") GMMSeg:生成式語義分割新范式!可同時處理閉集和開集識別
GMMSeg:生成式語義分割新范式!可同時處理閉集和開集識別
GMMSeg 同時具備判別式與生成式模型的優(yōu)勢,在語義分割領域,首次實現(xiàn)使用單一的模型實例,在閉集 (closed-set) 及開放世界 (open-world) 分割任務中同時取得先進性能。
當前主流語義分割算法本質上是基于 softmax 分類器的判別式分類模型,直接對 p (class|pixel feature) 進行建模,而完全忽略了潛在的像素數(shù)據(jù)分布,即 p (class|pixel feature)。這限制了模型的表達能力以及在 OOD (out-of-distribution) 數(shù)據(jù)上的泛化性。 在最近的一項研究中,來自浙江大學、悉尼科技大學、百度研究院的研究者們提出了一種全新的語義分割范式 —— 基于高斯混合模型(GMM)的生成式語義分割模型 GMMSeg。

GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models
論文鏈接:https://arxiv.org/abs/2210.02025
代碼鏈接:https://github.com/leonnnop/GMMSeg
GMMSeg 對像素與類別的聯(lián)合分布進行建模,通過 EM 算法在像素特征空間學習高斯混合分類器 (GMM Classifier),以生成式范式對每一個類別的像素特征分布進行精細捕捉。與此同時,GMMSeg 采用判別式損失來端到端的優(yōu)化深度特征提取器。這使得 GMMSeg 同時具備判別式與生成式模型的優(yōu)勢。 實驗結果表明,GMMSeg 在多種分割網(wǎng)絡架構 (segmentation architecture) 及骨干網(wǎng)絡 (backbone network) 上都獲得了性能提升;同時,無需任何后處理或微調,GMMSeg 可以直接被應用到異常分割 (anomaly segmentation) 任務。 迄今為止,這是第一次有語義分割方法能夠使用單一的模型實例,在閉集 (closed-set) 及開放世界 (open-world) 條件下同時取得先進性能。這也是生成式分類器第一次在大規(guī)模視覺任務中展示出優(yōu)勢。 判別式 v.s. 生成式分類器
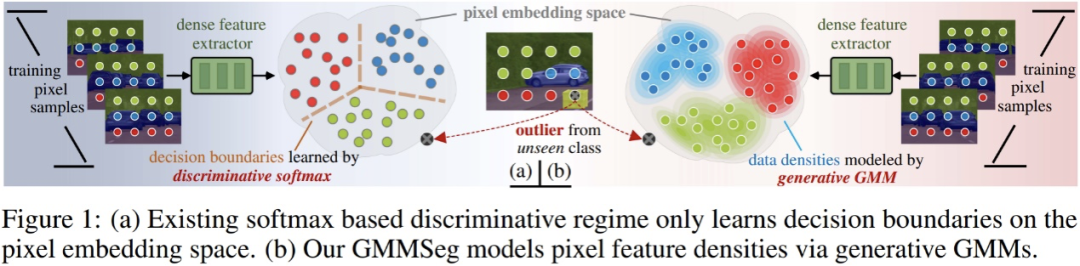
