 文本分割技術的應用場景
文本分割技術的應用場景
寫在前面
之前看了一篇很不錯的外文博客,結合自己查閱學習的一些論文和資料,加上自己的理解,整理了一些內容,準備來跟大家分享關于文本分割任務的相關內容。
文本分割任務的目的是將文本劃分為若干有意義的文本塊,不同的分割目的有不同的分割粒度,比如:詞、句子或者主題。
今天我們將要分享的文本分割任務的分割粒度聚焦在主題上,這類文本分割任務也稱為主題分割:識別文本主題的過渡從而將長文本劃分若干具有不同主題的文本塊。
1. 不同的文本形式
文本分割非常實用。在日常生活學習中,我們會接觸到各種各樣的文本:
- 書面文本,如:博客、文章、新聞等
-
各種轉錄文本(即記錄文本):
- 電視新聞的轉錄
- 播客的轉錄
- 電話的轉錄
- 在線會議的轉錄
這些文本通常都非常長,需要利用文本分割技術來處理這些文本,將它們按照主題的轉移或變化劃分為若干主題段落,每個主題段落內部所表達的主題一致且連貫,不同主題段落間則描述不同的主題。
當然,針對不同的文本,“主題”定義不同。比如:新聞文本分割中,主題可能是指一則新聞故事(Story);在線會議轉錄文本分割中,主題可能指的是不同的會議議題。無論“主題”代表的是什么,利用文本分割技術劃分長文本最直接的目的都是增加文本的可讀性。
當然以上這些文本中可能含有各種會影響文本分割結果的噪聲,最常見的就是錯別字。當然在英文場景下還可能有拼寫錯誤、語法錯誤,在自動轉錄的情況下出現使用不當的單詞。
轉錄需要自動識別語音并將所說的內容轉錄成等效的書面格式(依賴ASR技術),所以通常來說相對于書面文本,轉錄文本中含有更多的噪聲,尤其是在線會議的轉錄文本。這點很容易理解,因為在線會議中,參會人有各種各樣的口音、網絡連接質量也常常不太穩定、參會人使用的介質(麥克風)的質量也參差不齊。
2. 文本分割技術的應用場景
通過前面的介紹,我們已經了解了文本分割(主題分割)任務是什么以及它所處理的文本的各種形式,現在我們一起來看看文本分割的應用場景。
2.1 增加可讀性
現在給你兩篇文章:一篇沒有任何章節名稱、沒有任何段落,就只是長長的文本字符串;另一篇分段合理,每個自然段落過渡合理,邏輯自洽。
你愿意讀哪一篇?不用想,當然是第二篇。文本分割最基礎的作用就是將冗長的文本劃分為讀者更易閱讀的一個個文本塊,也就是把形如第一篇的文章變成第二篇。
2.2 更全面的摘要
文本摘要技術是用于總結提煉文章的。通常我們在閱讀文章前,可以先通過文章的摘要了解內容概況,如果感興趣再逐字逐句進行精讀。就跟我們挑選要去電影院看的電影一樣,先看簡介,看看是不是自己的菜,免得浪費電影票和自己的時間。
但是,多數文本摘要模型在處理多主題的文章上效果還沒那么好,生成的摘要通常很難囊括文章所涵蓋的所有主題。
在處理多主題文章時,一個很直接且有效的解決方案就是,先利用文本分割模型將文章分成若干個具有不同主題的文本塊,再利用摘要模型為每個文本塊生成摘要,在進行進一步的組織和編排。
