 一個時代有一個時代的計算架構
一個時代有一個時代的計算架構
Can Machines Think?
這是阿蘭·圖靈在1950年論文《計算機器和智能》中的經典提問,圍繞著圖靈的目標,軟件和硬件開啟了分頭行動。
軟件,以算法為核心,衍生出了神經網絡,并在深度學習的加持下,讓人工智能浪潮實現全面洶涌。
硬件,以芯片為載體,從CPU、GPU到各類AI芯片,從執行人的計算程序,到像人一樣計算。芯片和AI,硬件和軟件,一個源頭流出的兩條大河,終于在此刻合流交匯。
但背后的驅動力也越來越明顯:
一個時代有一個時代的架構。
現在,面向AI時代的計算架構,呼之欲出。
讓機器執行人的思考和計算:從CPU到GPU
要想知道未來到哪去,必先知道自己從哪兒來。
今天,一切智能機器無論大小,都少不了一塊CPU。正是這個好比“大腦”的東西,讓大大小小的硬件可以執行人寫好的規則,實現各式各樣的功能。
世界首塊CPU誕生于1971年,但它的概念可以追溯到世界上第一臺具有現代意義的通用計算機——EDVAC身上。
EDVAC是ENIAC(世界第一臺電子計算機)的小老弟,由馮·諾伊曼設計。EDVAC最大的改變之一,就是將計算機劃由運算器、控制器、存儲器、輸入和輸出這五個部分組成。
這就是著名的馮·諾伊曼架構。從這個架構里,我們就可以看到CPU的雛形。
——從彼時至今,無論CPU的具體實現怎么變、晶體管數量翻多少番,它的構成始終由運算器、控制器和寄存器這三大部分組成。
其中,運算器也叫算術邏輯單元(ALU),負責算術運算和邏輯運算。寄存器細分為指令寄存器和數據寄存器等,負責暫存指令、ALU所需的操作數、ALU算出的結果等。
控制器則負責整體調度工作,包括對要執行的指令進行譯碼、從內存中調取數據給寄存器、向運算器和寄存器發出具體操作指令等。
從上面這個分工我們也能看出CPU的大概工作流程,簡單來說就是這四步:
1、從內存提取指令;2、解碼;3、執行;4、寫回。
其中寫回到寄存器的結果,可供后續指令快速訪問。
看起來,整個流程沒有什么bug。
但仔細回看一下CPU三大組成的各自分工,可以發現控制器和寄存器是這里面要負責的東西最多、要存的東西最多的兩部分。
從下面這張CPU的簡略架構圖也能看出,運算器“偏居一隅”,幾乎80%的空間都被控制單元和存儲單元占據。

這樣的設計就造成CPU最擅長的是邏輯控制,而非計算。
同時,依照馮·諾依曼架構“順序執行”的原則,“古板”的CPU只能執行完一條指令再來下一條,計算能力進一步受限。
當然,你說CPU靈活性高、通用性強,我們可以將它進行同構并行。
但別忘了,單個CPU的性能上限就那么高、能容納的核數也有限,這種方法能挖掘的潛能實在有限。
