 小編科普一下超標量處理器中的Cache
小編科普一下超標量處理器中的Cache
超標量處理器中,Cache和分支預測會直接影響著性能,分支預測的內容將在其它博文中介紹,本文重點關注超標量處理器中的Cache。
Cache之所以存在,是因為存儲器的速度遠遠滯后于處理器的速度,人們觀察到在計算機的世界中,存在如下的兩個現象:
時間相關性(temporal locality):如果一個數據現在被訪問了,那么以后很有可能也會被訪問;
空間相關性(spatial locally):如果一個數據現在被訪問了,那么它周圍的數據在以后可能也會被訪問;
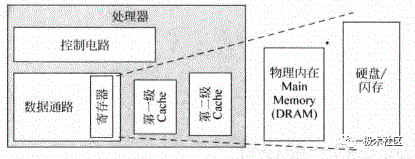
處理器中的各種cache示意如圖1所示,現代超標量處理器都是哈佛結構,為了增加流水線的執行效率,L1 Cache一般都包括兩個物理的存在,指令Cache(I-Cache)和數據Cache(D-Cache),本質上兩者是一樣的,I-Cache只會發生讀情況,D-Cahce既可以讀也可以寫,所以更復雜點,L1 Cach緊密耦合在處理器的流水線中,主打功能就是求快。
L2通常是指令和數據共享,它和處理器的速度不必保持同樣,可以容忍慢點,它存在的主要意義是盡量保存更多的內容,即求全。
在L1 Cache miss的情況下,會去訪問L2 Cache,加入L2 Cache在缺失時去訪問物理內存(一般是DRAM),這個訪問時間很長,因此要盡可能地提高L2 Cache的命中率。
L1 Cache和L2 Cache是和處理器聯系最緊密的,通常采用SRAM實現。物理主存Main memory通常是采用DRAM實現的。
再往下就是硬盤(Disk)和閃存(Flash)。層層嵌套,CPU擁有存儲器相當于硬盤的大小和SRAM的速度。
L1 Cache和L2 Cache通常和處理器是在一塊實現的。
在SoC中,主存和處理器之間通過總線SYSBUS連接起來。
 ?
?
圖1 處理器中的各種Cache
Cache主要由兩部分組成,Tag部分和Data部分。因為Cache是利用了程序中的相關性,一個被訪問的數據,它本身和它周圍的數據在最近都有可能被訪問,因此Data部分就是用來保存一片連續地址的數據,而Tag部分則是存儲著這片連續地址的公共地址,一個Tag和它對應的所有數據Data組成一行稱為Cache line,而Cache line中的數據部分成為數據塊(Cache data block,也稱做Cache block或Data block)。
如果一個數據可以存儲在Cache的多個地方,這些被同一個地址找到的多個Cache line稱為Cache set。
以上關系如圖2所示。
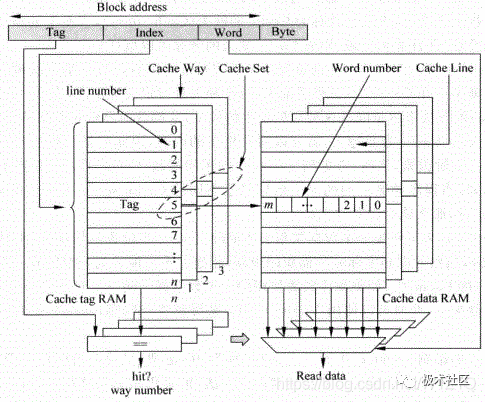
圖2 Cache的結構
圖2中只表示了一種可能的實現方式,在實際當中,Cache有三種主要的實現方式,直接映射(direct-mapped)Cache,組相連(set-associative)Cache和全相連(full-associative)Cache,實現原理如圖3所示。
對于物理內存(physical memory)中的一個數據來說,如果在Cache中只有一個地方可以容納它,它就是直接映射的Cache;如果Cache中有多個地方可以放置這個數據,它就是組相連的Cache;如果Cache中任何的地方都可以放置這個數據,那么它就是全相連的Cache。可以看出,直接映射和全相連映射這兩種結構的Cache實際上是組相連Cache的兩種特殊情況,現代處理器中的Cache一般屬于上述三種方式的一種,例如TLB和Victim Cache多采用全相連結構,而普通的I-Cache和D-Cache則采用組相連結構等。
