 隊列管理電路-上篇
隊列管理電路-上篇
在數字芯片設計中,幾乎所有模塊都會涉及到隊列管理。輸入輸出的管理、不同數據流的調度、亂序數據的重排序、不同模塊的同步處理、資源管理,等等,均會涉及到隊列管理邏輯。如何選擇合適的硬件邏輯,對模塊的微架構有較大的影響,需要基于具體需求做綜合權衡后再做選擇。本文簡單羅列幾種隊列管理邏輯,均是個人曾經實現過的。
1 最簡單的隊列-FIFO
First In First Out,用于輸入輸出之間的緩沖,吸收輸入側的突發流量。實現也比較簡單,深度固定的環形buffer,使用讀寫指針進行管理。需要注意的是,讀寫指針的管理,FIFO為空和FIFO為滿,讀寫指針均是相等的,需使用另外的標號進行處理。也有其余的實現方式,比如移位寄存器。

使用SpinalHDL實現FIFO的代碼如下。輸入輸出的push/pop,使用了valid/ready握手的Stream接口;使用Mem定義環形buffer,pushPtr/popPtr分別對應讀寫指針;特別關注risingOccupancy信號,push和pop沒有同時發生時,更新為push,該信號可用于標記FIFO的空滿狀態。讀寫指針相等且該信號為低,表示FIFO為空;讀寫指針相等且該信號為高,表示FIFO為滿。
// spinal/lib/Stream.scala
val io = new Bundle {
val push = slave Stream (dataType)
val pop = master Stream (dataType)
val flush= in Bool() default(False)
val occupancy = out UInt (log2Up(depth + 1) bits)
val availability = out UInt (log2Up(depth + 1) bits)
}
val ram = Mem(dataType, depth)
val pushPtr = Counter(depth)
val popPtr = Counter(depth)
val ptrMatch = pushPtr === popPtr
val risingOccupancy = RegInit(False)
val pushing = io.push.fire
val popping = io.pop.fire
val empty = ptrMatch & !risingOccupancy
val full = ptrMatch & risingOccupancy
io.push.ready := !full
io.pop.valid := !empty & !(RegNext(popPtr.valueNext === pushPtr, False) & !full) //mem write to read propagation
io.pop.payload := ram.readSync(popPtr.valueNext)
when(pushing =/= popping) {
risingOccupancy := pushing
}
when(pushing) {
ram(pushPtr.value) := io.push.payload
pushPtr.increment()
}
when(popping) {
popPtr.increment()
}
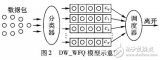
2 共享Buffer的多隊列FIFO
考慮一個場景,輸入的請求需要分發至不同的輸出側,下游存在反壓。簡單實現,基于不同的輸出分別設置FIFO,但可能存在資源浪費,某些數據流場景FIFO的利用率不高,尤其是在數據位寬較大的場景。
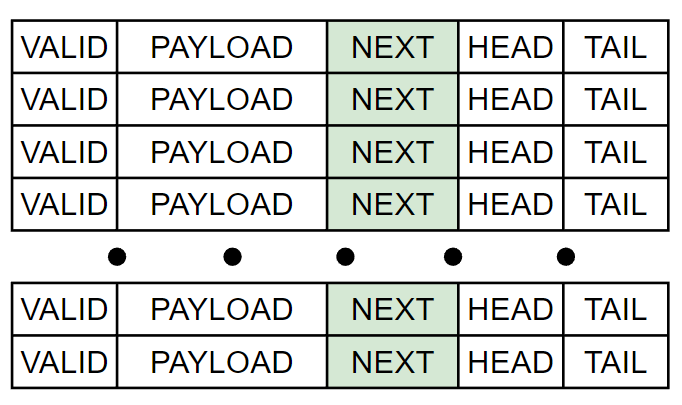
共享Buffer的多隊列FIFO,每個隊列的FIFO還是按照簡單隊列進行管理,基于每個隊列管理讀寫指針。但是,不再使用環形Buffer,每個buffer entry記錄其隊列號、隊列指針和Payload,如下圖所示。對于Payload位寬較小的場景,收益不大,若存在大位寬時,可有效提升Buffer的利用率。

