") CPU優(yōu)化技術(shù)-NEON自動向量化
CPU優(yōu)化技術(shù)-NEON自動向量化
本文選自極術(shù)專欄《嵌入式AI》的文章,授權(quán)轉(zhuǎn)自知乎作者高性能計(jì)算學(xué)院的《移動端算法優(yōu)化》。前面我們學(xué)習(xí)了如何快速上手開始NEON編程,ArmNEON優(yōu)化技術(shù),Arm NEON 匯編與Intrinsics編程,CPU優(yōu)化技術(shù)之NEON介紹和CPU 優(yōu)化技術(shù)-NEON 指令介紹,本篇將會詳細(xì)介紹NEON 自動向量化。
一、概述
SIMD 作為一種重要的并行化技術(shù),在提升性能的同時(shí)也會增加開發(fā)的難度。目前大多數(shù)編譯器都具有自動向量化的功能,將 C/C++ 代碼自動替換為 SIMD 指令。
從編譯技術(shù)上來說,自動向量化一般包含兩部分:循環(huán)向量化(Loop vectorization)和超字并行向量化(SLP,Superword-Level Parallelism vectorization,又稱Basic block vectorization)。
演示代碼:
void add(int *a, int *b, int n, int * restrict sum)
{
// it is assumed that the input n is an integer multiple of 4
for (int i = 0; i < (n & ~3); ++i)
{
sum[i] = a[i] + b[i];
}
}
- 循環(huán)向量化:將循環(huán)進(jìn)行展開,增加循環(huán)中的執(zhí)行代碼來減少循環(huán)次數(shù)。如以下代碼將循環(huán)次數(shù)精簡到之前的1/4。
for (int i = 0; i < (n & ~3); i += 4)
{
sum[i] = a[i ] + b[i];
sum[i + 1] = a[i + 1] + b[i + 1];
sum[i + 2] = a[i + 2] + b[i + 2];
sum[i + 3] = a[i + 3] + b[i + 3];
}
-
SLP 向量化:編譯器將多個(gè)標(biāo)量運(yùn)算綁定到一起,使其成為向量運(yùn)算。下圖將四次標(biāo)量運(yùn)算替換為一次向量運(yùn)算。
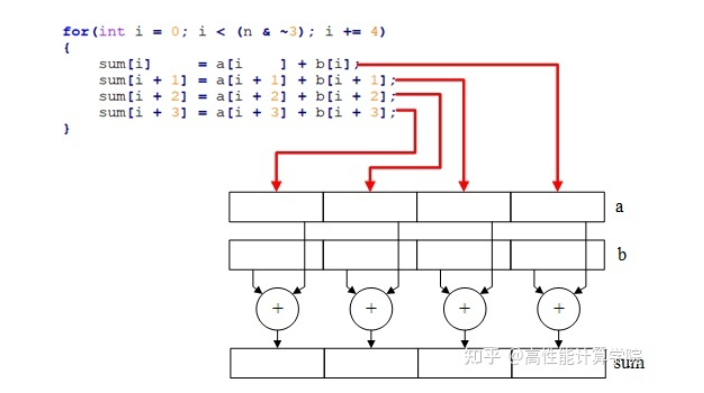
SLP 自動向量化
接下來介紹如何通過編譯器實(shí)現(xiàn)自動向量化。
二、編譯器配置
目前支持自動向量化的編譯器有 Arm Compiler 6、Arm C/C++ Compiler、LLVM-clang 以及 GCC,這幾種編譯器間的相互關(guān)系如下表所示。

自動向量化默認(rèn)不會被啟用,編程人員需要向編譯器提供允許自動向量化的“許可證”來對自動向量化功能進(jìn)行使能。
A.Arm Compiler 中使能自動向量化
下文中 Arm Compiler 6 與 Arm C/C++ Compiler 使用 armclang 統(tǒng)稱,armclang 使能自動向量化配置信息如下表所示:
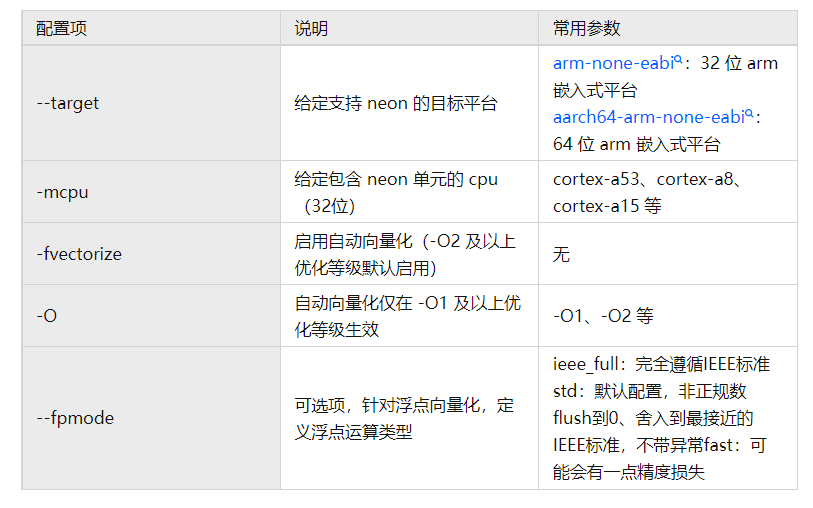
armclang 實(shí)現(xiàn)自動向量化示例:
# AArch32
armclang --target=arm-none-eabi -mcpu=cortex-a53 -O1 -fvectorize main.c
# AArch64
armclang --target=aarch64-arm-none-eabi -O2 main.c
B. LLVM-clang中使能自動向量化
Android NDK 從 r13 開始以 clang 為默認(rèn)編譯器,本節(jié)通過 cmake 調(diào)用Android NDK r19c 工具鏈展示 clang 的自動向量化方法。
- 使用 Android NDK 工具鏈?zhǔn)鼓茏詣酉蛄炕渲?a target="_blank">參數(shù)如下表:

- 在 CMake 中配置自動向量化方式如下:
# method 1
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O1 -fvectorize")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O1 -fvectorize")
# method 2
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O2")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -O2")
C. GCC 中使能自動向量化
在 gcc 中使能自動向量化配置參數(shù)如下:
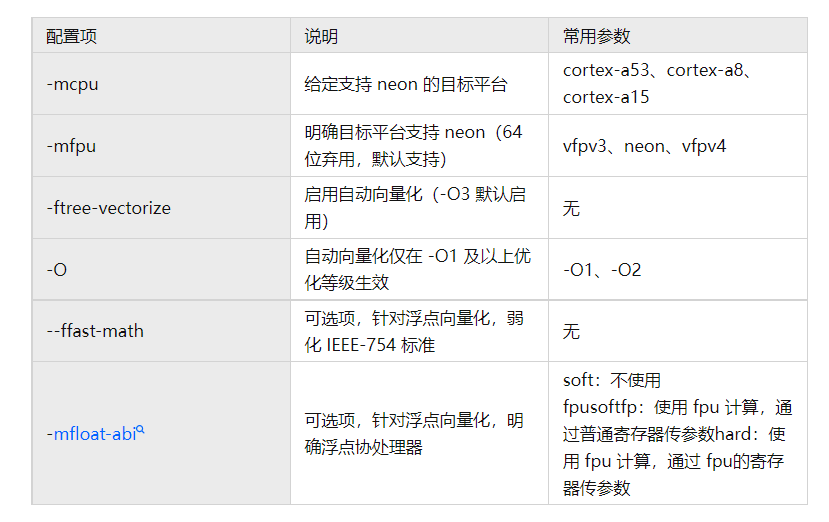
-
在不明確配置 -mcpu 的情況下,編譯器將使用默認(rèn)配置(取決于編譯工具鏈時(shí)的選項(xiàng)設(shè)置)進(jìn)行編譯。
-
通常情況下 -mfpu 和 -mcpu 的配置存在關(guān)聯(lián)性,對應(yīng)關(guān)系如下。(如當(dāng)選取-mcpu為cortex-a8時(shí),-mfpu一般設(shè)置為vfpv3或neon)
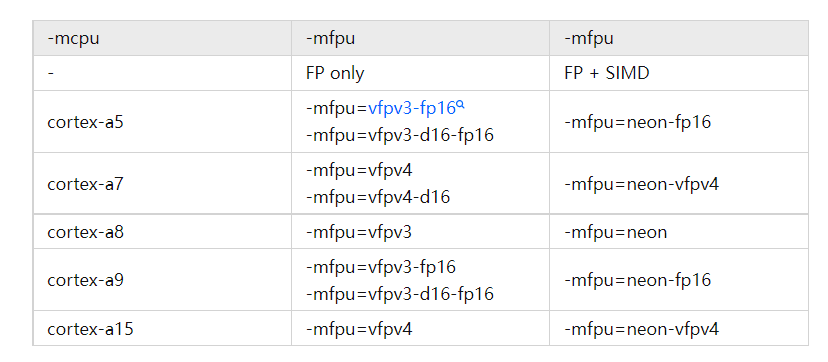
gcc 中實(shí)現(xiàn)自動向量化的編譯配置如下:
# AArch32
arm-none-linux-gnueabihf-gcc -mcpu=cortex-a53 -mfpu=neon -ftree-vectorize -O2 main.c
# AArch64
aarch64-none-linux-gnu-gcc -mcpu=cortex-a53 -ftree-vectorize -O2 main.c
此外,gcc 中可以通過 -fopt-info-vec 命令查看自動向量化的詳細(xì)信息,比如哪些代碼實(shí)現(xiàn)了向量化,哪些代碼沒有實(shí)現(xiàn)向量化及沒有進(jìn)行向量化的原因。
D. 自動向量化實(shí)例