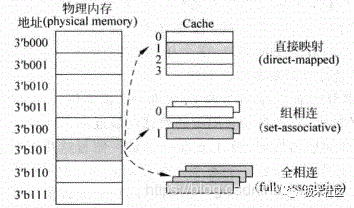
圖3 Cache的三種實現方式
1. Cache的組成方式
1.1 直接映射
直接映射結構的Cache是最容易實現的一種方式,處理器訪問存儲器的地址會被分為三部分:Tag、Index和Block Offset。
如圖4所示,使用Index來從Cache中找到一個對應的Cacheline,但是所有Index相同的地址都會尋址到這個Cacheline,因此在Cacheline中還有Tag部分,用來和地址中的Tag進行比較,只有它們相等才表明這個Cacheline就是想要的那個。
在一個Cacheline中有很多數據,通過存儲器地址中的Block Offset部分可以找到真正想要的數據,它可以定位到每個字節。
在Cacheline中還有一個有效位(Valid),用來標記這個Cacheline是否保存著有效的數據,只有在之前被訪問過的存儲器地址,它的數據才會存在于對應的Cacheline中,相應的有效位也會被置為1。
直接映射有個缺點,就是對于所有Index相同的存儲器地址,都會尋址到同一個Cacheline,如果兩個Index部分相同的存儲器地址交互地訪問Cache,就會一直導致Cache缺失,嚴重地降低了處理器的執行效率。
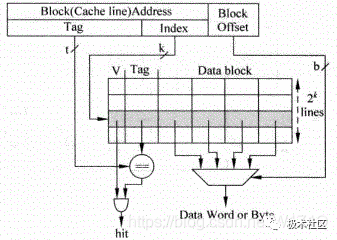
圖4 直接映射Cache
1.2 組相連
組相連的方式是為了解決直接映射結構Cache的不足而提出的,存儲器中的一個數據不單單只能放在一個Cacheline中,而是可以放在多個Cacheline中,對于一個組相連結構的Cache來說,如果一個數據可以放在n個位置,則稱這個Cache是n路組相連的Cache(n way set-associative Cache),圖5為一個兩路組相連Cache的原理圖。
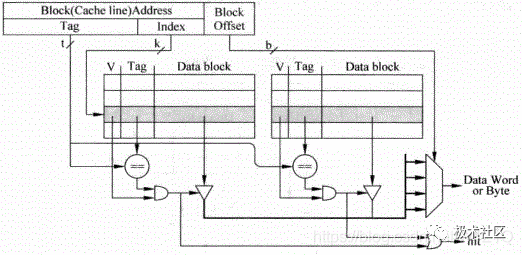
圖5 2路組相連映射Cache
這種結構仍舊使用存儲器地址的Index部分對Cache進行尋址,此時可以得到兩個Cacheline,這兩個Cacheline稱為一個Cache set,究竟哪個Cacheline才是最終需要的,是根據Tag比較的結果來確定的,如果兩個Cacheline的Tag比較結果都不相等,那么就說明這個存儲器地址對應的數據不在Cache中,也就是發生了Cache缺失。
這種方式在實際處理器中應用最為廣泛,上面提到的Tag部分和Data部分都是分開放置的,稱為Tag SRAM和Data SRAM,可以同時訪問這兩部分。
圖5所示為并行訪問,如果先訪問Tag SRAM部分,根據Tag比較的結果再去訪問Data SRAM部分,就稱為串行訪問。
圖6為并行訪問方法的示意圖,對于并行訪問的結構,當某個地址的Tag部分被讀取的同時,這個地址在Data部分對應的所有數據也會被讀取出來,并送到一個多路選擇器,這個多路選擇器受到Tag部分比較結果的控制,選出對應的Data block,然后根據存儲器地址中Block Offset的值,選擇出合適的字節,一般將選擇字節的這個過程稱為數據對齊(Data Alignment)。 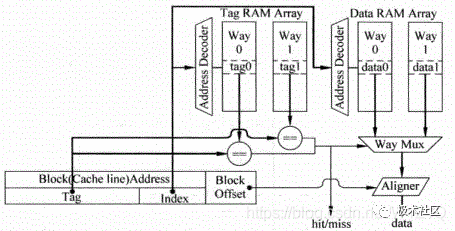
圖6 并行訪問Cache中的Tag和Data部分
如圖7為串行訪問實現方式,對于串行訪問方法來說,首先對Tag SRAM進行訪問,根據Tag比較的結果,就可以知道數據部分中,哪一路的數據時需要被訪問的,此時可以直接訪問這一路的數據,這樣就不在需要圖6中的多路選擇器,而且,只需要訪問數據部分指定的那個SRAM,其它的SRAM由于都不需要被訪問,可以將它們的使能信號置為無效,這樣可以節省很多功耗,當然串行訪問在延遲上會更大。
