 世界杯融入詞庫的位置編碼方法介紹
世界杯融入詞庫的位置編碼方法介紹
本文的開頭還是從最近爆火的世界杯開始說起,以當下最火的“世界杯阿根廷戰勝墨西哥”來說。如果我們一個字符一個字符的獲取到embedding,勢必NER的效果會很差,但是如果我們能夠讓模型知道,世界杯、阿根廷、墨西哥分別是三個實體的名字,尤其是在位置編碼中“暗示”給模型,會有很好的效果。
上次的分享,主要集中在詞語的Embedding方式,這種方式在工業界非常的好用,簡單而且有效果。實際上對于算法工程師來說,處理好數據、特征,往往也是對自己能力的重大考驗。接下來我們分析一下子NER知識融合的另一種方式,在模型中嵌入知識的表達:
FLAT: Chinese NER Using Flat-Lattice Transformer | 復旦大學| ACL 2020
介紹
近年來,漢字“格”結構被證明是一種有效的中文命名實體識別方法,格子結構被證明對利用詞信息和避免分詞的錯誤傳播有很大的好處。那么接下來的問題是,什么是漢字格子?Lattice這個單詞正是格子的意思,NER任務嘗試引入這種類似“格子”的數據來增加NER詞匯的容量。
實際上在NER任務中,格是一個有向無環圖,其中每個節點都是一個字符或一個潛在的字,可以參考圖1a。格子包括句子中的一系列字符和可能的單詞。它們不是按順序排列的,單詞的第一個字符和最后一個字符決定了它的位置。漢字格中的一些詞可能對NER很重要。舉例來說,第一個格子就是“重慶”,也即是從“重”到“慶”。寫到這里,讀者可能會問,為什么不直接弄成格子呢?例如一個n*n的矩陣?可以是可以的,但是勢必會增加內存開銷,這點在GPU上的體現很明顯。
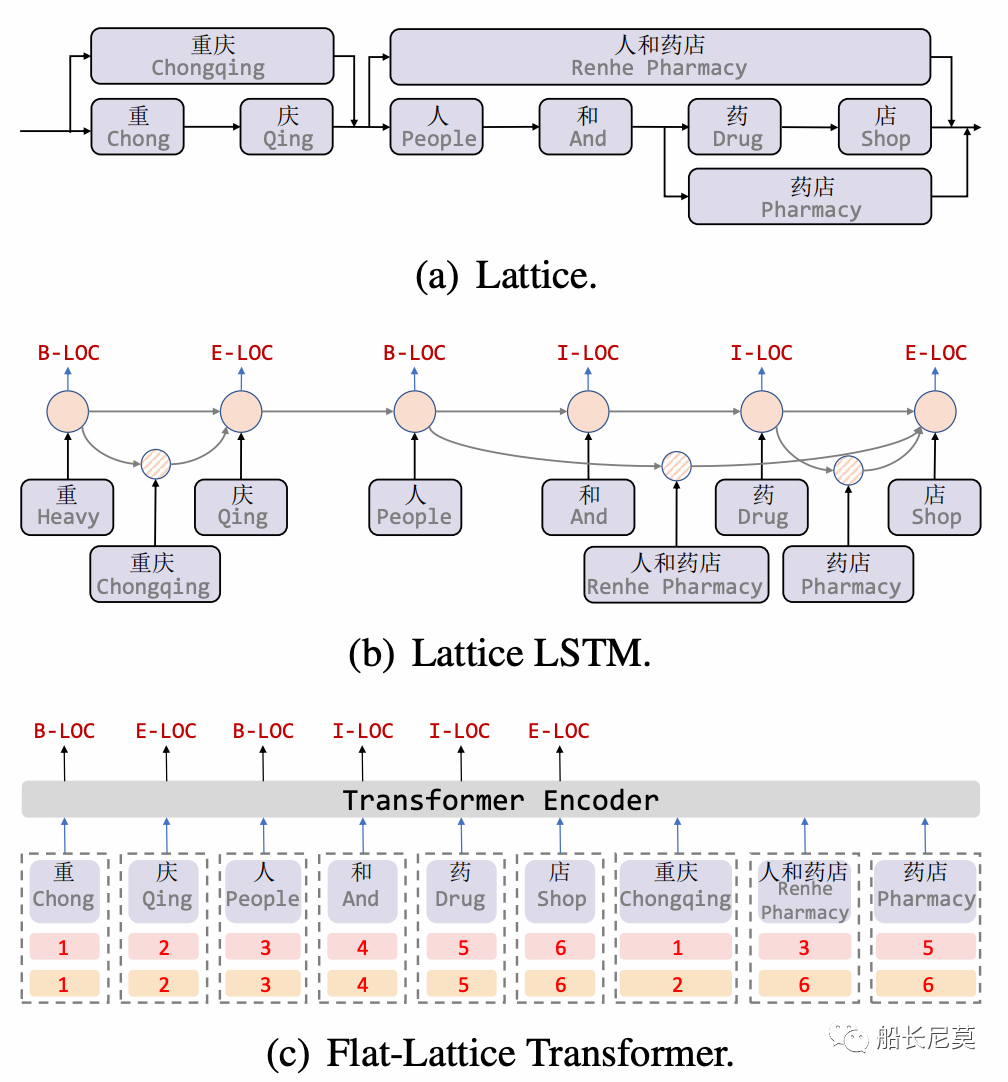
圖1:a 為格子的概念圖,b為模型Lattice LSTM的結構圖,c為本文的模型圖
之前的論文,為了適應格子結構,提出了Lattice LSTM,這種方式無疑會增加計算開銷,模型圖在圖1b。在本文中,我們提出了FLAT:用于中文的 Transformer。具體來講,本文只是將格子結構變成了頭部位置和尾部位置兩種索引的方式。如圖1c,可以看出有數字的地方,就代表了字符的位置,那么詞語“重慶”下面跟著的就是1,2,意思是從第一個字符,到第二個字符,是第一個詞語“重慶”。同理還有后面的詞語“人和藥店”,和“藥店”。
有意思的地方在于,本文也是引入了多種實體匹配的情況,“藥店”這個實體就匹配到了“人和藥店”和“藥店”,這點在工業界很實用,因為一句話中很可能包含了很多很多的詞語,充分的利用到這部分信息,是我們需要做的事情。
