 輻射場的實時密集單眼SLAM簡析
輻射場的實時密集單眼SLAM簡析
摘要
我們提出了一個新的幾何和光度3D映射管道,用于從單眼圖像中準確和實時地重建場景。為了實現這一目標,我們利用了最近在密集單眼SLAM和實時分層容積神經輻射場方面的進展。我們的見解是,密集的單眼SLAM通過提供準確的姿勢估計和具有相關不確定性的深度圖,為實時適應場景的神經輻射場提供了正確的信息。
通過我們提出的基于不確定性的深度損失,我們不僅實現了良好的光度測量精度,還實現了巨大的幾何精度。事實上,我們提出的管道比競爭對手的方法實現了更好的幾何和光度測量精度(PSNR提高了179%,L1深度提高了86%),同時實時工作并只使用單眼圖像。
主要貢獻
我們提出了第一個結合密集單眼SLAM和分層體積神經輻射場優點的場景重建管道。
我們的方法從圖像流中建立精確的輻射場,不需要姿勢或深度作為輸入,并且可以實時運行。
我們在Replica數據集上實現了單眼方法的最先進性能。
主要方法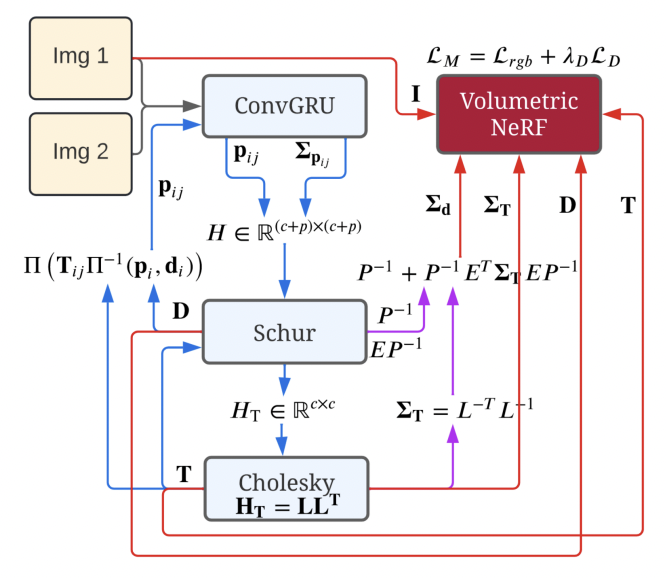
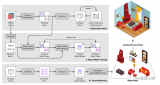
我們管道的輸入包括連續的單眼圖像(這里表示為Img 1和Img 2)。從右上角開始,我們的架構使用Instant-NGP擬合一個NeRF,我們使用RGB圖像I和深度D對其進行監督,其中深度由其邊緣協方差ΣD加權。
受Rosinol等人[23]的啟發,我們從密集的單眼SLAM計算這些協方差。在我們的案例中,我們使用Droid-SLAM。我們在第3.1節提供了關于信息流的更多細節。藍色顯示的是Droid-SLAM的貢獻和信息流,同樣,粉紅色是Rosinol的貢獻,而紅色是我們的貢獻。
1. 追蹤
密集SLAM與協方差 我們使用Droid-SLAM作為我們的跟蹤模塊,它為每個關鍵幀提供密集的深度圖和姿勢。從一連串的圖像開始,Droid-SLAM首先計算出i和j兩幀之間的密集光流pij,使用的架構與Raft相似。
Raft的核心是一個卷積GRU(圖2中的ConvGRU),給定一對幀之間的相關性和對當前光流pij的猜測,計算一個新的流pij,以及每個光流測量的權重Σpij。
有了這些流量和權重作為測量值,DroidSLAM解決了一個密集束調整(BA)問題,其中三維幾何被參數化為每個關鍵幀的一組反深度圖。這種結構的參數化導致了解決密集BA問題的極其有效的方式,通過將方程組線性化為我們熟悉的相機/深度箭頭狀的塊狀稀疏Hessian H∈R (c+p)×(c+p) ,其中c和p是相機和點的維度,可以被表述為一個線性最小二乘法問題。
