") 全社會性自動駕駛重構計算模型
全社會性自動駕駛重構計算模型
元宇宙是人類社會網(wǎng)絡化和虛擬化,通過對實體對象對應生成數(shù)字”智能體”來構建一個人機共存的新社會形態(tài)。元宇宙去中心化+AI化+虛擬化的底層網(wǎng)絡融合架構,是當前在萌芽中的下一代互聯(lián)網(wǎng)web3.0的社會實踐。
元宇宙零距離社會里的社會計算,是一種數(shù)據(jù)經(jīng)濟行為的計算,即通過區(qū)塊鏈的智能合約來構建數(shù)字經(jīng)濟中的數(shù)據(jù)資產(chǎn),對于隱私數(shù)據(jù)存儲提供可信計算和高可信度服務,借助數(shù)據(jù)交易和權益計算來產(chǎn)生經(jīng)濟效益,Web3的布局與發(fā)展預計將超過當前邊緣地域政治的影響,可能會徹底顛覆全球經(jīng)濟次序。 對于自動駕駛ADS行業(yè),我們也可以將其核心演進趨勢定義為群體智能的社會計算,簡單表述為,用NPU大算力和去中心化計算來虛擬化駕駛環(huán)境,通過數(shù)字化智能體(自動駕駛車輛AV)的多模感知交互(社交)決策,以及車車協(xié)同,車路協(xié)同,車云協(xié)同,通過跨模數(shù)據(jù)融合、高清地圖重建、云端遠程智駕等可信計算來構建元宇宙中ADS的社會計算能力。
群體智能:多智能體間的社交決策
在真實的交通場景里,一個理性的人類司機在復雜的和擁擠的行駛場景里,通過與周圍環(huán)境的有效協(xié)商,包括揮手給其它行駛車輛讓路,設置轉(zhuǎn)向燈或閃燈來表達自己的意圖,來做出一個個有社交共識的合理決策。而這種基于交通規(guī)則+常識的動態(tài)交互,可以在多樣化的社交/交互駕駛行為分析中,通過對第三方駕駛者行為和反應的合理期望,來有效預測場景中動態(tài)目標的未來狀態(tài)。這也是設計智能車輛AV安全行駛算法的理論基礎,即通過構建多維感知+行為預測+運動規(guī)劃的算法能力來實現(xiàn)決策安全的目的。而會影響到車輛在交互中的決策控制的駕駛行為包括駕駛者(人或AV)的社會層面交互和場景的物理層面交互兩個方面:
社會層面交互:案例包括行駛車輛在并道、換道、或讓道時的合理決策控制,主車道車輛在了解其它車輛的意圖后自我調(diào)速,給需要并換道的車輛合理讓路來避免可能的沖突和危險。
物理層面交互:案例包括靜態(tài)物理障礙(靜態(tài)停車車輛,道路可行駛的邊界,路面障礙物體)和動態(tài)物理線索(交通標識,交通燈和實時狀態(tài)顯示,行人和運動目標)。
ADS群體智能的社會計算,對這種交互/社交行為,可以在通常的定義上擴展,也就是道路使用者或者行駛車輛之間的社交/交往,即通過彼此間的信息交換、協(xié)同或者博弈,實現(xiàn)各自利益最大化和獲取最低成本,這一般包括三個屬性(Wang 2022):
動態(tài)Dynamics:個體之間和個體與環(huán)境之間的閉環(huán)反饋(State,Action, Reward),駕駛?cè)?智能體AV對總體環(huán)境動態(tài)做出貢獻,也會被總體環(huán)境動態(tài)所影響。
度量Measurement: 信息交換,包括跨模數(shù)據(jù)發(fā)布與共享,駕駛?cè)?智能體AV對道路使用者傳遞各自的社交線索和收集識別外部線索。