將數據寫入Buffer時,先找一個Free Entry(Vliad為低),將該數據所屬的隊列號及其對應的寫指針、Payload寫入到對應的Entry內。讀取Buffer時,則使用隊列號和讀指針進行匹配,將命中的Entry內容讀取出來。若讀寫指針所能描述的范圍比buffer深度大,則不需要額外的標號記錄空滿狀態。存在的問題,若buffer深度較大或隊列數量較多,隊列號和指針匹配邏輯會占用較多的資源。
3 重力FIFO
類似于排隊,從隊頭開始尋找可輸出的Entry,調度輸出并留下空位,后面的Entry再往前排,新輸入的請求則放置在隊列尾。如圖所示,存在有效數據的Entry,其前面的Entry被調度后留下空位,該Entry就像受到重力作用往下掉,因此我也稱之為重力FIFO。

該結構的問題,存在大量的移位,設想Payload位寬為32bit,深度為32,將近1kbit的寄存器在做移位處理,其功耗可想而知。但是對于一些具體場景,還是能夠帶來一些收益的,如隊列數量較大,甚至大于buffer深度;至于Payload位寬較大的場景,可考慮二次索引處理,Payload保存至另外的buffer,該結構內的Payload Entry則緩存其索引信息。
4 Bitmap排序
先來看一個結構,深度為8的隊列,每個Entry使用8bit緩存8個Entry的狀態,若該狀態信號滿足觸發條件,如全為0,則調度該Entry內容。
Bitmap排序就是使用了這一結構,在輸入請求進入隊列后,檢查當前隊列狀態,存在關聯請求的Entry位置置位為1,否則為0。若存在請求輸出之后,所有Entry狀態的對應位置均設為0。若某個Entry的狀態信號全為0,則請求調度輸出。其數據結構如下圖所示,其中0/1僅作為狀態信號的示例,并非實際場景。

該結構可以實現較為靈活的排序,隊列的數量幾乎不會受到限制,進入隊列的請求,也可修改其Mask Bitmap,動態刷新其先后關系。與重力FIFO類似,無需額外的數據結構保存其隊列關系,而是直接體現在原有結構內。存在的問題,隊列深度會受到面積限制,面積與深度的平方成正比;另外,在動態更新Mask Bitmap之后,某些實現可能無法保證先后關系。
面積問題可以考慮用分級處理。如需實現256深度的隊列,其Mask Bitmap需要65536個寄存器實現Mask Bitmap。分解為8個32深度的隊列,需要的寄存器數量為8192;分解為16個16深度的隊列,寄存器數量為4096。
5 小結
隊列管理電路還有一個比較常見的實現,鏈表。在亂序數據的重排序、資源管理等等方面,通常會用鏈表實現,與上幾個結構相比,鏈表會復雜一些。該部分將在下篇描述。
除最簡單的FIFO之外,其余幾個都沒有代碼,如各位要有興趣,請留言,我可以再嘗試寫一些Spinal代碼實現。
-
芯片設計
+關注
關注
15文章
980瀏覽量
54620 -
隊列管理
+關注
關注
0文章
4瀏覽量
6276 -
數字芯片
+關注
關注
1文章
103瀏覽量
18337
發布評論請先 登錄
相關推薦
主動隊列管理建模及最優控制策略
簡單羅列幾種隊列管理邏輯電路
什么是鏈表?怎樣使用鏈表作為隊列管理電路
不同服務類型的隊列管理及性能比較
一種改進的主動隊列管理算法
網絡中常用的隊列管理方法比較
主動隊列管理建模及最優控制策略
一種基于速率的公平隊列管理算法
一種參數自適應的主動隊列管理算法—自適應BLUE
面向網絡能效優化的動態權重隊列管理算法





 工商網監
工商網監
評論