") 為什么在JVM中線程崩潰不會導(dǎo)致JVM進(jìn)程崩潰呢?
為什么在JVM中線程崩潰不會導(dǎo)致JVM進(jìn)程崩潰呢?
線程崩潰,進(jìn)程一定會崩潰嗎
一般來說如果線程是因為非法訪問內(nèi)存引起的崩潰,那么進(jìn)程肯定會崩潰,為什么系統(tǒng)要讓進(jìn)程崩潰呢,這主要是因為在進(jìn)程中,各個線程的地址空間是共享的 ,既然是共享,那么某個線程對地址的非法訪問就會導(dǎo)致內(nèi)存的不確定性,進(jìn)而可能會影響到其他線程,這種操作是危險的,操作系統(tǒng)會認(rèn)為這很可能導(dǎo)致一系列嚴(yán)重的后果,于是干脆讓整個進(jìn)程崩潰
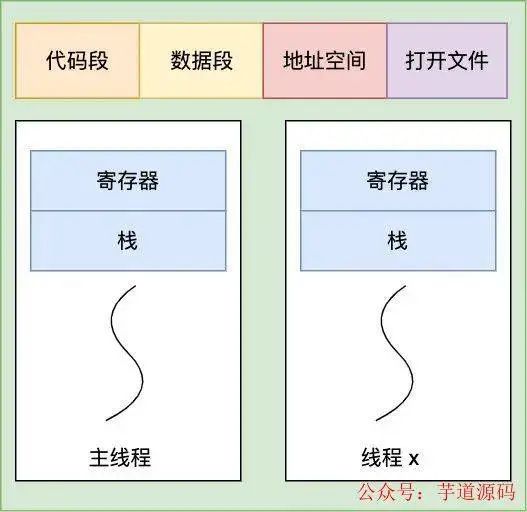
線程共享代碼段,數(shù)據(jù)段,地址空間,文件
非法訪問內(nèi)存有以下幾種情況,我們以 C 語言舉例來看看
針對只讀內(nèi)存寫入數(shù)據(jù)
#include#include intmain(){ char*s="helloworld";
//向只讀內(nèi)存寫入數(shù)據(jù),崩潰 s[1]='H'; }
訪問了進(jìn)程沒有權(quán)限訪問的地址空間(比如內(nèi)核空間)
#include#include intmain(){ int*p=(int*)0xC0000fff;
//針對進(jìn)程的內(nèi)核空間寫入數(shù)據(jù),崩潰 *p=10; }
在 32 位虛擬地址空間中,p 指向的是內(nèi)核空間,顯然不具有寫入權(quán)限,所以上述賦值操作會導(dǎo)致崩潰
訪問了不存在的內(nèi)存,比如
#include#include intmain(){ int*a=NULL; *a=1; }
以上錯誤都是訪問內(nèi)存時的錯誤,所以統(tǒng)一會報 Segment Fault 錯誤(即段錯誤),這些都會導(dǎo)致進(jìn)程崩潰
基于 Spring Boot + MyBatis Plus + Vue & Element 實現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
進(jìn)程是如何崩潰的-信號機制簡介
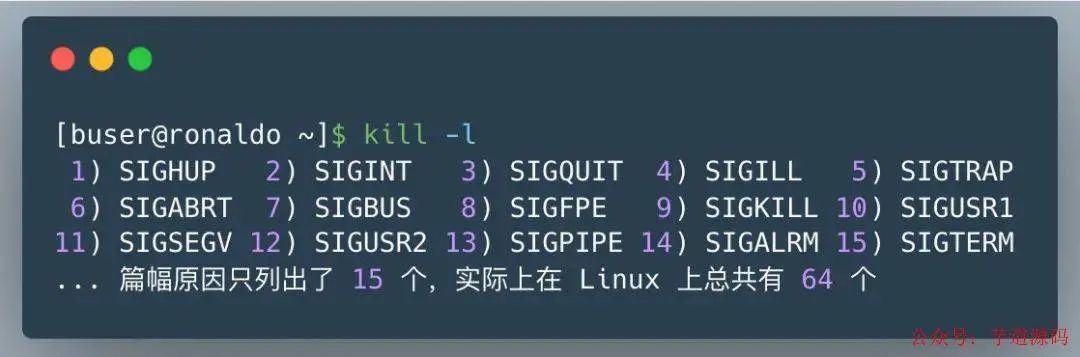
那么線程崩潰后,進(jìn)程是如何崩潰的呢,這背后的機制到底是怎樣的,答案是信號 ,大家想想要干掉一個正在運行的進(jìn)程是不是經(jīng)常用 kill -9 pid 這樣的命令,這里的 kill 其實就是給指定 pid 發(fā)送終止信號的意思,其中的 9 就是信號,其實信號有很多類型的,在 Linux 中可以通過 kill -l查看所有可用的信號
當(dāng)然了發(fā) kill 信號必須具有一定的權(quán)限,否則任意進(jìn)程都可以通過發(fā)信號來終止其他進(jìn)程,那顯然是不合理的,實際上 kill 執(zhí)行的是系統(tǒng)調(diào)用,將控制權(quán)轉(zhuǎn)移給了內(nèi)核(操作系統(tǒng)),由內(nèi)核來給指定的進(jìn)程發(fā)送信號
那么發(fā)個信號進(jìn)程怎么就崩潰了呢,這背后的原理到底是怎樣的?