決策Decision: 利益/利用最大化,理性來說道路使用者追求的多是個體的最大利益。
顯然,交通規(guī)則是不會完全規(guī)定和覆蓋所有駕駛行為的,其它方面可以通過個體之間的社交/交互來補充。人類司機總體來說也不會嚴格遵守交通規(guī)則,類似案例包括黃燈初期加速通過路口,讓路時占用部分其它道路空間來減少等待時間等等。ADS通過對這類社會行為的收集、學習與理解,可以部分模仿和社會兼容,通過Social-Aware和Safety-Assured決策,避免過度保守決策,同時提供算法模型的可解釋性、安全性能和控制效率。具體實現(xiàn)來說,可以采用類似人類司機的做法,依據(jù)駕駛?cè)蝿盏牟煌褂铆h(huán)境中不同的關注區(qū)域ROI和關注時間點,以及直接或間接的社交/交互,采用類似概率圖模型和消息傳遞等機制來建模。社交影響因子的度量,即在給定駕駛環(huán)境狀態(tài)x下,個體如何采取action a,一般有兩種思路(Wang 2022) :
基于模型驅(qū)動的方法
模型參數(shù)多采用個體間物理距離和速度加速度等傳感信息。
基于利用率Utility-based的模型:將個體之間交互作為一個優(yōu)化問題來考慮
案例:換道并道操作,目標是保持理想的速度(徑向控制)下如何使側(cè)向路徑跟蹤誤差最小化(側(cè)向控制)
概率生成模型:采用貝葉斯網(wǎng)絡的條件概率分布或條件行為預測來評估
案例:導航,通過對周圍個體行為的概率預測,并結合安全風險特征進行逆優(yōu)化
基于風險的模型:將交通規(guī)則域知識與駕駛場景的背景嵌入到可解釋可學習的勢或能量函數(shù)中
問題:基于相對距離的測量不能反映真實場景的物理約束,例如高速公路的分道桿幾乎與行駛車輛沒有交互。
社會認知模型:
案例:類似心理學的讀心術來模仿個體的駕駛行為。
基于數(shù)據(jù)驅(qū)動的方法
駕駛環(huán)境的虛擬化,即在圖模型中將環(huán)境中的隱含信息(圖節(jié)點和關系)用低維標量或者向量(embedding)來表征。
DNN:
采用Autoencoder、Transformer或GAN來建模,通過CONV/RNN層將多傳感信息映射成低維向量。
GNN with Social Pooling:
GNN:
○可以將結構化信息嵌入embedding來做為模型輸入。
○或?qū)⑸缃魂P系用特定圖邊的可學習的參數(shù)來量化,即weighted graph edges。
Social Pooling:
○ 可以獨立地將信息嵌入時間空間維度下的latent狀態(tài)。
拓撲模型:
將個體間交互編碼成一個代數(shù)幾何的緊湊表征。
對單智能體而言,上述群體智能的社會計算表述,有一個典型的優(yōu)勢是,人類駕駛的社會關聯(lián)特性和超強駕駛模仿特性,可以在算法設計中采用關聯(lián)強化的reward函數(shù)來學習人類的這種社會群體跟隨特性。而人類群體對隱含場景的社會感知,可以更好地提高對環(huán)境遮擋的認知理解和進行不確定性的概率預測。
優(yōu)化建模與學習方法