從圖中可以看出,為了解決線性最小二乘問題,我們用Hessian的Schur補數來計算縮小的相機矩陣HT,它不依賴于深度,維度小得多,為R c×c。通過對HT=LLT的Cholesky因子化,其中L是下三角Cholesky因子,然后通過前置和后置求解姿勢T,從而解決相機姿勢的小問題。
此外,給定姿勢T和深度D,Droid-SLAM建議計算誘導光流,并再次將其作為初始猜測送入ConvGRU網絡,如圖2左側所示,其中Π和Π-1,是投影和背投函數。
圖2中的藍色箭頭顯示了跟蹤循環,并對應于Droid-SLAM。然后,受Rosinol等人的啟發,我們進一步計算密集深度圖和Droid-SLAM的姿勢的邊際協方差(圖2的紫色箭頭)。
為此,我們需要利用Hessian的結構,我們對其進行塊狀分割如下: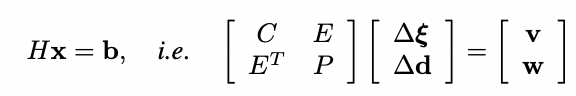
其中H是Hessian矩陣,b是殘差,C是塊狀相機矩陣,P是對應于每個像素每個關鍵幀的反深度的對角矩陣。我們用?ξ表示SE(3)中相機姿態的謊言代數的delta更新,而?d是每個像素反深度的delta更新。
E是相機/深度對角線Hessian的塊矩陣,v和w對應于姿勢和深度的殘差。從這個Hessian的塊分割中,我們可以有效地計算密集深度Σd和姿勢ΣT的邊際協方差: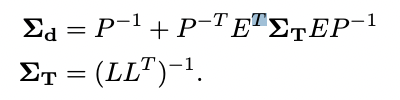
最后,鑒于跟蹤模塊計算出的所有信息--姿勢、深度、它們各自的邊際協方差以及輸入的RGB圖像--我們可以優化我們的輻射場參數,并同時完善相機的姿勢。
2. 建圖
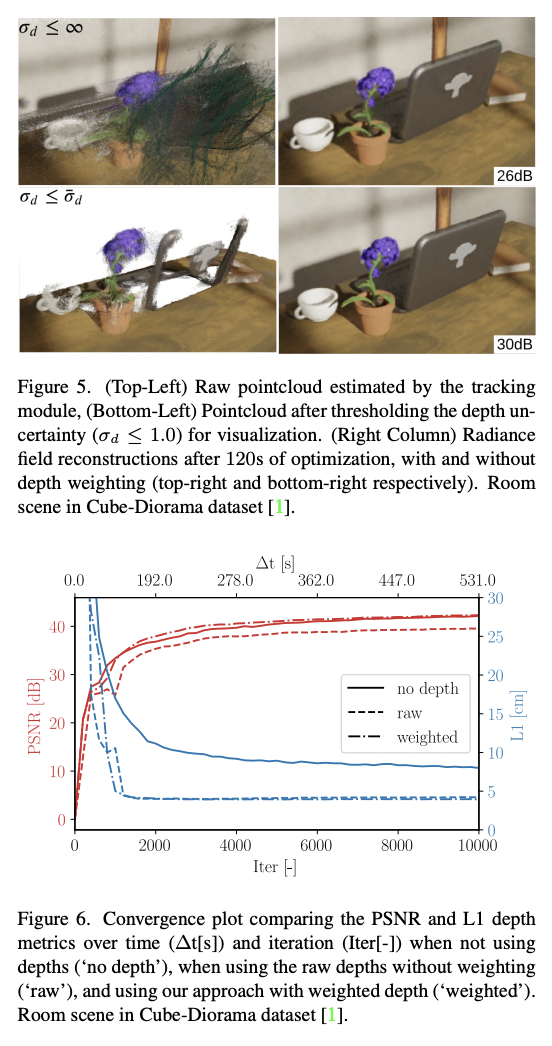
鑒于每個關鍵幀的密集深度圖,有可能對我們的神經體積進行深度監督。不幸的是,由于其密度,深度圖是非常嘈雜的,因為即使是無紋理的區域也被賦予了一個深度值。圖3顯示,密集的單眼SLAM所產生的點云是特別嘈雜的,并且包含大的離群值(圖3的頂部圖像)。
根據這些深度圖監督我們的輻射度場會導致有偏見的重建。 Rosinol等人的研究表明,深度估計的不確定性是一個很好的信號,可以為經典的TSDF體積融合的深度值加權。受這些結果的啟發,我們使用深度不確定性估計來加權深度損失,我們用它來監督我們的神經體積。
