 全解GPU軟件生態、場景、發展與局限性
全解GPU軟件生態、場景、發展與局限性
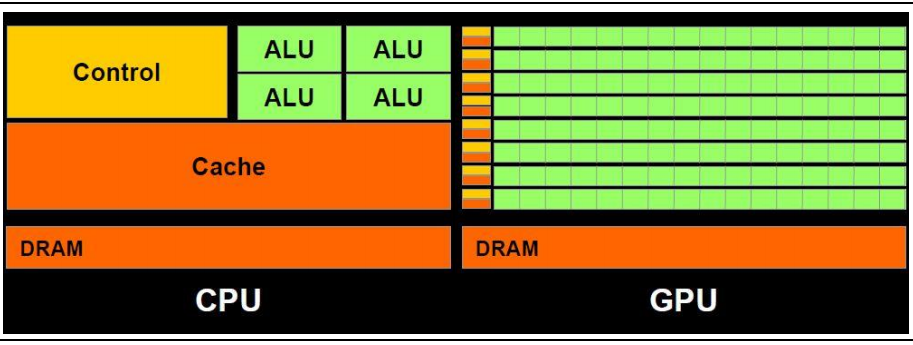
GPU作為一種協處理器,傳統用途主要是處理圖像類并行計算任務;計算機系統面對的計算任務有著復雜而不同的性能要求,當 CPU 無法滿足特定處理任務時,則需要一個針對性的協處理器輔助計算。GPU 就是針對圖像計算高并行度,高吞吐量,容忍高延遲而定制的并行處理器。
本文選自“從軟件算法生態看GPU發展與局限”,介紹GPU原理、GPU場景等,具體內容如下:
第一章、GPU 簡介1.1、GPU是什么? 1.2、為什么需要GPU等協處理器? 1.3、GPU還能干什么? 1.4、GPU不適合干什么? 1.5、GPU總體市場現狀第二章、GPU 未來面臨挑戰應用場景解析2.1 谷歌披露實用的全新人工智能專用協處理器:TPU 2.2 TPU 主要思路:針對人工智能算法需求裁剪計算精度 2.3 從谷歌 TPU 設計思路看人工智能硬件發展趨勢 2.4 GPU/FPGA 用于神經網絡計算的弱點:片上網絡第三章、GPU 未來較適應場景解析3.1 VR應用:持續增長的優勢領域 3.2 云計算/大數據應用
3.3 GPU,云和游戲服務結合
第一章、GPU簡介
GPU其原始設計針對圖像計算的特性進行優化,因此也能兼職一些與圖像計算特性接近的大規模并行標準浮點數計算任務,如科學計算與數值模擬。但大規模并行計算并非一個籠統的概念,而是一個可以按照計算性能需求在6個維度上進行細分的大類別。因此GPU絕非解決大規模并行計算問題的萬金油,無法很好的支持與圖形計算特性相差較大的并行計算任務。
1.1、GPU 是什么?
GPU其他名稱有顯示核心、視覺處理器、顯示芯片。顧名思義,GPU最主要的應用場景就是處理圖像顯示計算。計算機圖像顯示流程見圖,在這個過程中CPU決定了顯示內容,而GPU則決定了顯示的質量如何。像GPU這類輔助CPU完成特定功能芯片統稱“協處理器”,“協”字表明了GPU在計算機體系中處于從屬地位。
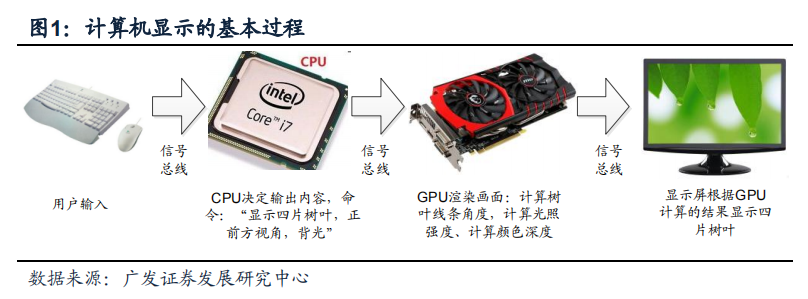
GPU芯片可根據與CPU的關系分為獨立GPU和集成GPU。獨立GPU通常圖形處理能力更高一些,但也有成本更高,功耗和發熱較大等問題。近年集成式GPU流行于移動計算平臺如筆記本和智能手機。例如高通的智能手機芯片通常將CPU和一個功能較弱的GPU以及其他協處理器通過SoC(System on Chip,片上系統)技術組合在一起。集成GPU圖形計算性能相對獨立GPU較弱但功耗/成本均針對了移動計算平臺的需求做了優化,將長期占據移動計算市場。

