 動圖演示C語言10大經典排序算法(含代碼)
動圖演示C語言10大經典排序算法(含代碼)
本文將通過動態演示+代碼的形式系統地總結十大經典排序算法。
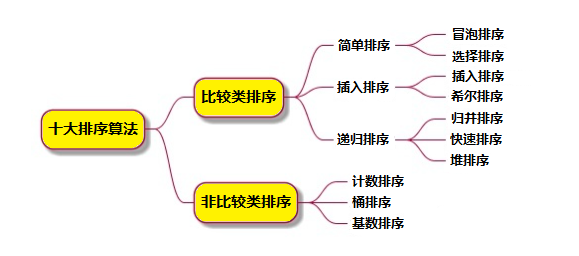
排序算法
算法分類
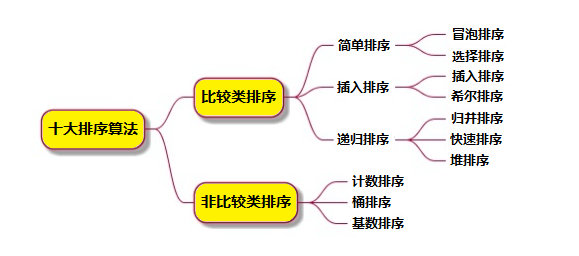
十種常見排序算法可以分為兩大類:
比較類排序:通過比較來決定元素間的相對次序,由于其時間復雜度不能突破O(nlogn),因此也稱為非線性時間比較類排序。
非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基于比較排序的時間下界,以線性時間運行,因此也稱為線性時間非比較類排序。
| 排序算法 | 平均時間復雜度 | 最差時間復雜度 | 空間復雜度 | 數據對象穩定性 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | O(1) | 穩定 |
| 選擇排序 | O(n2) | O(n2) | O(1) | 數組不穩定、鏈表穩定 |
| 插入排序 | O(n2) | O(n2) | O(1) | 穩定 |
| 快速排序 | O(n*log2n) | O(n2) | O(log2n) | 不穩定 |
| 堆排序 | O(n*log2n) | O(n*log2n) | O(1) | 不穩定 |
| 歸并排序 | O(n*log2n) | O(n*log2n) | O(n) | 穩定 |
| 希爾排序 | O(n*log2n) | O(n2) | O(1) | 不穩定 |
| 計數排序 | O(n+m) | O(n+m) | O(n+m) | 穩定 |
