 NVIDIA Triton 系列文章(8):用戶端其他特性
NVIDIA Triton 系列文章(8):用戶端其他特性
前面文章用 Triton 開源項目提供的 image_client.py 用戶端作示范,在這個范例代碼里調用大部分 Triton 用戶端函數,并使用多種參數來配置執行的功能,本文內容就是簡單剖析 image_client.py 的代碼,為讀者提供撰寫 Triton 用戶端的流程。
指定通信協議
為了滿足大部分網路環境的用戶端請求,Triton 在服務器與用戶端之間提供 HTTP 與 gRPC 兩種通信協議,如下架構圖所示:
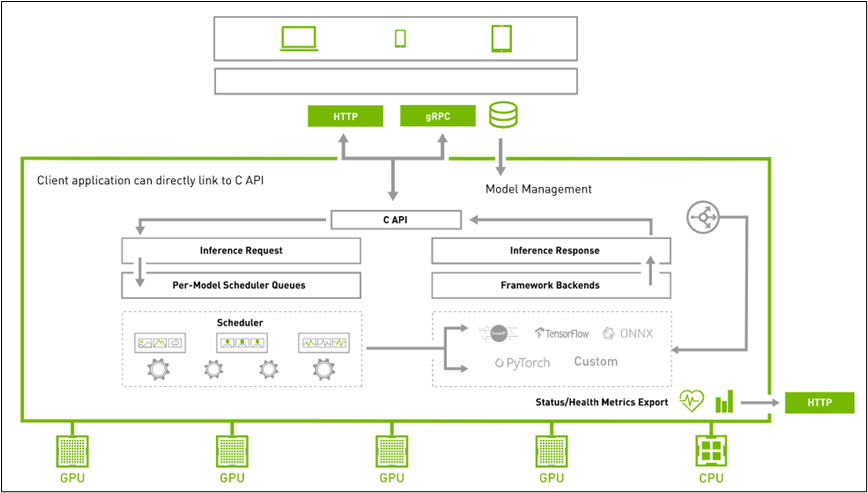
當我們啟動 Triton 服務器之后,最后狀態會停留在如下截屏的地方:

顯示的信息表示,系統提供 8001 端口給 gRPC 協議使用、提供 8000 端口給 HTTP 協議使用。此時服務器處于接收用戶端請求的狀態,因此“指定通信協議”是執行 Triton 用戶端的第一個工作。
這個范例支持兩種通信協議,一開始先導入tritonclient.http與tritonclient.grpc兩個模塊,如下:
import tritonclient.grpc as grpcclient
import tritonclient.http as httpclient代碼使用“-i”或“--protocal”其中一種參數指定“HTTP”或“gRPC”協議類型,如果不指定就使用“HTTP”預設值。再根據協議種類調用 httpcclient.InferenceServerClient() 或 grpcclient.InferenceServerClient() 函數創建 triton_client 對象,如下所示:
try:
if FLAGS.protocol.lower() == "grpc":
# Create gRPC client for communicating with the server
triton_client = grpcclient.InferenceServerClient(
url=FLAGS.url, verbose=FLAGS.verbose)
else:
