 谷歌提出FlexiViT:適用于所有Patch大小的模型
谷歌提出FlexiViT:適用于所有Patch大小的模型
太長不看版,果然還是延續谷歌的風格,創新不夠,實驗來湊。
廢話不多說,直接上圖,一圖勝千言:
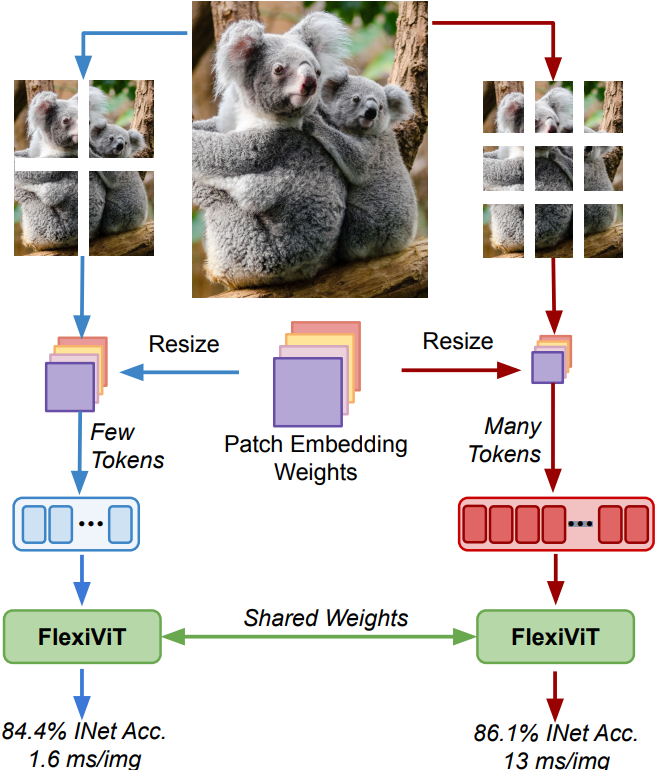
FlexiViT
顧名思義,FlexiViT,翻譯過來不就是靈活的 ViT 嘛?
Ooo,那怎么體現靈活?我們先回顧下 Vision Transformers 的工作流程。
一句話總結就是,ViT 是一種通過將圖像切割成一個個小方塊(patch)將圖像轉換為序列從而輸入到Transformer網絡進行訓練和推理的一種神經網絡架構。
本文的重點便是在研究這些小塊塊對性能的最終影響。通常來說:
方塊切的越小,精度會越高,但速度就變慢了;
方塊切的越大,精度會降低,但速度就上來了;
So,我們究竟是要做大做強,還是做小做精致?不用急,來自谷歌大腦的研究人員為你揭曉答案:成年人才做選擇,老子大小通吃。
正經點,讓我們切回來,古哥通過燃燒了數不盡的卡路里向我們證明了,在訓練期間隨機改變方塊的大小可以得到一組在廣泛的方塊大小范圍內表現良好的權重(泛化性能好)。
這結論有什么用?那便是使得在部署時大家可以根據不同的計算預算來調整模型。
通過在以下五大版圖進行廣泛的投資,可以清晰的發現收益率遠超滬深300:
圖像分類
圖像-文本檢索
開放世界檢測
全景分割
語義分割