| 桶排序 | O(n) | O(n) | O(m) | 穩定 |
| 基數排序 | O(k*n) | O(n2) | 穩定 |
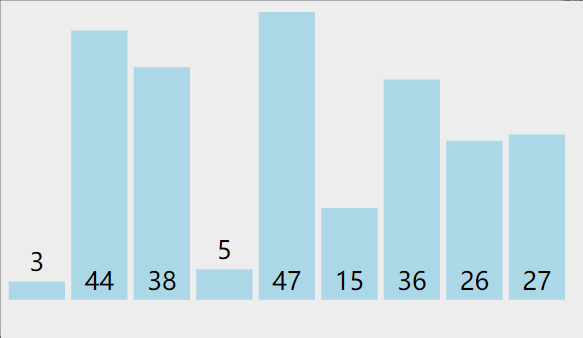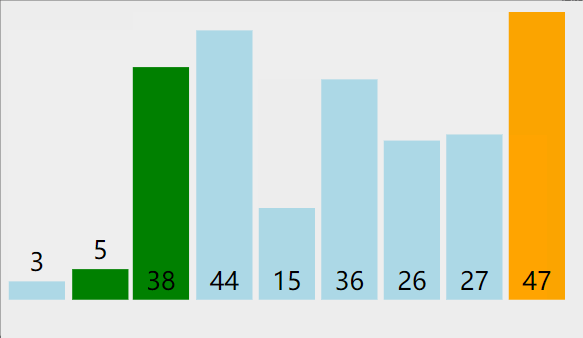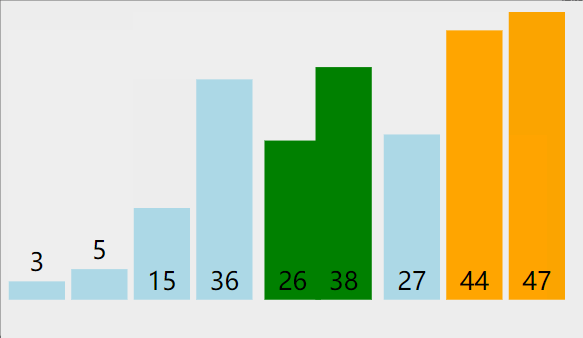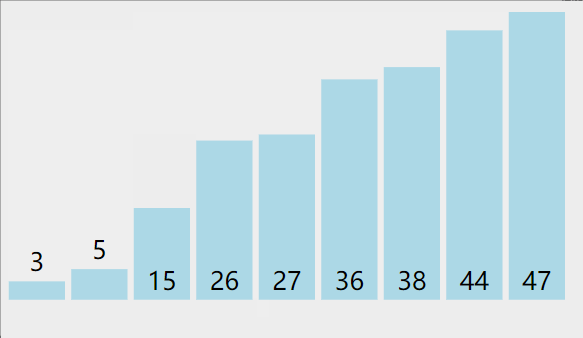
1. 冒泡排序
算法思想:
比較相鄰的元素。如果第一個比第二個大,就交換它們兩個
對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最后一對,這樣在最后的元素應該會是最大的數;
針對所有的元素重復以上的步驟,除了最后一個;
重復步驟1~3,直到排序完成。
代碼:
voidbubbleSort(inta[],intn)
{
for(inti=0;i-1;++i)
{
for(intj=0;j-1;++j)
{
if(a[j]>a[j+1])
{
inttmp=a[j];//交換
a[j]=a[j+1];
a[j+1]=tmp;
}
}
}
}
2. 選擇排序
算法思想:
在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末
以此類推,直到所有元素均排序完畢
代碼:
voidselectionSort(intarr[],intn){
intminIndex,temp;
for(inti=0;i1;i++){
minIndex=i;
for(varj=i+1;jif(arr[j]//尋找最小的數
minIndex=j;//將最小數的索引保存
}
}
temp=arr[i];
arr[i]=arr[minIndex];