在深入探討現(xiàn)有分割范式以及所提方法之前,這里簡略引入判別式以及生成式分類器的概念。 假設有數(shù)據(jù)集合 D,其包含成對的樣本 - 標簽對 (x, y);分類器的最終目標是預測樣本分類概率 p (y|x)。分類方法可以被分為兩類:判別式分類器以及生成式分類器。
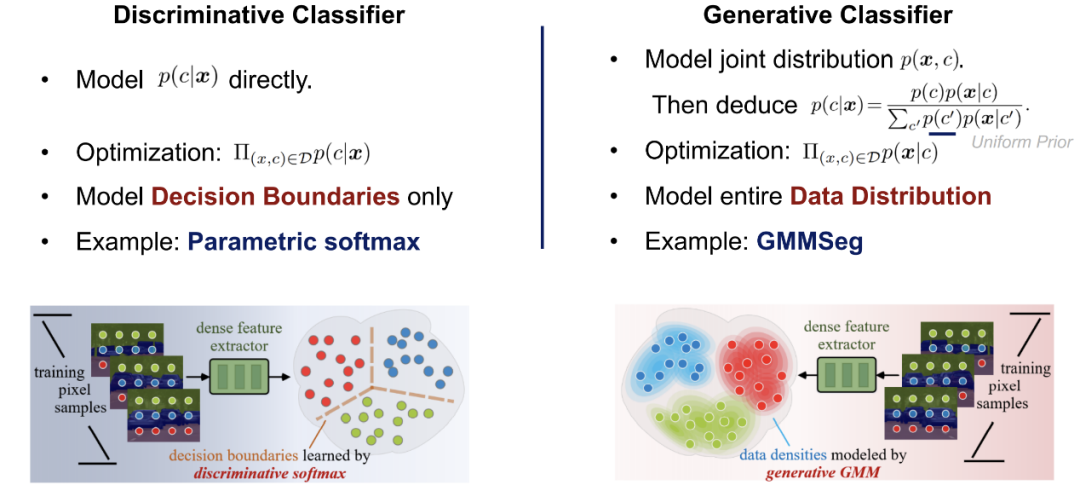
判別式分類器:直接建模條件概率 p (y|x);其僅僅學習分類的最優(yōu)決策邊界,而完全不考慮樣本本身的分布,也因此無法反映樣本的特性。
生成式分類器:首先建模聯(lián)合概率分布 p (x, y),而后通過貝葉斯定理推導出分類條件概率;其顯式地對數(shù)據(jù)本身的分布進行建模,往往針對每一個類別都會建立對應的模型。相比于判別式分類器,其充分考慮了樣本的特征信息。
主流語義分割范式:判別式 Softmax 分類器 目前主流的逐像素分割模型大多使用深度網(wǎng)絡抽取像素特征,而后使用 softmax 分類器進行像素特征分類。其網(wǎng)絡架構由兩部分組成: 第一部分為像素特征提取器,其典型架構為編碼器 - 解碼器對,通過將 RGB 空間的像素輸入映射到 D - 維度的高維空間獲取像素特征。 第二部分為像素分類器,即主流的 softmax 分類器;其將輸入的像素特征編碼為 C - 類實數(shù)輸出(logits),而后利用 softmax 函數(shù)對輸出(logits)歸一化并賦予概率意義,即利用 logits 計算像素分類的后驗概率:
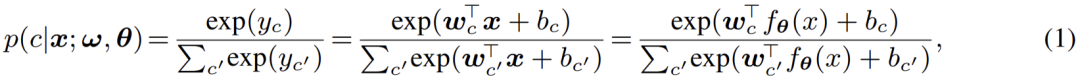
最終,由兩個部分構成的完整模型將通過 cross-entropy 損失進行端到端的優(yōu)化:
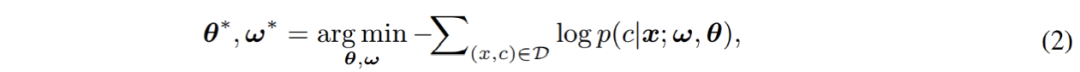
在此過程中,模型忽略了像素本身的分布,而直接對像素分類預測的條件概率 p (c|x) 進行估計。由此可見,主流的 softmax 分類器本質為判別式分類器。 判別式分類器結構簡單,并因其優(yōu)化目標直接針對于縮小判別誤差,往往能夠取得優(yōu)異的判別性能。然而與此同時,其有一些尚未引起已有工作重視的致命缺點,極大的影響了 softmax 分類器的分類性能及泛化性:
首先,其僅僅對決策邊界進行建模;完全忽視了像素特征的分布,也因而無法對每一個類別的具體特性進行建模與利用;削弱了其泛化性以及表達能力。
