") 一文輕松圖解搞懂Elasticsearch原理!
一文輕松圖解搞懂Elasticsearch原理!
- 認(rèn)識倒排索引
- 分布式架構(gòu)原理
- 寫入數(shù)據(jù)的工作原理
- 寫數(shù)據(jù)底層原理
- 讀取數(shù)據(jù)的工作原理
- 搜索工作原理
- 刪除/更新數(shù)據(jù)底層原理
ES 的集群模式和 kafka 很像,kafka 又和 redis 的集群模式很像。總之就是相互借鑒!
不管你用沒用過 ES,今天我們一起聊聊它。就當(dāng)擴(kuò)展大家的知識廣度了!
認(rèn)識倒排索引
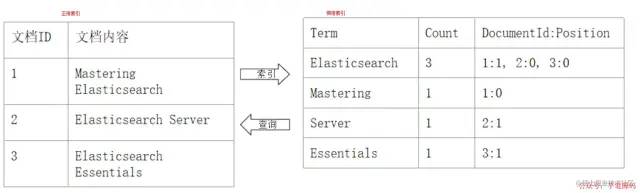
「正排索引 VS 倒排索引:」
 正排索引 VS 倒排索引
正排索引 VS 倒排索引「倒排索引包括兩個部分:」
-
單詞詞典(
Term Dictionary):記錄所有文檔的單詞,記錄單詞到倒排列表的關(guān)聯(lián)關(guān)系?
單詞詞典一般比較大,可以通過
B+樹 或 哈希拉鏈法實(shí)現(xiàn),以滿足高性能的插入與查詢?
-
倒排列表(
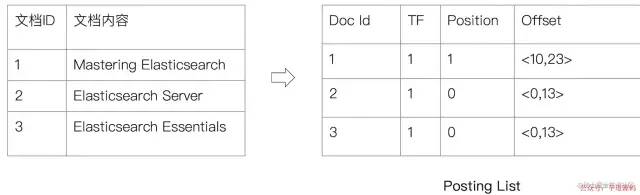
Posting List):記錄了單詞對應(yīng)的文檔結(jié)合,由倒排索引項(Posting)組成: -
-
文檔
ID
-
文檔
-
詞頻
TF:該單詞在文檔中出現(xiàn)的次數(shù),用于相關(guān)性評分 -
位置(
Position):單詞在文檔中分詞的位置。用于語句搜索(Phrase Query) -
偏移(
Offset):記錄單詞的開始結(jié)束位置,實(shí)現(xiàn)高亮顯示
 倒排索引
倒排索引
「ElasticSearch 的倒排索引:」
-
ElasticSearch的JSON文檔中的每個字段,都有自己的倒排索引
-
可以針對某些字段不做索引
- 優(yōu)點(diǎn):節(jié)省存儲空間
- 缺點(diǎn):字段無法被搜索
基于 Spring Boot + MyBatis Plus + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
分布式架構(gòu)原理
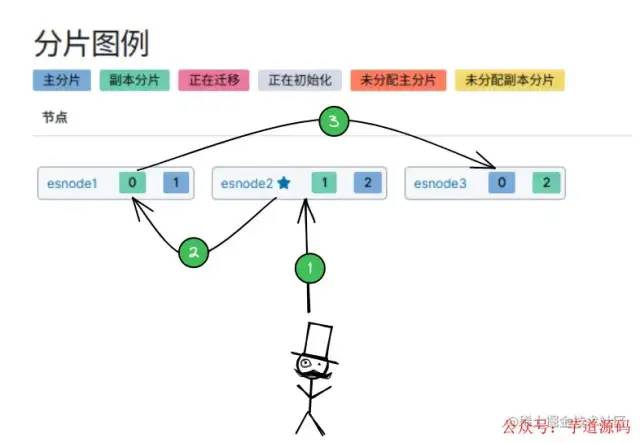
「分片 shard:一個索引可以拆分成多個 shard 分片。」
-
主分片
primary shard:每個分片都有一個主分片。 -
備份分片
replica shard:主分片寫入數(shù)據(jù)后,會將數(shù)據(jù)同步給其他備份分片。
將 ES 集群部署在 3個 機(jī)器上(esnode1、esnode2、esnode3):
「創(chuàng)建個索引,分片為 3 個,副本數(shù)設(shè)置為 1:」
PUT/sku_index/_settings
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}
響應(yīng):
{
"acknowledged":true
}
 分布式架構(gòu)原理
分布式架構(gòu)原理
「ES 集群中有多個節(jié)點(diǎn),會自動選舉一個節(jié)點(diǎn)為 master 節(jié)點(diǎn),如上圖的 esnode2節(jié)點(diǎn):」
-
主節(jié)點(diǎn)(
master):管理工作,維護(hù)索引元數(shù)據(jù)、負(fù)責(zé)切換主分片和備份分片身份等。 -
從節(jié)點(diǎn)(
node):數(shù)據(jù)存儲。
「集群中某節(jié)點(diǎn)宕機(jī):」
- 主節(jié)點(diǎn)宕機(jī):會重新選舉一個節(jié)點(diǎn)為 主節(jié)點(diǎn)。
