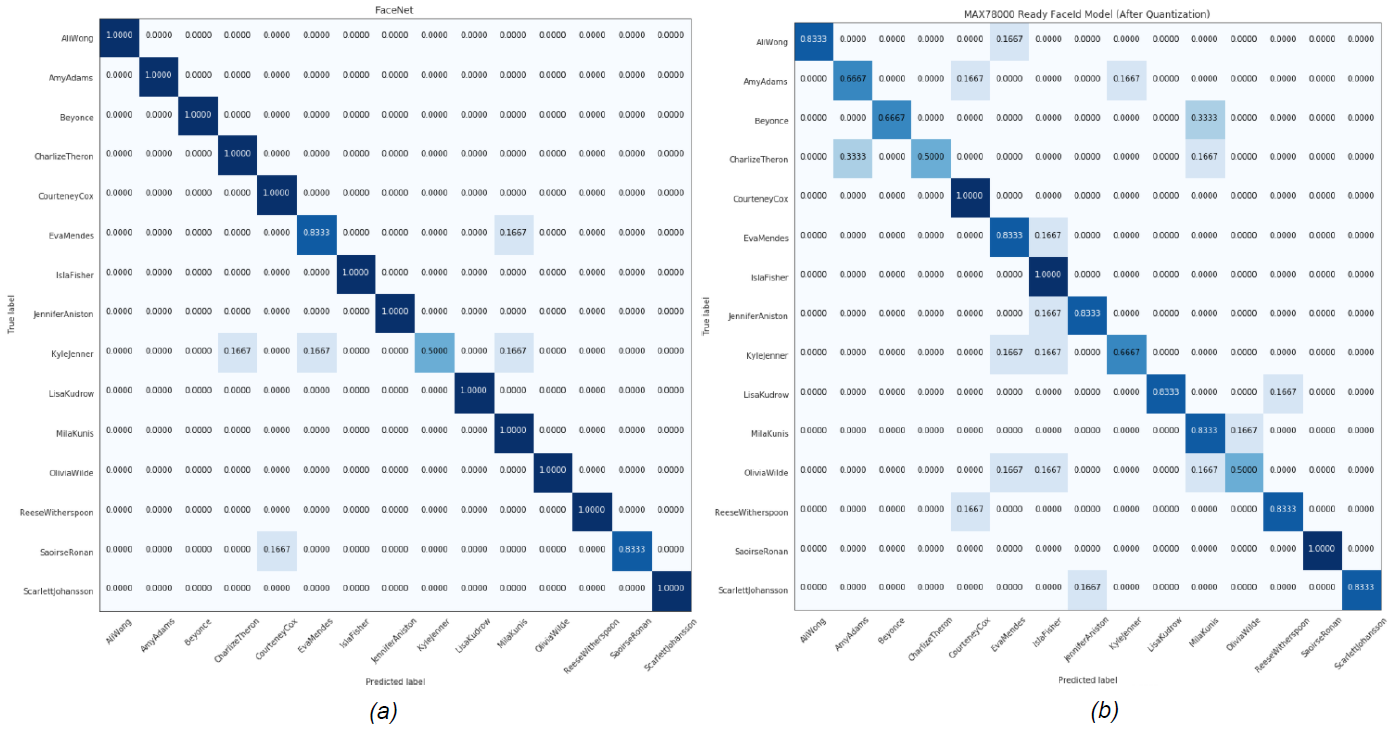
圖8.女性MaximCeleb數(shù)據(jù)集的(a)MTCNN+FaceNet (b)AI85FaceIdNet模型的混淆矩陣。
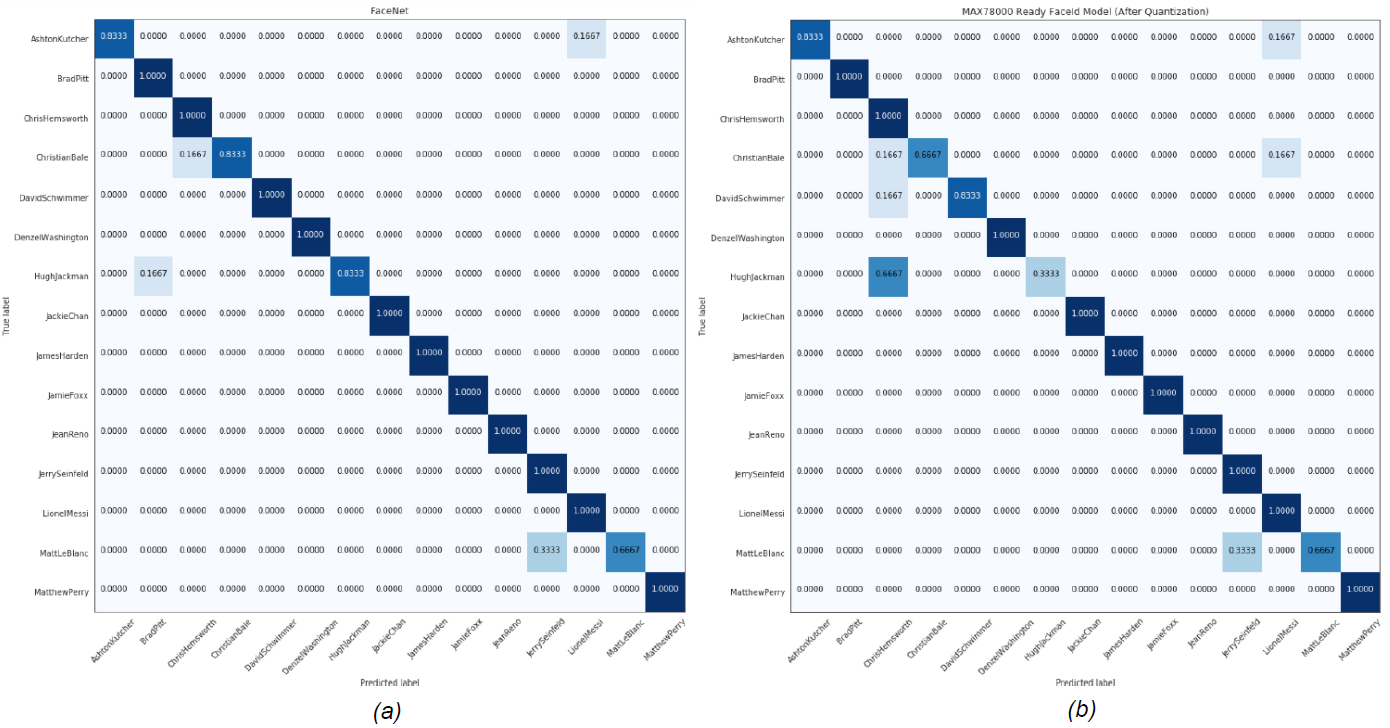
圖9.男性MaximCeleb數(shù)據(jù)集的(a)MTCNN+FaceNet(b)AI85FaceIdNet模型的混淆矩陣。
識(shí)別未知受試者
利用所開(kāi)發(fā)模型的受試者工作特征(ROC)曲線來(lái)識(shí)別未知受試者。ROC 曲線是一個(gè)圖形圖,說(shuō)明了二元分類(lèi)器系統(tǒng)在其區(qū)分閾值變化時(shí)的診斷能力[10].
上一節(jié)將人臉到主體的距離定義為人臉嵌入到為每個(gè)主體存儲(chǔ)的整個(gè)嵌入的平均 L2 距離。決定是在確定與面部嵌入的距離最小的受試者時(shí)做出的。可以使用模型的 ROC 確定最小距離的閾值,因?yàn)槊總€(gè)圖像都被標(biāo)識(shí)為數(shù)據(jù)庫(kù)中的主體之一。
ROC 曲線是通過(guò)繪制不同閾值下的真陽(yáng)性 (TP) 率與假陽(yáng)性 (FP) 率的對(duì)比來(lái)創(chuàng)建的。因此,當(dāng)它在ROC曲線上移動(dòng)時(shí),閾值設(shè)置會(huì)發(fā)生變化,并且可以相對(duì)于所選性能確定閾值。
30個(gè)受試者的Maxim Celebrity數(shù)據(jù)集用于生成ROC曲線,其中數(shù)據(jù)庫(kù)中僅假設(shè)有15名女性(或男性)受試者。其余的被確定為未知受試者。正確分類(lèi)的樣品可提高 TP 率,而其他樣品可提高 FP 率。圖 10 顯示了男性和女性數(shù)據(jù)集的 AI85FaceId 模型的 ROC 曲線。
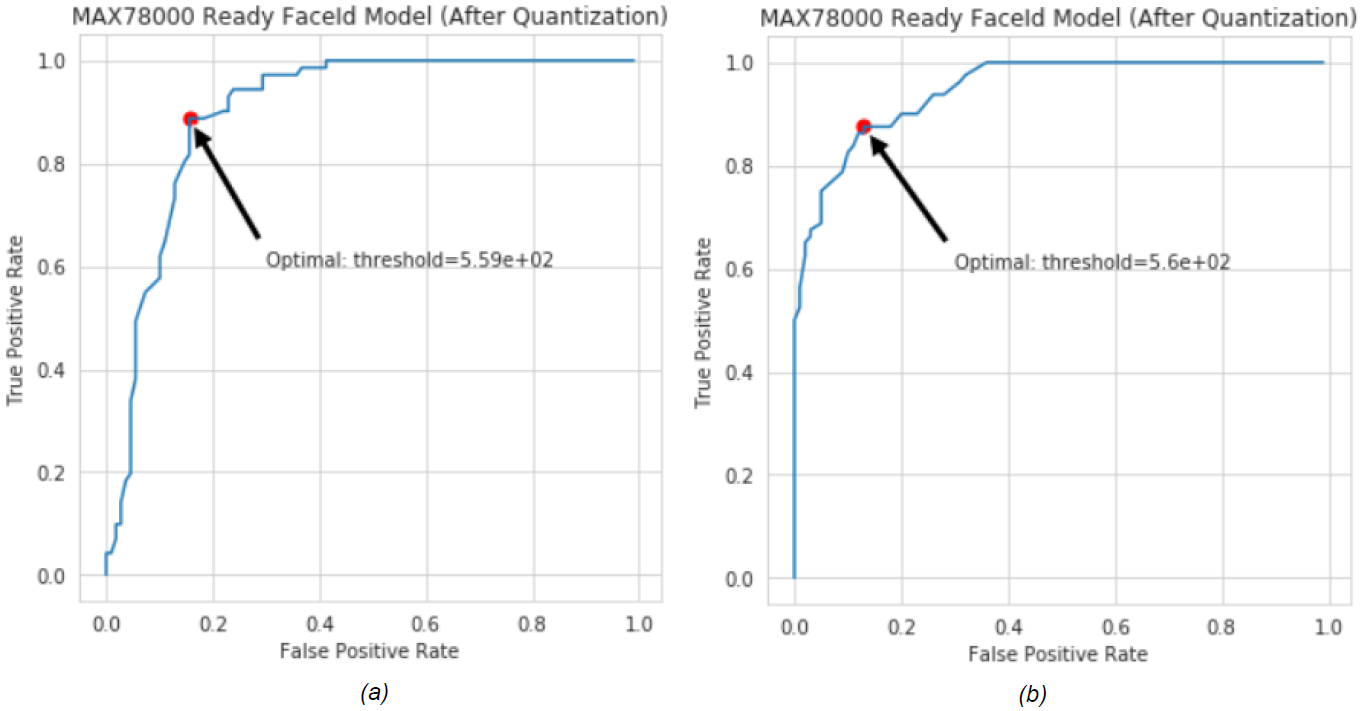
圖 10.AI85FaceIdNet的ROC曲線,用于(a)女性和(b)男性MaximCeleb數(shù)據(jù)集。
