 深入解讀Grace CPU芯片架構
深入解讀Grace CPU芯片架構
NVIDIA Grace CPU是 NVIDIA 開發的第一款數據中心 CPU。通過將 NVIDIA 專業知識與 Arm 處理器、片上結構、片上系統 (SoC) 設計和彈性高帶寬低功耗內存技術相結合。參考內容“NVIDIA GraceCPU處理器合集”。
NVIDIA Grace CPU 從頭開始構建,以創建世界上第一個用于計算的超級芯片(super chip)。超級芯片的核心是NVLink Chip-2-Chip (C2C),它允許 NVIDIA Grace CPU 以 900 GB/s 的雙向帶寬與超級芯片中的另一個 NVIDIA Grace CPU 或NVIDIA Hopper GPU進行通信。
NVIDIA Grace Hopper Superchip將節能、高帶寬的 NVIDIA Grace CPU 與功能強大的 NVIDIA H100 Hopper GPU 結合使用 NVLink-C2C,以最大限度地提高強大的高性能計算 (HPC) 和巨型 AI 工作負載的能力。 NVIDIA Grace CPU 超級芯片是使用兩個通過 NVLink-C2C 連接的 Grace CPU 構建的。該超級芯片建立在現有 Arm 生態系統的基礎上,為 HPC、要求苛刻的云工作負載以及高性能和高能效的密集基礎設施創建了首個毫不妥協的 Arm CPU。 在本文中,您將了解 NVIDIA Grace CPU 超級芯片以及提供 NVIDIA Grace CPU 性能和能效的技術。有關詳細信息。
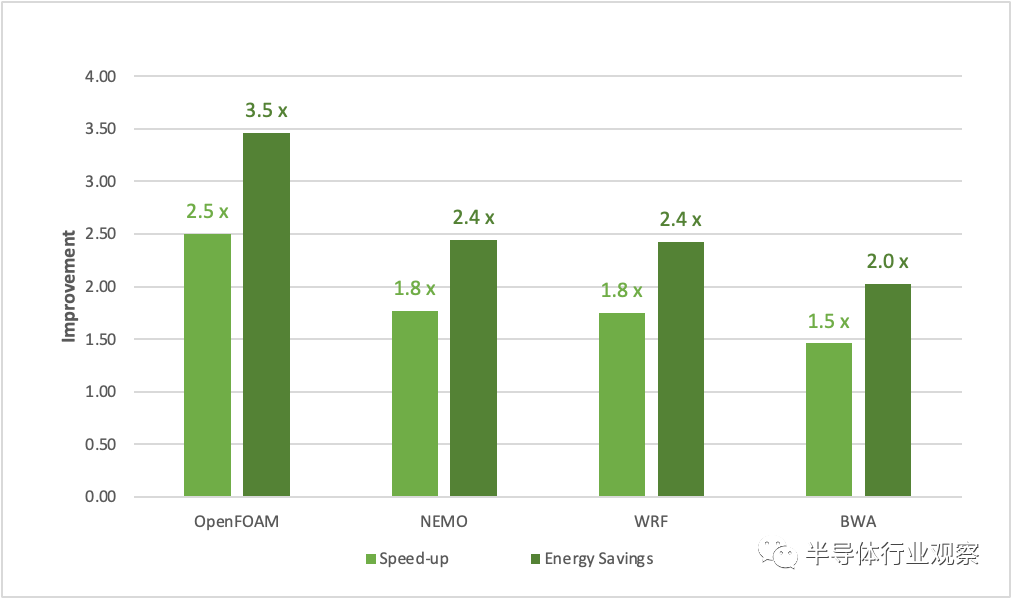
圖 1. 與雙插槽 Milan 7763 CPU 相比,NVIDIA Grace CPU Superchip 上應用程序的性能和節能效果