2.3 視頻轉文章
融合媒體時代,新聞報道需要以不同的形式(如:視頻、文章、博客等)分發至不同的渠道(如:短視頻app、微信、微博等)。借助ASR技術,我們可以將新聞視頻中的語音文本提取出來并轉化成書面格式。為增加可讀性,再利用文本分割技術將轉換的書面文本劃分成有意義的段落,組織成更適合閱讀的形式。
當然文本分割技術在信息檢索、寫作助手、對話建模等等其他NLP下游任務上也有其相應的應用。
3. 文本分割任務的評價指標
文本分割任務是識別文本主題的過渡從而將長文本劃分若干具有不同主題的文本塊。所以,如下圖所示文本分割模型實際上就是在對文本中的每個句子進行二分類,判斷每個句子是否是分割邊界(也就是文本塊的最后一句)。

在這樣一個任務上,比較常用的評價指標有:Precision&Recall(也就是我們在《二分類任務評價指標(中)》介紹過的查準率和查全率)、Pk、WindowDiff。
3.1 Precision & Recall
3.1 Precision & Recall的含義
既然文本分割(主題分割)本質上是在句子級的二分類任務,那么自然可以使用Precision與Recall,對應的含義如下:
- Precision(查準率):衡量了“被判別為分割邊界的句子中有多少比例是真正的邊界” ;
- Recall(查全率):衡量了“所有真正的分割邊界中有多少比例被模型識別出來了” ;
3.2 Precision & Recall 的問題
然而,Precision&Recall這兩個指標對“near miss”不敏感。

在上圖中,Ref 是 ground truth,每個塊代表一個句子,垂直線表示真實的分割邊界。A-0 與 A-1 是兩個文本分割模型。
從圖中可以清楚地看到,模型 A-0 預測的分割邊界非常接近 ground truth,這就是所謂的“near miss”,即預測結果與真實結果偏離得很少,大概一兩句話。另一方面,模型 A-1 預測的分割邊界與ground truth 就差得遠了。
也就是說,雖然兩個模型都沒有預測正確,但從“near miss”角度來看,模型 A-0 相對優于模型 A-1。但是,Precision&Recall指標可不會考慮這些,它們不在乎預測邊界與真實邊界的相對距離,只管預測正確與否,所以 A-0 與 A-1 從Precision、Recall值來看效果是相當的。
3.2 Pk 指標
3.2.1 Pk 指標定義
針對 “near miss”, Beeferemen 等人提出了Pk指標。

Pk是基于滑動窗口計算的,窗口大小可以自行指定,如果沒有指定一般就取真實文本段平均長度的的一半。在滑動窗口的同時,判斷窗口的兩端的節點是否屬于同一文本段,并比較真實結果與模型預測的結果是否一致,最后將不一致的數量除以滑動次數即可得到Pk值。所以模型的Pk值越低,說明模型預測得越好。