# Specify large enough concurrency to handle the
# the number of requests.
concurrency = 20 if FLAGS.async_set else 1
triton_client = httpclient.InferenceServerClient(
url=FLAGS.url, verbose=FLAGS.verbose, concurrency=concurrency)最后啟用 triton_client.infer() 函數對 Triton 服務器發出推理要求,當然得將所需要的參數提供給這個函數,如下所示:
responses.append(
triton_client.infer(FLAGS.model_name,
inputs,
request_id=str(sent_count),
model_version=FLAGS.model_version,
outputs=outputs))不過 image_client.py 代碼中并未設定 gRPC 所需要的 8001 端口,因此使用這個通訊協議時,需要用“-u”參數設定“IP:端口”,例如下面指令:
$ python3 image_client.py -m inception_graphdef -s INCEPTION VGG ${HOME}/images/mug.jpg -i GRPC -u <服務器IP>:8001在 examples 范例目錄下還有20 個基于 gRPC 協議的范例以及 10 個基于 HTTP 協議的范例,則是在代碼內直接指定個別通信協議與端口號的范例,讀者可以根據需求去修改特定的范例代碼。
調用異步模式(async mode)與數據流(streaming)
大部分讀者比較熟悉的并行計算模式,就是在同一個時鐘脈沖(clock puls)讓不同計算核執行相同的工作,也就是所謂的 SIMD(單指令多數據)并行計算,通常適用于數據量大而且持續的密集型計算任務。
對 Triton 推理服務器而言,并不能確認所收到的推理要求是否為密集型的計算。事實上很大比例的推理要求是屬于零碎型計算,這種狀況下調用“異步模式”會讓系統更加有效率,因為它允許不同計算核(線程)在同一個時鐘脈沖段里執行不同指令,這樣能大大提高執行彈性進而優化計算性能。
當 Triton 服務器端啟動之后,就能接收來自用戶端的“異步模式”請求,不過在 HTTP 協議與 gRPC 協議的處理方式不太一樣。
在代碼中用 httpclient.InferenceServerClient() 函數創建 HTTP 的 triton_client 對象時,需要給定“concurrnecy(并發數量)”參數,而創建 gRPC 的用戶端時就不需要這個參數。
調用異步模式有時會需要搭配數據流(stream)的處理器(handle),因此在實際推理的函數就有 triton_client.async_infer() 與 triton_client.async_stream_infer() 兩種,使用 gRPC 協議創建的 triton_client,在調用無 stream 模式的 async_infer() 函數進行推理時,需要提供 partial(completion_callback, user_data) 參數。
由于異步處理與數據流處理有比較多底層線程管理的細節,初學者只需要范例目錄下的代碼,包括 image_client.py 與兩個 simple_xxxx_async_infer_client.py 的代碼就可以,細節部分還是等未來更熟悉系統之后再進行深入。
使用共享內存(share memory)
