") 基于長度感知注意機制的長度可控摘要模型
基于長度感知注意機制的長度可控摘要模型
以往的長度可控摘要模型大多在解碼階段控制長度,而編碼階段對指定的摘要長度不敏感。這樣模型傾向于生成和訓練數(shù)據(jù)一樣長的摘要。在這篇論文中,作者提出了一種長度感知注意機制(LAAM,length-aware attention mechanism)來適應基于期望長度的編碼。
本文的方法是在由原始訓練數(shù)據(jù)構(gòu)建的摘要長度平衡數(shù)據(jù)集上訓練 LAAM,然后像往常一樣進行微調(diào)。結(jié)果表明,這種方法可以有效地生成具有所需長度的高質(zhì)量摘要,甚至是原始訓練集中從未見過的短長度摘要。

論文題目:Length Control in Abstractive Summarization by Pretraining Information Selection
收錄會議:
ACL 2022
論文鏈接:
https://aclanthology.org/2022.acl-long.474.pdf
代碼鏈接:
https://github.com/yizhuliu/lengthcontrol
背景
摘要任務目的是改寫原文,在簡明流暢的摘要中再現(xiàn)原文的語義和主題。為了在不同的移動設(shè)備或空間有限的網(wǎng)站上顯示摘要,我們必須生成不同長度的摘要。
長度可控的摘要是一個多目標優(yōu)化問題,包括:
在期望的長度內(nèi)生成完整的摘要
以及根據(jù)期望的長度選擇適當?shù)?a target="_blank">信息
相關(guān)方法
現(xiàn)有的基于編解碼器模型的長度可控摘要可分為兩類:
解碼時的早停
編碼前的信息選擇
解碼過程中的早停方法關(guān)注何時輸出 eos(end of sequence),也就是摘要的結(jié)束標志。有人設(shè)計了專門的方法。這個專門方法是通過在測試期間將期望長度的位置上的所有候選單詞分配 ?∞ 的分數(shù)來生成 eos。這個方法可以應用于任何 seq2seq 模型。然而,這些方法只是簡單地為解碼器增加了長度要求,而忽略了從源文檔編碼內(nèi)容或信息選擇也必須適應不同長度要求的問題。
基于信息選擇的方法分為兩階段。一個突出的例子是 LPAS,在第一階段,從源文檔中提取最重要的l個標記作為所需長度的原型摘要,并在第二階段通過雙編碼器對源文檔和原型摘要進行編碼。一方面,這種兩階段方法會在中間結(jié)果中引入噪聲。另一方面,這些方法的第二階段沒有第一手的長度信息,這削弱了長度控制。
本文方法
在本文中,作者提出了LAAM(長度感知注意機制),它擴展了 Transformer seq2seq 模型,具有根據(jù)長度約束在上下文中選擇信息的能力。
LAAM 重新 normalize 編碼器和解碼器之間的注意力,以增強指定長度范圍內(nèi)具有更高注意力分數(shù)的 token,幫助從源文檔中選擇長度感知信息。隨著解碼進行,增強 token 的數(shù)量將會逐步減少,直到 eos 獲得最高的注意力分數(shù),這有助于在指定長度上停止解碼過程。
LAAM 可以被認為是上一節(jié)兩類方法的混合版本。
同時作者觀察到,在現(xiàn)有訓練集中,不同長度的摘要數(shù)量有很大差異。為了平衡摘要在不同長度范圍內(nèi)的分布,本文提出了一種啟發(fā)式方法:首先定義摘要長度范圍,然后從原文中直接抽取不同長度的摘要,根據(jù)特定指標控制抽取摘要的相關(guān)度,從而創(chuàng)建長度平衡數(shù)據(jù)集(LBD,length-balanced dataset)。