Pk指標在nltk中有相應實現,可以直接調用(nltk.pk[1]):
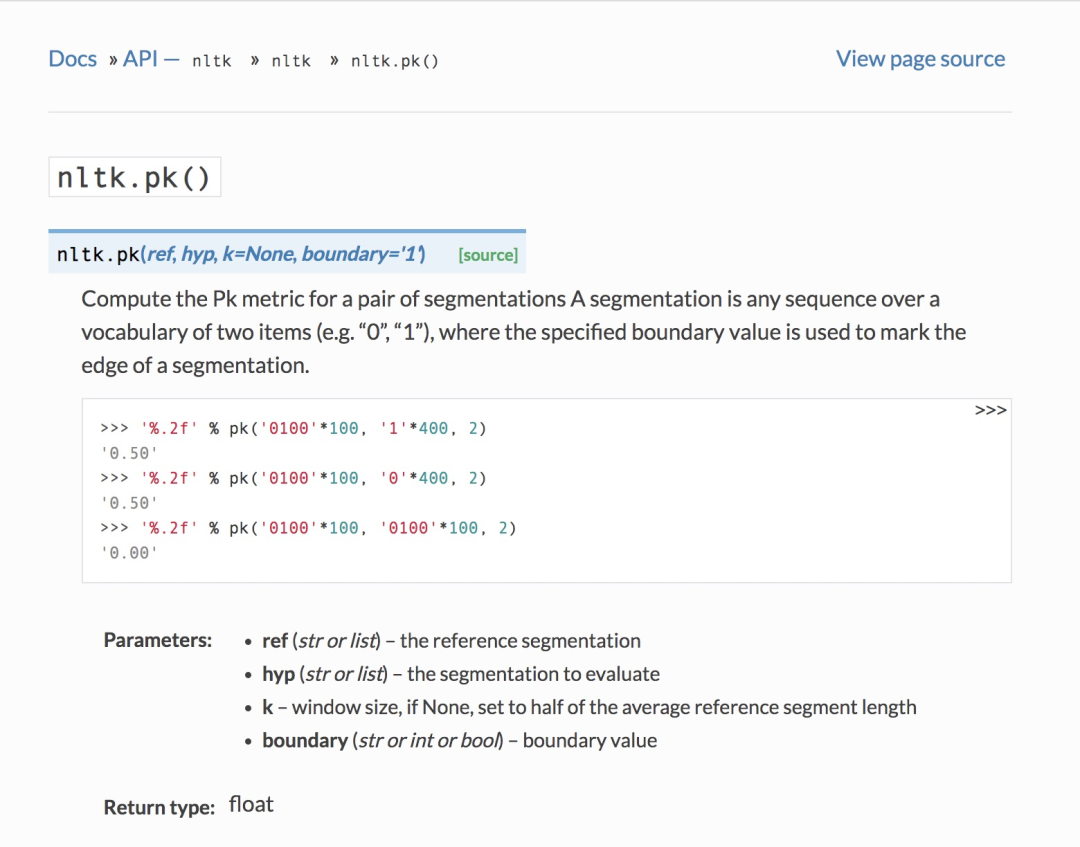
下面是Pk的實現源碼(為了便于大家結合定義看代碼實現,小喵已經在下面的源代碼中添加了相應注釋):
#Beeferman'sPktextsegmentationevaluationmetric
[docs]defpk(ref,hyp,k=None,boundary='1'):
"""
ComputethePkmetricforapairofsegmentationsAsegmentation
isanysequenceoveravocabularyoftwoitems(e.g."0","1"),
wherethespecifiedboundaryvalueisusedtomarktheedgeofa
segmentation.
>>>'%.2f'%pk('0100'*100,'1'*400,2)
'0.50'
>>>'%.2f'%pk('0100'*100,'0'*400,2)
'0.50'
>>>'%.2f'%pk('0100'*100,'0100'*100,2)
'0.00'
:paramref:thereferencesegmentation
:typeref:strorlist
:paramhyp:thesegmentationtoevaluate
:typehyp:strorlist
:paramk:windowsize,ifNone,settohalfoftheaveragereferencesegmentlength
:typeboundary:strorintorbool
:paramboundary:boundaryvalue
:typeboundary:strorintorbool
float
"""
#若k未指定,則k設置為真實分割結果中文本段平均長度的一半
ifkisNone:
k=int(round(len(ref)/(ref.count(boundary)*2.)))
#不匹配計數
err=0
#滑動
foriinxrange(len(ref)-k+1):
#判斷是否屬于同一文本段,只需要判斷窗口內是否出現了分割邊界,若出現了就不屬于同一文本段
r=ref[i:i+k].count(boundary)>0
h=hyp[i:i+k].count(boundary)>0
ifr!=h:
err+=1
#pk值為不匹配次數除以總的滑動次數
returnerr/(len(ref)-k+1.)
3.2.2 Pk 指標問題
Pk指標也存在一些問題:
- 對文本塊大小過于敏感
- 沒有考慮分割邊界數量
- 假負例比假正例更易受到懲罰
- 對于“near miss”處罰太多
對Pk指標存在的問題感興趣的讀者可以細讀相關論文。小喵在這里僅針對“假負例比假正例更易受到懲罰”展開提一下。