如果發起推理請求的 Triton 用戶端與 Triton 服務器在同一臺機器時,就可以使用共享內存的功能,這包含一般系統內存與 CUDA 顯存兩種,這項功能可以非常高效地降低數據傳輸的開銷,對提升推理性能有明顯的效果。
在 image_client.py 范例中并未提供這項功能,在 Python 范例下有 6 個帶有“shm”文件名的代碼,就是支持共享內存調用的范例,其中 simple_http_shm_client.py 與 simple_grpc_shm_client.py 為不同通信協議提供了使用共享系統內存的代碼,下面以 simple_grpc_shm_client.py 內容為例,簡單說明一下主要執行步驟:
# 1.為兩個輸入張量創建數據:第1個初始化為一整數、第2個初始化為所有整數
input0_data = np.arange(start=0, stop=16, dtype=np.int32)
input1_data = np.ones(shape=16, dtype=np.int32)
input_byte_size = input0_data.size * input0_data.itemsize
output_byte_size = input_byte_size
# 2. 為輸出創建共享內存區域,并存儲共享內存管理器
shm_op_handle = shm.create_shared_memory_region("output_data",
"/output_simple",
output_byte_size * 2)
# 3.使用Triton Server注冊輸出的共享內存區域
triton_client.register_system_shared_memory("output_data", "/output_simple",
output_byte_size * 2)
# 4. 將輸入數據值放入共享內存
shm_ip_handle = shm.create_shared_memory_region("input_data",
"/input_simple",
input_byte_size * 2)
# 5. 將輸入數據值放入共享內存
shm.set_shared_memory_region(shm_ip_handle, [input0_data])
shm.set_shared_memory_region(shm_ip_handle, [input1_data],
offset=input_byte_size)
# 6. 使用Triton Server注冊輸入的共享內存區域
triton_client.register_system_shared_memory("input_data", "/input_simple",
input_byte_size * 2)
# 7. 設置參數以使用共享內存中的數據
inputs = []
inputs.append(grpcclient.InferInput('INPUT0', [1, 16], "INT32"))
inputs[-1].set_shared_memory("input_data", input_byte_size)
inputs.append(grpcclient.InferInput('INPUT1', [1, 16], "INT32"))
inputs[-1].set_shared_memory("input_data",
input_byte_size,
offset=input_byte_size)
outputs = []
outputs.append(grpcclient.InferRequestedOutput('OUTPUT0'))
outputs[-1].set_shared_memory("output_data", output_byte_size)