其背后的機制如下
CPU 執(zhí)行正常的進(jìn)程指令
調(diào)用 kill 系統(tǒng)調(diào)用向進(jìn)程發(fā)送信號
進(jìn)程收到操作系統(tǒng)發(fā)的信號,CPU 暫停當(dāng)前程序運行,并將控制權(quán)轉(zhuǎn)交給操作系統(tǒng)
調(diào)用 kill 系統(tǒng)調(diào)用向進(jìn)程發(fā)送信號(假設(shè)為 11,即 SIGSEGV,一般非法訪問內(nèi)存報的都是這個錯誤)
操作系統(tǒng)根據(jù)情況執(zhí)行相應(yīng)的信號處理程序(函數(shù)),一般執(zhí)行完信號處理程序邏輯后會讓進(jìn)程退出
注意上面的第五步,如果進(jìn)程沒有注冊自己的信號處理函數(shù),那么操作系統(tǒng)會執(zhí)行默認(rèn)的信號處理程序(一般最后會讓進(jìn)程退出),但如果注冊了,則會執(zhí)行自己的信號處理函數(shù),這樣的話就給了進(jìn)程一個垂死掙扎的機會,它收到 kill 信號后,可以調(diào)用 exit() 來退出,但也可以使用 sigsetjmp,siglongjmp 這兩個函數(shù)來恢復(fù)進(jìn)程的執(zhí)行
//自定義信號處理函數(shù)示例 #include#include #include //自定義信號處理函數(shù),處理自定義邏輯后再調(diào)用exit退出 voidsigHandler(intsig){ printf("Signal%dcatched! ",sig); exit(sig); } intmain(void){ signal(SIGSEGV,sigHandler); int*p=(int*)0xC0000fff; *p=10;//針對不屬于進(jìn)程的內(nèi)核空間寫入數(shù)據(jù),崩潰 } //以上結(jié)果輸出:Signal11catched!
如代碼所示 :注冊信號處理函數(shù)后,當(dāng)收到 SIGSEGV 信號后,先執(zhí)行相關(guān)的邏輯再退出
另外當(dāng)進(jìn)程接收信號之后也可以不定義自己的信號處理函數(shù),而是選擇忽略信號,如下
#include#include #include intmain(void){ //忽略信號 signal(SIGSEGV,SIG_IGN); //產(chǎn)生一個SIGSEGV信號 raise(SIGSEGV); printf("正常結(jié)束"); }
也就是說雖然給進(jìn)程發(fā)送了 kill 信號,但如果進(jìn)程自己定義了信號處理函數(shù)或者無視信號就有機會逃出生天,當(dāng)然了 kill -9 命令例外,不管進(jìn)程是否定義了信號處理函數(shù),都會馬上被干掉
說到這大家是否想起了一道經(jīng)典面試題:如何讓正在運行的 Java 工程的優(yōu)雅停機,通過上面的介紹大家不難發(fā)現(xiàn),其實是 JVM 自己定義了信號處理函數(shù),這樣當(dāng)發(fā)送 kill pid 命令(默認(rèn)會傳 15 也就是 SIGTERM)后,JVM 就可以在信號處理函數(shù)中執(zhí)行一些資源清理之后再調(diào)用 exit 退出。這種場景顯然不能用 kill -9,不然一下把進(jìn)程干掉了資源就來不及清除了
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現(xiàn)的后臺管理系統(tǒng) + 用戶小程序,支持 RBAC 動態(tài)權(quán)限、多租戶、數(shù)據(jù)權(quán)限、工作流、三方登錄、支付、短信、商城等功能
為什么線程崩潰不會導(dǎo)致 JVM 進(jìn)程崩潰
現(xiàn)在我們再來看看開頭這個問題,相信你多少會心中有數(shù),想想看在 Java 中有哪些是常見的由于非法訪問內(nèi)存而產(chǎn)生的 Exception 或 error 呢,常見的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我們都了解,屬于是訪問了不存在的內(nèi)存
但為什么棧溢出(Stackoverflow)也屬于非法訪問內(nèi)存呢,這得簡單聊一下進(jìn)程的虛擬空間,也就是前面提到的共享地址空間
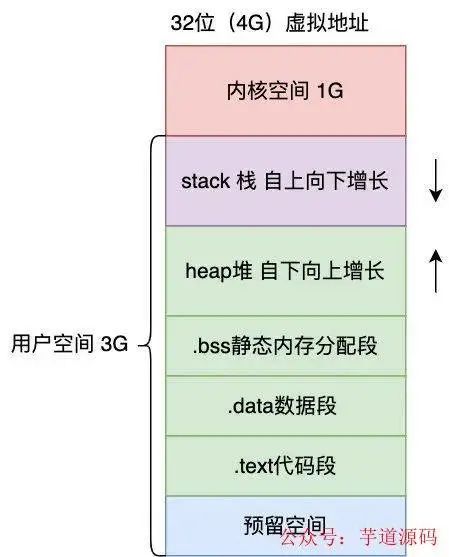
現(xiàn)代操作系統(tǒng)為了保護進(jìn)程之間不受影響,所以使用了虛擬地址空間來隔離進(jìn)程,進(jìn)程的尋址都是針對虛擬地址,每個進(jìn)程的虛擬空間都是一樣的,而線程會共用進(jìn)程的地址空間,以 32 位虛擬空間,進(jìn)程的虛擬空間分布如下
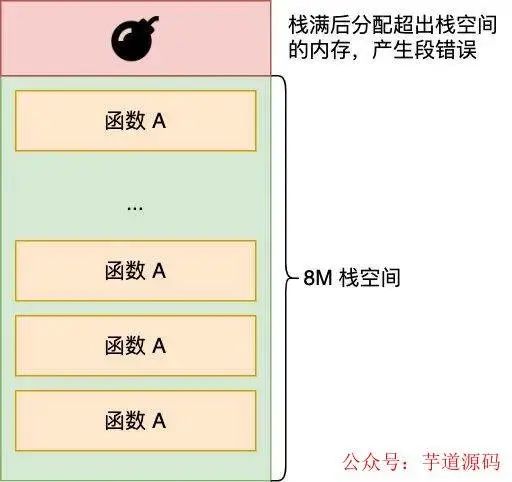
那么 stackoverflow 是怎么發(fā)生的呢,進(jìn)程每調(diào)用一個函數(shù),都會分配一個棧楨,然后在棧楨里會分配函數(shù)里定義的各種局部變量,假設(shè)現(xiàn)在調(diào)用了一個無限遞歸的函數(shù),那就會持續(xù)分配棧幀,但 stack 的大小是有限的(Linux 中默認(rèn)為 8 M,可以通過 ulimit -a 查看),如果無限遞歸很快棧就會分配完了,此時再調(diào)用函數(shù)試圖分配超出棧的大小內(nèi)存,就會發(fā)生段錯誤,也就是 stackoverflowError
好了,現(xiàn)在我們知道了 StackoverflowError 怎么產(chǎn)生的,那問題來了,既然 StackoverflowError 或者 NPE 都屬于非法訪問內(nèi)存, JVM 為什么不會崩潰呢,有了上一節(jié)的鋪墊,相信你不難回答,其實就是因為 JVM 自定義了自己的信號處理函數(shù),攔截了 SIGSEGV 信號,針對這兩者不讓它們崩潰,怎么證明這個推測呢,我們來看下 JVM 的源碼來一探究竟
openJDK 源碼解析
HotSpot 虛擬機目前使用范圍最廣的 Java 虛擬機,據(jù) R 大所述, Oracle JDK 與 OpenJDK 里的 JVM 都是 HotSpot VM,從源碼層面說,兩者基本上是同一個東西,OpenJDK 是開源的,所以我們主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u,有興趣的可以下載來看看