其次,其使用單一的參數(shù)對 (w,b) 建模一個類別;換言之,softmax 分類器依賴于單模分布 (unimodality) 假設;這種極強且過于簡化的假設在實際應用往往不能成立,這導致其只能夠取得次優(yōu)的性能。
最后,softmax 分類器的輸出無法準確反映真實的概率意義;其最終的預測只能作為與其他類別進行比較時的參考。這也正是大量主流分割模型較難檢測出 OOD 輸入的根本原因。
針對這些問題,作者認為應該對目前主流的判別式范式進行重新思考,并在本文中給出了對應的方案:生成式語義分割模型 ——GMMSeg。 生成式語義分割模型:GMMSeg 作者從生成式模型的角度重新梳理了語義分割過程。相較于直接建模分類概率 p (c|x),生成式分類器對聯(lián)合分布 p (x, c) 進行建模,而后使用貝葉斯定理推導出分類概率:
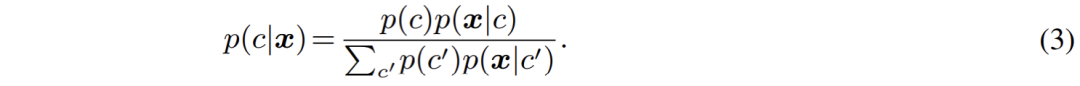
其中,出于泛化性考慮,類別先驗 p (c) 往往被設置為 uniform 分布,而如何對像素特征的類別條件分布 p (x|c) 進行建模,就成為了當前的首要問題。 在本文中,即 GMMSeg 中,采用高斯混合模型對 p (x|c) 進行建模,其形式如下:
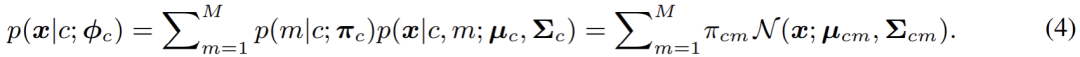
在分模型 (component) 數(shù)目不受限的情況下,高斯混合模型理論上能夠擬合任意的分布,因而十分優(yōu)雅且強大;同時,其混合模型的本質也使得建模多模分布 (multimodality),即建模類內變化,變得可行。基于此,本文采用極大似然估計來優(yōu)化模型的參數(shù):
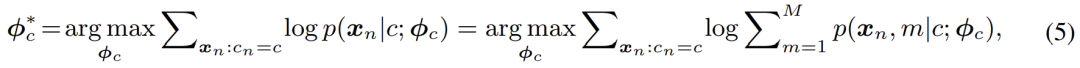
其經典的解法為 EM 算法,即通過交替執(zhí)行 E-M - 兩步逐步優(yōu)化 F - 函數(shù):
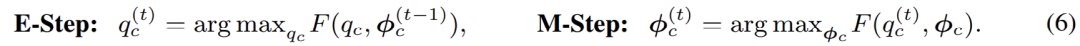
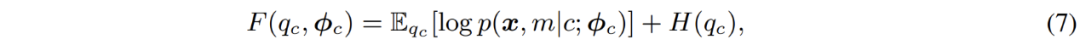
具體到高斯混合模型的優(yōu)化;EM 算法實際上在 E - 步中,對數(shù)據(jù)點屬于每一個分模型的概率進行了重新估計。換言之,其相當于在 E - 步中對像素點進行了軟聚類 (soft clustering);而后,在 M - 步,即可利用聚類結果,再次更新模型參數(shù)。
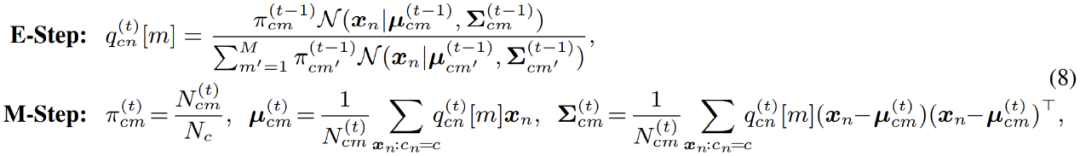