所以,要是讓CPU來完成計算量動輒上億的AI任務,實在是“愛莫能助”。就比如在自動駕駛領域,系統需要同時查看人行道、紅綠燈等路況,如果交給CPU來計算,總不能車都撞上了還沒算出來結果吧。
所以,針對CPU“拉垮”的計算能力,GPU站在了浪潮之巔。
正如其全稱“圖形計算單元”,GPU的初衷主要是為了接替CPU進行圖形渲染的工作。
因為圖像上的每一個像素點都需要處理,這項任務計算量相當大。尤其遇上一個復雜的三維場景,就需要在一秒內處理幾千萬個三角形頂點和光柵化幾十億的像素。
不過,由于每個像素點處理的過程和方式相差無幾,這項艱巨的任務可以靠并行計算來化解。
而這恰好就是GPU最得天獨厚的優勢,尤其以處理這種邏輯簡單、類型統一的瑣碎計算任務為甚。
GPU之所以擅長并行計算,從其架構里就決定了。
GPU幾乎主要由計算單元ALU組成,僅有少量的控制單元和存儲單元。
這也就意味著,GPU可以擁有數百、數千甚至上萬核心來同時處理計算任務,使計算的并行度得到成千上萬倍的提升——相比現在普通電腦最多8核CPU同時工作,這是一個多么恐怖的數字。
再舉一個最簡單的例子來直觀感受一下。
比如現在我們來計算一下5000個數相加之后的總和。
如果我們用CPU來算,即使派上8核CPU,每個核也需要計算625個數;假設每計算一個數需要1s,即使8核并行計算,總共也需要625s。(這里暫時不考慮支持向量指令的CPU)而GPU,核心數成千上萬,計算5000個數字只需每核算1個數,1s就能搞定。
625sVS1s,這是何等的差距。
除了并行計算能力,GPU的內存帶寬也是CPU的幾十倍 ,決定了它將數據從內存移動到計算核心的速度更快,整體計算性能更加讓CPU望塵莫及。
由于GPU的設計并沒有專門跟圖形綁定的邏輯,屬于一種通用的并行計算架構,所以除了圖像處理,它其實也非常適用于科學計算,乃至復雜的AI任務。
所以在2012年,當Hinton及其弟子Alex Krizhevsky將其作為深度學習模型AlexNet的計算芯片,一舉贏得Image Net圖像識別大賽之后,GPU在AI領域的名聲就一炮打響。
而早就基于自家GPU推出了CUDA系統的英偉達,又憑借著三年時間里將GPU性能提升65倍,并提供后端模型訓練和前端推理應用的全套深度學習解決方案,奠定了自己在該領域的王者地位。
直到今天,GPU也還是AI時代算力的核心、人工智能硬件領域的霸主。
然而,GPU屬于通用計算芯片和架構,并非專門為AI打造,無法實現性能和功耗的統一。它的計算能力越強代表核心越多,功耗也就越大。
比如RTX 4090,450W;比如今年9月剛上市的H100,直接史無前例,700W。這種情況還大有逐年攀升之勢。
還是拿自動駕駛舉例,在電車基本成為主流的當下,如此高的功耗勢必對續航里程造成困擾。更別提越來越多的終端也開始具備AI能力(比如手機、智能音箱),它們不僅要求計算能力,對功耗的要求也更加嚴格,再強的GPU在這里也顯得很弱勢。