- 從節(jié)點(diǎn)宕機(jī):由 主節(jié)點(diǎn),將宕機(jī)節(jié)點(diǎn)上的 主分片身份轉(zhuǎn)移到其他機(jī)器上的 備份分片上。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實(shí)現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
寫入數(shù)據(jù)的工作原理
「寫單個文檔所需的步驟:」
-
客戶端選擇一個
Node發(fā)送請求,那么這個Node就稱為 「協(xié)調(diào)節(jié)點(diǎn)(Coorinating Node)」 。 -
Node使用文檔ID來確定文檔屬于分片 0,通過集群狀態(tài)中的內(nèi)容路由表信息獲知分片0 的主分片在Node1上,因此將請求轉(zhuǎn)發(fā)到Node1上。 -
Node1上的主分片執(zhí)行寫操作。如果寫入成功,則將請求并行轉(zhuǎn)發(fā)到Node3的副分片上,等待返回結(jié)果。當(dāng)所有的副分片都報告成功,
Node1將向Node(協(xié)調(diào)節(jié)點(diǎn))報告成功。
 寫入數(shù)據(jù)的工作原理
寫入數(shù)據(jù)的工作原理
「Tips:客戶端收到成功響應(yīng)時,意味著寫操作已經(jīng)在主分片和所有副分片都執(zhí)行完成。」
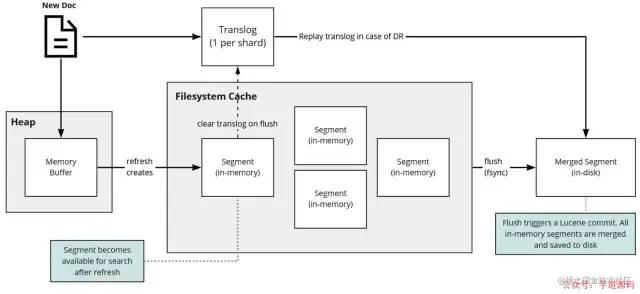
寫數(shù)據(jù)底層原理
寫數(shù)據(jù)底層原理「寫操作可分為 3 個主要操作:」
-
寫入新文檔: 這時候搜索,是搜索不到。
- 將數(shù)據(jù)寫入內(nèi)存
-
將這操作寫入
translog文件中
-
refresh操作: 默認(rèn)每隔 1s ,將內(nèi)存中的文檔寫入文件系統(tǒng)緩存(filesystem cache)構(gòu)成一個segment?
這時候搜索,可以搜索到數(shù)據(jù)。
?
-
「
1s時間:ES是近實(shí)時搜索,即數(shù)據(jù)寫入1s后可以搜索到。」
-
flush操作: 默認(rèn)每隔 30 分鐘 或者translog文件512MB,將文件系統(tǒng)緩存中的segment寫入磁盤,并將translog刪除。
「translog 文件:」 來記錄兩次 flush(fsync) 之間所有的操作,當(dāng)機(jī)器從故障中恢復(fù)或者重啟,可以根據(jù)此還原
-
translog是文件,存在于內(nèi)存中,如果掉電一樣會丟失。 - 「默認(rèn)每隔 5s 刷一次到磁盤中」
讀取數(shù)據(jù)的工作原理
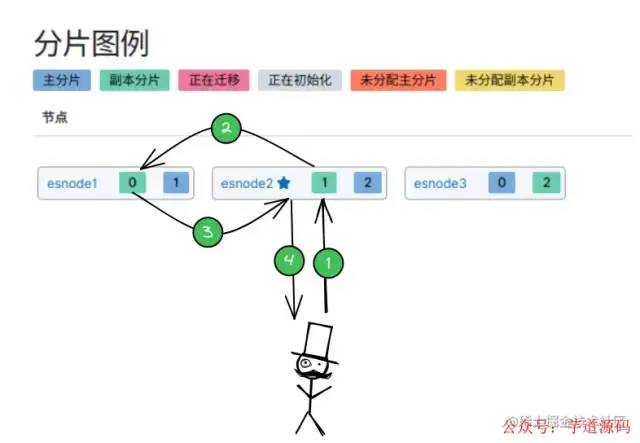
「讀取文檔所需的步驟:」
-
客戶端選擇一個
Node發(fā)送請求,那么這個Node就稱為 「協(xié)調(diào)節(jié)點(diǎn)(Coorinating Node)」 。 -
Node使用文檔ID來確定文檔屬于分片 0,通過集群狀態(tài)中的內(nèi)容路由表信息獲知分片0 有 2 個副本數(shù)據(jù)(一主一副),會使用隨機(jī)輪詢算法選擇出一個分片,這里將請求轉(zhuǎn)發(fā)到Node1 -
Node1將文檔返回給Node,Node將文檔返回給客戶端。
 讀取數(shù)據(jù)的工作原理
讀取數(shù)據(jù)的工作原理「在讀取時,文檔可能已經(jīng)存在于主分片上,但還沒有復(fù)制到副分片,這種情況下:」
- 讀請求命中副分片時,可能會報告文檔不存在。
- 讀請求命中主分片時,可能成功返回文檔。