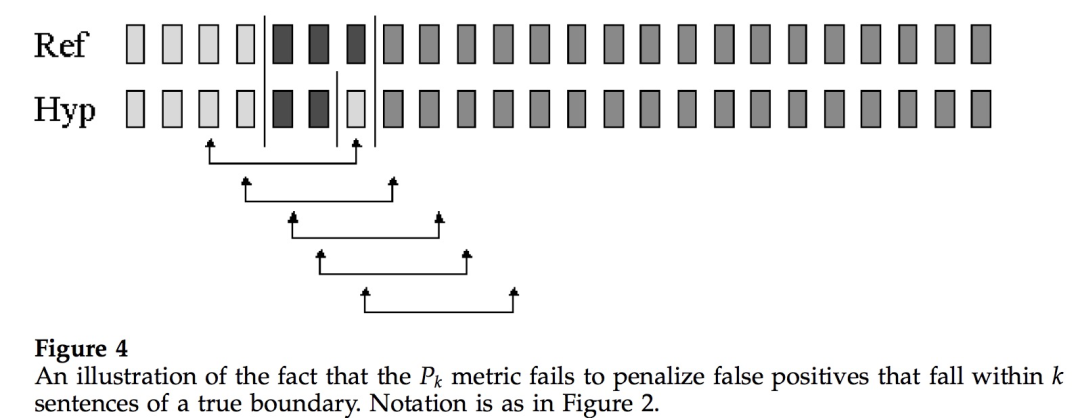
我們來看上面這幅圖,圖中滑動窗口大小為4 (表示在窗口兩端點內潛在的分割邊界數為4)。模型將兩個真實的分割邊界都預測了出來,同時也多預測了一個(即假正例,本來不是分割邊界的被預測為分割邊界)。
但是從Pk的定義來看,在每一個窗口內,模型預測與真實結果都是一致的,即窗口兩端情況都是一樣的,要么都是在同一文本段內,要么都在不同文本段內。也就是說只要窗口兩端情況一致,不管窗口內部情況如何,Pk都認為模型做對了,這樣“假正例”逃脫了懲罰。
3.3 WindowDiff 指標
針對Pk指標存在的問題,WindowDiff指標被提了出來(《A Critique and Improvement of an Evaluation Metric for Text Segmentation》[2])。
WindowDiff指標也是基于滑動窗口計算。不同的是,WindowDiff指標直接判別在窗口內部真實結果與預測結果分割邊界數量的異同。
也就是說Pk與WindowDiff的計算類似,都是在分割結果上每次移動一個固定大小的窗口,并在窗口內計算模型預測結果與真實結果不匹配情況,最終求平均。不同之處在于,Pk是從“窗口兩端的句子是否位于同一個文本”的角度來判斷,而WindowDiff則是根據“窗口內所包含的分割邊界個數”來判斷。
同樣地,模型的WindowDiff值越低,說明模型預測的分割邊界與真實的分割邊界越接近,模型預測得越好。
WindowDiff在nltk中也有相應的實現(nltk.windowdiff()[3]):
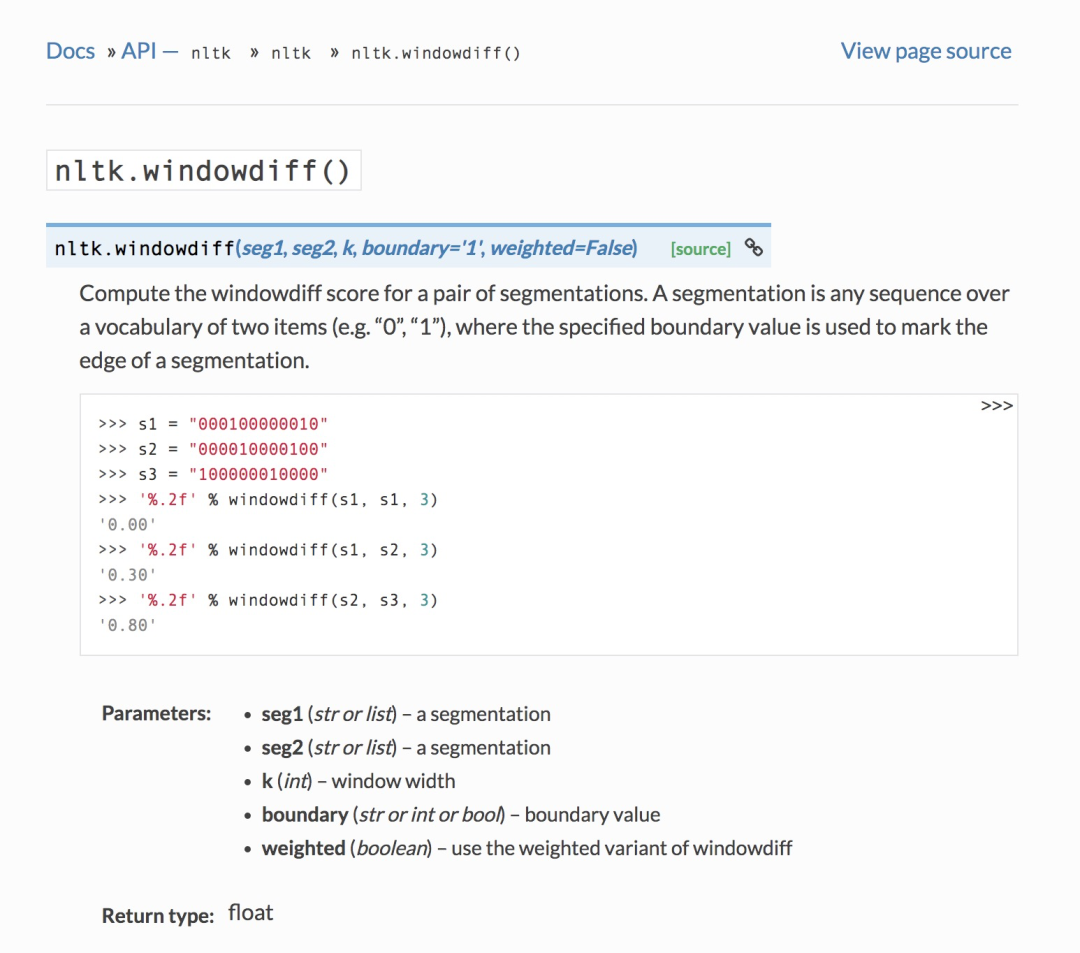
下面是WindowDiff的實現源碼(小喵也在代碼中添加了相應注釋):
defwindowdiff(seg1,seg2,k,boundary="1",weighted=False):
"""
Computethewindowdiffscoreforapairofsegmentations.A
segmentationisanysequenceoveravocabularyoftwoitems
(e.g."0","1"),wherethespecifiedboundaryvalueisusedto
marktheedgeofasegmentation.
>>>s1="000100000010"
>>>s2="000010000100"
>>>s3="100000010000"
>>>'%.2f'%windowdiff(s1,s1,3)
'0.00'
>>>'%.2f'%windowdiff(s1,s2,3)
'0.30'
>>>'%.2f'%windowdiff(s2,s3,3)
'0.80'
:paramseg1:asegmentation
