 深度學習的長期發展仍在繼續
深度學習的長期發展仍在繼續
2016年,人工智能軟件包AlphaGo擊敗韓國圍棋大師李世石。圍棋是一種兩人抽象戰略棋盤游戲,其目標是用棋子包圍比對手更多的領土。2017年,經過改進的新版AlphaGo(AlphaGo Master)擊敗了世界圍棋第一人柯潔。這種新穎的人工智能 (AI) 系統并沒有依靠先前建立的策略來擊敗人類對手,而是在某些特定領域似乎超越了人類的認知,甚至表現出了一定的思考能力,有效地縮小了當前技術水平與現有技術之間的差距。流行文化想象人工智能可以。
過去,人工智能一直像是遙遠的科幻小說。但當今世界很多技術的應用已經達到了堪稱人工智能的水平。除了前面提到的圍棋軟件外,最近還部署了一系列人工智能系統并取得了巨大的效果,包括自動駕駛系統、智能管家,甚至還有蘋果智能手機捆綁的語音助手 Siri。這些應用背后的核心算法是深度學習,它是機器學習最熱門的分支之一。與其他機器學習算法不同,深度學習依賴于對大量數據進行迭代訓練來發現數據的特征并提供相應的結果。其中許多特征已經超越了人類定義特征的表達能力,
然而,深度學習尚未在所有方面超越人類。相反,它完全取決于人類對所使用算法的設計決策。深度學習從誕生到結出我們今天看到的果實,大約用了 50 年的時間。它的發展歷史讓我們得以一窺計算機科學家一絲不茍的獨創性,并提供了一個機會來討論這個令人興奮的領域的發展方向。
什么是深度學習?
深度學習利用所謂的人工神經網絡 (ANN)。盡管神經網絡算法的名稱來源于它們模擬動物神經元如何傳輸信息的事實,但深度學習一詞來自所涉及的多層級聯神經元——允許在信息傳輸中實現深度的多個層.
在動物中,神經的一端連接到受體,另一端連接到動物的皮層,信號通過中間的多層神經元傳導。神經元實際上并不是一對一連接的,而是有多個連接(如輻射連接和收斂連接),從而形成網絡結構。這種豐富的結構最終使得信息的提取和動物大腦中相應認知的產生成為可能。動物的學習過程需要在大腦中整合外部信息。外部信息進入神經系統,神經系統又變成大腦皮層可以接收的信號。將信號與大腦中的現有信息進行比較,從而可以建立完整的認知。
同樣,使用計算機編程技術,計算機科學家允許包含某些參數和權重的函數層來模擬神經元的內部操作,使用非線性操作的疊加來模擬神經元之間的連接,并最終重新整合信息以產生分類或預測結果作為輸出。為了處理神經網絡輸出與真實世界結果之間的差異,神經網絡通過梯度逐層調整相應的權重以減少差異,從而實現深度學習。
深度學習的起源
令人驚訝的是,模擬動物的神經活動并不是深度學習的專有領域。早在 1957 年,Frank Rosenblatt 就提出了感知器的概念。感知器實際上是一個單層神經網絡,只能區分兩種類型的結果。該模型非常簡單,輸出和輸入信息之間的關系本質上是一個加權和。雖然權重直接根據輸出與真實值的差自動調整,但整個系統的學習能力有限,只能用于簡單的數據擬合。
幾乎與此同時,神經科學也出現了重大進展。神經科學家 David Hubel 和 Torsten Wiesel 對貓的視覺神經系統進行的研究證實,大腦皮層對視覺特征的反應是由不同的細胞完成的。在他們的模型中,簡單細胞感知光信息,而復雜細胞感知運動信息。
受此啟發,日本學者福島邦彥于1980年提出新認知網絡模型來識別手寫數字(圖1)。該網絡分為多層,每一層由一種神經元組成。在網絡中,兩種類型的神經元被用來交替提取和組合圖形信息。這兩種類型的神經元后來演變成卷積層和提取層,它們仍然非常重要。然而,這個網絡中存在的神經元是人工設計的,它們不會自動適應呈現的結果,因此它們不具備學習能力,并且僅限于識別一小組簡單數字的基本任務。