圖1顯示了輸入的RGB圖像,其相應的深度圖的不確定性,所產生的點云(在用σd≤1.0對其不確定性進行閾值化以實現可視化),以及我們使用不確定性加權的深度損失時的結果。鑒于不確定性感知的損失,我們將我們的映射損失表述為: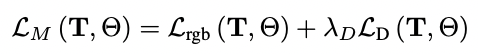
我們對姿勢T和神經參數Θ進行最小化,給定超參數λD來平衡深度和顏色監督(我們將λD設置為1.0)。特別是,我們的深度損失是由以下公式給出的。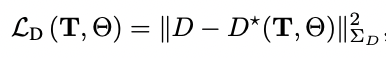
其中,D*是渲染的深度,D、ΣD是由跟蹤模塊估計的密集深度和不確定性。我們將深度D*渲染為預期的射線終止距離。每個像素的深度都是通過沿著像素的射線取樣的三維位置來計算的,在樣本i處評估密度σi,并將得到的密度進行alpha合成,與標準的體積渲染類似: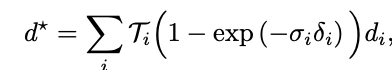
顏色的渲染損失如下: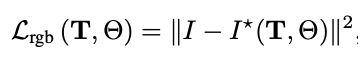
3. 架構
我們的管道由一個跟蹤線程和一個映射線程組成,兩者都是實時和并行運行的。追蹤線程不斷地將關鍵幀活動窗口的BA重投影誤差降到最低。
映射線程總是優化從跟蹤線程收到的所有關鍵幀,并且沒有一個有效幀的滑動窗口。這些線程之間的唯一通信發生在追蹤管道生成新關鍵幀時。
在每一個新的關鍵幀上,跟蹤線程將當前關鍵幀的姿勢與它們各自的圖像和估計的深度圖,以及深度的邊際協方差,發送到映射線程。
只有跟蹤線程的滑動優化窗口中當前可用的信息被發送到映射線程。跟蹤線程的有效滑動窗口最多包括8個關鍵幀。
只要前一個關鍵幀和當前幀之間的平均光流高于一個閾值(在我們的例子中是2.5像素),跟蹤線程就會生成一個新的關鍵幀。最后,映射線程還負責渲染,以實現重建的交互式可視化。
主要結果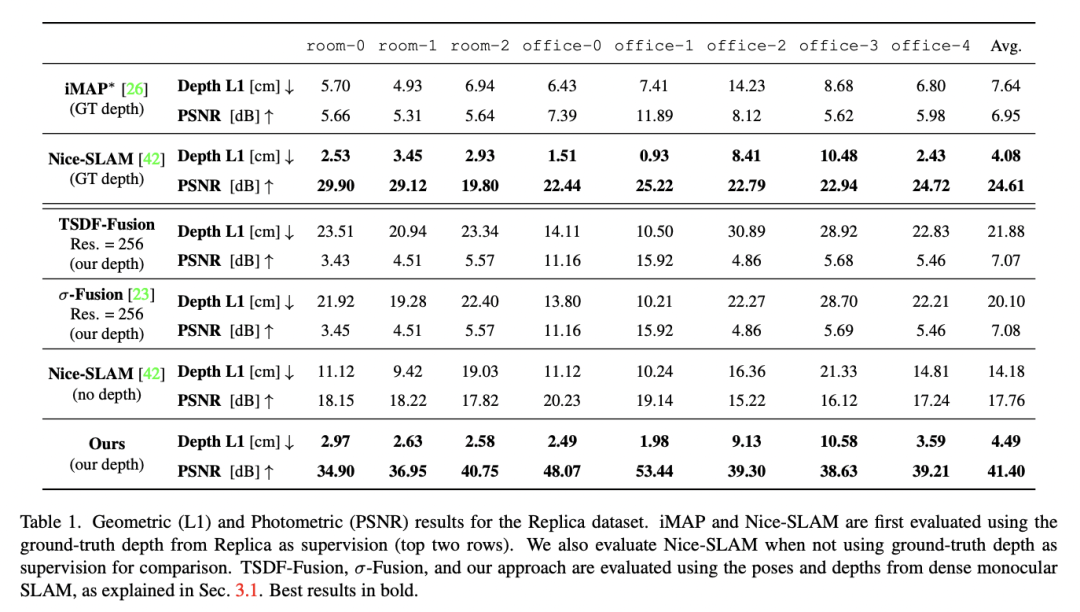

審核編輯:劉清
-
Gru
+關注
關注
0文章
12瀏覽量
7470 -
SLAM
+關注
關注
23文章
405瀏覽量
31713 -
NGP
+關注
關注
0文章
12瀏覽量
6665
原文標題:NeRF-SLAM:實時密集單眼SLAM 輻射場的實時密集單眼SLAM
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論