我們以上節(jié)的求和示例代碼,來對編譯器自動向量化的功能進(jìn)行演示。編譯器以 32 位 arm-gcc 為例:
# automatic vectorization is not enabled
arm-none-linux-gnueabihf-gcc -O2 main.c -o avtest
# automatic vectorization is enabled
arm-none-linux-gnueabihf-gcc -mfpu=neon -ftree-vectorize -O2 main.c -o avtest
- 使用 objdump 查看反匯編代碼,反匯編命令如下:
arm-none-linux-gnueabihf-objdump -d avtest > assemble.txt
-
反匯編結(jié)果對比如下圖:
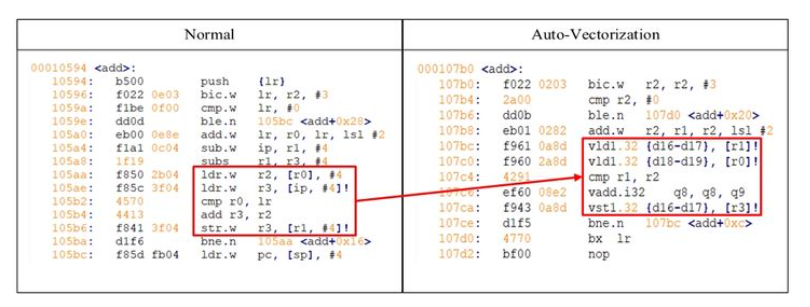
反匯編代碼
啟用自動向量化之后,編譯器通過矢量化加載 (ldr -> vld1)、求和 (add -> vadd)以及保存 (str -> vst1)等指令,將每次循環(huán)中處理的數(shù)據(jù)變?yōu)?4 個(gè),循環(huán)次數(shù)精簡為之前的 1/4。
三、自動向量化友好型代碼
基于一定的編程優(yōu)化準(zhǔn)則,可以更好的協(xié)助編譯器完成自動向量化的工作,獲得理想的性能狀態(tài)。
A. 避免使用難以向量化的語句
-
數(shù)據(jù)依賴
當(dāng)循環(huán)中存在數(shù)據(jù)依賴時(shí),編譯器無法進(jìn)行向量化。
下述代碼中計(jì)算 a[i] 時(shí)依賴上一次循環(huán)的輸出,無法被向量化。
// the output of a[i] depends on its last result
for (int i = 1; i < n; ++i)
{
a[i] = a[i - 1] + 1;
}
-
多級指針
編譯器無法對間接尋址,多級索引、多級解引用等行為進(jìn)行向量化,盡量避免使用多級指針。
下述代碼通過 idx 進(jìn)行了多級索引,無法被向量化。
// idx is unpredictable, so this code cannot be vectorized
for (int i = 0; i < n; ++i)
{
sum[idx[i]] = a[idx[i]] + b[idx[i]];
}
-
條件及跳轉(zhuǎn)語句
當(dāng)循環(huán)中存在條件語句或跳轉(zhuǎn)語句時(shí),代碼很難被向量化。因此應(yīng)盡量避免在循環(huán)中的使用if、break等語句。當(dāng)循環(huán)中需要調(diào)用函數(shù)時(shí),盡量使用內(nèi)聯(lián)函數(shù)進(jìn)行替換。
下述代碼通過調(diào)用內(nèi)聯(lián)函數(shù) add_single2 避免發(fā)生函數(shù)跳轉(zhuǎn)。
__attribute__((noinline)) int add_single1(int a, int b);
__inline__ __attribute__((always_inline)) int add_single2(int a, int b);
void add(const int *a, const int *b, int n, int * restrict sum)