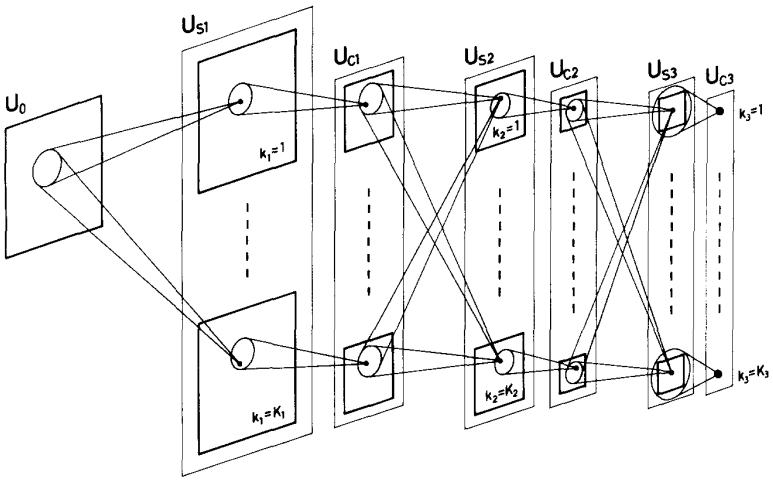
數字。1:neocognitron 機器的工作機制(來源:Fukushima,Kunihiko。“Neocognitron:一種能夠進行視覺模式識別的分層神經網絡。”Neural Networks 1.2(1988):119-130)
當無法實現學習能力時,需要額外的手動設計來代替真正的自學習網絡。1982年,美國科學家約翰霍普菲爾德發明了一種神經網絡,它有幾個限制,可以在變化中保持記憶,從而促進學習。同年,芬蘭科學家 Teuvo Kohonen 提出了一種基于無監督算法向量量化神經網絡(學習向量量化網絡)的自組織映射,希望通過縮短輸入和輸出之間的歐氏距離,從復雜網絡中學習正確的關系。1987年,美國科學家Stephen Grossberg和Gail Carpenter在早期理論的基礎上提出了自適應共振理論網絡。他們讓已知信息和未知信息產生共鳴,從已知信息推斷未知信息,實現類比學習。盡管這些網絡被附加了自組織、自適應和記憶等關鍵詞,但相應的學習方法并不高效。它需要基于應用本身不斷優化設計,再加上網絡內存容量小,難以在實踐中應用。
直到 1986 年計算機科學家 David Rumelhart、Geoffrey Hinton 和 Ronald Williams 發表了反向傳播算法,才逐漸解決神經網絡學習問題。神經網絡的輸出與真實值之間的差異現在可以通過與梯度相關的鏈式法則反饋到每一層的權重中,從而有效地允許每一層函數以與感知機相同的方式進行訓練。這是 Geoffrey Hinton 在該領域的第一個里程碑。如今,他是谷歌的一名工程研究員,并且是圖靈獎的獲得者,這是計算機科學領域的最高榮譽。
“我們不想建立一個模型來模擬大腦的工作方式,”欣頓說。“我們會觀察大腦,同時認為,既然大腦是一個可行的模型,我們應該看看如果我們想創建其他一些可行的模型,大腦會提供靈感。反向傳播算法模擬的正是大腦的反饋機制。”
此后在 1994 年,Geoffrey Hinton 小組的博士后計算機科學家 Yann LeCun 結合神經認知機制和反向傳播算法創建了 LeNet,這是一種用于識別手寫郵政編碼的卷積神經網絡,實現了 99% 的自動識別,并且能夠處理幾乎任何形式的手寫。該算法取得了巨大成功,并被美國郵政系統投入使用。
深度學習時代來臨
盡管取得了上述成就,但深度學習直到后來的某個時候才獲得顯著的普及。一個原因是神經網絡需要更新大量參數(僅 2012 年提出的 AlexNet 就有 65 萬個神經元和 6000 萬個參數),并且需要強大的數據處理和計算能力(圖 2 )). 此外,試圖通過減少網絡中的層數來減少數據量和訓練時間會使深度學習不如其他機器學習方法(例如在 2000 年左右變得非常流行的支持向量機)有效。Geoffrey Hinton 在 2006 年的另一篇論文首次使用深度信念網絡這個名稱,其中 Hinton 提供了一種優化整個神經網絡的方法。雖然這為深度學習的日后流行奠定了基礎,但之所以使用深度網絡而不是之前的神經網絡綽號,是因為主流研究期刊對神經網絡這個詞持反感態度,甚至看到論文就拒絕投稿。某些論文標題中使用的詞。