有不同的方法可以確定最佳閾值。ROC 曲線上最接近該點(diǎn) (TP = 1.0, FP = 0.0) 的點(diǎn)被選為閾值(圖 10)。兩組的最佳值都非常接近 560。因此,F(xiàn)aceID 應(yīng)用程序的未知主體閾值設(shè)置為 560。
CNN 模型合成
通過(guò)CNN模型訓(xùn)練部分給出的步驟得到的量化模型是MAX78000使用Maxim工具中的python腳本合成的。此腳本生成一個(gè) C 代碼,其中包括初始化 CNN 加速器、加載量化的 CNN 權(quán)重、為給定的示例輸入樣本運(yùn)行模型以及在準(zhǔn)備好以下三項(xiàng)后從設(shè)備獲取模型輸出的函數(shù):
量化的 PyTorch 檢查點(diǎn)文件或 TensorFlow 模型導(dǎo)出為 ONNX 格式。
網(wǎng)絡(luò)模型 YAML 說(shuō)明。
一個(gè)示例輸入,其中包含要包含在生成的 C 代碼中進(jìn)行驗(yàn)證的預(yù)期結(jié)果。
運(yùn)行以下腳本以生成合成代碼:
./ai8xize.py -e --verbose --top-level cnn -L --test-dir --prefix faceid --checkpoint-file --config-file networks/faceid.yaml --device MAX78000 --fifo --compact-data --mexpress --display-checkpoint --unload
準(zhǔn)系統(tǒng)C代碼用作構(gòu)建FaceID演示應(yīng)用程序的基礎(chǔ),以初始化設(shè)備,加載權(quán)重(內(nèi)核),推送示例輸入并獲取結(jié)果。
生成嵌入集