另外,一些更復雜的AI場景(如云端推理、模型訓練等),常常動輒就需要上百塊GPU一起運算,這讓整個計算平臺的功耗控制也是相當棘手。很多機構不得不考慮能源和環保問題。
這不,今年7月誕生的目前最大的多語言開源模型BLOOM,就動用了384塊A100煉成,釋放的熱量最終都用來給學校供暖了。
所以,綜上來看,CPU和GPU的出現,雖然幫助機器擁有了執行人的思考和計算的能力,尤其后者讓AI計算任務得到了相當大的加速,但一些缺點還是讓它們無法大展身手。
因此要想讓機器像人一樣思考和計算,通用計算芯片的架構決定了不會是最佳方案。
讓機器像人一樣思考和計算:AI芯片大爆發
數據驅動的方式方法,讓機器像人一樣思考和計算展現了可能。
但背后的計算需求,也讓過去的計算架構越顯強弩之末。
據統計,光是在2012年到2018年的六年時間里,人們對于算力的需求增長了就超過30萬倍。也就說,每3.5個月AI算力就大約翻一倍。如今這個數字還在繼續攀升。
所謂“通不如精”,以CPU和GPU為代表的通用計算芯片架構,已經無法很好地匹配和滿足這一需求,所以在各類新AI技術層出不窮的同時,新計算、新架構、新芯片在過去幾年也迎來了前所未有的大爆炸。
因此這幾年,我們看到了很多除了CPU和GPU以外的各種“xPU”,諸如谷歌TPU、Graphcore IPU、特斯拉NPU、英偉達DPU……
盡管它們的分類不同,有的屬于半定制化的FPGA,有的屬于全定制化的ASIC,有的應用于終端,有的應用于云端……但作為專門為AI任務和需求而生的新芯片,它們都有著比CPU/GPU功耗低、計算性能高、成本更低等優勢,落地到哪里就給哪里帶去了翻天覆地的變化,比如最近幾年的智能手機、自動駕駛、機器人、VR等領域。
按照能力和用途,這些AI芯片們在這個過程中上演了這樣兩個階段:
首先是僅作為加速器,輔助CPU完成HPC、模型訓練/推理等AI任務。
(AI芯片幾乎都不具有圖靈完備,所以必須要和CPU一起搭配使用,這也是所謂的“異構融合”大趨勢。)
它們的結構類似串聯,可以用“CPU+xPU”這樣的公式來表達。
這一組合最經典的其實就是CPU+GPU,它倆到現在其實也還在流行。
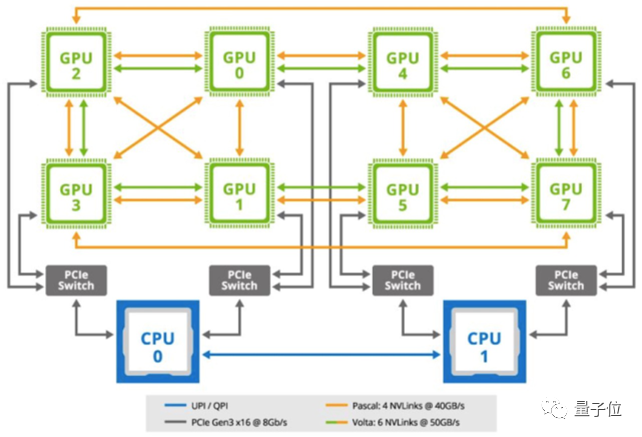
只不過如前面所說,GPU不算專門為AI設計的芯片,無法在這一領域發揮出極致的性能,所以這里的xPU更多的指TPU、IPU、DPU等AI加速芯片。
(當然,GPU還是自有它的用處,所以它有時也會加入進來,形成“CPU+GPU+xPU”的結構。)
這一模式最大的特點就是,CPU只負責少量的計算,一般為那些情況比較復雜、計算難度不確定、靈活性要求高的部分;大部分“臟活累活”都由計算能力超強、能耗又沒那么高的xPU來完成。