深度學習的重大轉折發生在 2012 年。計算機視覺領域的科學家開始意識到數據大小的重要性。2010 年,斯坦福大學計算機科學副教授李飛飛發布了 ImageNet,這是一個圖像數據庫,包含數千萬張手動標記的圖像,屬于 1000 個類別,包括動物、植物、日常生活等領域。從 2010 年到 2017 年,計算機視覺專家根據這些圖像舉辦年度分類競賽,ImageNet 已成為全球視覺研究中機器學習和深度學習算法的試金石。2012 年,多倫多大學 Geoffrey Hinton 的一名學生 Alex Krizhevsky 通過在兩塊 NVIDIA 顯卡 (GPU) 上編寫神經網絡算法贏得了 ImageNet 分類競賽,他的算法大大超過了第二名參賽者的識別率。該網絡隨后被命名為 AlexNet。這是深度學習快速崛起的開始。
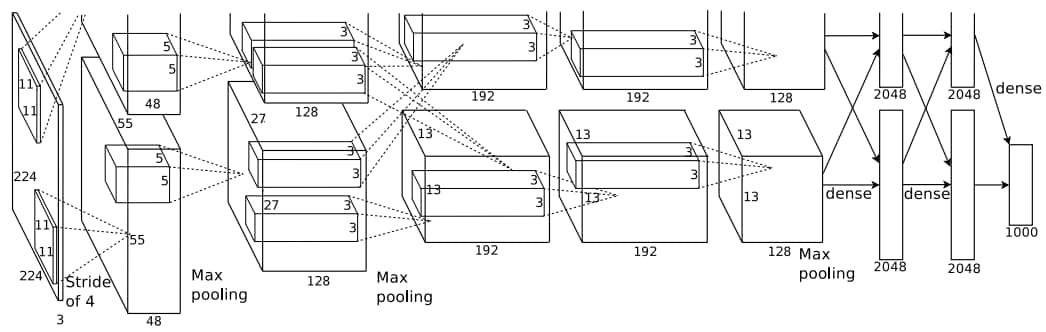
圖 2:AlexNet 的網絡結構(來源:Krizhevsky、Alex、Ilya Sutskever 和 Geoffrey E. Hinton,“Imagenet classification with deep convolutional neural networks”,Advances in Neural Information Processing Systems,2012。)
從 AlexNet 開始,到 ImageNet 的數據支持和商用顯卡的計算支持,神經網絡架構研究逐漸爆發。首先,由于發布了多個軟件包(例如 Caffe、TensorFlow 和 Torch),實施深度學習變得更加容易。其次,ImageNet 分類競賽和 COCO 競賽的后續迭代,其中給定的任務涉及更復雜的圖像分割和描述,產生了 VGGNet、GoogLeNet、ResNet 和 DenseNet。這些神經網絡使用的層數逐漸增加,從AlexNet的11層和VGGNet的19層到ResNet的150層,甚至DenseNet的200層,從而實現了真正的深度學習。在某些關于分類問題的數據集上進行測試時,這些深度神經網絡甚至超過了人類的識別精度(ImageNet 上的人類錯誤率約為 5%,而 SENet 可以達到 2.25%)。這在下表1:
表 1:歷屆 ImageNet 圖像分類競賽中表現最佳的網絡總結(來源:作者根據https://github.com/sovrasov/flops-counter.pytorch的原始論文計算得出)。
| 網絡 | 亞歷克斯網 | ZFNet | VGG網 | 谷歌網 | ResNet | ResNeXt | SENet |
| Top 5 錯誤率 | 15.32% | 13.51% | 7.32% | 6.67% | 3.57% | 3.03% | 2.25% |
| 層數 | 8個 | 8個 | 16 | 22 | 152 | 152 | 154 |
| 參數個數 | 60M | 60M | 138M | 7M | 60M | 44M | 67M |
| 年 | 2012 | 2013年 | 2014 | 2014 | 2015年 | 2016年 | 2017年 |
|---|