ADS的一個最常見的交互場景是在城市和高速公路上的日常交通行為,包括車輛跟隨,車輛換道,主路輔路并道等。上述所表述的Utility-based的理性模型,采用的是基于目標函數(shù)進行優(yōu)化的模型,需要定義一個目標,例如在前行方向的車輛之間有一個可用的空閑空間。一種設計思路是假定人類駕駛行為基本上就是一個游戲理論問題,存在著多智能體的互相耦合連續(xù)決策。這種交互或社交,可以用動態(tài)Markov游戲來建模,單體之間通過合作或競爭來完成任務,即所謂的多智能體強化學習Multi-AgentReinforcement Learning(MARL),將環(huán)境定義為Markov決策過程(MDP)或者是部分可觀察的POMDP。解決的思路的引入下述的方法來摹擬交互過程中的決策控制:
游戲理論方法:包括強化學習RL,逆強化學習IRL和模仿學習IL等。
控制理論方法:模型預測控制MPC,線性二次元高斯控制LQGC等。
上述將將社交行為轉(zhuǎn)化成遞歸優(yōu)化問題,對目標個體而言,對其它智能體的角色和整體效果的定位,如圖1所示,可以有三種:
障礙Obstacles關系:基于對其它運動目標的行為和運動預測來規(guī)劃個體自身,視預測不可更改,這種單向社交,在部分場景會導致目標個體過度保守、困于僵局或有不安全行為。
理性跟隨者Rational Follower關系: 這種定義假定其它個體基于自身利用率進行優(yōu)化決策,對目標個體的行為沒有預判和響應,會導致目標個體的動作/響應難以取得最優(yōu)解。
相互依賴群體關系:這種假定可以通過戰(zhàn)略和戰(zhàn)術規(guī)劃來實現(xiàn),戰(zhàn)略規(guī)劃可以建模成一個閉環(huán)的動態(tài)游戲,戰(zhàn)術規(guī)劃可以建模成一個開環(huán)的軌跡規(guī)劃與優(yōu)化。或者通過多智能體的同步游戲來捕獲動態(tài)的交互依賴,解決沖突問題。對目標個體而言,可以只考慮局部鄰近個體,通過個體間通信可以減少所有關聯(lián)個體存在的類似同時減速或者同時停車讓路等算法陷阱問題。
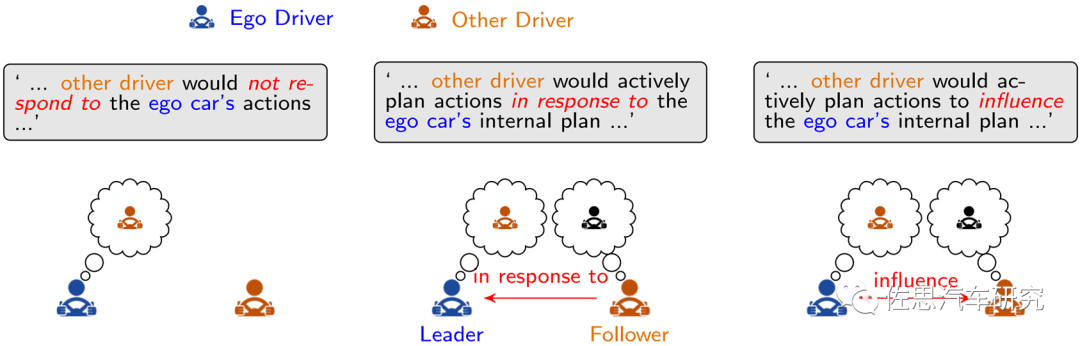
圖1 多智能體社交關系案例分析(Wang 2022) 顯然在ADS中直接引入游戲理論框架,可解釋性強,但隨著參與交互的個體數(shù)目和場景復雜度增加,計算復雜度也會指數(shù)比例增加,工程實現(xiàn)會比較困難。 人類駕駛者可以通過獎勵強化機制來與環(huán)境進行安全交互。這種機制推動了ADS行業(yè)采用游戲理論中強化學習方案,通過同步或者異步處理模式,來獲取個體間的交互。一種可行的方法將遞歸的政策Policy學習任務定義為單智能體的single-agent RL學習問題,者涉及到states, actions, reward和動態(tài)環(huán)境參數(shù)。異步實現(xiàn)的算法包括DeepQ-Learning (DQN),D3QN等,這種單體RL方案由于假定其它個體的戰(zhàn)略行為不變性,很容易導致不穩(wěn)定的控制政策,難以解決不安全行駛風險。而同步實現(xiàn)方案,環(huán)境狀態(tài)的進化和激勵來自群體交互和聯(lián)合行動,每個智能體都視為MDP-based Agent,共同進行多智能體強化學習MARL。同步實現(xiàn)的算法目前受限于有限的交通場景,個體間的社會特性都是預定義的,解決這個問題的一個可行思路是采用課程學習的策略,從簡單場景開始來一步步來進行深化學習。