就如下圖所示,在實際情況中,它們的分工很可能遵守“二八定律”——xPU負責整個系統80%的計算任務,剩下的20%由CPU+GPU分擔,其中GPU的比例又高達16%,留給CPU的只剩下4%。
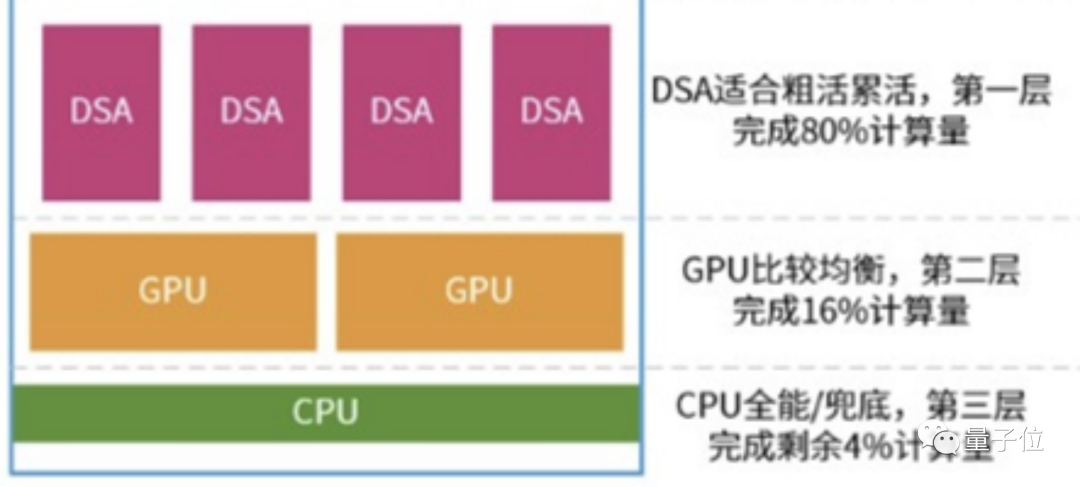
如果進行軟硬件融合的進一步優化,三者之間的比例還可能變動為90%、9%和1%。
這樣各司其職、各揮所長的安排可以保證最極致的性能和性價比,做到從前CPU和GPU單上無法企及的高度。
其次,AI芯片作為專用芯片,針對專門的領域推出,負責某一特定AI任務的計算。
(說通俗點,就是某一塊專用芯片能在自動駕駛領域使用,換了機器人領域就不行)。
在這種模式下,各xPU已成為各系統的主角,決定該系統的整體性能和效果。
這就導致一些自動駕駛公司,在宣傳它們的技術時,只把xPU拉出來大肆宣傳,基本不提CPU和GPU的事兒了。
那么CPU在干嘛?當然是利用自己擅長的邏輯控制來把控整個流程。
因此此時,CPU和AI芯片的關系更像一種并聯結構,我們就可以用“CPU、xPU”的公式來表達(當然,GPU也仍然可能參與其中)。
如前面所說,由于CPU基本不決定計算性能,我們也就不用再寄希望于CPU的戰斗力有多強。
進一步地,我們可以認為,這種模式其實是將通用計算芯片的核心地位削減了——CPU的地位又變了。
那么,成為“中流砥柱”的AI芯片們究竟有多大威力?我們來看3個案例。
首先是云端。
在這個領域,互聯網巨頭們有著“本土作戰”的優勢,因此大多可以不依賴英偉達等傳統巨頭。
如谷歌2015年就推出了自己的云端加速AI芯片TPU。
它的中文名叫張量處理器,屬于ASIC芯片的一種,專為加速深度學習框架TensorFlow而設計。
得益于用量化技術進行8位整數運算、脈動陣列、基于復雜指令集(CISC)等設計,它與同期的CPU和GPU相比(英特爾至強E5-2699 v3與Tesla K80 GPU),可以提供大約15-30倍的性能提升。
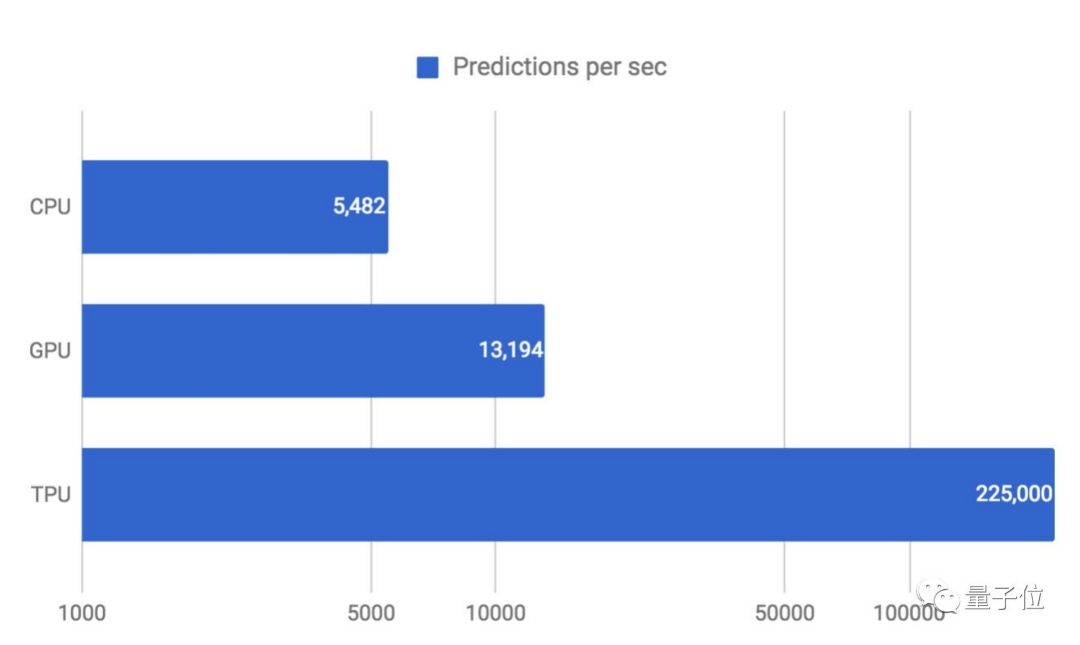
如下圖所示,當將延遲全部控制在7毫秒之內時,TPU每秒可運行的MLP0預測可達22.5萬次。同等情況下,CPU只有5000多,GPU也僅為1.3萬+。
效率方面(性能/瓦特)的提升也高達30-80倍:
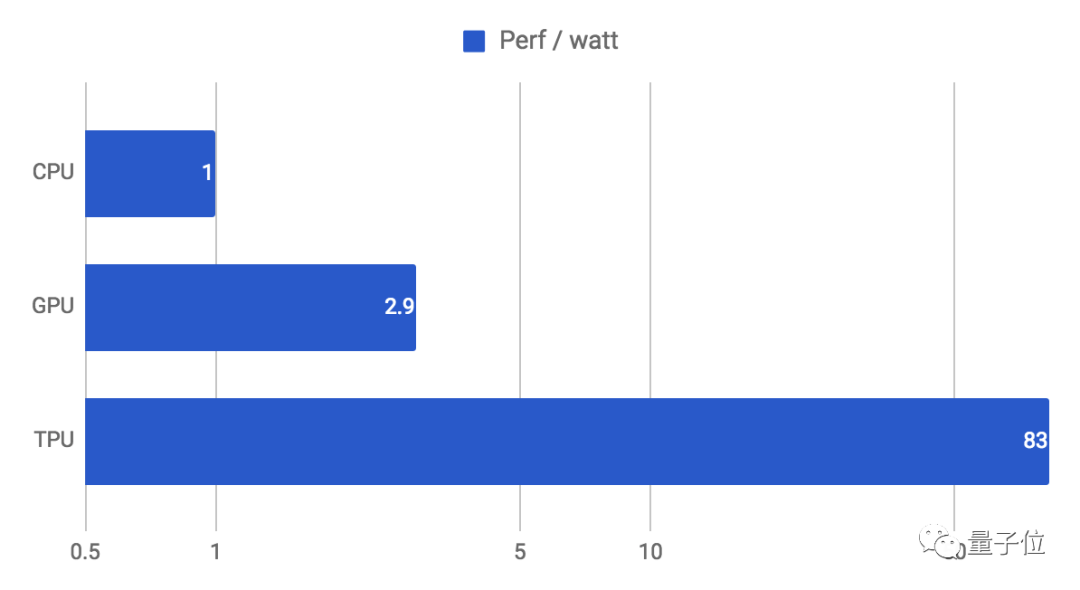
(谷歌第一代TPU功耗約為40W,性能最強的第四代也只有175W,而同時期的A100已達400W。)
這樣的成績意味著它既可以大規模運行于最先進的神經網絡,也可以同時把成本控制在可接受的程度上。
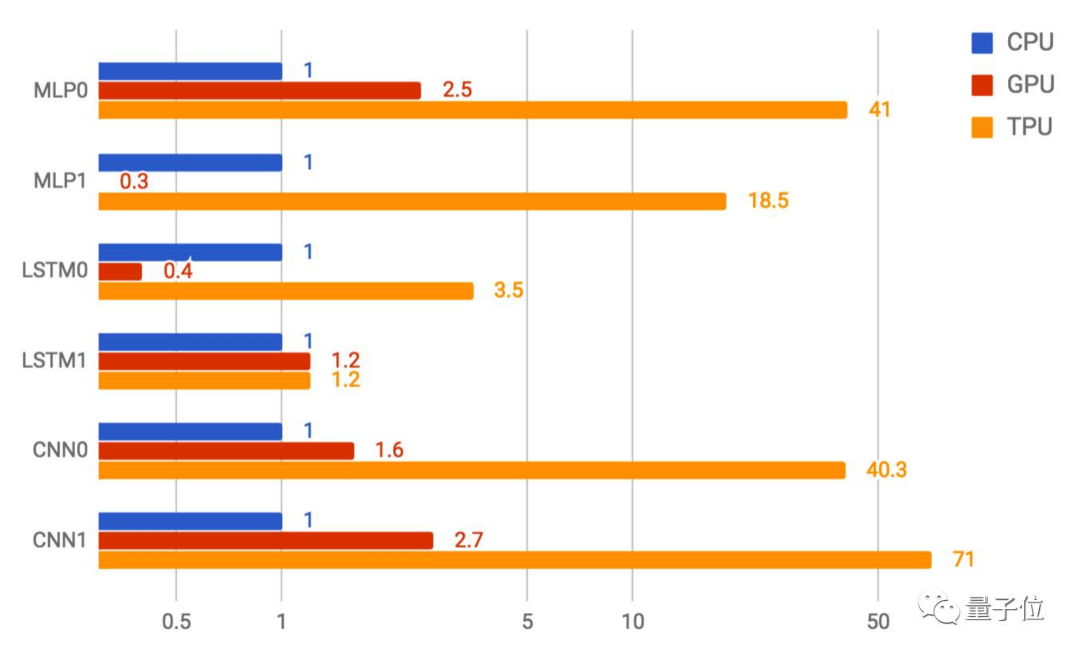