更改包含主題嵌入的頭文件 embeddings.h,以創(chuàng)建自定義數(shù)據(jù)集以運(yùn)行 FaceID 演示。db_gen文件夾中的 Python 腳本 generate_face_db.py 用于此目的。腳本的示例用法在gen_db.sh中給出。該腳本將存儲(chǔ)主題圖像的文件夾名稱作為參數(shù)。此文件夾必須包括每個(gè)主題的單獨(dú)子文件夾,并且這些子文件夾必須以主題的名稱或標(biāo)識(shí)符命名。圖 11 顯示了示例 db 文件夾結(jié)構(gòu)。受試者的圖像放置在關(guān)聯(lián)的文件夾中。
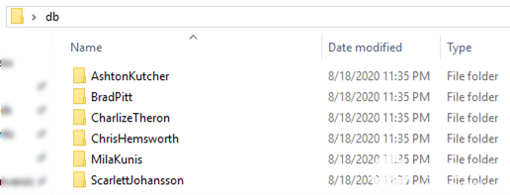
圖 11.用于生成自定義嵌入集的示例數(shù)據(jù)庫(kù)文件夾結(jié)構(gòu)。
像gen_db.sh和generate_face_db.py一樣使用參數(shù)調(diào)用,會(huì)自動(dòng)生成嵌入 embeddings.h,其中包含 db 文件夾中的圖像和主題。更改文件后,下一個(gè)構(gòu)建將成為具有更新嵌入列表的自定義版本。
$ ./gen_db.sh
用MTCNN進(jìn)行人臉識(shí)別,用檢測(cè)到的人臉裁剪120×160幀,并在generate_face_db.py中進(jìn)行照明校正。圖像必須大于 120 × 160,并且只能包含一個(gè)面向相機(jī)的主體。建議每個(gè)受試者至少五張圖像,以提高識(shí)別準(zhǔn)確性。
面容演示平臺(tái)
人臉識(shí)別在MAX78000評(píng)估板上使用FaceID固件進(jìn)行演示。評(píng)估板(圖12.MAX78000上的FaceID應(yīng)用截圖和圖11所示的主題數(shù)據(jù)庫(kù))由TFT屏幕和視頻圖形陣列(VGA)攝像頭組成,均朝上以在自拍模式下工作。演示應(yīng)用程序持續(xù)運(yùn)行并報(bào)告每個(gè)幀的一個(gè)預(yù)測(cè)。如果提取的嵌入與數(shù)據(jù)庫(kù)中主題的接近程度不超過(guò)預(yù)定義的閾值,則會(huì)報(bào)告未知類(lèi)。閾值是按照前面部分所述獲得的,可以更新(embedding_process.h 中的變量thresh_for_unknown_subject)。 可以使用 L1(曼哈頓)距離代替 L2 范數(shù),因?yàn)樗枰^少的計(jì)算。但必須相應(yīng)地重復(fù)未知閾值確定步驟。