arr[minIndex]=temp;
}
for(intk=0;iprintf("%d",arr[k]);
}
}
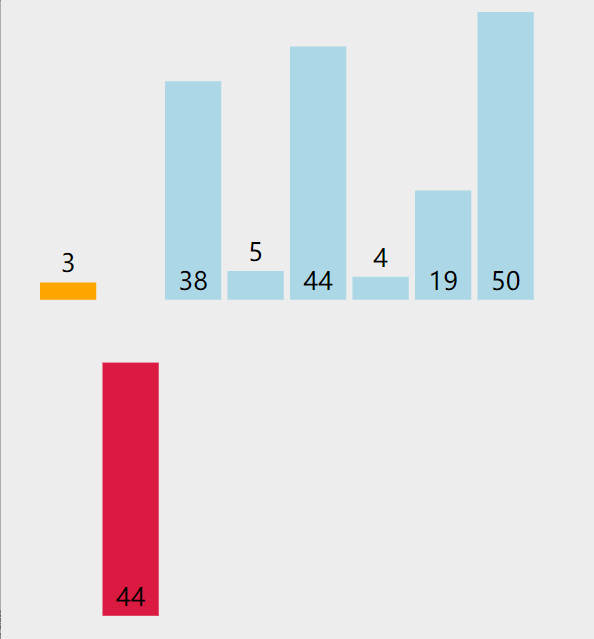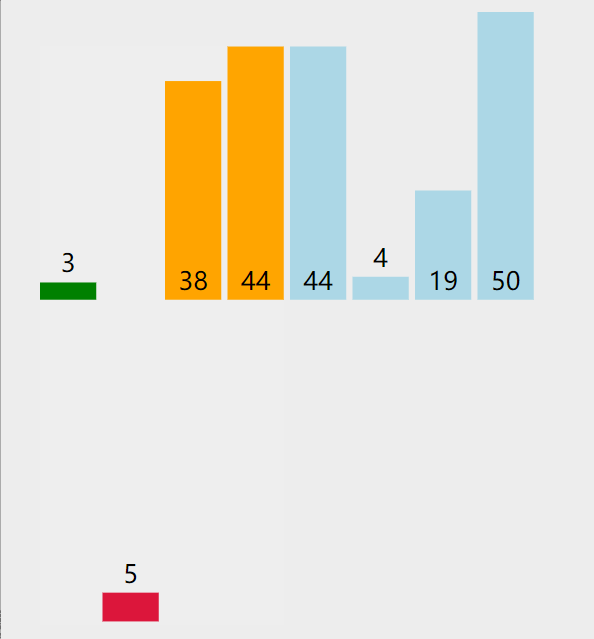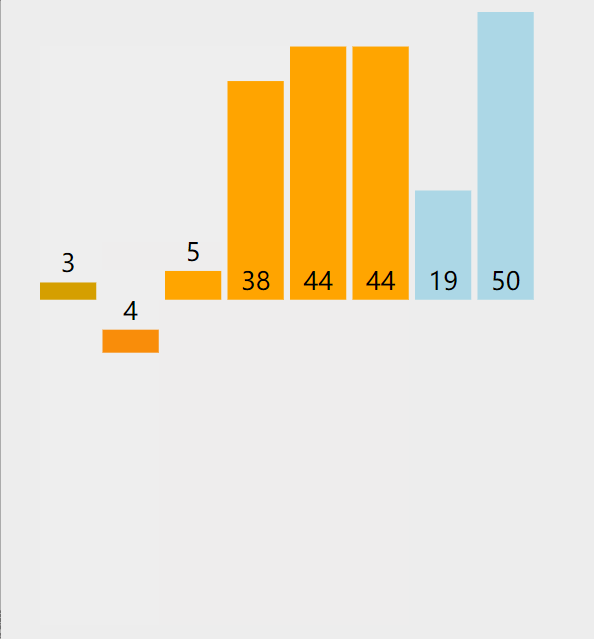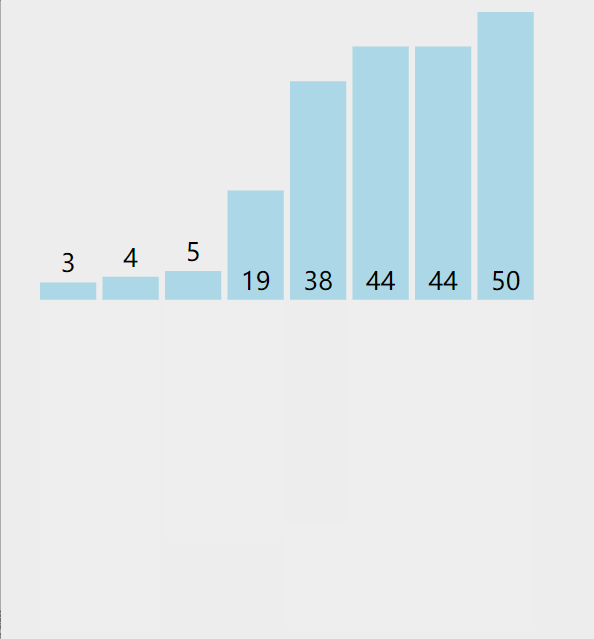
3. 插入排序
算法思想:
從第一個元素開始,該元素可以認為已經被排序;
取出下一個元素,在已經排序的元素序列中從后向前掃描;
如果該元素(已排序)大于新元素,將該元素移到下一位置;
重復步驟3,直到找到已排序的元素小于或者等于新元素的位置;
將新元素插入到該位置后;
重復步驟2~5。
代碼:
voidprint(inta[],intn,inti){
cout<":";
for(intj=0;j<8;j++){
cout<"";
}
cout<<endl;
}
voidInsertSort(inta[],intn)
{
for(inti=1;iif(a[i]-1]){//若第i個元素大于i-1元素,直接插入。小于的話,移動有序表后插入
intj=i-1;
intx=a[i];//復制為哨兵,即存儲待排序元素
a[i]=a[i-1];//先后移一個元素
while(x//查找在有序表的插入位置
a[j+1]=a[j];
j--;//元素后移
}
a[j+1]=x;//插入到正確位置
}
print(a,n,i);//打印每趟排序的結果
}
}
intmain(){
inta[15]={2,3,4,5,15,19,16,27,36,38,44,46,47,48,50};