:typeseg1:strorlist
:paramseg2:asegmentation
:typeseg2:strorlist
:paramk:windowwidth
:typek:int
:paramboundary:boundaryvalue
:typeboundary:strorintorbool
:paramweighted:usetheweightedvariantofwindowdiff
:typeweighted:boolean
float
"""
#句子數相同
iflen(seg1)!=len(seg2):
raiseValueError("Segmentationshaveunequallength")
ifk>len(seg1):
raiseValueError("Windowwidthkshouldbesmallerorequalthansegmentationlengths")
#不匹配計數
wd=0
#滑動
foriinrange(len(seg1)-k+1):
#預測結果與真實結果在窗口內的分割邊界數的差值
ndiff=abs(seg1[i:i+k].count(boundary)-seg2[i:i+k].count(boundary))
ifweighted:
wd+=ndiff
else:
#分割邊界不相同,即邊界數差值不為人零時,不匹配計數加1
wd+=min(1,ndiff)
#不匹配次數除以總的滑動次數
returnwd/(len(seg1)-k+1.)
總結
在今天的文章中,小喵跟大家一起學習了什么是文本分割(主題分割)、文本分割任務的應用場景以及文本分割任務的相關評價指標,如:Precision&Recall、Pk、WindowDiff。
希望大家通過本文能夠對文本分割任務有一個基本的認識。在接下來的文章里,小喵將跟大家一起閱讀文本分割的相關論文、學習文本分割的相關模型。
審核編輯 :李倩
-
自動識別
+關注
關注
3文章
217瀏覽量
22818 -
文本
+關注
關注
0文章
118瀏覽量
17068
原文標題:總結
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
系統放大器的技術原理和應用場景
OTA測試暗箱的技術原理和應用場景
無線通信測試平臺的技術原理和應用場景
移動終端測試儀的技術原理和應用場景
便攜式示波器的技術原理和應用場景
實時示波器的技術原理和應用場景
源測量單元設備的技術原理和應用場景
太陽膜測試儀的技術原理和應用場景
超聲波測厚儀的技術原理和應用場景
智能IC卡測試設備的技術原理和應用場景
NFC協議分析儀的技術原理和應用場景
脈沖式線圈測試儀的技術原理和應用場景
卷積神經網絡在文本分類領域的應用
NanoEdge AI的技術原理、應用場景及優勢
人工智能中文本分類的基本原理和關鍵技術





 工商網監
工商網監
評論