△TPU在以上6種神經網絡中的CNN1上表現最好,性能是GPU的26倍
它的出現,不僅打破了深度學習硬件執行的瓶頸,也在一定程度上撼動了英偉達等傳統巨頭的地位。
谷歌也對它重用有加,搜索、街景、照片、翻譯等服務以及AlphaGo背后的神經網絡計算,都交由它來完成。TPU的出現,成為了AI時代云端計算需求的代表性解決方案。
終端方面,最具代表性的場景是AI司機變革下的汽車領域,即自動駕駛。
目前,自動駕駛芯片有兩條主要技術路線:
一是英偉達Orin靠“魔改”GPU所走的通用架構路線;另一個是特斯拉、高通、Mobileye等青睞的專用芯片技術路線,也就是CPU+(GPU)+xPU的形式。
比如特斯拉FSD芯片就是主要由CPU、GPU和NPU組成。

△圖源wikichip,特斯拉FSD芯片die shot圖
其中,NPU是里面占比最大的處理器,是整個架構的重點。
它是由特斯拉硬件團隊自研的一種ASIC芯片,主要用來對視覺算法中的卷積運算和矩陣乘法運算進行有效加速。
具體來看,每塊NPU的運行頻率為2GHz,峰值性能可達每秒36.86萬億次運算(TOPs),總功耗卻僅為7.5W。
所以,正是從特斯拉開始,專為自動駕駛所需的神經網絡打造的NPU開始成為汽車芯片的主要組成部分,傳統的通用芯片CPU、GPU開始退居輔助位置。
國內方面,唯一實現車載智能芯片大規模前裝量產的地平線,其代表芯片征程系列,也是采用“CPU+ASIC”的技術路線,ASIC部分用的是自研的BPU。
它的使用使最新的征程5芯片算力達到了128TOPS,功耗也只有30W。
由此,征程5靠4.3TOPS/W能耗比,一舉超過了特斯拉FSD(2TOPS/W)、也超過了2022年高端智能電動車標配的英偉達Orin(3.9TOPS/W)。
這種性能和功耗展現出的對比,甚至是標志性的。背后是芯片架構在AI時代正在發生的變化趨勢:
CPU在其中的作用和地位一直在變化,而這其實反映的是AI時代計算架構客觀需求的進化——
一開始是完全規則驅動,只有CPUGPU等通用計算芯片進行發力,但由于架構的規則都是被寫死的,無法適應越來越快的算力需求;
于是開始了半規則驅動,CPUGPU等通用計算芯片的核心能力繼續發力,但已開始有專用芯片的介入,讓AI計算架構不再依賴于完全寫死的規則,相對靈活地發揮出價值;
再到后來,便開啟了自定義規則驅動的階段,此時專用型AI芯片占據核心地位,CPU/GPU僅僅作輔助之用,AI計算架構獲得最大的自由度。
而我們的機器也終于能夠從執行人的思考和計算,越來越接近像人一樣思考和計算。
但這還不是終點。
終極計算架構:Neural Computing
終點是什么?不同視角會有不同的答案。
最近正在被更多人認同的是:Neural Computing,神經網絡架構,或者說神經網絡統一架構。