然而在實際應用中,作者發(fā)現(xiàn)標準的 EM 算法收斂緩慢,且最終結果較差。作者懷疑是由于 EM 算法對參數(shù)優(yōu)化初始值過于敏感,導致其難以收斂到更優(yōu)的局部極值點。受到近期一系列基于最優(yōu)傳輸理論 (optimal transport) 的聚類算法的啟發(fā),作者對混合分模型分布額外引入了一個 uniform 先驗:
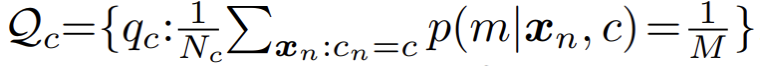
相應的,參數(shù)優(yōu)化過程中的 E - 步驟被轉化為約束優(yōu)化問題,如下:
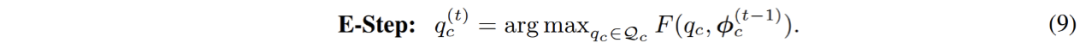
這個過程可以被直觀的理解成,對聚類過程引入了一個均分的約束:在聚類過程中,數(shù)據(jù)點能夠被一定程度上均勻的分配給每一個分模型。引入此約束之后,此優(yōu)化過程就等價于下式列出的最優(yōu)傳輸問題:
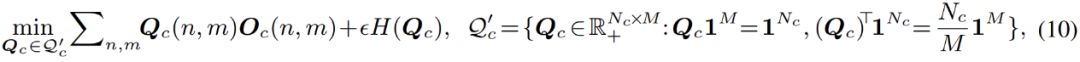
此式可以利用 Sinkhorn-Knopp 算法快速求解。而整個改進過后的優(yōu)化過程被命名為 Sinkhorn EM,其被一些理論工作證明,具有與標準 EM 算法相同的全局最優(yōu)解,且更不容易陷入局部最優(yōu)解。 在線混合 (Online Hybrid) 優(yōu)化 之后,在完整的優(yōu)化過程中,文章中使用了一種在線混合 (online hybrid) 的優(yōu)化模式:通過生成式 Sinkhorn EM,在逐漸更新的特征空間中,不斷對高斯混合分類器進行優(yōu)化;而對于完整框架中另一個部分,即像素特征提取器部分,則基于生成式分類器的預測結果,使用判別式 cross-entropy 損失進行優(yōu)化。兩個部分交替優(yōu)化,互相對齊,使得整個模型緊密耦合,并且能夠進行端到端的訓練:

在此過程中,特征提取部分只通過梯度反向傳播優(yōu)化;而生成式分類器部分,則只通過 SinkhornEM 進行優(yōu)化。正是這種交替式優(yōu)化的設計,使得整個模型能夠緊湊的融合在一起,并同時繼承來自判別式以及生成式模型的優(yōu)勢。 最終,GMMSeg 受益于其生成式分類的架構以及在線混合的訓練策略,展示出了判別式 softmax 分類器所不具有的優(yōu)勢:
其一,受益于其通用的架構,GMMSeg 與大部分主流分割模型兼容,即與使用 softmax 進行分類的模型兼容:只需要替換掉判別式 softmax 分類器,即可無痛增強現(xiàn)有模型的性能。
其二,由于 hybrid 訓練模式的應用,GMMSeg 兼并了生成式以及判別式分類器的優(yōu)點,且一定程度上解決了 softmax 無法建模類內變化的問題;使得其判別性能大大提升。
其三,GMMSeg 顯式建模了像素特征的分布,即 p (x|c);GMMSeg 能夠直接給出樣本屬于各個類別的概率,這使得其能夠自然的處理未曾見過的 OOD 數(shù)據(jù)。
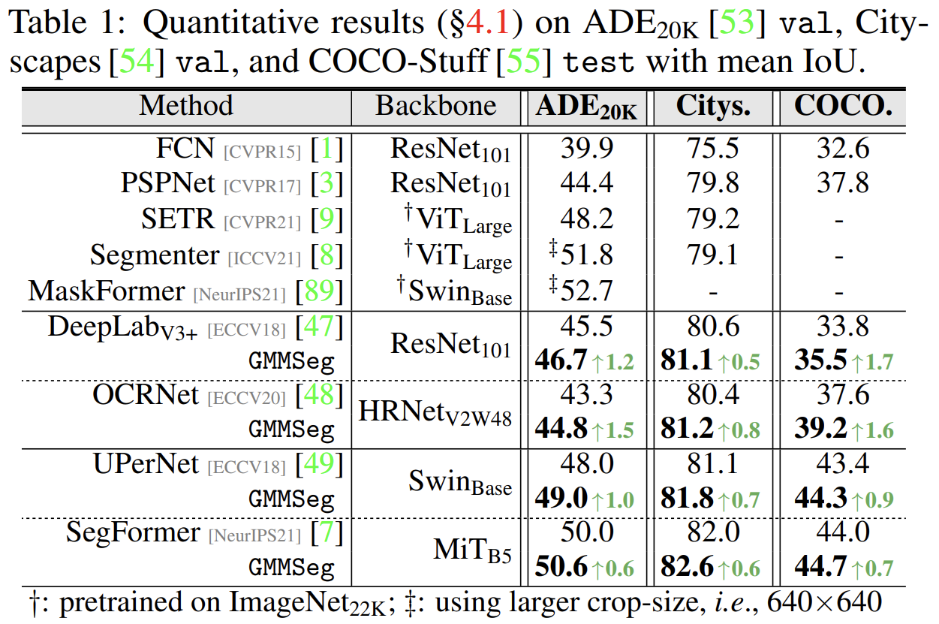
實驗結果 實驗結果表明,不論是基于 CNN 架構或者是基于 Transformer 架構,在廣泛使用的語義分割數(shù)據(jù)集 (ADE20K, Cityscapes, COCO-Stuff) 上,GMMSeg 都能夠取得穩(wěn)定且明顯的性能提升。

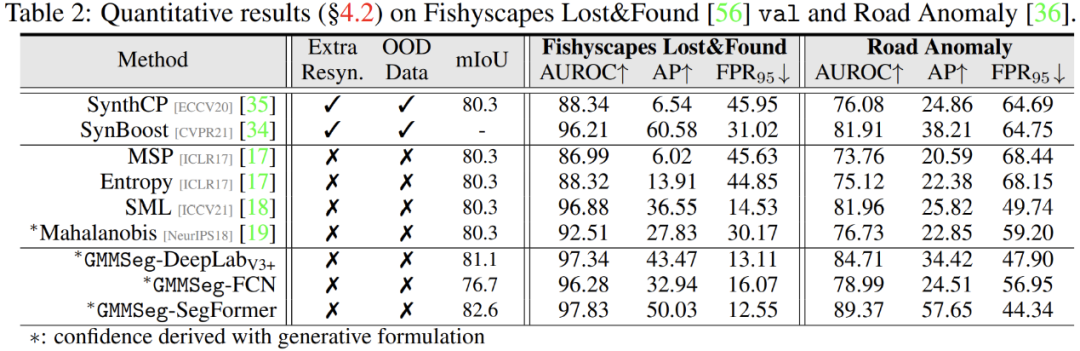
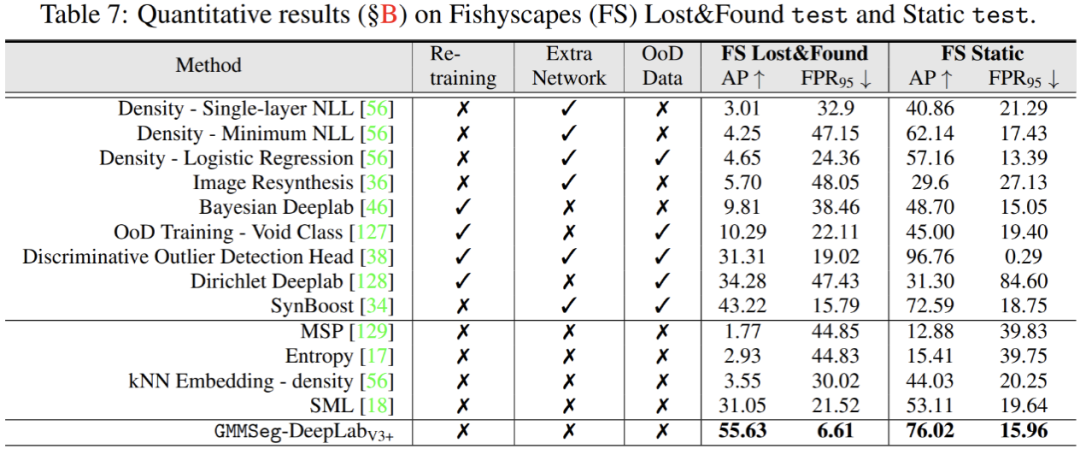
除此之外,在異常分割任務中,無需對在閉集任務,即常規(guī)語義分割任務中訓練完畢的模型做任何的修改,GMMSeg 即可在所有通用評價指標上,超越其他需要特殊后處理的方法。

審核編輯 :李倩
-
算法
+關注
關注
23文章
4601瀏覽量
92671 -
分類器
+關注
關注
0文章
152瀏覽量
13175
原文標題:NeurIPS 2022 | GMMSeg:生成式語義分割新范式!可同時處理閉集和開集識別
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
微處理器的指令集有哪些
RISC-V和arm指令集的對比分析
RISC-V指令集的特點總結
圖像語義分割的實用性是什么
圖像分割和語義分割的區(qū)別與聯(lián)系
圖像分割與語義分割中的CNN模型綜述
請問NanoEdge AI數(shù)據(jù)集該如何構建?
語音數(shù)據(jù)集:智能駕駛中車內語音識別技術的基石
Harvard FairSeg:第一個用于醫(yī)學分割的公平性數(shù)據(jù)集

自動駕駛數(shù)據(jù)集的生成模型之WoVoGen框架原理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論