專為 HPC 和 AI 工作負載打造的超級芯片
NVIDIA Grace CPU 超級芯片通過將旗艦雙路 x86-64 服務器或工作站平臺提供的性能水平集成到單個超級芯片中,代表了計算平臺設計的一場革命。高效的設計可在較低的功率范圍內實現 2 倍的計算密度。

NVIDIA Grace CPU 旨在提供高單線程性能、高內存帶寬和出色的數據移動能力,每瓦性能領先。NVIDIA Grace CPU Superchip 結合了兩個連接超過 900 GB/s 雙向帶寬 NVLink-C2C 的 NVIDIA Grace CPU,提供 144 個高性能 Arm Neoverse V2 內核和高達 1 TB/s 帶寬的數據中心級 LPDDR5X 內存,帶糾錯碼( ECC)內存。
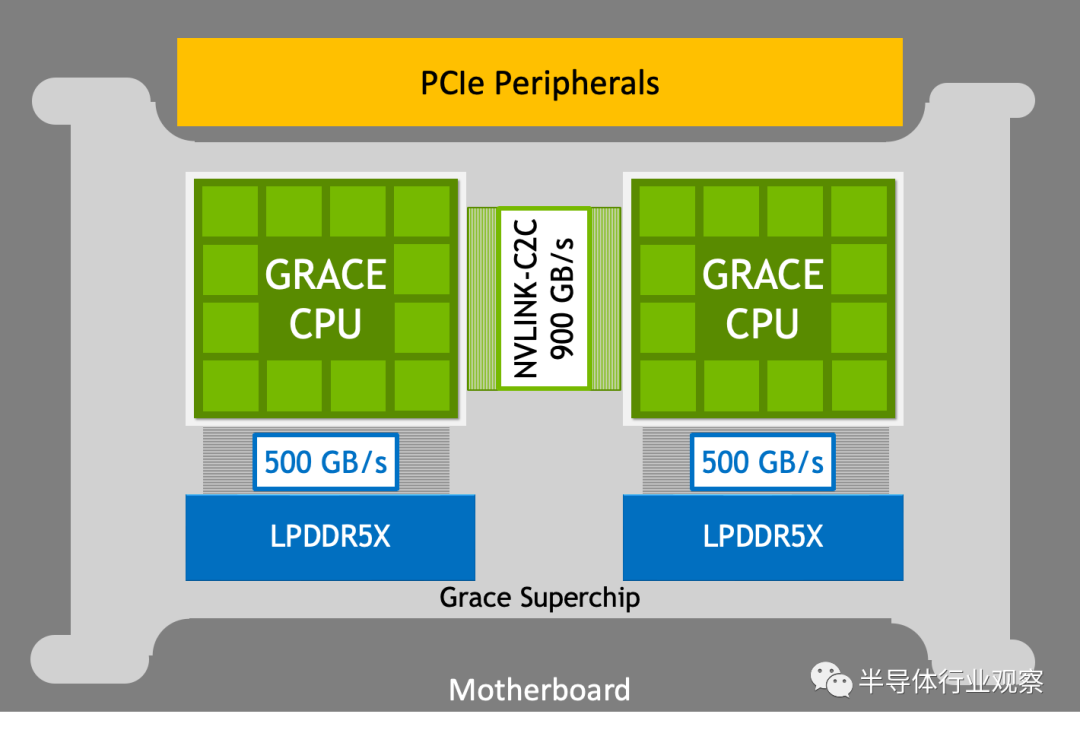
圖2. 具有 900 GB/s NVLink-C2C 的 NVIDIA Grace CPU 超級芯片
使用 NVLink-C2C 互連緩解瓶頸
為了擴展到 144 個 Arm Neoverse V2 內核并在兩個 CPU 之間移動數據,NVIDIA Grace CPU Superchip 需要在 CPU 之間建立高帶寬連接。NVLink C2C 互連在兩個 NVIDIA Grace CPU 之間提供高帶寬直接連接,以創建 NVIDIA Grace CPU 超級芯片。
使用 NVIDIA Scalable Coherency Fabric 擴展內核和帶寬
現代 CPU 工作負載需要快速的數據移動。由 NVIDIA 設計的可擴展一致性結構 (SCF) 是一種網狀結構和分布式緩存架構,旨在擴展內核和帶寬(圖 3)。SCF 提供超過 3.2 TB/s 的總二分帶寬,以保持數據在 CPU 內核、NVLink-C2C、內存和系統 IO 之間流動。 CPU 核心和 SCF 緩存分區分布在整個網格中,而緩存交換節點通過結構路由數據并充當 CPU、緩存內存和系統 IO 之間的接口。NVIDIA Grace CPU 超級芯片在兩個芯片上具有 234 MB 的分布式三級緩存。