outputs.append(grpcclient.InferRequestedOutput('OUTPUT1'))
outputs[-1].set_shared_memory("output_data",
output_byte_size,
offset=output_byte_size)
results = triton_client.infer(model_name=model_name,
inputs=inputs,
outputs=outputs)
# 8. 從共享內存讀取結果
output0=results.get_output("OUTPUT0")至于范例中有兩個 simple_xxxx_cudashm_client.py 這是針對 CUDA 顯存共享的返利代碼,主要邏輯與上面的代碼相似,主要將上面“shm.”開頭的函數改成“cudashm.”開頭的函數,當然處理流程也更加復雜一些,需要有足夠 CUDA 編程基礎才有能力駕馭,因此初學者只要大致了解流程就行。
以上就是 Triton 用戶端會用到的基本功能,不過缺乏足夠的說明文件,因此其他功能函數的內容必須自行在開源文件內尋找,像 C++ 版本的功能得在 src/c++/library 目錄下的 common.h、grpc_client.h 與 http_client.h 里找到細節,Python 版本的函數分別在 src/python/library/triton_client 下的 grpc、http、utils 下的 __init__.py 代碼內,獲取功能與函數定義的細節。
推薦閱讀
NVIDIA Jetson Nano 2GB 系列文章(1):開箱介紹

NVIDIA Jetson Nano 2GB 系列文章(2):安裝系統
NVIDIA Jetson Nano 2GB 系列文章(3):網絡設置及添加 SWAPFile 虛擬內存
NVIDIA Jetson Nano 2GB 系列文章(4):體驗并行計算性能
NVIDIA Jetson Nano 2GB 系列文章(5):體驗視覺功能庫
NVIDIA Jetson Nano 2GB 系列文章(6):安裝與調用攝像頭
NVIDIA Jetson Nano 2GB 系列文章(8):執行常見機器視覺應用
NVIDIA Jetson Nano 2GB 系列文章(9):調節 CSI 圖像質量
NVIDIA Jetson Nano 2GB 系列文章(10):顏色空間動態調節技巧
NVIDIA Jetson Nano 2GB 系列文章(11):你應該了解的 OpenCV
NVIDIA Jetson Nano 2GB 系列文章(12):人臉定位
NVIDIA Jetson Nano 2GB 系列文章(13):身份識別
NVIDIA Jetson Nano 2GB 系列文章(14):Hello AI World
NVIDIA Jetson Nano 2GB 系列文章(15):Hello AI World 環境安裝
NVIDIA Jetson Nano 2GB 系列文章(16):10行代碼威力
NVIDIA Jetson Nano 2GB 系列文章(17):更換模型得到不同效果
NVIDIA Jetson Nano 2GB 系列文章(18):Utils 的 videoSource 工具
NVIDIA Jetson Nano 2GB 系列文章(19):Utils 的 videoOutput 工具
NVIDIA Jetson Nano 2GB 系列文章(20):“Hello AI World” 擴充參數解析功能
NVIDIA Jetson Nano 2GB 系列文章(21):身份識別

NVIDIA Jetson Nano 2GB 系列文章(22):“Hello AI World” 圖像分類代碼
NVIDIA Jetson Nano 2GB 系列文章(23):“Hello AI World 的物件識別應用