InsertSort(a,15);
print(a,15,15);
}
算法分析:
插入排序在實現上,通常采用in-place排序(即只需用到O(1)的額外空間的排序),因而在從后向前掃描過程中,需要反復把已排序元素逐步向后挪位,為最新元素提供插入空間。
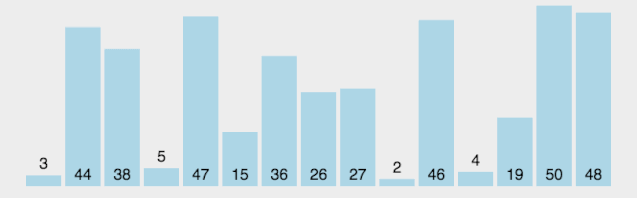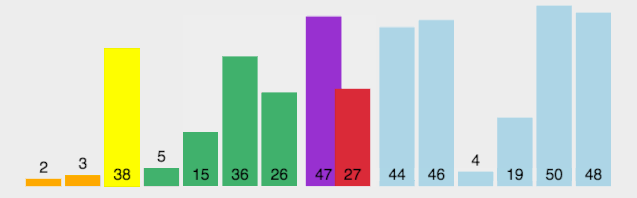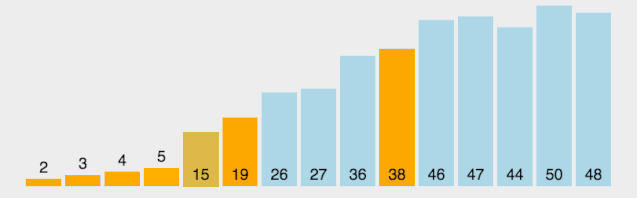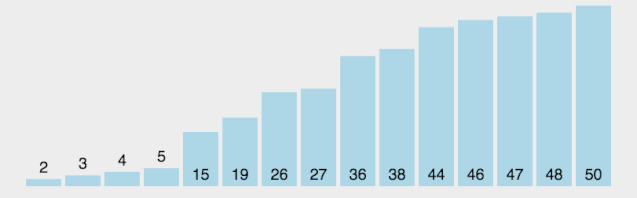
4.快速排序
快速排序的基本思想是通過一趟排序將待排記錄分隔成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序。
算法思想:
選取第一個數為基準
將比基準小的數交換到前面,比基準大的數交換到后面
遞歸地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序
代碼:
voidQuickSort(vector<int>&v,intlow,inthigh){
if(low>=high)//結束標志
return;
intfirst=low;//低位下標
intlast=high;//高位下標
intkey=v[first];//設第一個為基準
while(first//將比第一個小的移到前面
while(first=key)
last--;
if(first//將比第一個大的移到后面
while(firstif(first//
v[first]=key;
//前半遞歸
QuickSort(v,low,first-1);
//后半遞歸