我們只要研究 Linux 下的 JVM,為了便于說明,也方便大家查閱,我把其中關(guān)于信號處理的關(guān)鍵流程整理了下(忽略其中的次要代碼)
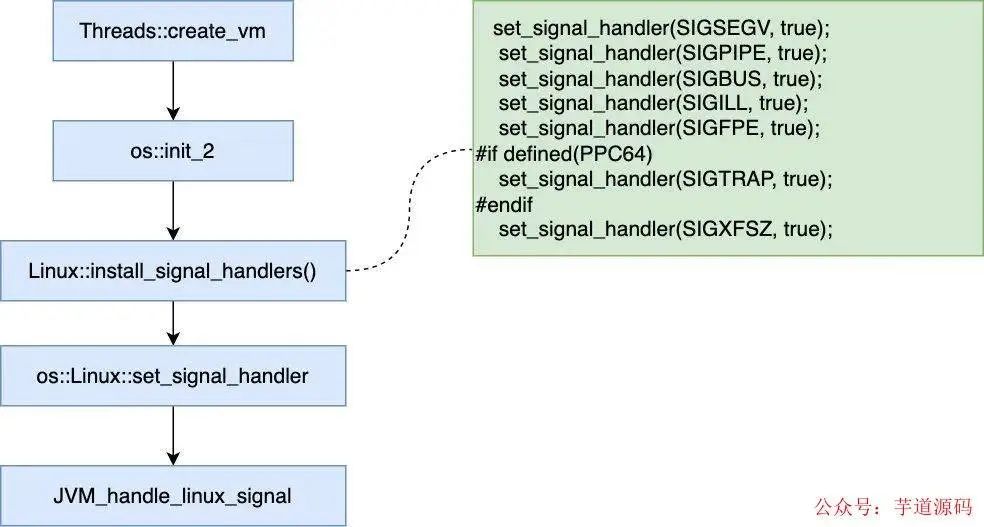
可以看到,在啟動 JVM 的時候,也設(shè)置了信號處理函數(shù),收到 SIGSEGV,SIGPIPE 等信號后最終會調(diào)用 JVM_handle_linux_signal 這個自定義信號處理函數(shù),再來看下這個函數(shù)的主要邏輯
JVM_handle_linux_signal(intsig,
siginfo_t*info,
void*ucVoid,
intabort_if_unrecognized){
//MustdothisbeforeSignalHandlerMark,ifcrashprotectioninstalledwewilllongjmpaway
//這段代碼里會調(diào)用siglongjmp,主要做線程恢復(fù)之用
os::check_crash_protection(sig,t);
if(info!=NULL&&uc!=NULL&&thread!=NULL){
pc=(address)os::ucontext_get_pc(uc);
//HandleALLstackoverflowvariationshere
if(sig==SIGSEGV){
//Si_addrmaynotbevalidduetoabuginthelinux-ppc64kernel(see
//commentbelow).Useget_stack_bang_addressinsteadofsi_addr.
addressaddr=((NativeInstruction*)pc)->get_stack_bang_address(uc);
//判斷是否棧溢出了
if(addrstack_base()&&
addr>=thread->stack_base()-thread->stack_size()){
if(thread->thread_state()==_thread_in_Java){//針對棧溢出JVM的內(nèi)部處理
stub=SharedRuntime::continuation_for_implicit_exception(thread,pc,SharedRuntime::STACK_OVERFLOW);
}
}
}
}
if(sig==SIGSEGV&&
!MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)){
//此處會做空指針檢查
stub=SharedRuntime::continuation_for_implicit_exception(thread,pc,SharedRuntime::IMPLICIT_NULL);
}
//如果是棧溢出或者空指針最終會返回true,不會走最后的report_and_die,所以JVM不會退出
if(stub!=NULL){
//saveallthreadcontextincaseweneedtorestoreit
if(thread!=NULL)thread->set_saved_exception_pc(pc);
uc->uc_mcontext.gregs[REG_PC]=(greg_t)stub;
//返回true代表JVM進(jìn)程不會退出
returntrue;
}
VMErrorerr(t,sig,pc,info,ucVoid);
//生成hs_err_pid_xxx.log文件并退出
err.report_and_die();
ShouldNotReachHere();
returntrue;//Mutecompiler
}
從以上代碼(注意看加粗的紅線字體部分)我們可以知道以下信息
發(fā)生 stackoverflow 還有空指針錯誤,確實都發(fā)送了 SIGSEGV,只是虛擬機不選擇退出,而是自己內(nèi)部作了額外的處理,其實是恢復(fù)了線程的執(zhí)行,并拋出 StackoverflowError 和 NPE,這就是為什么 JVM 不會崩潰且我們能捕獲這兩個錯誤/異常的原因
如果針對 SIGSEGV 等信號,在以上的函數(shù)中 JVM 沒有做額外的處理,那么最終會走到 report_and_die 這個方法,這個方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(記錄了一些堆棧信息或錯誤),然后退出
至此我相信大家明白了為什么發(fā)生了 StackoverflowError 和 NPE 這兩個非法訪問內(nèi)存的錯誤,JVM 卻沒有崩潰。原因其實就是虛擬機內(nèi)部定義了信號處理函數(shù),而在信號處理函數(shù)中對這兩者做了額外的處理以讓 JVM 不崩潰,另一方面也可以看出如果 JVM 不對信號做額外的處理,最后會自己退出并產(chǎn)生 crash 文件 hs_err_pid_xxx.log(可以通過 -XX:ErrorFile=/var/log/hs_err.log 這樣的方式指定),這個文件記錄了虛擬機崩潰的重要原因,所以也可以說,虛擬機是否崩潰只要看它是否會產(chǎn)生此崩潰日志文件
總結(jié)
正常情況下,操作系統(tǒng)為了保證系統(tǒng)安全,所以針對非法內(nèi)存訪問會發(fā)送一個 SIGSEGV 信號,而操作系統(tǒng)一般會調(diào)用默認(rèn)的信號處理函數(shù)(一般會讓相關(guān)的進(jìn)程崩潰),但如果進(jìn)程覺得"罪不致死",那么它也可以選擇自定義一個信號處理函數(shù),這樣的話它就可以做一些自定義的邏輯,比如記錄 crash 信息等有意義的事,回過頭來看為什么虛擬機會針對 StackoverflowError 和 NullPointerException 做額外處理讓線程恢復(fù)呢,針對 stackoverflow 其實它采用了一種棧回溯的方法保證線程可以一直執(zhí)行下去,而捕獲空指針錯誤主要是這個錯誤實在太普遍了,為了這一個很常見的錯誤而讓 JVM 崩潰那線上的 JVM 要宕機多少次,所以出于工程健壯性的考慮,與其直接讓 JVM 崩潰倒不如讓線程起死回生,并且將這兩個錯誤/異常拋給用戶來處理。
主線程異常會導(dǎo)致 JVM 退出?