即一個大一統的神經網絡計算架構,一套架構驅動所有場景、領域或任務,比如圖像處理、視頻編解碼、圖像的生成、渲染,只需要很少的一點點改動或者一點點算法的調優,就能解決各式各樣的問題。
其特點,就是用技術驅動的方式去集成少量的規則,讓硬件因軟件而打造,軟件為實現算法而生,這樣更符合AI算法模型和任務的特點,也才能真正讓模型躍遷驅動性能躍遷。而不再是傳統的用硬件迭代解決問題。
而且這種方法論,不只是單純的展望,因為正在被實踐。
比如智能車載芯片,不僅用神經網絡做了分割、檢測和識別等語義級信息,而且能夠清晰地看到一個趨勢,包括ISP(Image Signal Processing)這樣的圖像處理任務,也都能夠用神經網絡實現了。
而業內,視頻編解碼相關的方法,神經網絡也比傳統方式實現得更好,信噪比更優異。
這兩年火爆的NeRF,涉及到過去非常考驗硬件能力的圖像渲染,需要基于光線追蹤等等圖形學理論建立復雜規則的算法,也都被證明神經網絡可以做得更好。
甚至用的還是很簡單的神經網絡計算方法,通過學習再推理的方式重構整個過程,把過去花費大力氣求解的3D點云恢復重建等問題,更直接高效解決,實力和潛力,都不言自明了。
更重要的是,這種實踐被放到了一個更具時代變革的趨勢上:計算架構領域到了一個分久必合的時候,到了一個傳統馮諾依曼架構亟待突破的時候。
這是兩個時代的劃分,背后是人與機器關系的兩種范式。
1.0時代,依賴于經驗和規則,把人類理性分析轉換成計算機可具體執行的規則代碼,不僅定義目標,也定義整個執行的過程。
這個時代里有很多經典的算法排序,會告訴機器每一步做什么,以及怎么做。CPU和GPU都是這個時代里的集大成者。
2.0時代,依靠的是神經網絡學習和迭代,人類提目標、要求,有時目標甚至會是一個大致的方向和框架,但機器會在神經網絡驅動下,搞清楚如何去執行,如何圍繞目標求解最優解——機器有了自主性。于是就得從算法、架構到芯片確保機器的這種自主性。
1.0時代可以很多精細的規則、后處理、后融合,把所有人類對于具體場景任務的know-how變成計算機可嚴格執行的代碼,再與“摩爾定律”和硬件革新配合,做到極致的高效。
然而AI模型范式下對數據的需求,以及先進制程的瀕臨極限,摩爾定律失效已然是再明顯不過的事實。
所以計算架構和范式,一定會進入2.0時代,人類架構的是神經網絡模型,模型自己去求解目標和結果,整個過程不再依賴人寫死的規則和經驗。這會是軟件、硬件到認知方法方方面面的根本性改變——傳統的計算架構不再適用。
這種對自主機器到來的判斷,實際也能理解很多新現象。
比如馬斯克為什么把特斯拉的下一步,定在機器人形態上。
百度創始人李彥宏,把自動駕駛、智能車,放在了“汽車機器人”的維度上思考和談論。
