 介紹一種基于超異構計算的通用處理器GP-HPU
介紹一種基于超異構計算的通用處理器GP-HPU
本文章主要介紹綜合的、融合的基于超異構計算的通用處理器GP-HPU(General Purpose Hyper-heterogeneous Processing Unit)。
1 不同處理器類型的分類和協同
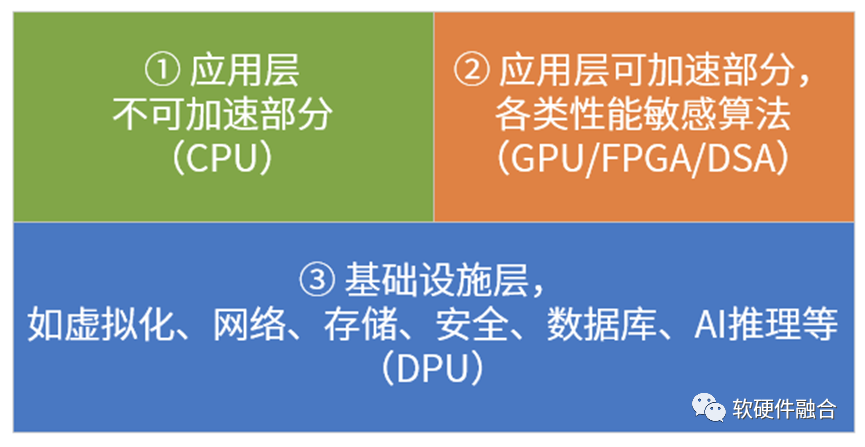
我目前有個基本的思考框架,來把各種PU進行劃分:系統是由分層分塊的模塊組成的,這樣我們可以大致上把系統分為三部分,如上圖所示。
各類PU分析如下:
CPU,中央處理器,是最核心的處理器。目前其他各種處理器,號稱取代CPU的核心地位,這些表述是不對的:你只是代替CPU干臟活累活,一切的控制和管理依然是CPU來完成。
各類加速器芯片。通過CPU+xPU的異構計算架構,如GPU、FPGA加速器、各類AI芯片(谷歌TPU、graphcore IPU、NPU、BPU等)以及其他各種加速芯片,這類芯片沒法單獨運行,需要有CPU的協作,構成CPU+xPU的異構計算的方式運行。
DPU。目前,大家對DPU的理解是,DPU主要負責系統I/O的處理。不管是網絡I/O還是遠程存儲I/O,都需要走網絡,因為DPU被不少人認為是I/O加速的處理器。更深一層的理解,是DPU是作為基礎設施處理器的存在,負責整個系統底層工作的處理。
SOC,系統級芯片。把整個系統的所有處理放在一個芯片里,有各種加速引擎負責性能敏感的工作任務,CPU負責一些基本任務的處理和整個系統的控制和管理。
不管叫什么PU,逃不開這四個類型。
2 場景特點:綜合、通用以及資源預備
許多AI芯片或系統落地面臨的一個主要問題是“我好不容易做了一盤餃子,可用戶需要的是一桌菜肴”。也即是說,客戶需要的是綜合性的系統解決方案,而AI只是其中的一部分,甚至非常小的一部分。
具體的終端應用場景包羅萬象,但云端和邊緣端,卻都是清一色的服務器來提供服務端的運行以及和終端的協同。這些服務器,可以服務各行各業、各種不同類型的場景的服務端工作任務的處理。云和邊緣服務器場景,需要考慮服務端系統的特點(微服務化功能持續解構,并且還和多租戶、多系統共存),對系統的靈活性的要求遠高于對性能的要求,需要提供的是綜合性的通用解決方案。
在云和邊緣數據中心,當CSP投入數以億計資金,上架數以萬計的各種型號、各種配置的服務器的時候,嚴格來說,它并不知道,具體的某臺服務器最終會售賣給哪個用戶,這個用戶到底會在服務器上面跑什么應用。并且,未來,這個用戶的服務器資源回收之后再賣個下一個用戶,下一個用戶又用來干什么,也是不知道的。
因此,對CSP來說,最理想的狀態是,存在一種服務器,足夠通用,即不管是哪種用戶哪種應用運行其上,都足夠高效快捷并且低成本。只有這樣,系統才夠簡單而穩定,運維才能簡單并且高效。然后要做的,就是把這種服務器大規模復制(大規模復制意味著單服務器成本的更快速下降)。
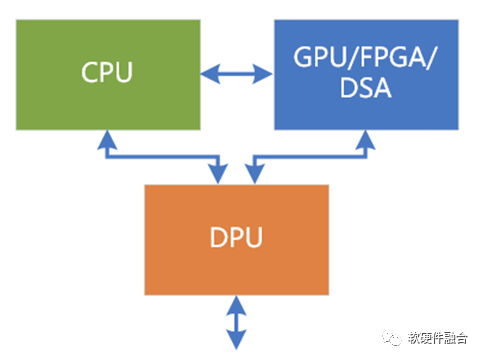
服務器都是相對通用,服務器上目前大芯片就三個位置,也就是我們通常所說的數據中心三大芯片的位置:CPU、業務加速的GPU以及基礎設施加速的DPU。大家要做的,就是自己芯片的定位,以及同其他各種廠家的各種芯片來競爭這三個位置。
有些專用的芯片,用在特定領域,需要設計專門的服務器,這種方案都流離在整個云和邊緣計算主流體系之外的,落地門檻很高,也很難大規模落地。
3 超異構處理器是什么?