有讀者讀完前面部分的文章后,問出了上面這個問題。
他認(rèn)為如果 JVM 中的主線程異常沒有被捕獲,JVM 還是會崩潰,那么這個說法是否正確呢,我們做個試驗看看結(jié)果是否是他說的這樣
publicclassTest{
publicstaticvoidmain(String[]args){
TestThreadtestThread=newTestThread();
TestThread.start();
Integerp=null;
//這里會導(dǎo)致空指針異常
if(p.equals(2)){
System.out.println("hahaha");
}
}
}
classTestThreadextendsThread{
@Override
publicvoidrun(){
while(true){
System.out.println("test");
}
}
}
試驗很簡單,首先啟動一個線程,在這個線程里搞一個 while true 不斷打印, 然后在主線程中制造一個空指針異常,不捕獲,然后看是否會一直打印 test
結(jié)果是會不斷打印 test,說明主線程崩潰,JVM 并沒有崩潰 ,這是怎么回事, JVM 又會在什么情況下完全退出呢?
其實在 Java 中并沒有所謂主線程的概念,只是我們習(xí)慣把啟動的線程作為主線程而已,所有線程其實都是平等的,不管什么線程崩潰都不會影響到其它線程的執(zhí)行,注意我們這里說的線程崩潰是指由于未 catch 住 JVM 拋出的虛擬機錯誤(VirtualMachineError)而導(dǎo)致的崩潰,虛擬機錯誤包括 InternalError,OutOfMemoryError,StackOverflowError,UnknownError 這四大子類
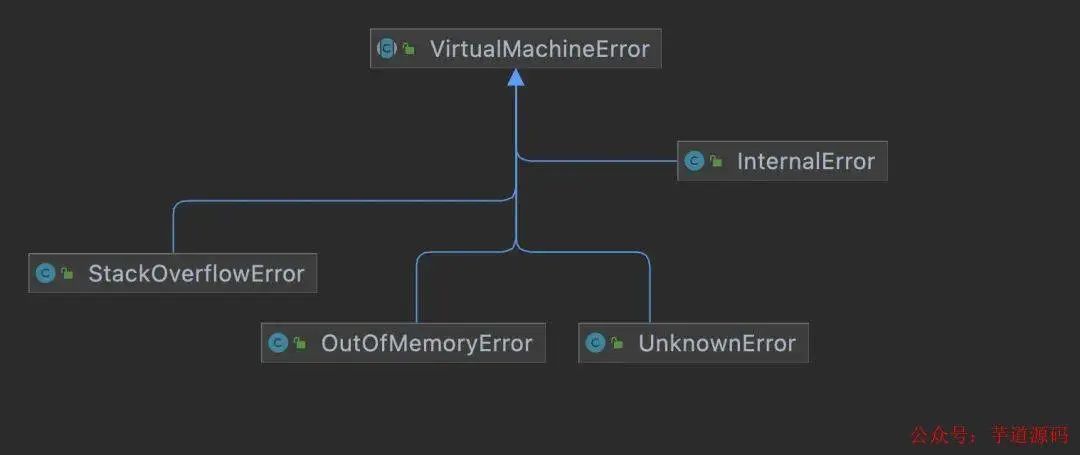
JVM 拋出這些錯誤其實是一種防止整個進(jìn)程崩潰的自我防護機制,這些錯誤其實是 JVM 內(nèi)部定義了信號處理函數(shù)處理后拋出的,JVM 認(rèn)為這些錯誤"罪不致死",所以選擇恢復(fù)線程再給這些線程拋錯誤(就算線程不 catch 這些錯誤也不會崩潰)的方式來避免自身崩潰,但如果線程觸發(fā)了一些其他的非法訪問內(nèi)存的錯誤,JVM 則會認(rèn)為這些錯誤很嚴(yán)重,從而選擇退出,比如下面這種非法訪問內(nèi)存的錯誤就會被認(rèn)為是致命錯誤,JVM 就不會向上層拋錯誤,而會直接選擇退出
Fieldf=Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafeunsafe=(Unsafe)f.get(null);
unsafe.putAddress(0,0);
回過頭來看,除了這些致命性錯誤導(dǎo)致的 JVM 崩潰,還有哪些情況會導(dǎo)致 JVM 退出呢,在 javadoc 上說得很清楚
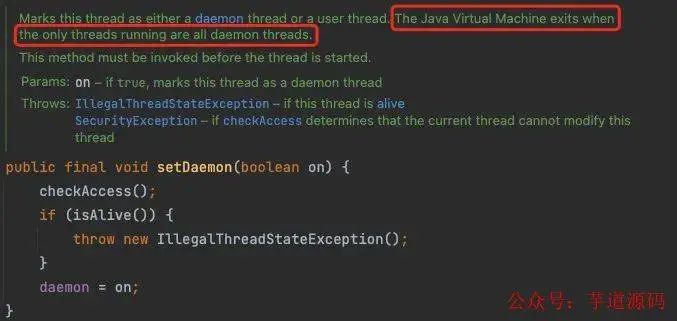
The Java Virtual Machine exits when the only threads running are all daemon threads
也就是說只有在 JVM 的所有線程都是守護線程(daemon thread)的時候才會完全退出,什么是守護線程?守護線程其實是為其他線程服務(wù)的線程,比如垃圾回收線程就是典型的守護線程,既然是為其他線程服務(wù)的,那么一旦其他線程都不存在了,守護線程也沒有存在的意義了,于是 JVM 也就退出了,守護線程通常是 JVM 運行時幫我們創(chuàng)建好的,當(dāng)然我們也可以自己設(shè)置,以開頭的代碼為例,在創(chuàng)建完 TestThread 后,調(diào)用 testThread.setDaemon(true) 方法即可將線程轉(zhuǎn)為守護線程,然后再啟動,這樣在主線程退出后,JVM 就會退出了,大家可以試試
Java 線程模型簡介
我們可以看看 Java 的線程模型,這樣大家對 JVM 的線程調(diào)度也會有一個更全面的認(rèn)識,我們可以先從源碼角度看看,啟動一個 Thread 到底在 JVM 內(nèi)部發(fā)生了什么,啟動源碼代碼在 Thread#start 方法中
publicclassThread{
publicsynchronizedvoidstart(){
...