在ADS中引入游戲理論框架的另外一個風險是環(huán)境信息的不完全性(部分可觀察),假定駕駛者都是理性的,每個駕駛者的意圖都能夠被第三方獲取。在實際交通環(huán)境中,信息獲取的不對稱性比比皆是。同時對于非理性的駕駛行為,如果在保證有安全保障的決策控制的前提下,一定程度的同情心或者同理心是非常有必要的。一種思路是引入一對社會參數(shù)(β, λ)來對道路上駕駛者的理性水平和角色,通過貝葉斯規(guī)則觀察進行參數(shù)更新。
上述的討論分析,可以將駕駛者的決策過程,轉(zhuǎn)化為對部分可觀察環(huán)境虛擬化或參數(shù)化,同時對個體間社交選擇的偏愛進行參數(shù)化,嵌入到價值函數(shù)中去,通過基于優(yōu)化的狀態(tài)反饋策略,尋求駕駛?cè)后w利益最大化問題的最優(yōu)解。一個通常的解決思路是,將其它個體的獎勵函數(shù)表征為當前狀態(tài)的線性結構化的加權特征,對應的權值向量,可以通過逆最優(yōu)控制理論(例如IRL )來進行學習估計,IRL的目的是從人類駕駛演示的駕駛偏向中學習底層的目標函數(shù),通過將IRL編碼的人類駕駛行為集成到AV的目標函數(shù)中來構建能夠社會性兼容的行駛控制。
在ADS動態(tài)和不確定性的場景中,環(huán)境需要建模成部分可觀察的MDP即POMDP,為了降低計算復雜度,一般都選擇離散化空間或者部分連續(xù)空間來解決POMDP問題。對不確定性信息評估的一種常用的做法是對當前狀態(tài)進行概率分布進行構建,得到一個置信(belief)狀態(tài),這種形態(tài)可以通過離線或者在線構建。離線計算意味著,不是針對當前狀態(tài),而是對所有可能的置信狀態(tài)的最可能的行為,在線計算意味著需要在精度和效率之間做權衡。 上述提到的將駕駛環(huán)境視為一個Markov決策過程MDP,一個設計思路是Q-Learning(DQN, D2QN, D3QN)算法,它屬于Single-AgentMDP方法,即將其它道路使用者視為穩(wěn)態(tài)環(huán)境的一部分。自體(ego agent)通過與環(huán)境的交互/社交來尋求關聯(lián)累計獎勵a的最優(yōu)方案,即在一個固定時間窗T范圍內(nèi),在環(huán)境狀態(tài)s下policy政策π的價值函數(shù)優(yōu)化問題 ADS的交互性決策控制,是一個典型的多目標問題,包括行駛的安全保證、整體效率和舒適體驗。D2QN和D3QN的優(yōu)勢在Q函數(shù)值表達中引入了防止碰撞的思路,但學習效率和最終性能仍然低于應用預期。一種設計思路是將模仿學習IL與RL 相結合(IRL)。IL有兩種學習模式:
行為克隆方法Behaviour Cloning:直接學習從觀察到行動actions的映射關系,尋求目標的似然函數(shù)最大化或者誤差最小化,需要有足夠的訓練數(shù)據(jù)為前提,但在復雜的交互場景下的域自適應能力表現(xiàn)不佳。
利用率重建 Utility Recovering: 這種IRL學習方法,非直接利用數(shù)據(jù)通過觀察來獲取獎勵函數(shù),從而使規(guī)劃車輛的社交行為能夠近可能的摹擬演示效果。這種假設與人類駕駛行為非常接近,尤其是如何在不同類型的新場景下如何安全有效地與其它駕駛者的進行交互。IRL的目的是通過摹擬自體的駕駛行為從數(shù)據(jù)中學習自體獎勵函數(shù)。