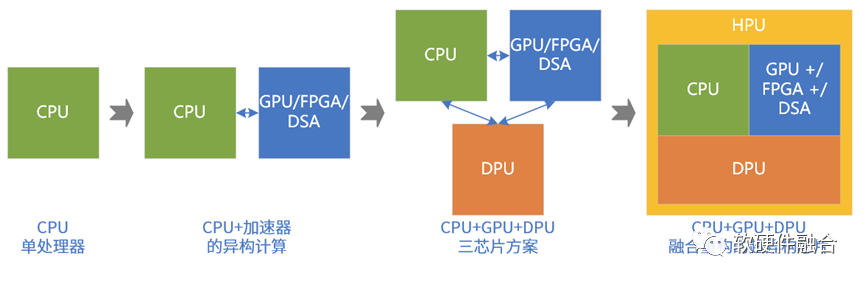
系統持續演進:
第一階段,性能要求不高,CPU能夠滿足要求。目前數據中心大量服務器依然是只有CPU處理器。
第二階段,性能敏感類任務大量出現,不得不進行異構加速。如AI訓練、視頻圖像處理,HPC等場景。這類場景,目前的狀況主要:NVIDIA GPU+CUDA為主流,FPGA FaaS非主流,AI類的DSA落地較少(包括谷歌TPU,也不算成功)。
第三階段。DPU的出現,CPU、GPU和DPU共同構成數據中心的三大處理芯片。
第四階段,再融合。
為什么不是獨立多芯片?為什么需要融合單芯片?融合單芯片是有諸多優勢的:
融合有利于計算的充分整合,進一步提升數據計算效率;
系統成本跟主要芯片的數量是直接相關的,融合型單芯片可以進一步降低成本;
融合系統,內部功能劃分和交互統一構建,相比三芯片方案,可以顯著降低彼此功能和交互的各種掣肘(相互拖累);
大部分(80%-90%)場景是相對輕量級場景,通過超異構的單芯片可以覆蓋其復雜度和系統規模;
Chiplet加持,可以通過多DIE單芯片的方式,實現重量級場景的覆蓋。
超異構處理器,可以認為是由CPU、GPU、各類DSA以及其他各類處理器引擎共同組成的,CPU、GPU和DPU整合重構的一種全系統功能融合的單芯片解決方案。
3.1 為什么叫超異構處理器?