start0();
...
}
privatenativevoidstart0();
}
可以看到最終會調(diào)用 start0 這個 native 方法,我們?nèi)ハ螺d一下 openJDK(地址:https://github.com/AdoptOpenJDK/openjdk-jdk8u) 來看看這個方法對應(yīng)的邏輯
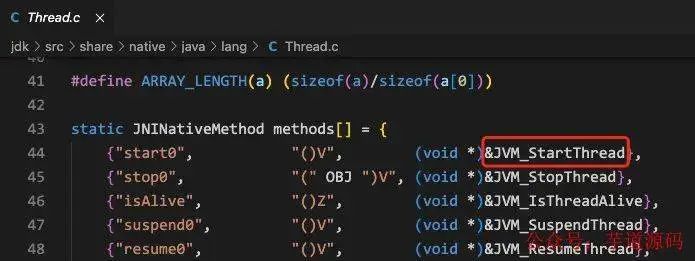
可以看到 start0 對應(yīng)的是 JVM_startThread 這個方法,我們主要觀察在 Linux 下的線程啟動情況,一路追蹤下去
//jvm.cpp
JVM_ENTRY(void,JVM_StartThread(JNIEnv*env,jobjectjthread))
native_thread=newJavaThread(&thread_entry,sz);
//thread.cpp
JavaThread::JavaThread(ThreadFunctionentry_point,size_tstack_sz)
{
os::create_thread(this,thr_type,stack_sz);
}
//os_linux.cpp
boolos::create_thread(Thread*thread,ThreadTypethr_type,size_tstack_size){
intret=pthread_create(&tid,&attr,(void*(*)(void*))java_start,thread);
}
可以看到最終是通過調(diào)用 pthread_create 來啟動線程的,這個方法是一個 C 函數(shù)庫實現(xiàn)的創(chuàng)建 native thread 的接口,是一個系統(tǒng)調(diào)用,由此可見 pthread_create 最終會創(chuàng)建一個 native thread,這個線程也叫內(nèi)核線程 ,操作系統(tǒng)只能調(diào)度內(nèi)核線程,于是我們知道了在 Java 中,Java 線程和內(nèi)核線程是一對一的關(guān)系,Java 線程調(diào)度實際上是通過操作系統(tǒng)調(diào)度實現(xiàn)的,這種一對一的線程也叫 NPTL(Native POSIX Thread Library) 模型,如下
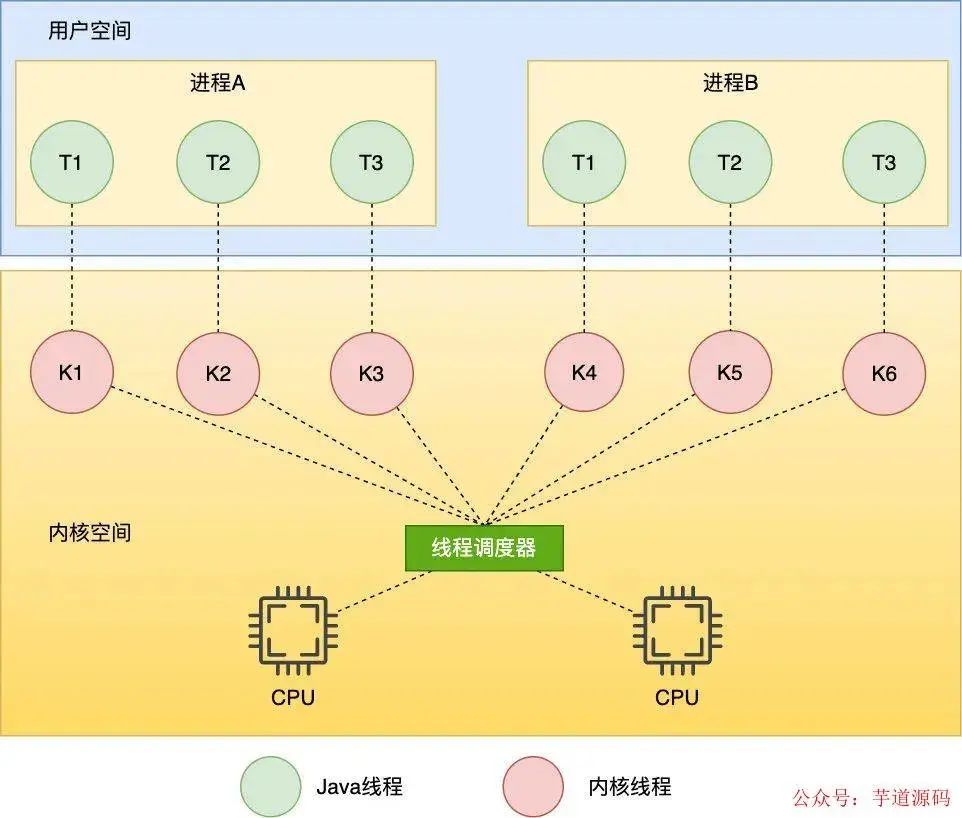
NPTL線程模型
那么這個內(nèi)核線程在內(nèi)核中又是怎么表示的呢, 其實在 Linux 中不管是進(jìn)程還是線程都是通過一個 task_struct 的結(jié)構(gòu)體來表示的, 這個結(jié)構(gòu)體定義了進(jìn)程需要的虛擬地址,文件描述符,寄存器,信號等資源
早期沒有線程的概念,所以每次啟動一個進(jìn)程都需要調(diào)用 fork 創(chuàng)建進(jìn)程,這個 fork 干的事其實就是 copy 父進(jìn)程對應(yīng)的 task_struct 的多數(shù)字段(pid 等除外),這在性能上顯然是無法接受的。于是線程的概念被提出來了,線程除了有自己的棧和寄存器外,其他像虛擬地址,文件描述符等資源都可以共享
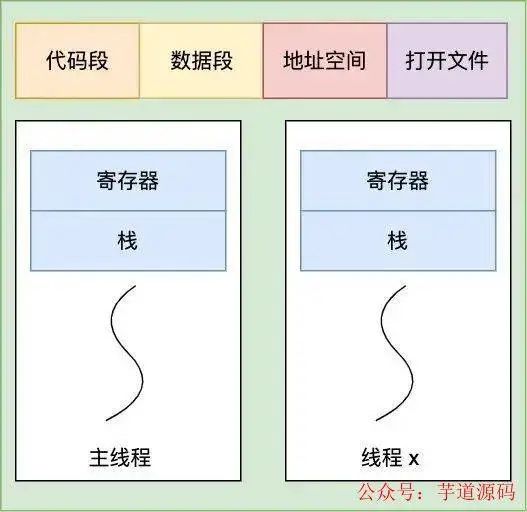
線程共享代碼段,數(shù)據(jù)段,地址空間,文件等資源
于是針對線程,我們就可以指定在創(chuàng)建 task_struct 時,采用共享 而不是復(fù)制字段的方式。其實不管是創(chuàng)建進(jìn)程(fork)還是創(chuàng)建線程(pthread_create)最終都會通過調(diào)用 clone() 的形式來創(chuàng)建 task_struct,只不過 pthread_create 在調(diào)用 clone 時,指定了如下幾個共享參數(shù)