總上所述,在動態(tài)場景中,由于理性的人類駕駛行為是所有可能的解決方案中,最接近最優(yōu)的決策輸出,這種觀察可以將人類駕駛交互用計算可表達優(yōu)化模型來公式化。這種基于優(yōu)化的方法從分析角度來說可解釋,數(shù)學上可證明,可以添加各種約束條件來避免碰撞,但如何降低復雜度來滿足計算性能是非常有挑戰(zhàn)的。
DNN-based模型
基于DNN模型的方法,是一種在數(shù)據(jù)充分的條件下,通過少量的人力投入就可以提供非常有力的設計表達。尤其是針對社交關系建模與推理來解決ADS中預測與規(guī)劃問題,通過監(jiān)督和自監(jiān)督學習的方式,單獨或者聯(lián)合建模的方式,以及IL和RL的學習流程。交互建模的輸入來自車輛狀態(tài),包括定位信息,速度,加速度,角速度,車輛朝向等。端到端的DL-based方法通常直接通過卷積處理原始傳感數(shù)據(jù)(RGB圖像和點云),計算簡潔但會損失弱的或者隱含的交互推理的內(nèi)容表達。如圖2所示,深度學習模型中的不同構建模塊,是可以對多智能體的交互推理進行有效建模和表達的,其中
(a)全連接FC層:又稱多層感知器MLP,其中所有輸入通過連接可以與輸出交互并對輸出做出貢獻。
(b)卷積CONV層:卷積層采用局部感知場,所以每層的連接會比較稀疏,通常假定合適用來捕獲空間關系,最初的底層卷積層一般提取類似邊緣紋理類的信息,越接近頂層也偏語義特征。
(c)遞歸Recurrent層 :通常用來處理時間維度的數(shù)據(jù)序列,多用來捕獲時間關系。
(d)圖Graph層:典型的圖包括節(jié)點、邊(用來描述節(jié)點間關系)、和上下文全局屬性,通常用來捕獲圖結構表征中顯性關系推理,與FC層和RNN層一個不同之處是輸入的先后次序不會影響結構,圖結構還可以處理不同數(shù)目的個體,比較適合多個體的ADS環(huán)境。
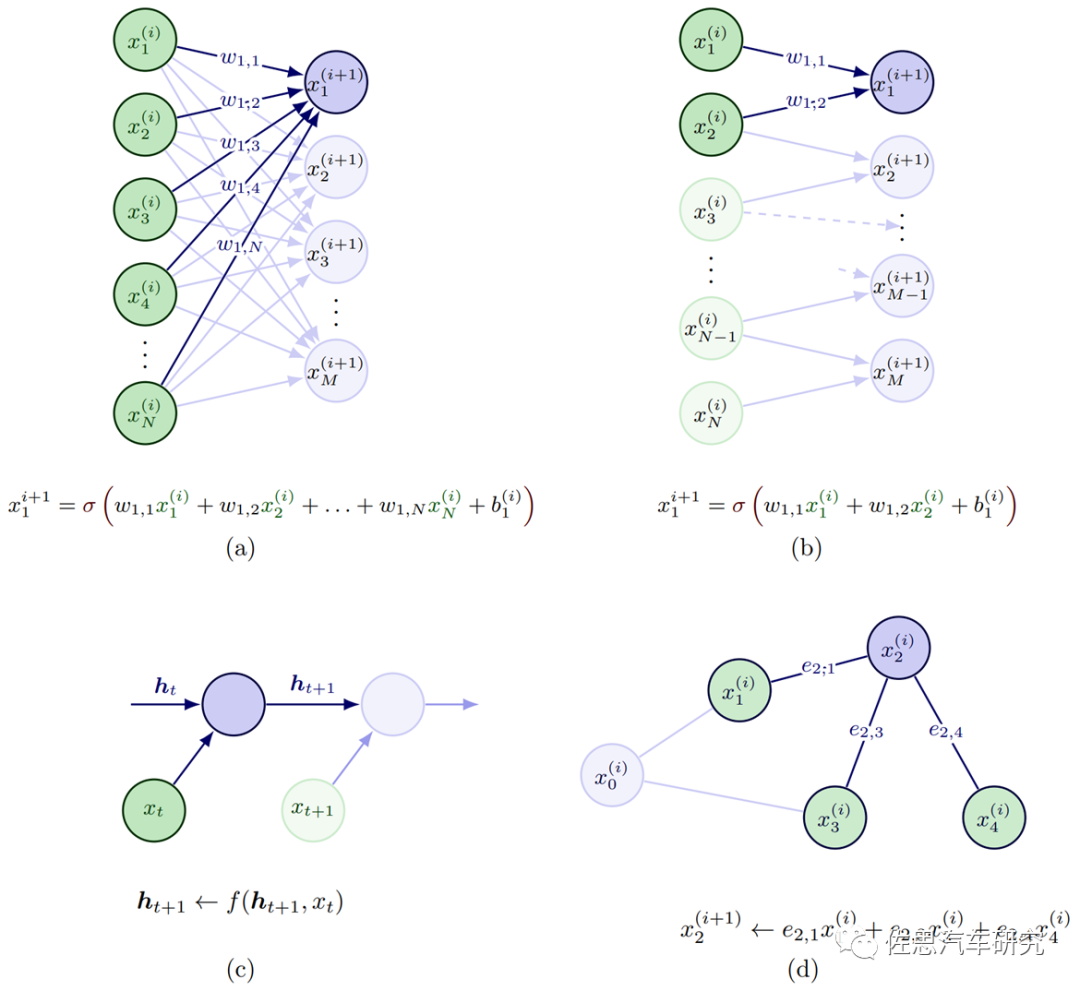
圖2 DNN模塊對多智能體交互的建模案例(Wang 2022)
對于ADS中社交特征表征,常用的有空間時間狀態(tài)特征矢量,空間占用方格和圖區(qū)域動態(tài)插入等方式。空時狀態(tài)特征矢量比較難以定義,尤其是個體數(shù)量變化和有效時間步長的不同,另外一個限制是依賴于個體插入的次序。所以一個常用的設計思路是采用占用方格地圖Occupancy Grid Map (OGM)來解決上述的兩個問題。OGM是以本體ego agent為中心來構建空間方格圖,可以處理ROI區(qū)域不同數(shù)目的智能體。OGM通常采用原始狀態(tài)(定位,速度,加速度)或者采用FC層來進行狀態(tài)編碼,如果FC層隱層包括個體的歷史軌跡信息,可以同時捕獲空間時間信息。OGM的分辨率對計算性能影響比較大。
相對而言,圖網(wǎng)絡GNN可以通過動態(tài)插入?yún)^(qū)域DIA抽取來更好地構建空間時間交互圖關系,圖的類型可以基于個體(車輛,行人,機動車等),也可以基于區(qū)域area,后者主要聚焦對車輛意圖(車道保持,換道并道,左拐右拐)的表征,這里DIA指的是可駕駛場景中空閑空隔。如圖3所示,DIA的優(yōu)勢在于對環(huán)境中靜態(tài)元素(道路拓撲,類似stop道路標志牌等)和動態(tài)元素(行駛車輛)非常靈活,可以認為是動態(tài)環(huán)境的統(tǒng)一表征或者也可以叫做環(huán)境的虛擬化。所有時間地平線的DIAs可以用來構建空間時間語義圖。