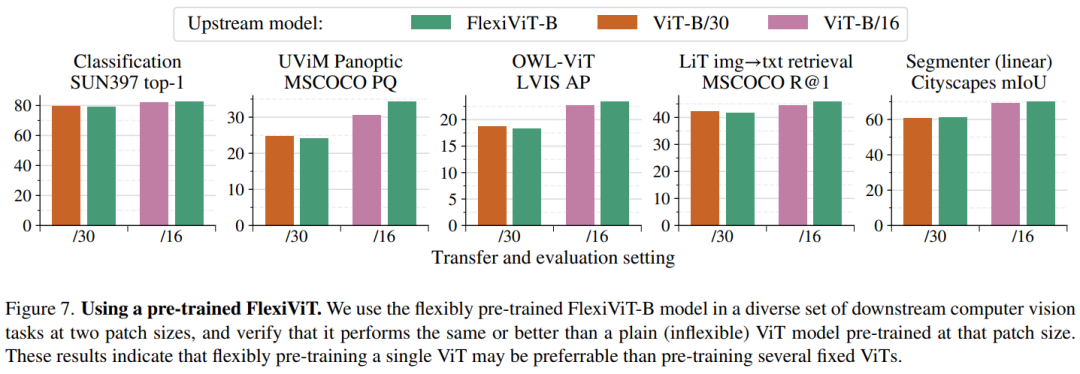
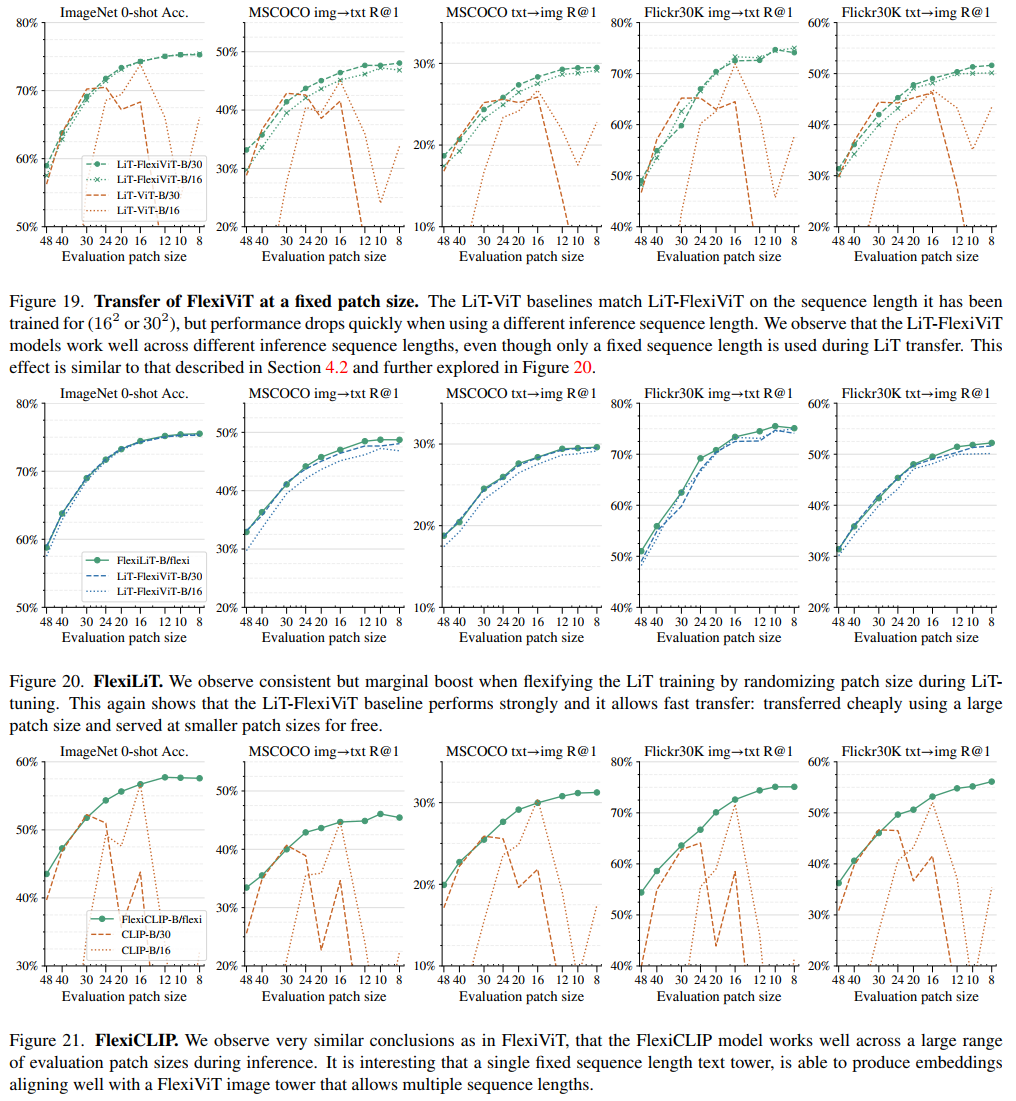
為了照顧下你們這些散(韭)戶(菜),古哥說你們可以將它任意添加到大多數依賴ViT骨干架構的模型來實現計算自由,即模型可以根據不同的計算資源調整自己的工作方式,從而獲得更好的性能和效率。
說了這么多,怎么做?直接把代號都發給你了,明天早盤直接梭哈即可:

看到看到這里了,總不能白嫖吧?點個贊友情轉發下再走咯~~~
審核編輯 :李倩
-
谷歌
+關注
關注
27文章
6142瀏覽量
105113 -
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
模型
+關注
關注
1文章
3178瀏覽量
48725
原文標題:谷歌提出FlexiViT:適用于所有Patch大小的模型
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出適用于網絡安全的NIM Blueprint
谷歌發布用于輔助編程的代碼大模型CodeGemma
微軟正式發布適用于Windows的Sudo
適用于所有尺寸TV的完全I2C可編程6通道LCD偏置IC TPS65177/A數據表

谷歌模型合成工具在哪下載安裝
谷歌模型框架是什么軟件?谷歌模型框架怎么用?
是否有適用于CYBT-343026-01的SPICE型號?






 工商網監
工商網監
評論