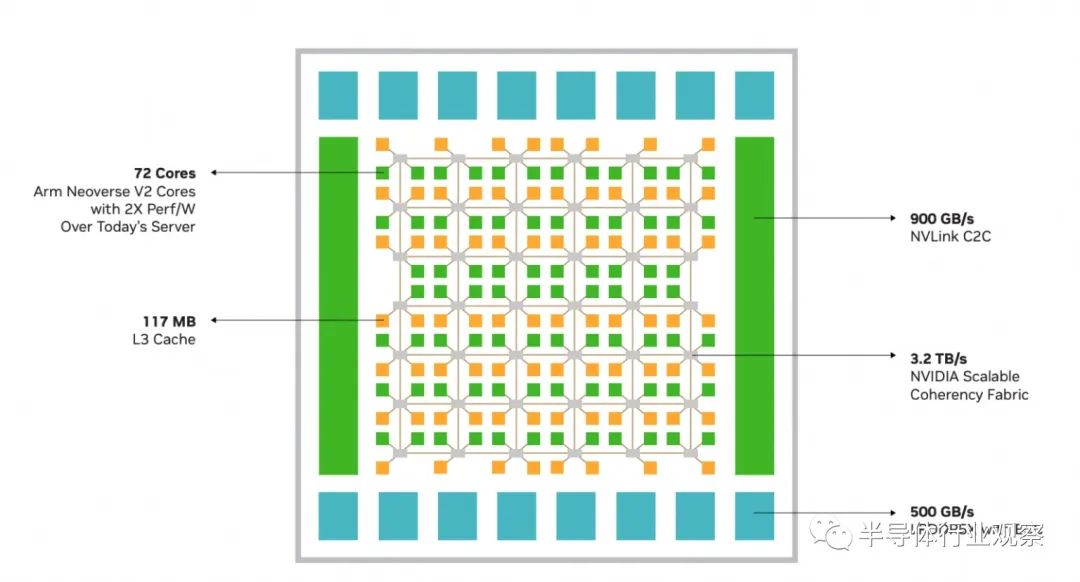
圖3. NVIDIA Grace CPU 和可擴展一致性結構
LPDDR5X
能效和內存帶寬都是數據中心 CPU 的關鍵組成部分。NVIDIA Grace CPU Superchip 使用高達 960 GB 的服務器級低功耗 DDR5X (LPDDR5X) 內存和 ECC。此設計為大規模 AI 和 HPC 工作負載實現了帶寬、能效、容量和成本的最佳平衡。 與八通道 DDR5 設計相比,NVIDIA Grace CPU LPDDR5X 內存子系統以每千兆字節每秒八分之一的功率提供高達 53% 的帶寬,同時成本相似。HBM2e 內存子系統本可以提供大量內存帶寬和良好的能效,但每 GB 成本是其 3 倍多,并且僅為 LPDDR5X 可用最大容量的八分之一。 LPDDR5X 較低的功耗降低了整體系統功率要求,并使更多資源能夠用于 CPU 內核。緊湊的外形使基于 DIMM 的典型設計的密度提高了 2 倍。
NVIDIA Grace CPU I/O
NVIDIA Grace CPU Superchip 支持多達 128 條用于 IO 連接的 PCIe Gen 5 通道。8 個 PCIe Gen 5 x16 鏈路中的每一個都支持高達 128 GB/s 的雙向帶寬,并且可以分為 2x8 個以提供額外的連接,并且可以支持各種 PCIe 插槽形狀因數,開箱即用地支持NVIDIA GPU和NVIDIA DPU、NVIDIA ConnectX SmartNIC、E1.S 和 M.2 NVMe 設備、模塊化 BMC 選項等。?