首先,不能叫超融合處理器。超融合的概念是云計算領域一個非常重要的概念,大致意思是說在小規模集群能夠把云計算的IaaS層的服務以及云堆棧OS完整部署,可以提供給企業和私有云場景的云計算解決方案,并且因為和公用云堆棧OS是同一的體系,可以實現混合云的充分協同。
超異構處理器和超融合沒有必然聯系,可以支持小集群的超融合,也可以支持大集群的不“融合”。
NVIDIA對DPU的未來愿景:數據量越來越大,而數據在網絡中流動,計算節點也是靠數據的流動來驅動計算,計算的架構從以計算為中心轉向了以數據為中心。
所有的系統本質上就是數據處理,那么所有的設備就都可以是Data Processing Unit。所以,未來以DPU為基礎,不斷地融合CPU和GPU的功能,DPU會逐漸演化成數據中心統一的處理器(只是,目前沒有叫超異構HPU這個名字罷了)。
不管名稱具體叫什么,這個處理器,一定是基于多種處理引擎混合的(超異構計算)、面向宏系統場景的(MSOC,Micro-SOC)、數據驅動的(DPU,Data Processing),一個全新的處理器類型。
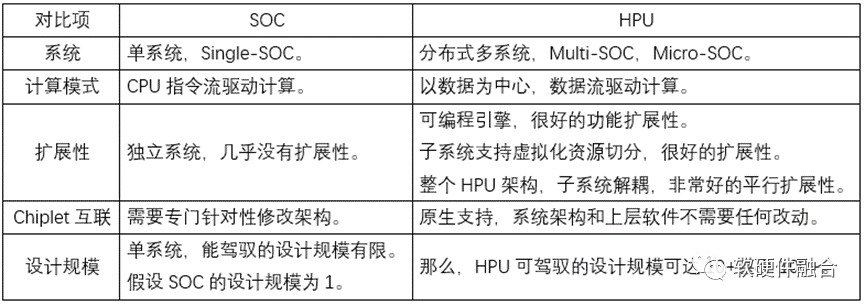
4 超異構處理器和傳統SOC的區別
嚴格來說,超異構處理器也是屬于SOC的范疇。但如果只是稱之為SOC,那無法體現超異構處理器和傳統SOC的本質區別。這樣,不利于我們深刻認識超異構處理器的創新價值所在,以及在支撐超異構處理器需要的創新技術和架構方面積極投入。
如下表格為超異構處理器和傳統SOC的對比:
5 超異構處理器,是否可以極致性能的同時,還足夠“通用”?
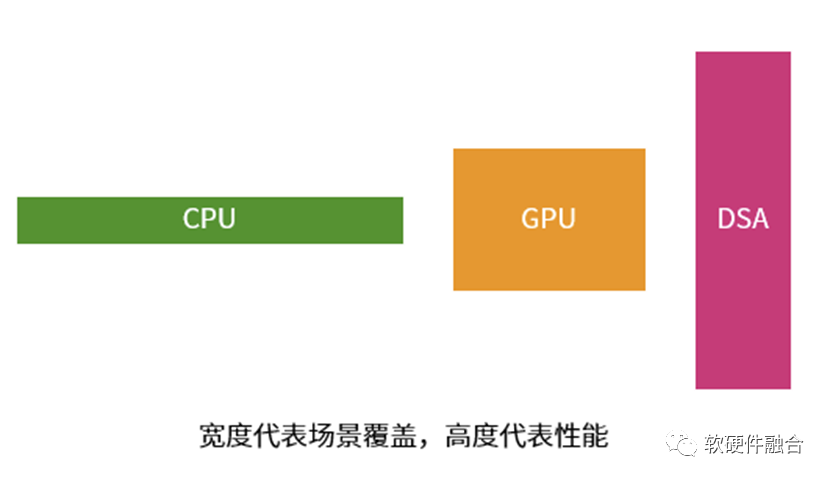
每一種處理器(引擎)都有其優勢,也都有其劣勢:
CPU非常通用,能夠干幾乎所有事情。但劣勢在于,其性能效率是最低的。
DSA的性能足夠好,劣勢在于只能覆蓋特定的領域場景,其它領域場景完全沒法用。
GPU,介于兩者之間。能夠覆蓋的領域場景比DSA多、比CPU少,性能比CPU好但比DSA差。
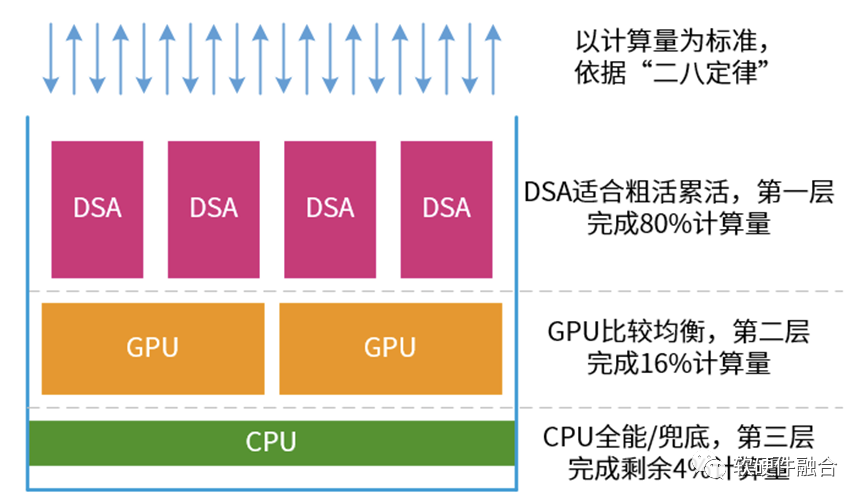
復雜的宏系統,存在“二八定律”。比如,在服務器上,永遠少不了的虛擬化、網絡、存儲、安全類的任務,以及很多服務器都需要的文件系統、數據庫、AI推理等。
因此,我們可以把系統計算當做一個塔防游戲:
在最前端,主要是各類DSA。他們的性能很好,負責處理算力需求強勁的任務。這些任務占整個計算量的80%。
中間是GPU,性能也不錯,覆蓋面也不錯。則負責處理剩余20%中的80%的計算量。