QuickSort(v,first+1,high);
}
5.堆排序
堆排序(Heapsort)是指利用堆這種數據結構所設計的一種排序算法。堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子節點的鍵值或索引總是小于(或者大于)它的父節點。
算法思想:
將初始待排序關鍵字序列(R1,R2….Rn)構建成大頂堆,此堆為初始的無序區;
將堆頂元素R[1]與最后一個元素R[n]交換,此時得到新的無序區(R1,R2,……Rn-1)和新的有序區(Rn),且滿足R[1,2…n-1]<=R[n];
由于交換后新的堆頂R[1]可能違反堆的性質,因此需要對當前無序區(R1,R2,……Rn-1)調整為新堆,然后再次將R[1]與無序區最后一個元素交換,得到新的無序區(R1,R2….Rn-2)和新的有序區(Rn-1,Rn)。不斷重復此過程直到有序區的元素個數為n-1,則整個排序過程完成。
代碼:
#include
6. 歸并排序
歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為2-路歸并。
算法思想:
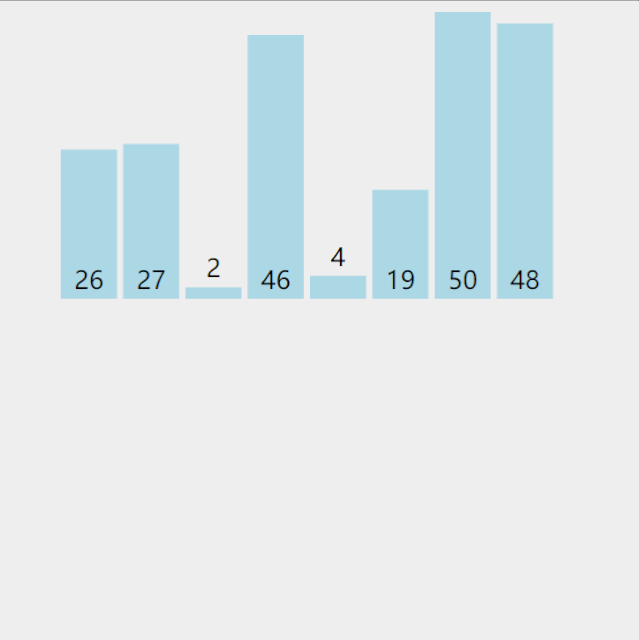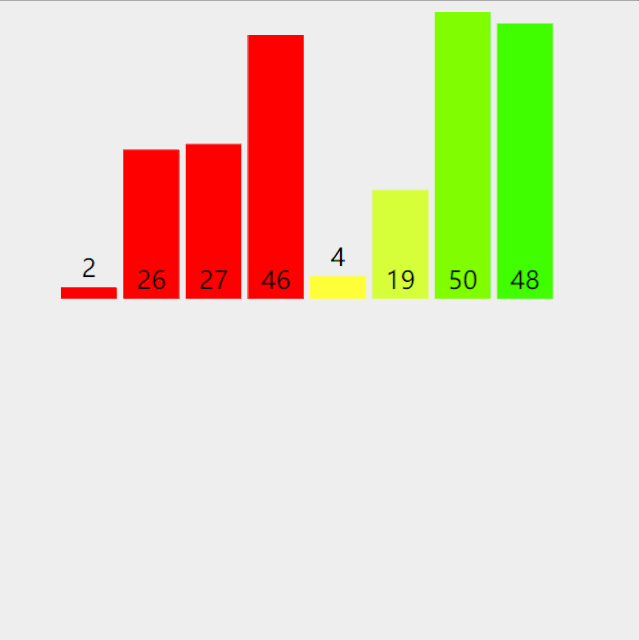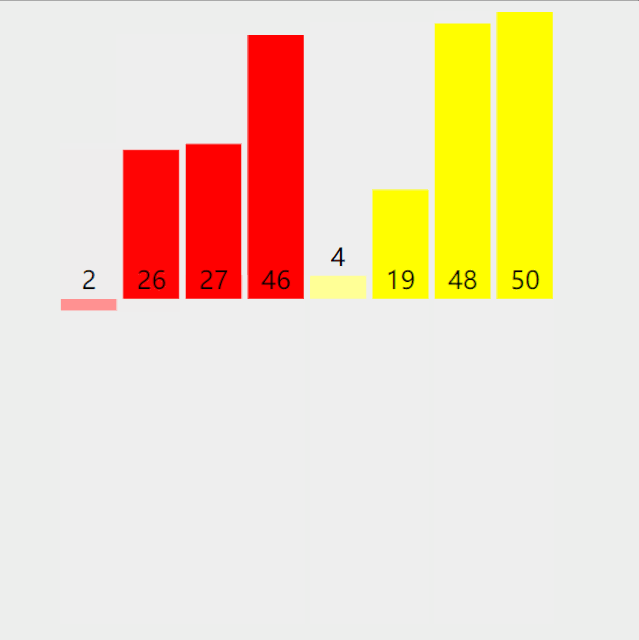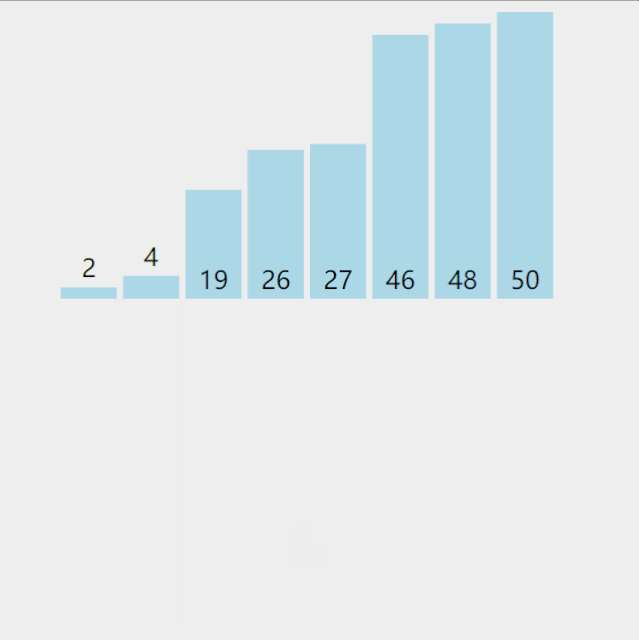
把長度為n的輸入序列分成兩個長度為n/2的子序列;
對這兩個子序列分別采用歸并排序;
將兩個排序好的子序列合并成一個最終的排序序列。
代碼:
voidprint(inta[],intn){
for(intj=0;jcout<"";