搜索工作原理
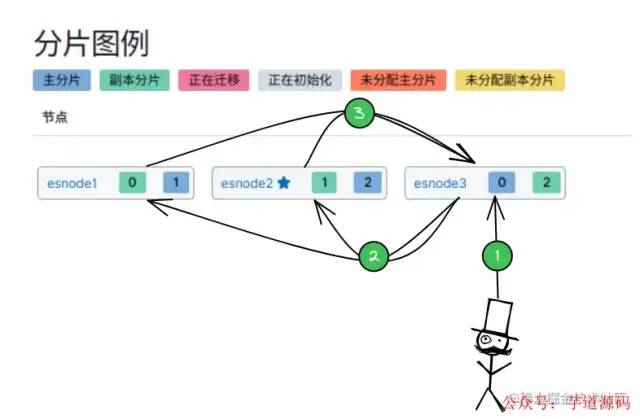
「搜索數(shù)據(jù)過程:」
-
客戶端選擇一個
Node發(fā)送請求,那么這個Node就稱為 「協(xié)調(diào)節(jié)點(diǎn)(Coorinating Node)」 。 -
Node協(xié)調(diào)節(jié)點(diǎn)將搜索請求轉(zhuǎn)發(fā)到所有的 分片(shard):主分片 或 副分片,都可以。 -
「
query階段」 :每個分片shard將自己的搜索結(jié)果(文檔ID)返回給協(xié)調(diào)節(jié)點(diǎn),由協(xié)調(diào)節(jié)點(diǎn)進(jìn)行數(shù)據(jù)的合并、排序、分頁等操作,產(chǎn)出最終結(jié)果。 -
「
fetch階段」 :由協(xié)調(diào)節(jié)點(diǎn)根據(jù) 文檔ID去各個節(jié)點(diǎn)上拉取實(shí)際的文檔數(shù)據(jù)。
 搜索工作原理
搜索工作原理舉個栗子: 有 3 個分片,查詢返回前 10 個匹配度最高的文檔
-
每個分片都查詢出當(dāng)前分片的
TOP 10數(shù)據(jù) -
「協(xié)調(diào)節(jié)點(diǎn)」 將
3 * 10 = 30的結(jié)果再次排序,返回最終TOP 10的結(jié)果。
刪除/更新數(shù)據(jù)底層原理
-
「刪除操作」 :
commit的時候會生成一個.del文件,里面將某個doc標(biāo)識為deleted狀態(tài),那么搜索的時候根據(jù).del文件就知道這個 doc 是否被刪除了。 -
「更新操作」 :就是將原來的
doc標(biāo)識為deleted狀態(tài),然后新寫入一條數(shù)據(jù)。
「底層邏輯是:」
-
Index Buffer每次refresh操作,就會產(chǎn)生一個segment file。(默認(rèn)情況:1秒1次) -
定制執(zhí)行
merge操作:將多個segment file合并成一個,同時將標(biāo)識為deleted的doc「物理刪除」 ,將新的segment file寫入磁盤,最后打上commit point標(biāo)識所有新的segment file。
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
6909瀏覽量
88850 -
spring
+關(guān)注
關(guān)注
0文章
338瀏覽量
14312
原文標(biāo)題:一文輕松圖解搞懂Elasticsearch原理!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Elasticsearch 再次開源

【書籍評測活動NO.50】親歷芯片產(chǎn)線,輕松圖解芯片制造,揭秘芯片工廠的秘密
一文搞懂Linux進(jìn)程的睡眠和喚醒
一文搞懂用ZPC輕松拿捏數(shù)據(jù)上云

統(tǒng)一日志數(shù)據(jù)流圖
PCB阻抗設(shè)計12問,輕松帶你搞懂阻抗!
一文搞懂DDR內(nèi)存原理
Rust編寫的首個Postgres基礎(chǔ)Elasticsearch開源替代品問世

文心一言APP上線數(shù)字分身功能
PCB阻抗設(shè)計12問,輕松帶你搞懂阻抗!
PCB阻抗設(shè)計12問,輕松帶你搞懂阻抗!
【華秋干貨鋪】PCB阻抗設(shè)計12問,輕松帶你搞懂阻抗

PCB阻抗設(shè)計12問,輕松帶你搞懂阻抗!

一文搞懂電器控制圖設(shè)計原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論