圖7 串行訪問Cache中的Tag部分和Data部分
1.3 全相連
在全相連中,一個存儲器地址的數據可以放在任何一個cacheline中,如圖8所示,存儲器地址中將不再有Index部分,而是直接在整個的Cache中進行Tag值比較,找到比較結果相等的那個Cache line,這種方式相當于直接使用存儲器的內容來尋址,從存儲器中找到匹配的項,這其實就是內容尋址的存儲器( Content Address Memory, CAM),實際當中的處理器在使用全相連結構的Cache時,都是使用CAM來存儲Tag值,使用普通的SRAM來存儲數據的。
當CAM中的某一行被尋址到時,SRAM中對應的行(一般稱為word line)也將會被找到,從而SRAM可以直接輸出對應的數據。
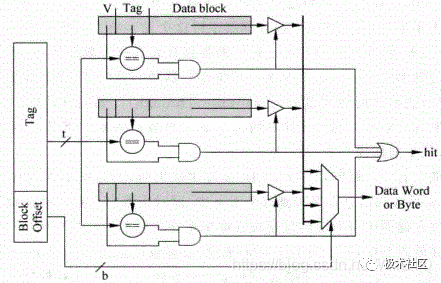
圖8 全相連
2. Cache的寫入
2.1 寫通和寫回
對于D-Cache來說,它的寫操作和讀操作有所不同,當執行一條store指令時,如果只是向D-Cache中寫入數據,而并不改變它的下級存儲器中的數據,這樣就會導致D-Cache和下級存儲器中,對于這一個地址有著不同的數據,這稱作不一致(non-consistent)。
要想保持它們的一致性,最簡單的方式就是當數據在寫到D-Cache的同時,也寫到它的下級存儲器中,這種寫入方式稱為寫通(Write Through)。
由于D-cache的下級存儲器需要的訪問時間相對是比較長的,而store指令在程序中出現的頻率又比較高,如果每次執行store指令時,都向這樣的慢速存儲器中寫入數據,處理器的執行效率肯定不會很高了。
如果在執行store指令時,數據被寫到D-Cache后,只是將被寫入的Cacheline做一個記號,并不將這個數據寫到更下級的存儲器中,只有當Cache中這個被標記的line要被替換時,才將它寫到下級存儲器中,這種方式就稱為 寫回(Write Back),被標記的記號在計算機術語中稱為臟(dirty)狀態,很顯然,這種方式可以減少寫慢速存儲器的頻率,從而獲得比較好的性能。
當然,這種方式會造成D-Cache和下級存儲器中有很多地址中的數據是不一致的,這會給存儲器的一致性管理帶來一定的負擔。
2.2 Non-Write Allocate和Write Allocate
上面所講述的情況都是假設在寫D-Cache時,要寫入的地址總是D-Cache中存在的,而實際當中,有可能發現這個地址并不在D-Cache中,這就發生了寫缺失(write miss),此時最簡單的處理方法就是將數據直接寫到下級存儲器中,而并不寫到D-Cache中,這種方式稱為Non-Write Allocate。
與之相對應的方法就是Write Allocate,在這種方法中,如果寫Cache時發生了缺失,會首先從下級存儲器中將這個發生缺失的地址對應的整個數據塊(data block)取出來,將要寫入到D-Cache中的數據合并到這個數據塊中,然后將這個被修改過的數據塊寫到D-Cache中。
如果為了保持存儲器的一致性,將這個數據塊也寫到下級存儲器中,這種方法就是上小節說過的寫通(Write Through)。
如果只是將D-Cache中對應的line標記為臟(Dirty)的狀態,只有等到這個line要被替換時,才將其寫回到下級存儲器中,則這種方法就是前面提到的寫回(Write Back)。
Write Allocate為什么在寫缺失時,要先將缺失地址對應的數據塊從下級存儲器中讀取出來,然后在合并后寫到Cache中?