自這一突破以來,計算機科學家越來越多地使用神經網絡算法來解決問題。除了上述在二維圖像的分類、分割和檢測中的應用,神經網絡還在時間信號領域甚至無監督機器學習中得到應用。循環神經網絡 (RN) 可以按時間順序接收信號輸入。網絡的每一層神經元都可以壓縮和存儲記憶,而網絡本身可以從記憶中提取有效維度來進行語音識別和文本理解。當神經網絡用于無監督學習時,不是提取主成分或提取特征值,只需使用包含多層網絡的自動編碼器,即可自動縮小和提取原始信息。將上述與矢量量化網絡相結合,可以在不大量使用標記數據的情況下對特征進行聚類并獲得分類結果。現在毫無疑問,無論是在有效性還是在應用范圍方面,神經網絡都已成為無可爭議的王者。
深度學習:最新技術和未來趨勢
2017 年,ImageNet 圖像分類大賽宣布完成決賽。但這并沒有預示著深度學習的終結。相反,研究和深度學習應用已經有效地超越了之前的分類問題階段,進入了廣泛發展的第二階段。與此同時,深度學習相關國際會議論文投稿數量逐年呈指數級增長,表明越來越多的研究人員和工程師正在致力于深度學習算法的開發和應用。未來幾年,深度學習的發展將主要順應以下幾個趨勢。
首先,從結構上講,使用的神經網絡類型會更加多樣化。生成對抗網絡 (GANs) 可以執行卷積神經網絡的逆過程,自 2016 年首次提出以來發展迅速,已成為深度學習的重要增長領域。因為深度學習算法可以從原始信息(比如圖像)中提取特征,那么逆過程在邏輯上應該是可行的。換句話說,應該可以使用雜亂的信號通過特定的神經網絡生成相應的圖像。正是基于這種洞察力,計算機科學家 Ian Goodfellow 提出了生成對抗網絡的概念。除了生成圖像的生成器之外,這種類型的網絡還提供鑒別器。在訓練過程中,生成器傾向于掌握生成的圖片,這些圖片與真實圖片極其接近,而計算機很難區分。相比之下,鑒別器傾向于掌握區分真實圖片和生成圖片的魯棒能力。隨著兩者相互學習,生成的圖像越逼真,鑒別器就越難鑒別。相反,鑒別器的能力越大,生成器就越有動力生成新的、更逼真的圖像。生成對抗網絡有著廣泛的應用,從人臉生成和識別到圖像分辨率提升、視頻幀率提升、圖像風格遷移等領域。
其次,此類網絡涉及的研究問題往往更加多樣化。一方面,在機器學習的其他分支中發現的一些概念,例如強化學習和遷移學習,在深度學習中找到了新的位置。另一方面,深度學習的研究已經從工程試錯發展到理論推導。深度學習因缺乏理論支撐而受到批評,在訓練過程中幾乎完全依賴數據科學家的經驗。為了減少經驗對結果的影響,減少選擇超參數的時間,研究人員除了對最初的經典網絡結構進行修改外,還在從根本上修正深度學習的效率。一些研究人員正試圖將其他機器學習方法(如壓縮感知和貝葉斯理論)聯系起來,以促進深度學習從工程試錯到理論指導實踐的轉變。也有人努力解釋深度學習算法的有效性,而不是僅僅將整個網絡視為黑匣子。與此同時,研究人員一直忙于為超參數主題建立另一套機器學習問題,稱為元學習,試圖降低超參數選擇過程的難度和隨機性。也有人努力解釋深度學習算法的有效性,而不是僅僅將整個網絡視為黑匣子。與此同時,研究人員一直忙于為超參數主題建立另一套機器學習問題,稱為元學習,試圖降低超參數選擇過程的難度和隨機性。也有人努力解釋深度學習算法的有效性,而不是僅僅將整個網絡視為黑匣子。與此同時,研究人員一直忙于為超參數主題建立另一套機器學習問題,稱為元學習,試圖降低超參數選擇過程的難度和隨機性。
第三,由于最近大量注入新的研究成果,更多的算法正在商業產品中使用。除了幾家開發圖像生成小程序的小公司外,大公司也在深度學習領域爭奪地盤。互聯網巨頭谷歌、Facebook、微軟都設立了深度學習開發中心。他們的中國同行百度、阿里巴巴、騰訊、京東和字節跳動也各自建立了自己的深度學習研究中心。DeepMind、商湯科技、曠視科技等幾家扎根于深度學習技術的獨角獸公司,也在眾多競爭者中脫穎而出。2019年以來,行業相關的深度學習研究逐漸從發表論文轉向落地項目。比如騰訊AI Lab優化了視頻播放,