以及當前以智能車載芯片知名的地平線,全名里為啥是“機器人技術”。
因為一旦沿著AI落地展開思考和推演,最后能作為獨立品類、物種展現AI核心變革力的,有且只有機器人,或者說就是自主機器人。
它可以是家里掃地的那種,可以是提供自動駕駛出行的那種,也可以是仿照人類形體而生的那種——從感知到控制都有自主權,會是邊緣的而非云端的,會是去中心化的而非中心化的。
而既然自主機器人是AI最終的歸屬,那更本質的要打造的產品,就是驅動這個自主機器人的大腦,就是處理器,或者更本質地說是計算架構。
這個本質問題的搞清楚,也能理解整個芯片半導體、信息計算產業的興衰規律。
按照經濟學的觀點說,需求決定了供應,經濟基礎決定了上層建筑。
這也是為什么一個時代會有一個時代的芯片,因為一個時代會有一個時代的計算架構。
既然神經網絡已經開啟了“機器像人一樣思考和計算”的變革,那固化執行人類思考和計算過程的架構,注定讓出中心地位,通用計算芯片也會逐漸失去主導權。
One more thing
這種無情的歷史變遷,也讓另一個知名類比更具現實骨感。
在AI浪潮洶涌的熱潮中,CPU一而再被質疑,一而再被挑戰,后來英特爾的高管給出了極具中國色彩的比喻——
“CPU是所有XPU平臺的中央神經系統,這就有點像中國人的主食米飯,別的XPU都是菜,不同地方的人喜歡不同的菜,但他們都需要和大米來搭配。”
這個類比,彼時彼刻,不得不承認既形象又巧妙。
只是比喻后來也跟此時此刻一樣精準:追求低碳水的新時代里,誰也沒想到,米飯竟然不再必要了。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10829瀏覽量
211196 -
神經網絡
+關注
關注
42文章
4765瀏覽量
100568 -
人工智能
+關注
關注
1791文章
46896瀏覽量
237670
原文標題:一個時代有一個時代的計算架構
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「大模型時代的基礎架構」閱讀體驗】+ 第一、二章學習感受
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
如何設計一個射頻收發機
大模型時代的算力需求
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
一個socket對應一個連接嗎
寧德時代調整組織架構,曾毓群親自掌舵制造與采購
AI時代的芯片革命:GPU、FPGA與TPU競相涌現
華為云函數工作流:引領未來無服務器計算時代

芯盾時代深度參編的行業標準《總體架構》即將施行

從一個錨點到一座港灣:華為加速“巨幕手機”時代到來






 工商網監
工商網監
評論