1.2、為什么需要 GPU 等協處理器?
在計算機系統中,之所以出現GPU等協處理器,歸根到底在于沒有一種芯片設計方案能夠滿足所有不同類別計算任務所需求的全部性能指標:
計算精度;
計算并行度;
計算延遲;
計算吞吐量;
并行進程之間的交互復雜度;
計算實時性要求;
魚和熊掌不可兼得;在設計計算機芯片中,以上六個指標不可能在有限的資源約束下同時滿足。圖的雷達圖比較了CPU的設計偏向(藍線)以及圖形計算的要求(紅線),越靠近外圈則表示要求高/性能好,如計算延遲低、計算吞吐量大。
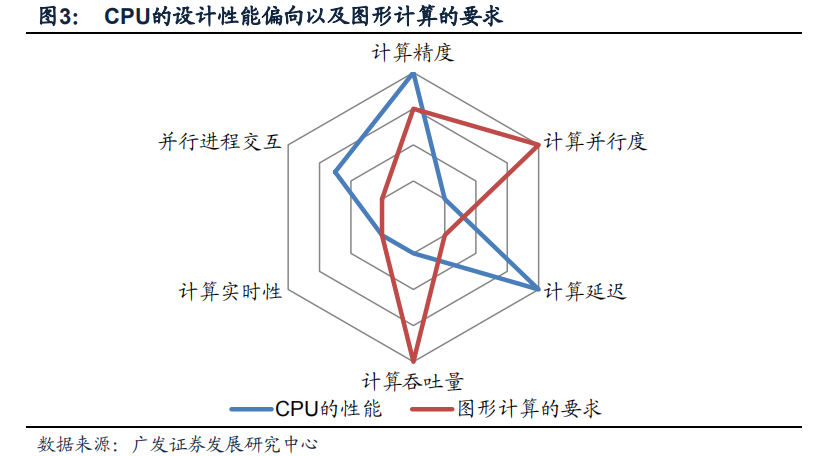
我們可以發現CPU設計的一部分偏好,如并行進程交互能力強,低計算延遲是圖形計算所不需要的;但圖形計算要求的高計算并行度,高計算吞吐量是CPU所不能提供的。將CPU應用在圖形處理中會造成一部分性能被浪費,而另一些性能CPU無法滿足要求(雷達圖上紅線和藍線的顯著差異);這提供了GPU這種針對圖形技術優化芯片性能指標的協處理器的生存空間。 在廣義計算系統體系中,其他類別的協處理器,如DSP,FPGA,BP等協處理器之所以獨立存在,均因為其所處理的特定計算任務在計算指標雷達圖中與CPU以及其他協處理器差異過大。一個協處理器產業是否有足夠的市場空間主要取決于其針對的計算任務在性能雷達圖中是否獨特(否則會被CPU等“兼職”),以及這種計算任務是否有足夠大市場需求。
1.3、GPU 還能干什么?
GPU生產廠商針對圖形處理的性能要求將資源分配強化兩個特定指標:計算并行度和計算吞吐量。除了圖形計算以外,還有一些計算任務的性能雷達圖落在GPU的性能范圍內或相差不甚太遠(見圖),比如數值仿真模擬、金融類計算、搜索引擎、數據挖掘等。