第四,隨著5G技術的逐步普及,深度學習將與云計算一起走進日常生活。由于缺乏計算資源,深度學習是一項普遍難以落地的技術。一臺帶有 GPU 的超級計算機的成本可能高達 3,411,900 美元(美元)或 500,000 日元(人民幣),而且并非所有公司都有資金和人才來充分利用此類設備。然而,隨著 5G 技術的普及和云計算的可用性,企業現在可以通過租用直接從云端獲取計算資源,而且成本低廉。公司可以將數據上傳到云端,并幾乎實時地從云端接收計算結果。許多新興的初創公司正在研究如何利用這一基礎設施,并組建了計算機科學家和數據科學家團隊,為其他公司提供深度學習算法支持和硬件支持。這使得以前與計算機技術關系不大的行業(例如制造、服務、娛樂,甚至法律行業)中的公司不再需要定義他們的問題并開發他們的解決方案。相反,他們現在可以通過與算法公司合作,從計算機技術行業的專業知識中受益,這樣他們就可以通過深度學習獲得授權。這使得以前與計算機技術關系不大的行業(例如制造、服務、娛樂,甚至法律行業)中的公司不再需要定義他們的問題并開發他們的解決方案。相反,他們現在可以通過與算法公司合作,從計算機技術行業的專業知識中受益,這樣他們就可以通過深度學習獲得授權。這使得以前與計算機技術關系不大的行業(例如制造、服務、娛樂,甚至法律行業)中的公司不再需要定義他們的問題并開發他們的解決方案。相反,他們現在可以通過與算法公司合作,從計算機技術行業的專業知識中受益,這樣他們就可以通過深度學習獲得授權。
總結與討論
50 多年來,深度學習從原型到成熟,從簡單到復雜。學術界和工業界積累了大量的理論和技術經驗。現在的發展方向比以往任何時候都更加多元化。一方面是因為很多相應的產品已經進入研發階段,另一方面是因為計算機科學家正在對深度學習進行更細致的研究。
當然,作為一門綜合學科,深度學習除了在圖像識別領域的核心發展歷程之外,還在語音分析和自然語言處理領域取得了碩果。同時,結合多種神經網絡和多媒體格式正迅速成為研究的熱點領域。例如,結合圖像和語言處理的自動圖像字幕是一個具有挑戰性的問題。
還應該注意的是,深度學習并不是實現神經網絡的唯一方法。一些現階段應用不那么廣泛的網絡結構,如自適應共振網絡、霍普菲爾德網絡和受限玻爾茲曼機,也可能有一天會推動整個行業進一步發展。可以肯定的是,雖然深度學習目前似乎仍籠罩在難以捉摸的復雜和神秘光環中,但在不久的將來,這個科幻概念將成為許多大大小小的公司的基礎技術。
審核編輯黃昊宇
-
深度學習
+關注
關注
73文章
5493瀏覽量
120980
發布評論請先 登錄
相關推薦
NPU在深度學習中的應用
AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度學習算法在嵌入式平臺上的部署
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
基于深度學習的小目標檢測
人工智能、機器學習和深度學習是什么
深度學習與卷積神經網絡的應用
深度學習與傳統機器學習的對比
深度解析深度學習下的語義SLAM

為什么深度學習的效果更好?


GPU在深度學習中的應用與優勢





 工商網監
工商網監
評論