clone(CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND,0);
畫外音 :CLONE_VM 共享頁表,CLONE_FS 共享文件系統(tǒng)信息,CLONE_FILES 共享文件句柄,CLONE_SIGHAND 共享信號
通過共享而不是復(fù)制資源的形式極大地加快了線程的創(chuàng)建,另外線程的調(diào)度開銷也會更小,比如在(同一進(jìn)程內(nèi))線程間切換的時候由于共享了虛擬地址空間,TLB 不會被刷新從而導(dǎo)致內(nèi)存訪問低效的問題
提到這相信你已經(jīng)明白了教科書上的一句話:進(jìn)程是資源分配的最小單元,而線程是程序執(zhí)行和調(diào)度的最小單位。在 Linux 中進(jìn)程分配資源后,線程通過共享資源的方式來被調(diào)度得以提升線程的執(zhí)行效率
由此可見,在 Linux 中所有的進(jìn)程/線程都是用的 task_struct,它們之間其實是平等的 ,那怎么表示這些線程屬于同一個進(jìn)程的概念呢,畢竟線程之間也是要通信的,一組線程以及它們所共同引用的一組資源就是一個進(jìn)程。, 它們還必須被視為一個整體。
task_struct 中引入了線程組的概念,如果線程都是由同一個進(jìn)程(即我們說的主線程)產(chǎn)生的, 那么它們的 tgid(線程組id) 是一樣的,如果是主線程,則 pid = tgid,如果是主線程創(chuàng)建的線程,則這些線程的 tgid 會與主線程的 tgid 一致,
那么在 LInux 中進(jìn)程,進(jìn)程內(nèi)的線程之間是如何通信或者管理的呢,其實 NPTL 是一種實現(xiàn)了 POSIX Thread 的標(biāo)準(zhǔn) ,所以我們只需要看 POSIX Thread 的標(biāo)準(zhǔn)即可,以下列出了 POSIX Thread 的主要標(biāo)準(zhǔn):
查看進(jìn)程列表的時候, 相關(guān)的一組 task_struct 應(yīng)當(dāng)被展現(xiàn)為列表中的一個節(jié)點(即進(jìn)程內(nèi)如果有多個線程,展示進(jìn)程列表 ps -ef 時只會展示主線程,如果要查看線程的話可以用 ps -T)
發(fā)送給這個進(jìn)程的信號(對應(yīng) kill 系統(tǒng)調(diào)用), 將被對應(yīng)的這一組 task_struct 所共享, 并且被其中的任意一個”線程”處理
發(fā)送給某個線程的信號(對應(yīng) pthread_kill), 將只被對應(yīng)的一個 task_struct 接收, 并且由它自己來處理
當(dāng)進(jìn)程被停止或繼續(xù)時(對應(yīng) SIGSTOP/SIGCONT 信號), 對應(yīng)的這一組 task_struct 狀態(tài)將改變
當(dāng)進(jìn)程收到一個致命信號(比如由于段錯誤收到 SIGSEGV 信號), 對應(yīng)的這一組 task_struct 將全部退出
畫外音 : POSIX 即可移植操作系統(tǒng)接口(Portable Operating System Interface of UNIX,縮寫為 POSIX ),是一種接口規(guī)范,如果系統(tǒng)都遵循這個標(biāo)準(zhǔn),可以做到源碼級的遷移,這就類似 Java 中的針對接口編程
這樣就能很好地滿足進(jìn)程退出線程也退出,或者線程間通信等要求了
NPTL 模型的缺點