而CPU的任務,就是兜底。所有“漏網之魚”都由CPU負責處理。
這個思路,也對應我們第一部分介紹的系統的三類任務劃分。
按照這個思路,我們再通過一些軟硬件融合的系統設計,提供更多的通用性、靈活性、可編程性、易用性等能力,然后再不斷的集成新的性能敏感任務的加速。
基本上,這樣的通用超異構處理器,可以在提供極致性能兼極致靈活性的同時,可以覆蓋大部分云、邊緣和超級終端的場景。
6 超異構處理器可以用在哪里?
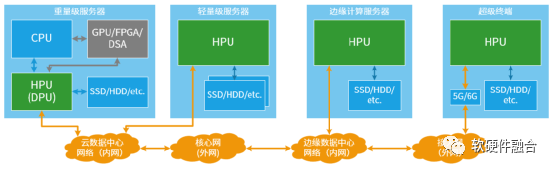
超異構處理器HPU相比傳統SOC,最核心的特點是宏系統,需要支持虛擬化和多租戶多系統共存,需要支持資源、數據和性能隔離。
因此,超異構處理器主要用在云計算、邊緣計算以及自動駕駛超級終端等復雜計算場景:
云端重量級服務器。首先,HPU可以當做DPU來使用;更長遠的,可以通過Chiplet方式實現HPU對重量級場景的覆蓋。
云端輕量級服務器。可以實現HPU單芯片對目前以CPU為主的多個芯片的集成,并且性能顯著提升。
邊緣計算服務器。類似云端輕量服務器,可以通過單芯片集成的HPU實現所有計算的全覆蓋。
超級終端。以自動駕駛為典型場景,目前也是逐漸地從分布式的ECU、DCU向集中式的超級終端單芯片轉變。這將是HPU在終端場景的典型應用。
總結一下,超異構處理器的核心價值在于確保整個系統如CPU一樣極致靈活性的同時,還可以提供相比目前主流芯片數量級的算力提升。可以用在云計算、邊緣計算、超級終端等各類復雜計算場景。
系統越復雜,超異構處理器的價值越凸顯!
審核編輯:編輯:劉清
-
處理器
+關注
關注
68文章
19160瀏覽量
229115 -
FPGA
+關注
關注
1626文章
21665瀏覽量
601814 -
加速器
+關注
關注
2文章
795瀏覽量
37756 -
NPU
+關注
關注
2文章
269瀏覽量
18543
原文標題:一種新的處理器類型:通用超異構處理器
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中國首個異構計算處理器IP核實現 可用于機器學習
異構計算的前世今生
異構計算在人工智能什么作用?
基于FPGA的異構計算是趨勢
異構計算的兩大派別 為什么需要異構計算?
異構計算:架構與技術
異構計算,你準備好了么?

異構計算真就完美無缺嗎
基于超異構計算的通用處理器GP-HPU介紹
異構計算面臨的挑戰和未來發展趨勢

新一代計算架構超異構計算技術是什么 異構走向超異構案例分析






 工商網監
工商網監
評論