因為通常對于寫D-Cache來說,最多也就是寫入一個字,直接寫入Cache的話,會造成數據塊中的其它部分和下級存儲器中對應的數據不一致,且是無效的,如果這個cacheline由于被替換而寫回到下級存儲器中時,就會使下級存儲器中的正確數據被篡改。
通過上面的描述可以看出,對于D-Cache來說,一般情況下,寫通(Write Through)總是配合Non-Write Allocate一起使用的,它們都是直接將數據更新到下級存儲器中,這兩種方法配合的工作流程如圖9所示。 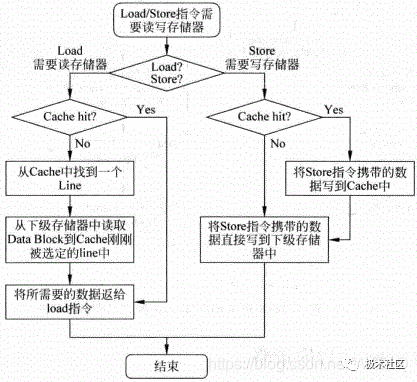
圖9 Write Through和Non-Write Allocate兩種方法配合工作的流程圖
在D-Cache中,寫回(Write back)的方法和Write Allocate也是配合在一起使用的,它的工作流程如圖10所示。

圖10 Write back和Write Allocate配合工作的流程圖
由圖10可以看出,在D-Cache中采用寫回(Write back)的方法時,不管是讀取還是寫入時發生缺失,都需要從D-Cache中找到一個line來存放新的數據,這個被替換的line如果此時是臟(dirty)狀態,那么首先需要將其中的數據寫回到下級存儲器中,然后才能夠使用這個line存放新的數據。
也就是說,當D-Cache中被替換的line是臟的狀態時,需要對下級存儲器進行兩次訪問,首先需要將這個line中的數據寫回到下級存儲器,然后需要從下級存儲器中讀取缺失的地址對應的數據塊,并將其寫到剛才找到的Cache line中。
對于D-Cache來說,還需要將寫入的數據也放到這個line中,并將其標記為臟的狀態。
從圖9和圖10可以看出,采用寫回和Write Allocate配合工作的方法,其設計復雜度要高于寫通和Non-Write Allocate配合工作的方法,但是它可以減少寫下級存儲器的頻率,從而使處理器獲得比較好的性能。
3. Cache的替換策略
在一個Cache Set內的所有line都已經被占用的情況下,如果需要存放從下游存儲器中讀過來的其它地址的數據,那么就需要從其中替換一個,如何從這些有效的Cache line找到一個并替換之,這就是替換(Cache replacement)策略。本節主要介紹幾種最常用的替換算法。
3.1 近期最少使用法
近期最少使用法(Least Recently Used, LRU)會選擇最近被使用次數最少的Cache line,因此這個算法需要追蹤每個Cache line的使用情況,這需要為每個Cache line都設置一個年齡(age)部分,每次當一個Cache line被訪問時,它對應的年齡部分就會增加,或者減少其它Cache line的年齡值,這樣當進行替換時,年齡值最小的那個Cacheline就是被使用次數最少的了,會選擇它進行替換。
圖11為LRU算法的工作流程。
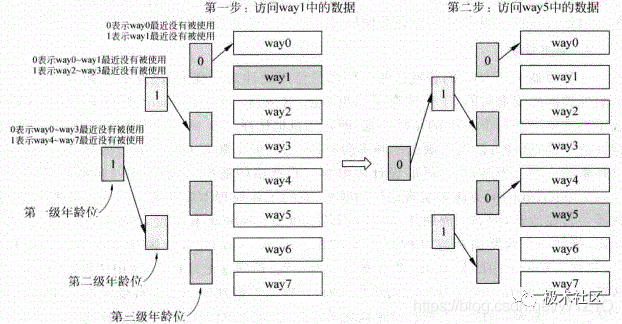
圖11 LRU算法的工作流程
3.2 替換策略
在處理器中,Cache的替換算法一般都是使用硬件來實現的,因此如果做得很復雜,會影響處理器的周期時間,于是就有了隨機替換(Random Replacement)的實現方法,這種方法不再需要記錄每個way的年齡信息,而是隨機地選擇一個way進行替換,相比于LRU替換方法來說,這種方法確實的頻率會更高一些,但是隨著Cache容量的增大,這個差距是越來越小的。
當然,在實際的設計中很難實現嚴格的隨機,一般采用一種稱為時鐘算法(Clock algorithm)的方法來實現近似的隨機,它的工作原理本質上就是一個計數器,這個計數器一直在運轉,例如每周期加1,計數器的寬度由Cache的相關度,也就是way的個數來決定,例如一個八路組相連的結構的Cache,則計數器的寬度需要三位,每次當Cache中的某個line需要被替換時,就會訪問這個計數器,使用計數器當前的值,從被選定的Cache Set中找到要替換的line,這樣就近似地實現了一種隨機的替換,這種方法從理論上來說,可能并不能獲得最優化的結果,但是它的硬件復雜度比較低,也不會損失過多的性能,因此綜合來看是一種不錯的折中方法。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19159瀏覽量
229115 -
存儲器
+關注
關注
38文章
7452瀏覽量
163598 -
TLB電路
+關注
關注
0文章
9瀏覽量
5248 -
SRAM芯片
+關注
關注
0文章
65瀏覽量
12048
原文標題:學習分享|CPU Cache知識
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是超標量處理器的流水線?超標量處理器的特點有哪些?
什么是超標量技術/FADD?
PowerPC芯片特點及超標量體系CPU優化技術
亂序超標量處理器核的功耗優化





 工商網監
工商網監
評論