NVIDIAJetson Nano 2GB 系列文章(24): “Hello AI World” 的物件識別應用
NVIDIAJetson Nano 2GB 系列文章(25): “Hello AI World” 圖像分類的模型訓練
NVIDIAJetson Nano 2GB 系列文章(26): “Hello AI World” 物件檢測的模型訓練
NVIDIAJetson Nano 2GB 系列文章(27): DeepStream 簡介與啟用
NVIDIAJetson Nano 2GB 系列文章(28): DeepStream 初體驗
NVIDIAJetson Nano 2GB 系列文章(29): DeepStream 目標追蹤功能
NVIDIAJetson Nano 2GB 系列文章(30): DeepStream 攝像頭“實時性能”
NVIDIAJetson Nano 2GB 系列文章(31): DeepStream 多模型組合檢測-1
NVIDIAJetson Nano 2GB 系列文章(32): 架構說明與deepstream-test范例
NVIDIAJetsonNano 2GB 系列文章(33): DeepStream 車牌識別與私密信息遮蓋
NVIDIA Jetson Nano 2GB 系列文章(34): DeepStream 安裝Python開發環境
NVIDIAJetson Nano 2GB 系列文章(35): Python版test1實戰說明
NVIDIAJetson Nano 2GB 系列文章(36): 加入USB輸入與RTSP輸出
NVIDIAJetson Nano 2GB 系列文章(37): 多網路模型合成功能
NVIDIAJetson Nano 2GB 系列文章(38): nvdsanalytics視頻分析插件
NVIDIAJetson Nano 2GB 系列文章(39): 結合IoT信息傳輸
NVIDIAJetson Nano 2GB 系列文章(40): Jetbot系統介紹
NVIDIAJetson Nano 2GB 系列文章(41): 軟件環境安裝
NVIDIAJetson Nano 2GB 系列文章(42): 無線WIFI的安裝與調試
NVIDIAJetson Nano 2GB 系列文章(43): CSI攝像頭安裝與測試
NVIDIAJetson Nano 2GB 系列文章(44): Jetson的40針引腳
NVIDIAJetson Nano 2GB 系列文章(46): 機電控制設備的安裝
NVIDIAJetson Nano 2GB 系列文章(47): 組裝過程的注意細節
NVIDIAJetson Nano 2GB 系列文章(48): 用鍵盤與搖桿控制行動
NVIDIAJetson Nano 2GB 系列文章(49): 智能避撞之現場演示
NVIDIAJetson Nano 2GB 系列文章(50): 智能避障之模型訓練
NVIDIAJetson Nano 2GB 系列文章(51): 圖像分類法實現找路功能
NVIDIAJetson Nano 2GB 系列文章(52): 圖像分類法實現找路功能
NVIDIAJetson Nano 2GB 系列文章(53): 簡化模型訓練流程的TAO工具套件
NVIDIA Jetson Nano 2GB 系列文章(54):NGC的內容簡介與注冊密鑰
NVIDIA Jetson Nano 2GB 系列文章(55):安裝TAO模型訓練工具
NVIDIA Jetson Nano 2GB 系列文章(56):啟動器CLI指令集與配置文件
NVIDIA Jetson Nano 2GB 系列文章(57):視覺類腳本的環境配置與映射
NVIDIA Jetson Nano 2GB 系列文章(58):視覺類的數據格式