NVIDIA Grace CPU 核心架構
為了實現最大的工作負載加速,快速高效的 CPU 是系統設計的重要組成部分。Grace CPU 的核心是 Arm Neoverse V2 CPU 內核。Neoverse V2 是 Arm V 系列基礎架構 CPU 內核中的最新產品,經過優化可提供領先的每線程性能,同時與傳統 CPU 相比提供領先的能效。

圖4. NVIDIA Grace CPU 的 Arm Neoverse V2 內核
Arm架構
NVIDIA Grace CPU Neoverse V2 核心實現了 Armv9-A 架構,它將 Armv8-A 架構中定義的架構擴展到 Armv8.5-A。為 Armv8.5-A 之前的 Armv8 架構構建的任何應用程序二進制文件都將在 NVIDIA Grace CPU 上執行。這包括針對 Ampere Altra、AWS Graviton2 和AWS Graviton3等 CPU 的二進制文件。
SIMD指令
Neoverse V2 在 4×128 位配置中實現了兩個單指令多數據 (SIMD) 向量指令集:可擴展向量擴展版本 2 (SVE2) 和高級 SIMD (NEON)。四個 128 位功能單元中的每一個都可以退出 SVE2 或 NEON 指令。這種設計使更多代碼能夠充分利用 SIMD 性能。SVE2 通過高級指令進一步擴展了 SVE ISA,這些指令可以加速機器學習、基因組學和密碼學等關鍵 HPC 應用程序。
原子操作(Atomic operation)
NVIDIA Grace CPU 支持在 Armv8.1 中首次引入的大型系統擴展 (LSE)。LSE 提供低成本的原子操作,可以提高 CPU 到 CPU 通信、鎖和互斥鎖的系統吞吐量。這些指令可以對整數數據進行操作。所有支持 NVIDIA Grace CPU 的編譯器都將在同步函數中自動使用這些指令,例如 GNU 編譯器集合__atomic內置函數和std::atomic. 當使用 LSE 原子而不是加載/存儲獨占時,改進可以達到一個數量級。
Armv9 附加功能
NVIDIA Grace CPU實現了Armv9 產品組合的多項關鍵功能,可在通用數據中心 CPU 中提供實用程序,包括但不限于加密加速、可擴展分析擴展、虛擬化擴展、全內存加密、安全啟動等。
NVIDIA Grace CPU 軟件