在本文方法中,先從原始的摘要數(shù)據(jù)集創(chuàng)建一個 LBD。之后,在 LBD 上預訓練LAAM,以增強 LAAM 在長度約束下的文本選擇能力。最后,將預訓練后的 LAAM 在原始數(shù)據(jù)集上微調(diào),以學習將所選文本改寫為不同長度的摘要。
當前訓練數(shù)據(jù)集中沒有短摘要,微調(diào)后的模型沒有見過短摘要,所以如果用它生成短摘要的話算是 zero-shot。得益于 LDB 的預訓練,本文的方法可以解決zero-shot情況下的長度控制問題。
本文的主要貢獻:
提出了LAAM(長度感知注意機制)來生成具有所需長度的高質(zhì)量摘要。
設(shè)計了一種啟發(fā)式方法,從原始數(shù)據(jù)集中創(chuàng)建一個LBD(長度平衡數(shù)據(jù)集)。在 LBD 上對 LAAM 進行預訓練后,LAAM 效果能有提升,并且可以有效解決 zero-shot 情況下的短摘要生成問題。
LAAM
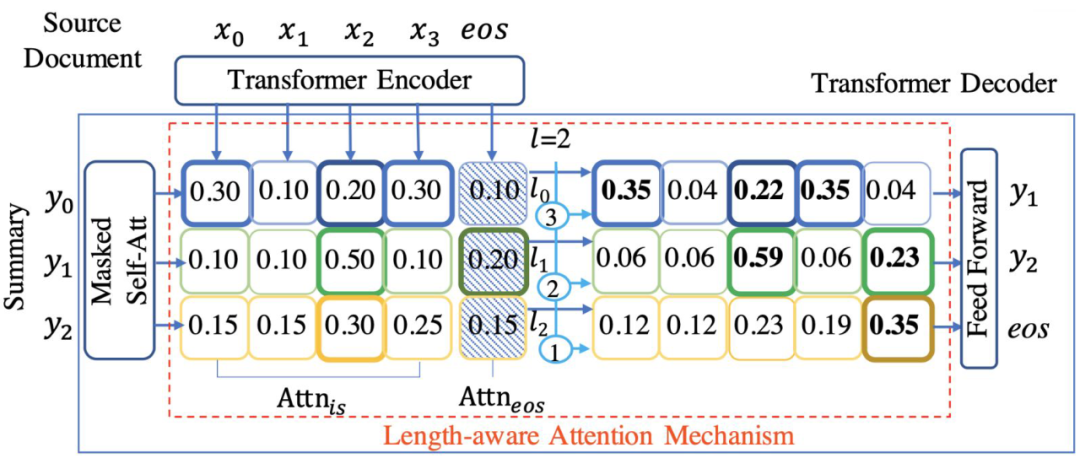
上圖是 Transformer 解碼器。
左上方為源文檔輸入:,作為注意力的 Key。
最左側(cè)為模型當前輸出:,作為注意力的 Query,兩者點乘得到注意力矩陣。 注意力矩陣分為兩部分, 負責文本信息選擇, 負責結(jié)束標志選擇
注意力矩陣的第一行加粗了 Top3,第二行加粗了 Top2,第三行加粗了 Top1,對加粗的進行提權(quán),本文通過這種方式向模型傳遞句子剩余預測長度信息。
也會進行提權(quán),并且越接近指定長度,提權(quán)幅度越大,模型也就更容易預測出 eos。
提權(quán)后要進行一次歸一化,不然和不為 1。
這就是本文提出的 LAAM 模型。
總結(jié)
本文方案的整體流程是:
用原始訓練集生成 LBD(長度平衡數(shù)據(jù)集)
在 LBD 上預訓練 LAAM 模型
在原始訓練集上微調(diào) LAAM 模型
審核編輯 :李倩
-
編解碼器
+關(guān)注
關(guān)注
0文章
253瀏覽量
24209 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24649
原文標題:ACL 2022 | 基于長度感知注意機制的長度可控摘要模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
示波器小技能:TDR測量線纜長度

測長機在測量長度尺寸方面有哪些優(yōu)勢?

CS1-U DC/AC5-240V磁性開關(guān)長度要求
hdmi線長度不能超過多少米
【大規(guī)模語言模型:從理論到實踐】- 閱讀體驗
hdmi線纜長度根據(jù)什么決定選擇
如何利用實時示波器測量線纜長度
嵌入式中零長度數(shù)組基本操作方法
3芯M9接口的長度是多少

DMA搬運的數(shù)據(jù)長度超過65535怎么處理?
如何提高BLE_MeshLightingLPN的發(fā)送數(shù)據(jù)長度?
你計算過車輛線束的最大繞線長度嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論