NVIDIA Jetson Nano 2GB 系列文章(59):視覺類的數據增強
NVIDIA Jetson Nano 2GB 系列文章(60):圖像分類的模型訓練與修剪
NVIDIA Jetson Nano 2GB 系列文章(61):物件檢測的模型訓練與優化
NVIDIA Jetson Nano 2GB 系列文章(62):物件檢測的模型訓練與優化-2
NVIDIA Jetson Nano 2GB 系列文章(63):物件檢測的模型訓練與優化-3
NVIDIA Jetson Nano 2GB 系列文章(64):將模型部署到Jetson設備
NVIDIA Jetson Nano 2GB 系列文章(65):執行部署的 TensorRT 加速引擎
NVIDIA Jetson 系列文章(1):硬件開箱

NVIDIA Jetson 系列文章(2):配置操作系統
NVIDIA Jetson 系列文章(3):安裝開發環境
NVIDIA Jetson 系列文章(4):安裝DeepStream
NVIDIA Jetson 系列文章(5):使用Docker容器的入門技巧
NVIDIA Jetson 系列文章(6):使用容器版DeepStream
NVIDIA Jetson 系列文章(7):配置DS容器Python開發環境
NVIDIA Jetson 系列文章(8):用DS容器執行Python范例
NVIDIA Jetson 系列文章(9):為容器接入USB攝像頭
NVIDIA Jetson 系列文章(10):從頭創建Jetson的容器(1)
NVIDIA Jetson 系列文章(11):從頭創建Jetson的容器(2)
NVIDIA Jetson 系列文章(12):創建各種YOLO-l4t容器
NVIDIA Triton系列文章(1):應用概論
NVIDIA Triton系列文章(2):功能與架構簡介
NVIDIA Triton系列文章(3):開發資源說明
NVIDIA Triton系列文章(4):創建模型倉
NVIDIA Triton 系列文章(5):安裝服務器軟件
NVIDIA Triton 系列文章(6):安裝用戶端軟件
NVIDIA Triton 系列文章(7):image_client 用戶端參數
原文標題:NVIDIA Triton 系列文章(8):用戶端其他特性
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3749瀏覽量
90863
原文標題:NVIDIA Triton 系列文章(8):用戶端其他特性
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA DOCA-OFED的主要特性

NVIDIA助力提供多樣、靈活的模型選擇
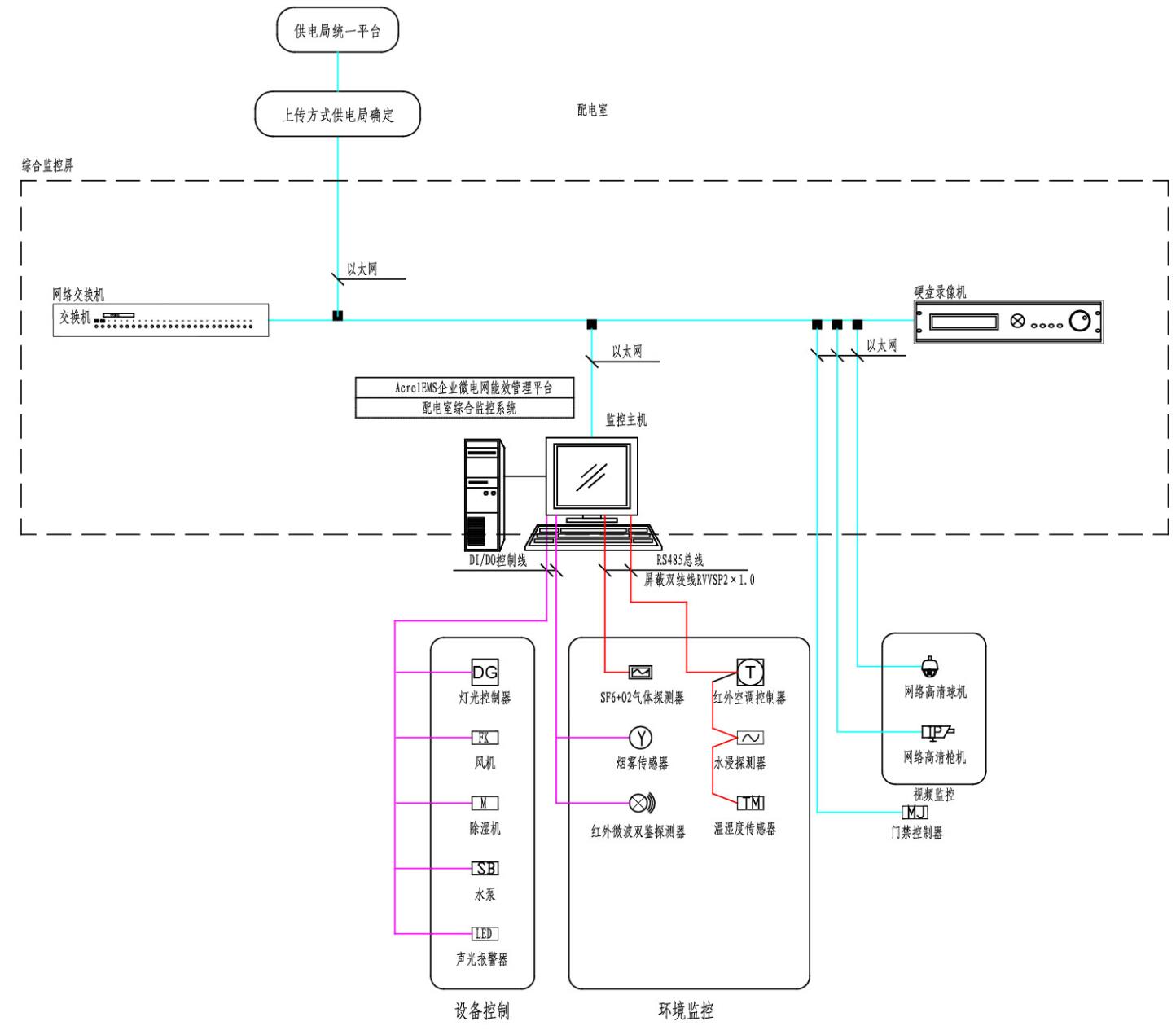
變電所、配電室、機房、箱變等用戶端供配電配電室綜合監測系統
牽手NVIDIA 元戎啟行端到端模型將搭載 DRIVE Thor芯片
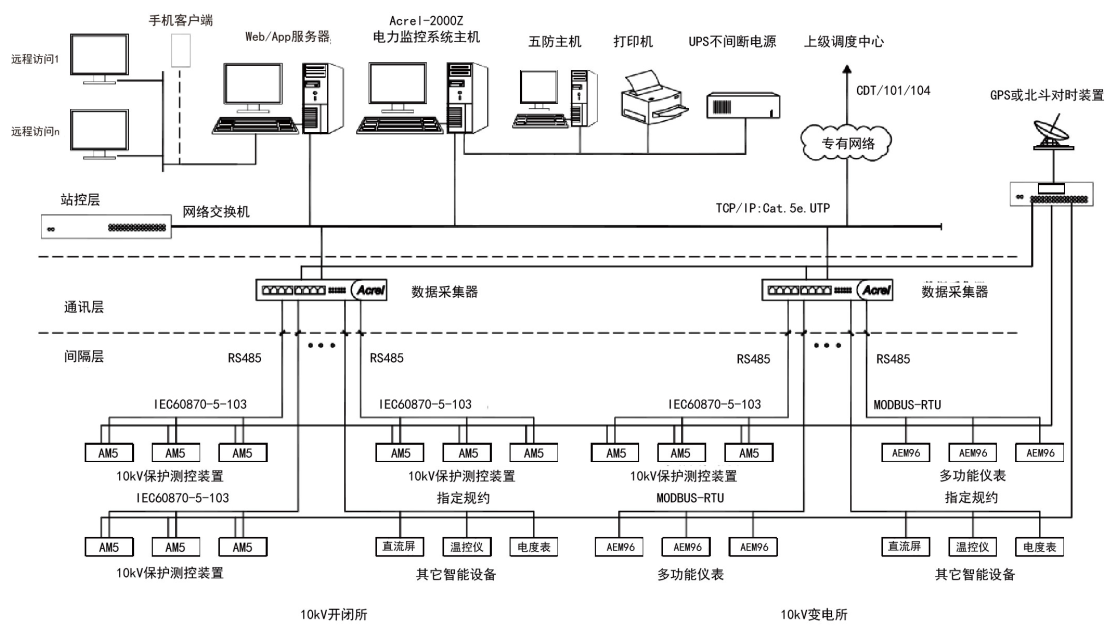
適用于35kV及以下新建或改擴建的用戶端Acrel-2000Z電力監控
使用NVIDIA Triton推理服務器來加速AI預測
在AMD GPU上如何安裝和配置triton?

一文淺談電能管理系統
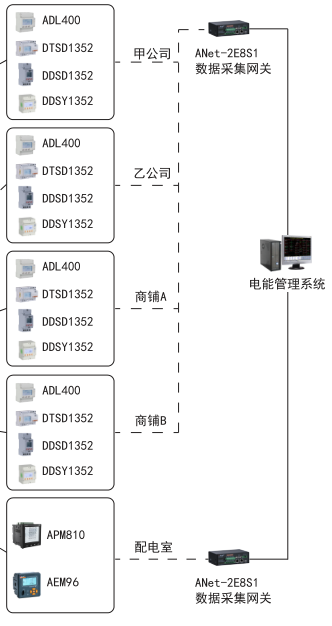
ACRELADL系列多功能電能表在迪拜大廈EMS中的應用
【BBuf的CUDA筆記】OpenAI Triton入門筆記一

利用NVIDIA產品技術組合提升用戶體驗
什么是Triton-shared?Triton-shared的安裝和使用
Triton編譯器的原理和性能






 工商網監
工商網監
評論