正因看中拓展GPU在特殊計算任務的應用前景,主流的GPU廠商紛紛推出軟硬件結合的并行編程解決方案。例如Nvidia推出閉源的CUDA并行計算平臺,而AMD推出了基于開放性OpenCL標準的Stream技術。這類技術在軟件上提供一個定制的編譯器,將計算任務盡可能分解成可獨立并行執行的小組件(術語為“線程”);在硬件上對GPU進行小幅度修改,少量提高其在延遲/并行交互等傳統弱項的性能。 雖然GPU的并行計算能力與金融數據處理需求存在一定匹配(圖4中紅線和藍線相近),但金融核心賬本計算中需要遠超過一般計算平臺的精度。GPU內部搭載的2進制計算單元無法保障賬本分毫不差;金融業的核心賬本計算業務長期依賴搭載10進制計算單元的IBM Power系列高端處理器。如果改造GPU使其搭載10進制硬件計算單元,則其又無法適應圖形計算的需求。這個案例充分說明:并非所有并行計算任務就一定適合GPU計算,而需要根據實際情況區分。
1.4、GPU 不適合干什么?
GPU屬于大規模并行計算芯片的一個子類;但其并不能解決所有的大規模并行計算任務。大規模并行計算芯片可粗略劃分為兩大組成部分:
1)并行計算單元,數目從數個至數千個不等,完成“線程”計算;
2)NoC(Network on Chip,片上通訊網絡),負責在計算單元之間傳遞數據; 針對不同的計算需求場景,大規模并行計算芯片的設計思路大體有兩個方向: 1)處理單元優化:包括增減處理器單元數量或改變處理器單元內部的結構等; 2)NoC網絡優化:更改網絡拓撲、網絡路由算法、優化網絡控制機制等; 這兩個方向上的優化需要分享芯片上有限的資源;強化一個方向的性能/增加某個方向的資源分配往往就意味著需要犧牲另一個方向的性能。 多核CPU、GPU、FPGA是常見的并行計算架構,它們的資源分配傾向示意圖見圖。
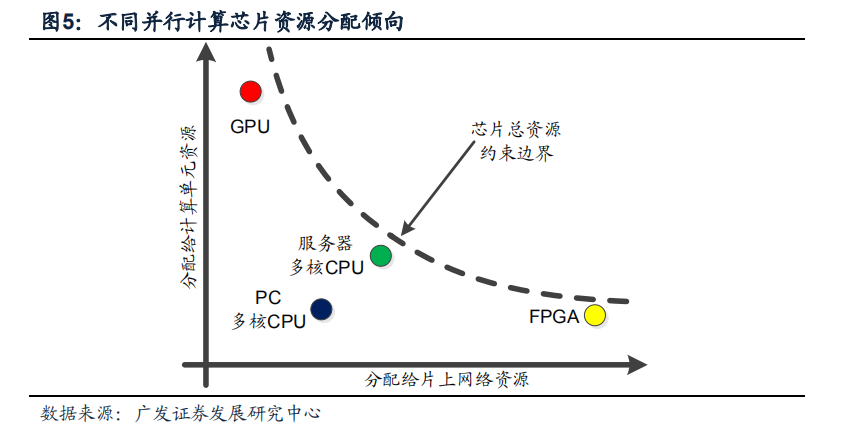
GPU將主要資源分配給了圖形常用計算單元,如浮點數的乘法和加法,而采用了最簡單的片上網絡拓撲:樹狀NoC網絡,在基本計算單元之間傳遞數據,見圖; 這種片上網絡的優缺點分別是:
優點1:消耗的資源最小;
缺點1:通過讀寫片上存儲的方式傳遞數據,速度較慢;
缺點2:樹根結點容易因通訊堵塞成為瓶頸,如圖中紅線和藍線分別表示A計算節點向B,C向D傳遞數據,兩個傳遞過程在根節點和二級共享節點交匯,當片上數據傳遞頻繁時,樹狀拓撲NoC極易發生堵塞問題。
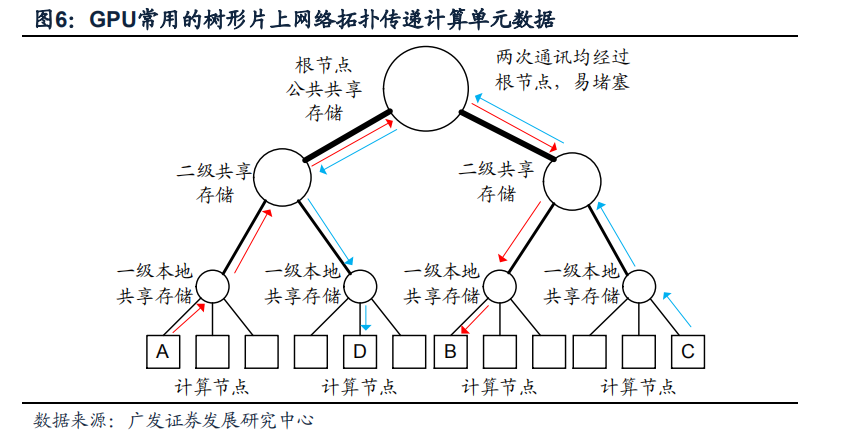
GPU之所以采用樹狀拓撲結構,概因其“主業”-圖形計算僅有少量情形需要在計算節點之間做復雜數據通信,因此采用樹狀拓撲以外的方案是純粹的浪費。但樹狀拓撲結構限制了相當多類別的大規模并行計算任務在GPU上發揮,換句話說,下列這些并行計算任務并不是GPU擴展的強項:
帶有較多分支判斷類的并行計算任務,典型任務如人機交互、電腦和環境交互中的邏輯判斷計算等;
并行計算中帶有較多串行成分,以及反饋算法的并行計算任務,典型例子如控制系統計算任務;
帶有網狀結構數據流的并行計算。典型案例為FFT(傅里葉分析)計算任務,CUDA中的FFT優化后可以提供相對CPU約10倍的提速,但當FFT長度超過某個門限后GPU的提升性能就發生下滑(資料來源:NV官網)。DSP芯片往往針對FFT的算法特性提供定制優化,沒有GPU存在的問題,因此手機SoC中往往由DSP而不是GPU處理FFT這種網狀大規模并行計算。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10825瀏覽量
211155 -
gpu
+關注
關注
28文章
4701瀏覽量
128707 -
計算機圖像
+關注
關注
2文章
5瀏覽量
2238
原文標題:全解GPU軟件生態、場景、發展與局限性
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于歐盟法規中測試場景的研究

直流輸電的優勢與局限性
微通道反應器目前的局限性
RISC-V在中國的發展機遇有哪些場景?
燈箱屏未來:技術突破與應用局限揭秘
FPGA的優勢及潛在局限性介紹

高光譜成像技術如何改善現有遙感技術的局限性?

超導材料在輸電領域的應用前景、優勢和局限性
GPU技術、生態及算力分析

新型全光開關可提高計算機處理器速度
探討碳化硅材料在制備晶圓過程中的關鍵技術和優勢





 工商網監
工商網監
評論