NPTL 是一種非常高效的模型,研究表明 NPTL 能夠成功地在 IA-32 平臺上在兩秒內(nèi)生成 100,000 個線程,而 2.6 之前未采用 NPTL 的內(nèi)核則需耗費 15 分鐘左右,看起來 NPTL 確實很好地滿足了我們的需求,但針對內(nèi)核線程來調(diào)度其實還是有以下問題
不管是進(jìn)程還是線程,每次阻塞、切換都需要陷入系統(tǒng)調(diào)用(system call),系統(tǒng)調(diào)用開銷其實挺大的,包括上下文切換(寄存器切換),特權(quán)模式切換等,而且還得先讓 CPU 跑操作系統(tǒng)的調(diào)度程序,然后再由調(diào)度程序決定該跑哪一個進(jìn)程(線程)
不管是進(jìn)程還是線程,都屬于搶占式調(diào)度(高優(yōu)先級線進(jìn)程優(yōu)先被調(diào)度),由于搶占式調(diào)度執(zhí)行順序無法確定的特點,使用線程時需要非常小心地處理同步問題
線程雖然更輕量級,但這只是相對于進(jìn)程而言,實際上使用線程所消耗的資源依然很大,比如在 linux 上,一個線程默認(rèn)的棧大小是1M,創(chuàng)建幾萬個線程就吃不消了
協(xié)程
NPTL 模型其實已經(jīng)足夠優(yōu)秀了,上述問題本質(zhì)上其實還是因為線程還是太“重”所致,那能否再在線程上抽出一個更輕量級的執(zhí)行單元(可被 CPU 調(diào)度和分派的基本單位)呢,答案是肯定的,在線程之上我們可以再抽象出一個協(xié)程(coroutine)的概念,就像進(jìn)程是由線程來調(diào)度的,同樣線程也可以細(xì)化成一個個的協(xié)程來調(diào)度
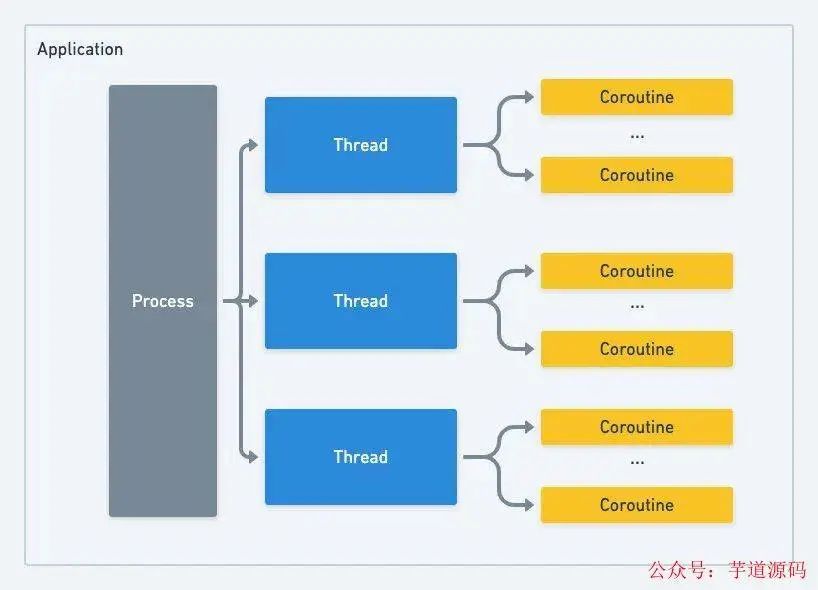
針對以上問題,協(xié)程都做了非常好的處理
協(xié)程的調(diào)度處于用戶態(tài),也就沒有了系統(tǒng)調(diào)用這些開銷
協(xié)程不屬于搶占式調(diào)度,而是協(xié)作式調(diào)度,如何調(diào)度,在什么時間讓出執(zhí)行權(quán)給其它協(xié)程是由用戶自己決定的,這樣的話同步的問題也基本不存在,可以認(rèn)為協(xié)程是無鎖的,所以性能很高
我們可以認(rèn)為線程的執(zhí)行是由一個個協(xié)程組成的,協(xié)程是更輕量的存在,內(nèi)存使用大約只有線程的十分之一甚至是幾十分之一,它是使用棧內(nèi)存按需使用的,所以創(chuàng)建百萬級的協(xié)程是非常輕松的事
協(xié)程是怎么做到上述這些的呢
協(xié)程(coroutine)可以分為兩個角度來看,一個是 routine 即執(zhí)行單元,一個是 co 即 cooperative 協(xié)作,也就是說線程可以依次順序執(zhí)行各個協(xié)程,但協(xié)程與線程不同之處在于,如果某個協(xié)程(假設(shè)為 A)內(nèi)碰到了 IO 等阻塞事件,可以主動讓出自己的調(diào)度權(quán),即掛起(suspend),轉(zhuǎn)而執(zhí)行其他協(xié)程,等 IO 事件準(zhǔn)備好了,再來調(diào)度協(xié)程 A
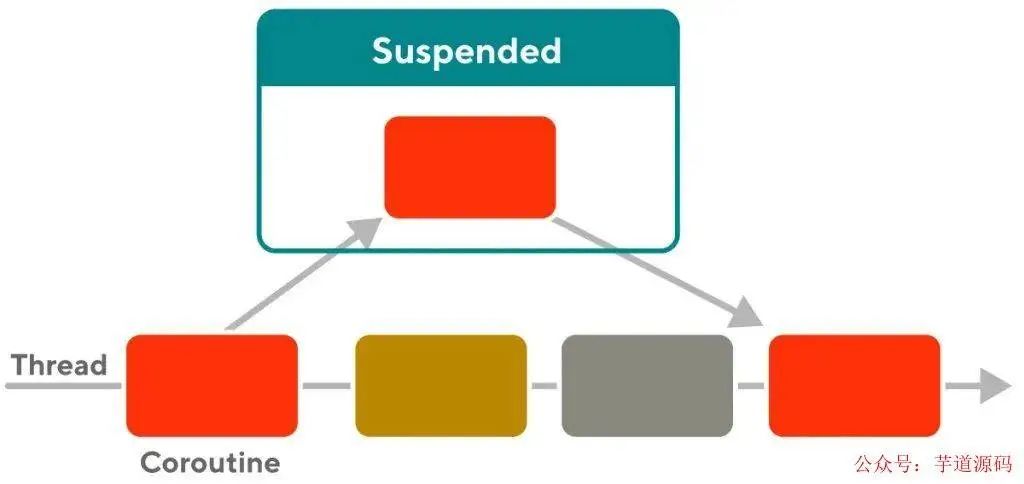
這就好比我在看電視的時候碰到廣告,那我可以先去倒杯水,等廣告播完了再回來繼續(xù)看電視。而如果是函數(shù),那你必須看完廣告再去倒水,顯然協(xié)程的效率更高。那么協(xié)程之間是怎么協(xié)作的呢,我們可以在兩個協(xié)程之間碰到 IO 等阻塞事件時隨時將自己掛起(yield),然后喚醒(resume)對方以讓對方執(zhí)行,想象一下如果協(xié)程中有挺多 IO 等阻塞事件時,那這種協(xié)作調(diào)度是非常方便的
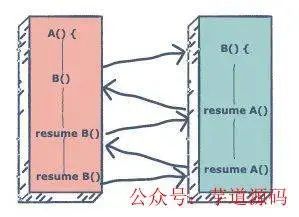 兩個協(xié)程之間的“協(xié)作”