圖 12.MAX78000上的FaceID應(yīng)用截圖,主題數(shù)據(jù)庫(kù)如圖11所示。
MAX78000評(píng)估板上的演示以縱向位置運(yùn)行,更適合拍攝和顯示自拍照。人臉必須位于藍(lán)色矩形中,因?yàn)榇瞬糠质且眉粢赃M(jìn)行處理的區(qū)域的中心。從原始捕獲中裁剪出三個(gè) 120 × 160 圖像,具有不同的 X 和 Y 偏移。這些被饋送到CNN模型,以提高作為增強(qiáng)方法的準(zhǔn)確性。在報(bào)告預(yù)測(cè)之前,通過(guò)向CNN發(fā)送多張覆蓋面部的圖像來(lái)測(cè)試預(yù)測(cè)的一致性。同樣,還測(cè)試了連續(xù)時(shí)間樣本中預(yù)測(cè)的一致性。這可能會(huì)給識(shí)別速度帶來(lái)一些滯后,但會(huì)增加應(yīng)用程序的魯棒性。圖 13 顯示了應(yīng)用程序的流程圖。
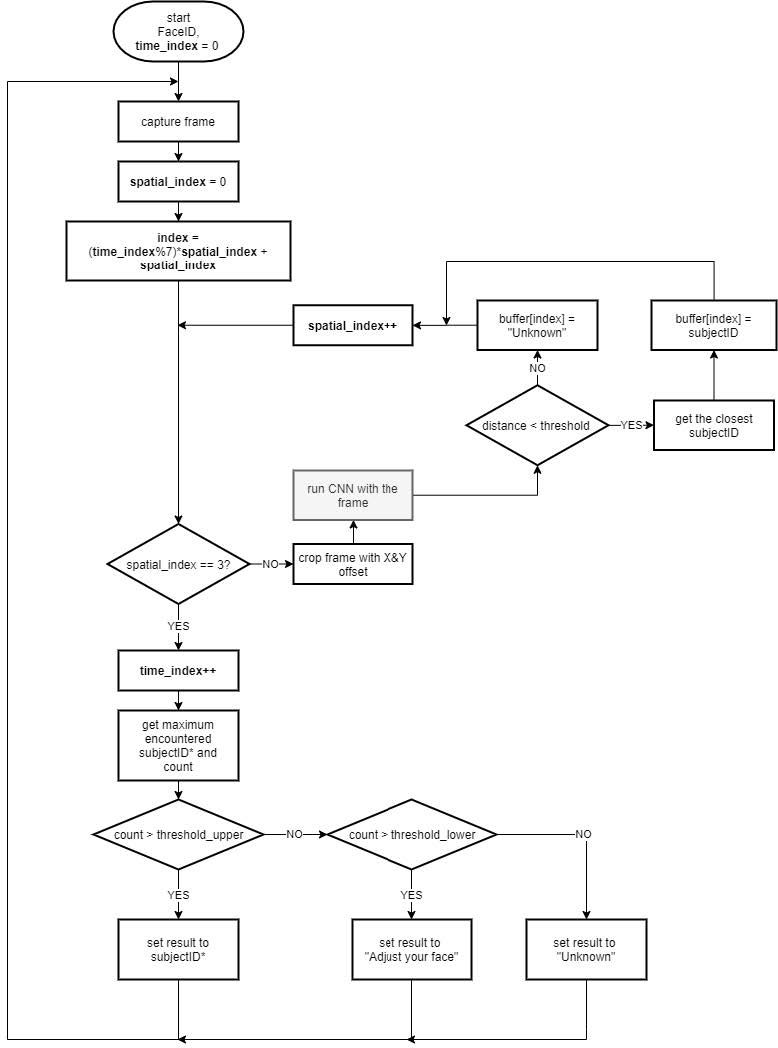
圖 13.MAX78000上FaceID演示應(yīng)用的工藝流程
結(jié)論
本應(yīng)用筆記演示了在MAX78000中實(shí)現(xiàn)人臉識(shí)別模型,以及如何在超低功耗MAX78000平臺(tái)上部署,用于資源受限的邊緣或物聯(lián)網(wǎng)應(yīng)用。該應(yīng)用遵循基于知識(shí)蒸餾的模型開(kāi)發(fā)方法,以滿足MAX78000的要求。因此,本文檔也可以作為將高性能大型網(wǎng)絡(luò)遷移到邊緣設(shè)備的指南。應(yīng)用筆記介紹了模型的性能分析以及合成模型以部署MAX78000所需的步驟。
審核編輯:郭婷
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2903文章
44269瀏覽量
371232 -
人工智能
+關(guān)注
關(guān)注
1791文章
46853瀏覽量