NVIDIA Grace CPU Superchip 旨在為軟件開發人員提供符合標準的平臺。 NVIDIA Grace CPU 符合 Arm 服務器基礎系統架構 (SBSA),以支持符合標準的硬件和軟件接口。此外,為了在基于 Grace CPU 的系統上啟用標準引導流程,Grace CPU 被設計為支持 Arm 服務器基本引導要求 (SBBR)。所有主要的 Linux 發行版,以及它們提供的大量軟件包,都可以在 NVIDIA Grace CPU 上完美運行,無需修改。 編譯器、庫、工具、分析器、系統管理實用程序以及用于容器化和虛擬化的框架現已上市,并且可以像在任何其他數據中心 CPU 上一樣輕松地在 NVIDIA Grace CPU 上安裝和使用。 此外,整個 NVIDIA 軟件堆棧都可用于 NVIDIA Grace CPU。NVIDIA HPC SDK 和每個 CUDA 組件都有 Arm 原生安裝程序和容器。NVIDIA GPU Cloud (NGC) 還提供深度學習、機器學習和針對 Arm 優化的 HPC 容器。NVIDIA Grace CPU 遵循主流 CPU 設計原則,并且與任何其他服務器 CPU 一樣進行編程。
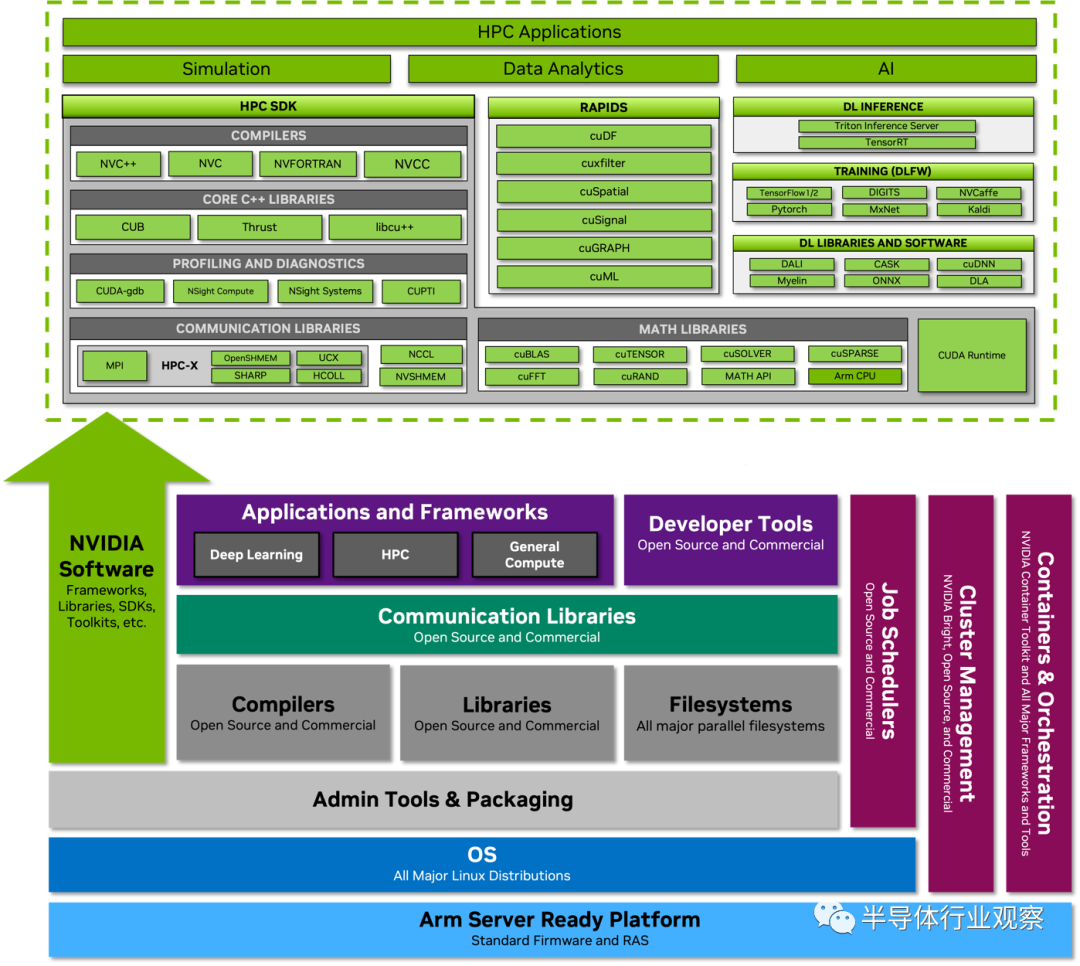
圖 5. NVIDIA Grace CPU 軟件生態系統將用于 CPU、GPU 和 DPU 的全套 NVIDIA 軟件與完整的 Arm 數據中心生態系統相結合
審核編輯 :李倩
-
處理器
+關注
關注
68文章
18927瀏覽量
227230 -
cpu
+關注
關注
68文章
10702瀏覽量
209371 -
NVIDIA
+關注
關注
14文章
4793瀏覽量
102429 -
芯片架構
+關注
關注
1文章
30瀏覽量
14537
原文標題:深入解讀Grace CPU芯片架構
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA芯片架構和資源有深入的理解,精通Verilog HDL、VHDL
【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
自動駕駛三大主流芯片架構分析
解讀MIPI A-PHY與車載Serdes芯片技術與測試
飛天技術沙龍回顧:業務創新新選擇,倚天Arm架構深入探討

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
美國首個Grace Hopper架構超算Venado落地:達10 exaFLOPS
X-Silicon發布RISC-V新架構 實現CPU/GPU一體化
RISC-V芯片新突破:CPU與GPU一體化核心設計
交換芯片架構是什么意思 交換芯片架構怎么工作
NVIDIA推出搭載GB200 Grace Blackwell超級芯片的NVIDIA DGX SuperPOD?
Arm架構與Neoverse技術在基礎設施領域的應用與發展
深入解讀AMD最新GPU架構





 工商網監
工商網監
評論