{
for (int i = 0; i < (n & ~3); ++i)
{
// replace normal functions with inline functions
// sum[i] = add_single1(a[i], b[i]);
sum[i] = add_single2(a[i], b[i]);
}
}
-
長數(shù)據(jù)類型
neon 對 64 位長數(shù)據(jù)類型的支持有限,且較小的數(shù)據(jù)位寬有更高的并行度,應(yīng)盡量選用較小的數(shù)據(jù)類型。當(dāng)程序中存在浮點(diǎn)數(shù)據(jù)時(shí),指明其數(shù)據(jù)類型。
下述代碼指明1.0是浮點(diǎn)數(shù)據(jù),否則編譯器會優(yōu)先將其理解為double。
// assume that array sum and a are floating-point arrays
for (int i = 0; i < (n & ~3); ++i)
{
// replace 1.0 with 1.f
// sum[i] = a[i] + 1.0;
sum[i] = a[i] + 1.f;
}
B. 增加自動向量化信息
-
地址交疊
指針操縱同一片數(shù)據(jù)區(qū)的情況被稱為地址交疊。地址交疊會阻止自動向量化操作。
當(dāng)程序不會發(fā)生地址交疊時(shí),用 restrict 限定符(C99 引入)在代碼中聲明指針?biāo)竻^(qū)域是獨(dú)立的。
下述代碼通過restrict限定 sum 與 a、b 間沒有地址交疊的情況。
// add restrict before the output parameter sum
void add(const int *a, const int *b, int n, int * restrict sum)
-
數(shù)組尺寸
明確數(shù)組尺寸,使其達(dá)到向量化處理長度的整數(shù)倍。但應(yīng)注意處理不足向量化部分的剩余數(shù)據(jù)。
下述代碼通過掩碼操作表明處理循環(huán)次數(shù)是 4 的整數(shù)倍。
// make number of cycles is an integer multiple of 4,
for (int i = 0; i < (n & ~3); ++i)
// don't forget to process the remaining data
-
循環(huán)展開
在一些編譯器中可以通過在 for 循環(huán)之前增加預(yù)處理語句告知編譯器循環(huán)展開級數(shù)。
下述代碼告知 armclang 編譯器希望將循環(huán)展開 4 次。
// #pragma unroll (4) // armcc
#pragma clang loop interleave_count(4) //armclang
for (int i = 0; i < n; ++i)
{
// ...
