 NVIDIA Triton 系列文章(11):模型類別與調度器-1
NVIDIA Triton 系列文章(11):模型類別與調度器-1
在 Triton 推理服務器的使用中,模型(model)類別與調度器(scheduler)、批量處理器(batcher)類型的搭配,是整個管理機制中最重要的環節,三者之間根據實際計算資源與使用場景的要求去進行調配,這是整個 Triton 服務器中比較復雜的部分。
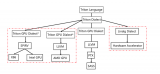
在模型類別中有“無狀態(stateless)”、“有狀態(stateful)”與“集成(ensemble)”三種,調度器方面則有“標準調度器(default scheduler)”與“集成調度器(ensemble scheduler)”兩種,而標準調度器下面還有“動態批量處理器(dynamic batcher)”與“序列批量處理器(sequence batcher)”兩種批量處理器。
模型類別與調度器/批量處理器之間存在一些關聯性,以下整理出一個簡單的配合表格,提供大家參考:
|
類別 |
調度器 |
批量處理器 |
使用場景 |
|
無狀態 |
標準調度器 |
動態批量處理器 |
面向各自獨立的推理模型 |
|
有狀態 |
標準調度器 |
序列批量處理器 |
處理存在交互關系的推理模型組 |
|
集成 |
集成調度器 |
創建復雜的工作流水線 |
接下去就要為這幾個管理機制的組合進行說明,由于內容較多并且不均衡,特別是“有狀態模型”與“集成模型”兩部分的使用是相對復雜的,因此這些組合會分為三篇文章來進行較為深入的說明。
1. 無狀態(Stateless)模式:
這是 Triton 默認的模型模式,最主要的要求就是“模型所維護的狀態不跨越推理請求”,也就是不存在與其他推理請求有任何交互關系,大部分處于最末端的獨立推理模型,都適合使用這種模式,例如車牌檢測最末端的將圖像識別成符號的推理、為車輛識別顏色/種類/廠牌的圖像分類等,還有 RNN 以及具有內部內存的類似模型,也可以是無狀態的。
2. 有狀態(Stateful)模式:
很多提供云服務的系統,需要具備同時接受多個推理請求去形成一系列推理的能力,這些推理必須路由到某些特定模型實例中,以便正確更新模型維護的狀態。此外,該模型可能要求推理服務器提供控制信號,例如指示序列的開始和結束。
Triton 服務器提供動態(dynamic)與序列(sequence)兩種批量處理器(batcher),其中序列批量處理器必須用于這種有狀態模式,因為序列中的所有推理請求都被路由到同一個模型實例,以便模型能夠正確地維護狀態。
序列批量處理程序還需要與模型相互傳遞信息,以指示序列的開始、結束、具有可執行推理請求的時間,以及序列的關聯編號(ID)。當對有狀態模型進行推理請求時,客戶端應用程序必須為序列中的所有請求提供相同的關聯編號,并且還必須標記序列的開始和結束。
下面是這種模式的控制行為有“控制輸入”、“隱式狀態管理”與“調度策略”三個部分,本文后面先說明控制輸入的內容,另外兩個部分在下篇文章內講解。
(1) 控制輸入(control inputs)
為了使有狀態模型能夠與序列批處理程序一起正確運行,模型通常必須接受 Triton 用于與模型通信的一個或多個控制輸入張量。
模型配置的sequence_batching里的control_input部分,指示模型如何公開序列批處理程序應用于這些控件的張量。所有控件都是可選的,下面是模型配置的一部分,顯示了所有可用控制信號的示例配置:

-
開始(start):
這個輸入張量在配置中使用“CONTROL_SEQUENCE_START”指定,上面配置表明模型有一個名為“START”的輸入張量,其數據類型為 32 位浮點數,序列批量處理程序將在對模型執行推理時定義此張量。
START 輸入張量必須是一維的,大小等于批量大小,張量中的每個元素指示相應批槽中的序列是否開始。上面配置中“fp32_false_true”表示,當張量元素等于 0 時為“false(不開始)”、等于 1 時為“ture(開始)”。
-
結束(End):
結束輸入張量在配置中使用“CONTROL_SEQUENCE_END”指定,上面配置表明模型有一個名為“END”的輸入張量,具有 32 位浮點數據類型,序列批處理程序將在對模型執行推理時定義此張量。
END 輸入張量必須是一維的,大小等于批量大小,張量中的每個元素指示相應批槽中的序列是否開始。上面配置中“fp32_false_true”表示,當張量元素等于 0 時為“false(不結束)”、等于 1 時為“ture(結束)”。
-
準備就緒(Ready):
就緒輸入張量在配置中使用“CONTROL_SEQUENCE_READY”指定,上面配置表明模型有一個名為“READY”的輸入張量,其數據類型為 32 位浮點數,序列批處理程序將在對模型執行推理時定義此張量。
READY 輸入張量必須是一維的,大小等于批量大小,張量中的每個元素指示相應批槽中的序列是否開始。上面配置中“fp32_false_true”表示,當張量元素等于 0 時為“false(未就緒)”、等于1時為“ture(就緒)”。
-
關聯編號(Correlation ID):
關聯編號輸入張量在配置中使用“CONTROL_SEQUENCE_CORRID”指定,上面置表明模型有一個名為“CORRID”的輸入張量,其數據類型為無符號 64 位整數,序列批處理程序將在對模型執行推理時定義此張量。
CORRID 張量必須是一維的,大小等于批量大小,張量中的每個元素表示相應批槽中序列的相關編號。
(2) 隱式狀態管理(implicit State Management)
這種方式允許有狀態模型將其狀態存儲在 Triton 服務器中。當使用隱式狀態時,有狀態模型不需要在模型內部存儲推理所需的狀態。不過隱式狀態管理需要后端(backend)支持。目前只有 onnxruntime_backend 和 tensorrt_backend 支持隱式狀態。
下面是模型配置的一部分,在sequence_batching配置中的 state 部分,就是用于指示該模型正在使用隱式狀態:
sequence_batching {
state [
{
input_name: "INPUT_STATE"
output_name: "OUTPUT_STATE"
data_type: TYPE_INT32
dims: [ -1 ]
}
]
}
這里做簡單的說明:
-
字段說明:
- input_name 字段:指定將包含輸入狀態的輸入張量的名稱;
- output_name 字段:描述由包含輸出狀態的模型生成的輸出張量的名稱;
- dims 字段:指定狀態張量的維度。
-
執行要點:
- 序列中第 i 個請求中模型提供的輸出狀態,將用作第 i+1 個請求中的輸入狀態;
- 當 dims 字段包含可變大小的維度時,輸入狀態和輸出狀態的尺度不必匹配;
- 出于調試目的,客戶端可以請求輸出狀態。為了實現這個目的,模型配置的輸出部分必須將輸出狀態(OUTPUT_STATE)列為模型的一個輸出;
- 由于需要傳輸額外的張量,從客戶端請求輸出狀態可能會增加請求延遲。
默認情況下,序列中的啟動請求包含輸入狀態的未初始化數據。模型可以使用請求中的開始標志來檢測新序列的開始,并通過在模型輸出中提供初始狀態來初始化模型狀態,如果模型狀態描述中的 dims 部分包含可變尺度,則 Triton 在開始請求時將每個可變尺寸設置為“1”。對于序列中的其他非啟動請求,輸入狀態是序列中前一個請求的輸出狀態。
對于狀態初的初始化部分,有以下兩種狀況需要調整:
-
啟動請求時:則模型將“OUTPUT_STATE”設置為等于“INPUT”張量;
-
非啟動請求時:將“OUTPUT_STATE”設為“INPUT”和“INPUT_STATE”張量之和。
除了上面討論的默認狀態初始化之外,Triton 還提供了“從 0 開始”與“從文件導入”兩種初始化狀態的機制。下面提供兩種初始化的配置示例:

兩個配置只有粗體部分不一樣,其余內容都是相同的,提供讀者做個參考。
以上是關于有狀態模型的“控制輸入”與“隱式狀態管理”的使用方式,剩下的“調度策略”部分,會在后文中提供完整的說明。
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-1
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3748瀏覽量
90842
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-1
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA新增生成式AI就緒系統認證類別
NVIDIA助力提供多樣、靈活的模型選擇
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

英偉達推出全新NVIDIA AI Foundry服務和NVIDIA NIM推理微服務
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

NVIDIA與Google DeepMind合作推動大語言模型創新
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
使用NVIDIA Triton推理服務器來加速AI預測
在AMD GPU上如何安裝和配置triton?

【BBuf的CUDA筆記】OpenAI Triton入門筆記一

利用NVIDIA產品技術組合提升用戶體驗
不要錯過!NVIDIA “大模型沒那么泛!”主題活動

什么是Triton-shared?Triton-shared的安裝和使用
Triton編譯器的原理和性能

NVIDIA 為部分大型亞馬遜 Titan 基礎模型提供訓練支持






 工商網監
工商網監
評論