模型部分
總的來說,本文的貢獻都集中于位置編碼的部分,所以我們著重看下位置編碼。在圖2的模型架構圖中,我們看到位置編碼作為底層結構,輸入給Transformer,最終進行輸出。那么位置編碼是如何計算的呢?創新性又在哪里?我們繼續介紹。
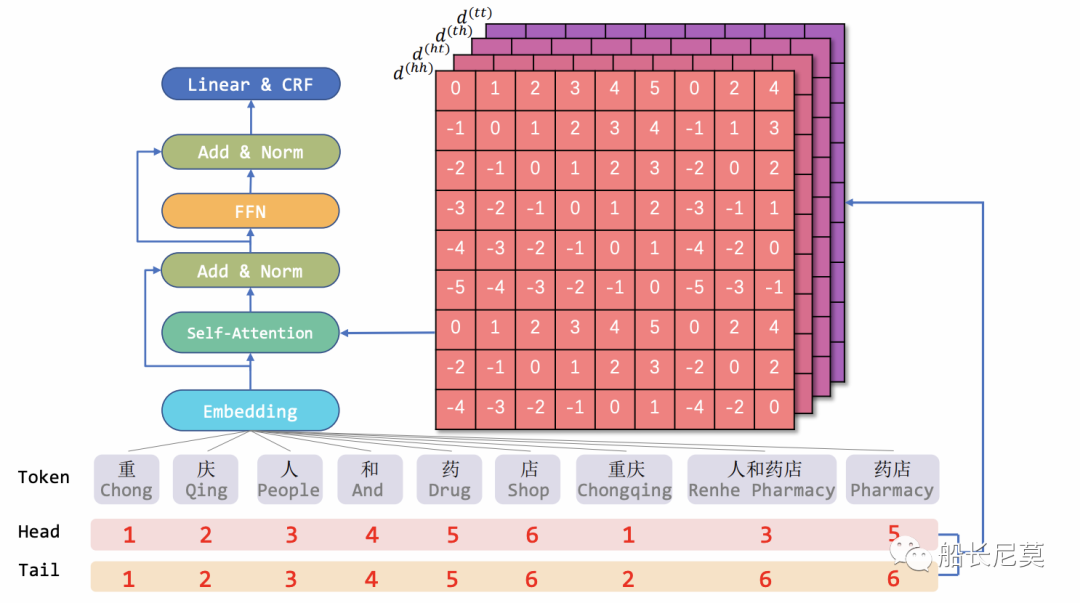
圖2:模型架構圖
將“格子”轉化為扁平的方式
我們只需要知道這串序列的頭和尾,就可以復原這個詞語,例如“重慶”是由“重”到“慶”組成的。這一步是不需要考慮梯度回傳的,為什么呢?因為這在數據處理層面,處理好之后才拿去給模型訓練的。
相對位置編碼
平面網格結構由不同長度的跨度組成。為了對區間之間的相互作用進行編碼,本文提出了區間的相對位置編碼。現在我們假設有兩條序列,分別是xi 和 xj,具體來說,是圖1中的“藥店”和“人和藥店”,這個例子,和明顯xi xj是相交的關系。可以參考圖2的模型圖。
對于格子中的兩個跨 xi 和 xj ,它們之間有三種關系:相交、包含和分離,由它們的首尾決定。接著就是來計算相對距離,那么相對距離有幾種呢?答案是四種,為什么會這樣?實際上是很簡單的排列組合,2*2=4,2代表了開頭或者結尾。使用 head[i] 和 tail[i] 表示跨度 xi 的頭和尾的位置。四種相對距離可以用來表示 xi 和 xj 之間的關系。它們可以被計算為:
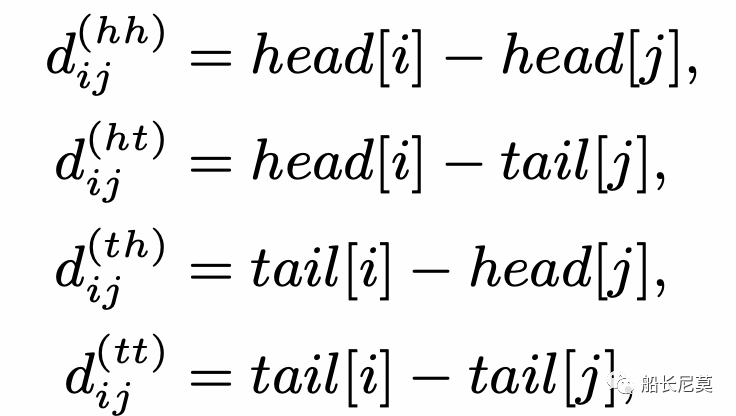
跨度的最終相對位置編碼是四個距離的一個簡單的非線性變換,見下面的公式。那么問題來了,為什么是四個距離一起計算,而不是只計算一個呢?是因為四個能夠完整的還原出原來的狀態,而一個不可以。舉例來說,如果只有d(hh),代表了從字符串xi的開頭,到字符串xj開頭的距離,只有這一段距離,是無法復現出原本的xi xj相對位置。
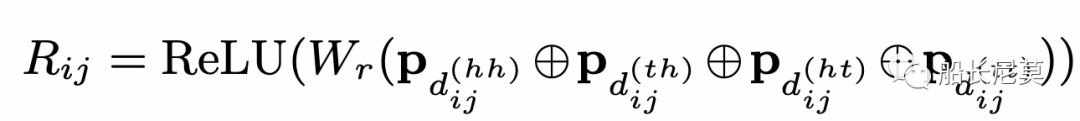
公式也是很好理解的,ReLU為激活函數,Wr是可學習的參數矩陣,四種距離,經過P運算之后疊加在一起作為輸入。那么P是什么運算呢?作者在這里沿用了Transformer原本的距離編碼。這個公式很神奇,因為很少有公式會把很大的數字,一萬放進去,P的運算在奇數位和偶數位的方式不同,2k代表偶數位,2k+1代表奇數位。在知乎上有很多對這種位置編碼的講解,感興趣的朋友可以自行瀏覽。
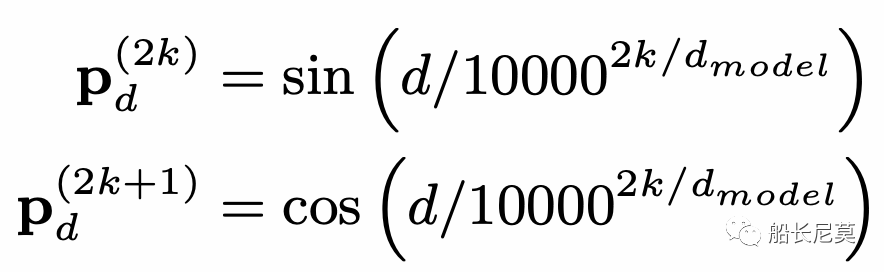
然后使用self-attention的一個變體來利用相對跨度位置編碼如下:

其中Rij是從上面的公式而來,E是取Embedding,而W都代表了線性變化的矩陣。緊接著就是用這個A*替換掉原本的A,在Transformer內部進行attention運算的時候,如下的公式所示。之后的步驟就是沿著Transformer的內部進行計算即可。整個模型架構我們介紹完畢了,本文的貢獻主要集中在位置編碼部分。
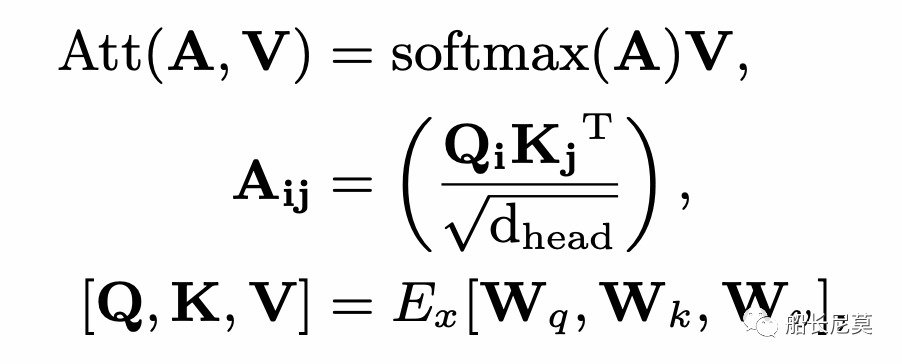
數據集介紹
數據集的詳細情況和之前船長對于NER的分享很類似,都是用了差不多的數據集。不進行過多介紹了。
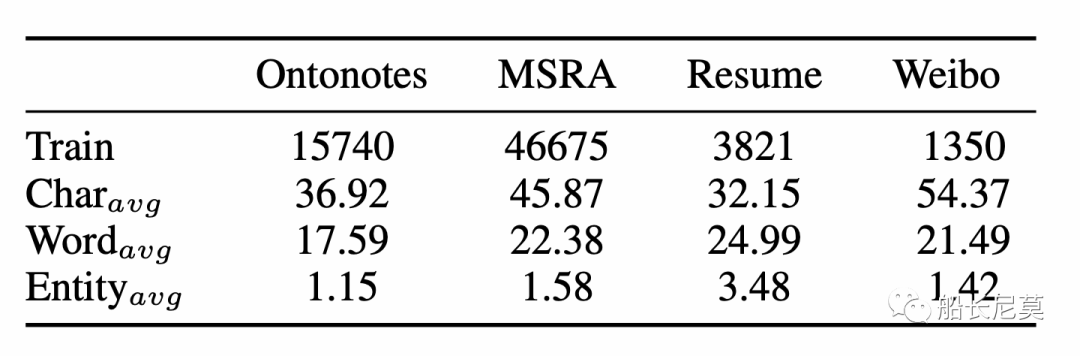
圖3:數據集介紹
結果
Flat的方式,相比于之前的方法,有著1~3個點的提升,不同的數據集提升效果不同。
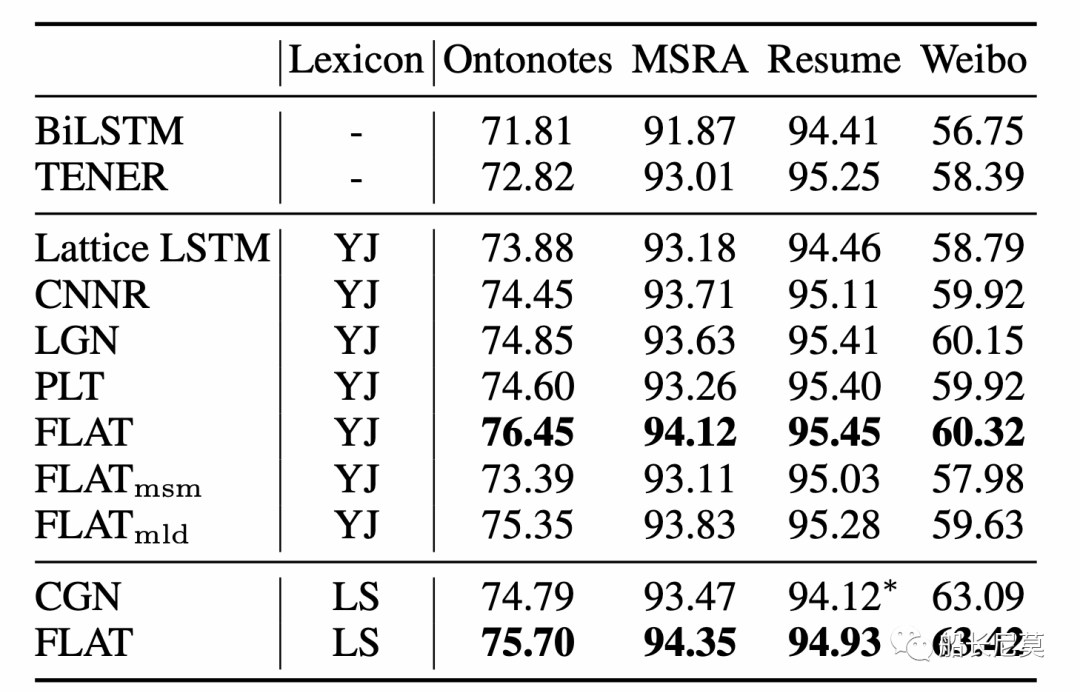
圖4:結果介紹
全連通結構的優點
與lattice LSTM相比,注意機制有兩個優點:
所有字符都可以直接與它的自匹配詞進行交互。
遠程依賴關系可以完全建模。這點根本上是緣由于Transformer的attention機制,注意力的機制能夠讓遠距離的文本不再變得遙遠。
FLAT的計算效率
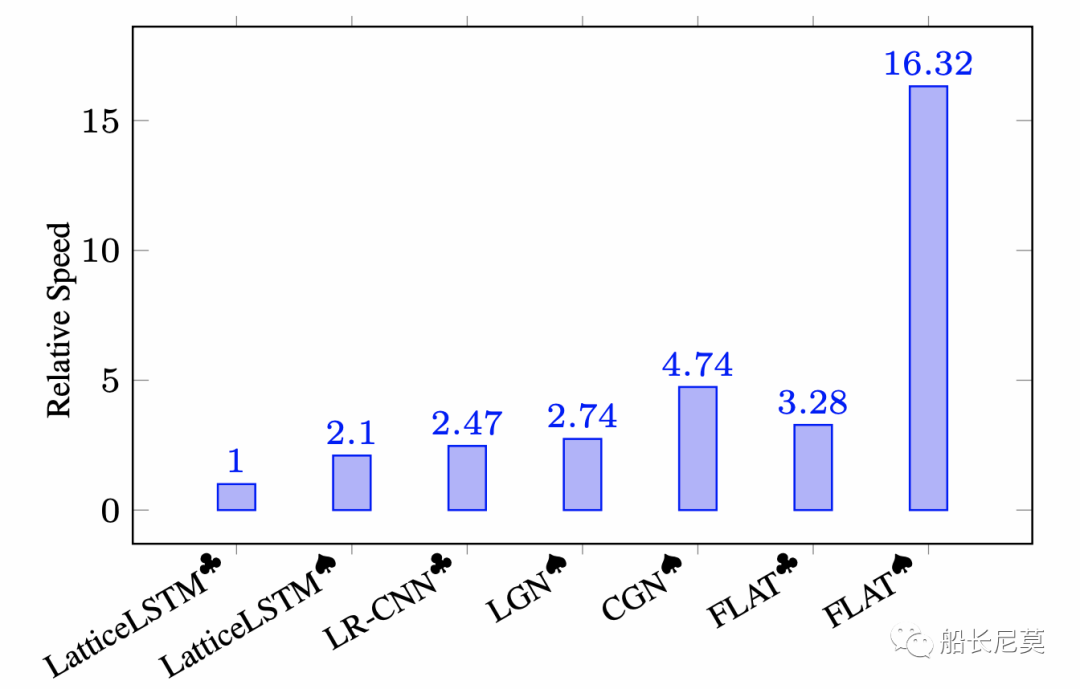
圖5:推理速度效果