}
-
結(jié)構(gòu)體加載
編譯器僅會對每一成員都有操作的結(jié)構(gòu)體加載操作進(jìn)行自動向量化,可以結(jié)合實(shí)際需求考慮去除用于結(jié)構(gòu)體對齊的填充數(shù)據(jù)。
下述代碼中刪除用于填充結(jié)構(gòu)體的變量 padding 以避免無法向量化。
struct st_align
{
char r;
char g;
char b;
// delete the data used to populate the structure
// char padding;
};
-
neon 加載指令要求結(jié)構(gòu)體中的所有項(xiàng)有相同的大小。
下述代碼中結(jié)構(gòu)體由于 short 類型與 char 類型不一致而不會被執(zhí)行自動向量化。
struct st_align
{
short r; // change short to char to get auto-vectoration
char g;
char b;
};
-
循環(huán)構(gòu)造
盡量通過
下述代碼通過調(diào)整i的范圍實(shí)現(xiàn)
// use '<' to construct a loop instead of '<='
// for(int i = 1; i <= n; ++i)
for (int i = 1; i < n + 1; ++i)
{
// ...
}
-
數(shù)組索引
當(dāng)對數(shù)組進(jìn)行操作時(shí),使用數(shù)組索引替代指針?biāo)饕?/span>
下述代碼通過 sum[i]進(jìn)行索引,而不是*(sum + i)。
// replace arrary with pointer
// *(sum + i) = *(a + i) + *(b + i);
sum[i] = a[i] + b[i];
C. 重排數(shù)據(jù)實(shí)現(xiàn)緩存友好
-
循環(huán)合并
當(dāng)數(shù)據(jù)連續(xù)存儲在結(jié)構(gòu)體中時(shí),可以進(jìn)行循環(huán)合并操作,即在一個(gè)循環(huán)內(nèi)處理臨近的數(shù)據(jù),提高緩存命中率。
下述代碼將 r、g、b 三個(gè)通道的處理合并到一個(gè)循環(huán)中。
// combine the rgb operation
/*
for (...)
{
pixels[i].r = ....;
}
for (...)
{
pixels[i].g = ....;
}
for (...)
{
pixels[i].b = ....;
}
*/
// cache friendly code
for (...)
{
pixels[i].r = ....;
pixels[i].g = ....;
pixels[i].b = ....;
}
四、總結(jié)
本章節(jié)主要介紹了自動向量化的相關(guān)內(nèi)容,其優(yōu)缺點(diǎn)對比如下:
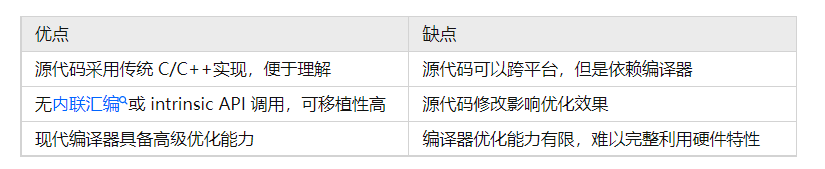
總之,雖然通過自動向量化技術(shù)我們可以在一定程度上降低向量化編程難度,增強(qiáng)代碼的可移植性,但是不能完全依賴于編譯器,而且有時(shí)為了獲得更高性能的代碼,還是需要通過intrinsic甚至neon匯編進(jìn)行編程。
審核編輯 :李倩
-
cpu
+關(guān)注
關(guān)注
68文章
10825瀏覽量
211151 -
C++
+關(guān)注
關(guān)注
22文章
2104瀏覽量
73496 -
編譯器
+關(guān)注
關(guān)注
1文章
1618瀏覽量
49051
原文標(biāo)題:Arm NEON學(xué)習(xí)(七)CPU 優(yōu)化技術(shù)-NEON 自動向量化
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
CPU優(yōu)化技術(shù)之自動向量化實(shí)例
小白快速上手Arm NEON編程手冊指南
簡述ARM SVE的發(fā)展以及和NEON的區(qū)別來探討Vector在AI中的應(yīng)用
使用SVE對HACCmk進(jìn)行矢量化的案例研究
如何使用Arm Compiler 6自動矢量化功能為Neon編譯
RealView編譯工具NEON矢量化編譯器指南
NEON音頻編解碼器優(yōu)化技術(shù)
發(fā)掘函數(shù)級單指令多數(shù)據(jù)向量化的方法
基于Matrix的Givens旋轉(zhuǎn)的QR分解向量化方法

控制流SIMD向量化方法

DSP的并行指令分析和冗余優(yōu)化算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論