237546 -
人臉識(shí)別
+關(guān)注
關(guān)注
76文章
4005瀏覽量
81764
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于MAX78000FTHR的機(jī)器學(xué)習(xí)實(shí)時(shí)處理方案
請(qǐng)問(wèn)各位大神,菜鳥(niǎo)要做雙目攝像頭來(lái)進(jìn)行人臉識(shí)別該用什么dsp芯片??
Dragonboard 410c USB攝像頭進(jìn)行人臉識(shí)別
opencv和face++如何進(jìn)行人臉檢測(cè)嗎?
如何對(duì)RK3399的HDMI進(jìn)行人臉識(shí)別呢
MAX78000將能耗和延遲降低100倍,從而在IoT邊緣實(shí)現(xiàn)復(fù)雜的嵌入式?jīng)Q策
Maxim Integrated新型神經(jīng)網(wǎng)絡(luò)加速器MAX78000 SoC在貿(mào)澤開(kāi)售
美信半導(dǎo)體新型神經(jīng)網(wǎng)絡(luò)加速器MAX78000 SoC
在MAX78000上開(kāi)發(fā)功耗優(yōu)化應(yīng)用
用于MAX78000模型訓(xùn)練的數(shù)據(jù)加載器設(shè)計(jì)
厲害了,這3個(gè)項(xiàng)目獲得了MAX78000設(shè)計(jì)大賽一等獎(jiǎng)!
在MAX78000上開(kāi)發(fā)功耗優(yōu)化應(yīng)用
MAX78000人工智能設(shè)計(jì)大賽第二季回歸!賽題廣任意玩,獎(jiǎng)勵(lì)足直接沖!

MAX78000: Artificial Intelligence Microcontroller with Ultra-Low-Power Convolutional Neural Network Accelerator Data Sheet MAX78000: Artific






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論