兩個協(xié)程之間的“協(xié)作”
不像函數(shù)必須執(zhí)行完才能返回,協(xié)程可以在執(zhí)行流中的任意位置 由用戶決定掛起和喚醒,無疑協(xié)程是更方便的
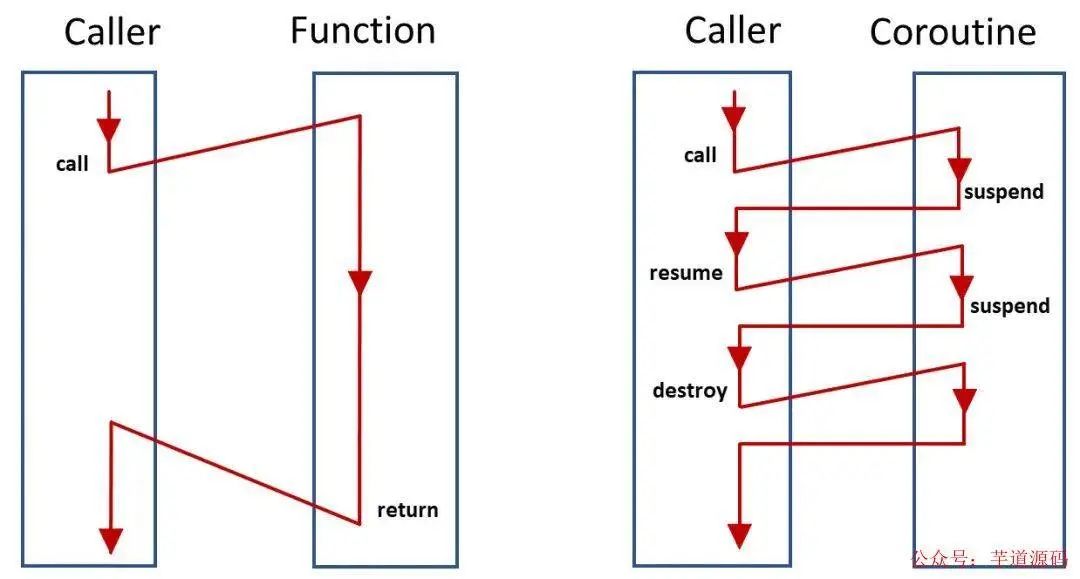
函數(shù)與協(xié)程的區(qū)別
更重要的一點是不像線程的掛起和喚醒等調(diào)度必須通過系統(tǒng)調(diào)用來讓內(nèi)核調(diào)度器來調(diào)度,協(xié)程的掛起和喚醒完全是由用戶決定的 ,而且這個調(diào)度是在用戶態(tài),幾乎沒有開銷!
前面我們一直提到一般我們在協(xié)程中碰到 IO 等阻塞事件時才會掛起并喚醒其他協(xié)程,所以可知協(xié)程非常適合 IO 密集型的應(yīng)用 ,如果是計算密集型其實用線程反而更加合適
為什么 Go 語言這么最近這么火,一個很重要的原因就是因為因為它天生支持協(xié)程,可以輕而易舉地創(chuàng)建成千上萬個協(xié)程,而如果是創(chuàng)建線程的話,創(chuàng)建幾百個估計就夠嗆了,不過比較遺憾的是 Java 原生并不支持協(xié)程,只能通過一些第三方庫如 Quasar 來實現(xiàn),2018 年 OpenJDK 官方創(chuàng)建了一個 loom 項目來推進(jìn)協(xié)程的官方支持工作
總結(jié)
從進(jìn)程,到線程再到協(xié)程,可知我們一直在想辦法讓執(zhí)行單元變得更輕量級,一開始只有進(jìn)程的概念,但是進(jìn)程的創(chuàng)建在 Linux 下需要調(diào)用 fork 全部復(fù)制一遍資源,雖然后來引入了寫時復(fù)制的概念,但進(jìn)程的創(chuàng)建開銷依然很大,于是提出了更輕量級的線程,在 Linux 中線程與進(jìn)程其實都是用 task_struct 表示的,只是線程采用了共享資源的方式來創(chuàng)建,極大了提升了 task_struct 的創(chuàng)建與調(diào)度效率,但人們發(fā)現(xiàn),線程的阻塞,喚醒都要通過系統(tǒng)調(diào)用陷入內(nèi)核態(tài)才能被調(diào)度程度調(diào)度,如果線程頻繁切換,開銷無疑是很大的,于是人們提出了協(xié)程的概念,協(xié)程是根據(jù)棧內(nèi)存按需求分配的,所需開銷是線程的幾十分之一,非常的輕量,而且調(diào)度是在用戶態(tài),并且它是協(xié)作式調(diào)度,可以很方便的掛起恢復(fù)其他協(xié)程的執(zhí)行,在此期間,線程是不會被掛起的,所以無論是創(chuàng)建還是調(diào)度開銷都很小,目前 Java 官方還不支持,不過支持協(xié)程應(yīng)該是大勢所趨,未來我們可以期待一下。
審核編輯:劉清
-
cpu
+關(guān)注
關(guān)注
68文章
10824瀏覽量
211135 -
JVM
+關(guān)注
關(guān)注
0文章
157瀏覽量
12206 -
openjdk
+關(guān)注
關(guān)注
0文章
8瀏覽量
2309
原文標(biāo)題:美團一面:為什么線程崩潰崩潰不會導(dǎo)致 JVM 崩潰
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Jvm的整體結(jié)構(gòu)和特點
看看基于JDK中自帶JVM工具的用法
Jvm工作原理學(xué)習(xí)筆記
如何解決JVM中一個極小概率發(fā)生的bug
如何解決JVM解釋器導(dǎo)致應(yīng)用崩潰的bug






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論