圖3 動態(tài)插入?yún)^(qū)域抽取和場景語義圖 構建案例(Wang 2022)
如圖2所示,群體智能的社會計算,其中的社交關系,可以采用不同的深度學習層來進行交互建模和編碼:
FC層交互編碼:采用將不同個體的特征進行拉平,拼接成一個向量。多用來對單體single agent進行運動和意圖建模,很少用于multiple agent。
CONV層交互編碼:將空間時間特征(狀態(tài)特征張量)或占用方格地圖做為CNN輸入來進行交互編碼。
Recurrent層交互編碼:多采用LSTM來進行時間維度推理,編碼產(chǎn)生的embedding張量可以捕獲時間空間的交互信息。
Graph層交互編碼:對多智能體之間的關系采用節(jié)點之間的無向或者有向邊來表征,可以用消息傳遞機制來進行交互學習,每個節(jié)點通過聚集鄰近節(jié)點的特征來更新自身的屬性特征。
在實際設計中,多將Recurrent層和Graph層相結合,可以很好地處理時間信息。而注意力attention機制編碼可以更好地量化一個特征如何影響其它特征。人類司機會在交互場景中有選擇地選取其它個體來進行關注,包括其過去現(xiàn)在的信息和未來的預判。所以注意力機制編碼可以基于時間域(短期的和長期的)和空間域(本地的和偏遠的),在上述方法中通過加權方案分別進行應用。對個體的注意力建模,可以采用基于距離的方法,這意味著其它個體越近,關注度也越高。 綜上所述,DL-based方法由于模塊化的設計和海量數(shù)據(jù)貢獻,性能占優(yōu),但如何能夠提供安全能力和大規(guī)模部署,需要解決幾個挑戰(zhàn):在保證性能基礎上改善可解釋性;在不同的駕駛個體,場景和態(tài)勢下繼續(xù)增強模型的推廣能力。
審核編輯 :李倩
-
貝葉斯網(wǎng)絡
+關注
關注
0文章
24瀏覽量
8290 -
智能體
+關注
關注
1文章
131瀏覽量
10567 -
自動駕駛
+關注
關注
783文章
13682瀏覽量
166144
原文標題:全社會性自動駕駛重構計算模型
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

標貝科技:自動駕駛中的數(shù)據(jù)標注類別分享

Apollo自動駕駛開放平臺10.0版即將全球發(fā)布
Waymo利用谷歌Gemini大模型,研發(fā)端到端自動駕駛系統(tǒng)

自動駕駛HiL測試方案案例分析--ADS HiL測試系統(tǒng)#ADAS #自動駕駛 #VTHiL
自動駕駛技術的典型應用 自動駕駛技術涉及到哪些技術
FPGA在自動駕駛領域有哪些優(yōu)勢?
FPGA在自動駕駛領域有哪些應用?
百度發(fā)布全球首個L4級自動駕駛大模型
智能駕駛大模型:有望顯著提升自動駕駛系統(tǒng)的性能和魯棒性
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
邊緣計算與自動駕駛系統(tǒng)如何結合
【量子計算機重構未來 | 閱讀體驗】+ 初識量子計算機
LabVIEW開發(fā)自動駕駛的雙目測距系統(tǒng)
自動駕駛“十問十答”





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論