不難看出,推理速度方面,FLAT完勝了之前的 LatticeLSTM方式,大概提升有8倍之多,其中黑桃、梅花代表實驗是否訓練以batch-parallel 的機制。
兼容BERT
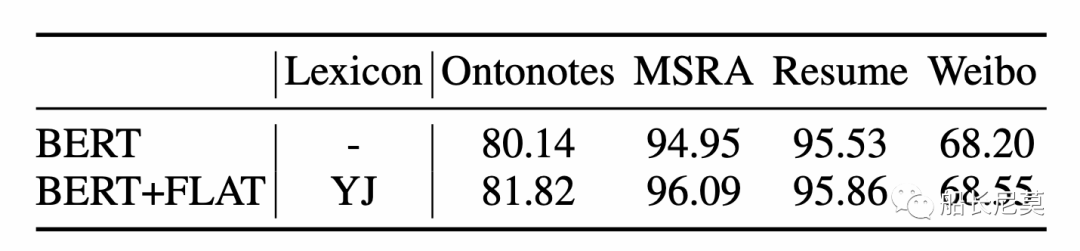
圖6:兼容了BERT之后的結果,BERT是指BERT+MLP+CRF架構,BERT+FLAT是指使用BERT嵌入的FLAT
將FLAT機制引入到BERT之后,提升相對很大,因為對預訓練模型的提升本身就很難。但是此處直接和BERT進行對比并不合適,因為BERT并沒有引入詞語的建模。但是能夠方便的嵌入到BERT中,無疑會更利用在工業界的利用。
寫在最后
本文介紹了一種FLAT的位置編碼方式,可以應用在Transformer模型上面,并且很容易結合BERT等預訓練模型。實驗結果很優秀,關鍵是推理速度很快,這點也讓方法很容易部署在線上,帶來很好的效果。
編輯:黃飛
-
NER
+關注
關注
0文章
7瀏覽量
6205 -
位置編碼器
+關注
關注
1文章
18瀏覽量
5551
原文標題:NER無法識別“世界杯”怎么辦?融入詞庫的位置編碼方法介紹
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論