}
cout<<endl;
}
//將r[i…m]和r[m+1…n]歸并到輔助數組rf[i…n]
voidMerge(ElemType*r,ElemType*rf,inti,intm,intn)
{
intj,k;
for(j=m+1,k=i;i<=m?&&?j?<=n?;?++k){
????if(r[j]elserf[k]=r[i++];
}
while(i<=?m)??rf[k++]?=?r[i++];
??while(j<=?n)??rf[k++]?=?r[j++];
??print(rf,n+1);
}
voidMergeSort(ElemType*r,ElemType*rf,intlenght)
{
intlen=1;
ElemType*q=r;
ElemType*tmp;
while(lenints=len;
len=2*s;
inti=0;
while(i+len-1,i+len-1);//對等長的兩個子表合并
i=i+len;
}
if(i+s-1,lenght-1);//對不等長的兩個子表合并
}
tmp=q;q=rf;rf=tmp;//交換q,rf,以保證下一趟歸并時,仍從q歸并到rf
}
}
intmain(){
inta[10]={2,3,4,5,15,19,26,27,36,38,44,46,47,48,50};
intb[10];
MergeSort(a,b,15);
print(b,15);
cout<<"結果:";
print(a,10);
}
7. 希爾排序
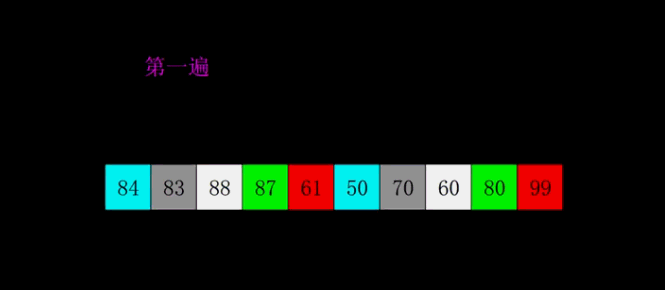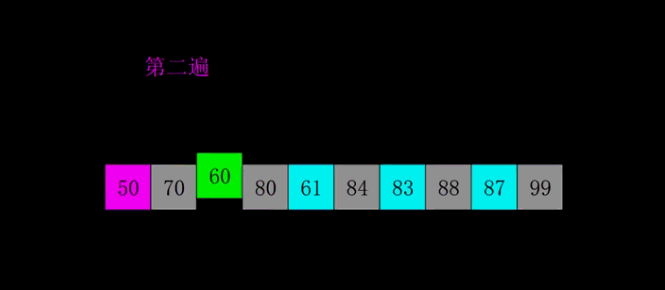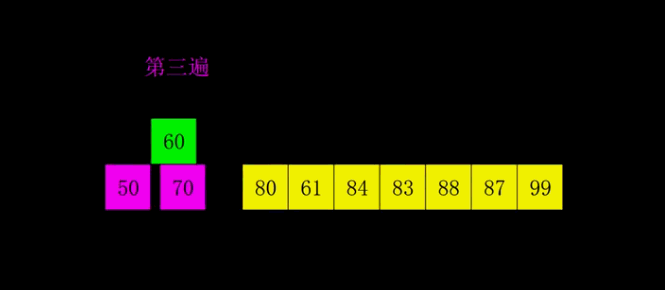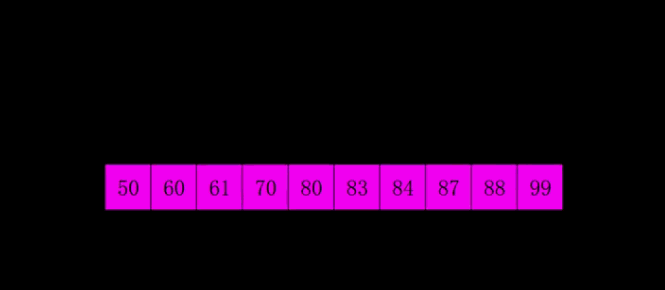
1959年Shell發明,第一個突破O(n2)的排序算法,是簡單插入排序的改進版。它與插入排序的不同之處在于,它會優先比較距離較遠的元素。希爾排序又叫縮小增量排序。
算法思想:
選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
按增量序列個數k,對序列進行k 趟排序;
每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序。僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度。
代碼:
voidshell_sort(Tarray[],intlength){
inth=1;
while(h3){
h=3*h+1;
}
while(h>=1){
for(inti=h;ifor(intj=i;j>=h&&array[j]array[j-h];j-=h){
std::swap(array[j],array[j-h]);
}
}
h=h/3;
}
}
8 計數排序
計數排序不是基于比較的排序算法,其核心在于將輸入的數據值轉化為鍵存儲在額外開辟的數組空間中。作為一種線性時間復雜度的排序,計數排序要求輸入的數據必須是有確定范圍的整數。
算法思想:
找出待排序的數組中最大和最小的元素;
統計數組中每個值為i的元素出現的次數,存入數組C的第i項;
對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加);
反向填充目標數組:將每個元素i放在新數組的第C(i)項,每放一個元素就將C(i)減去1。
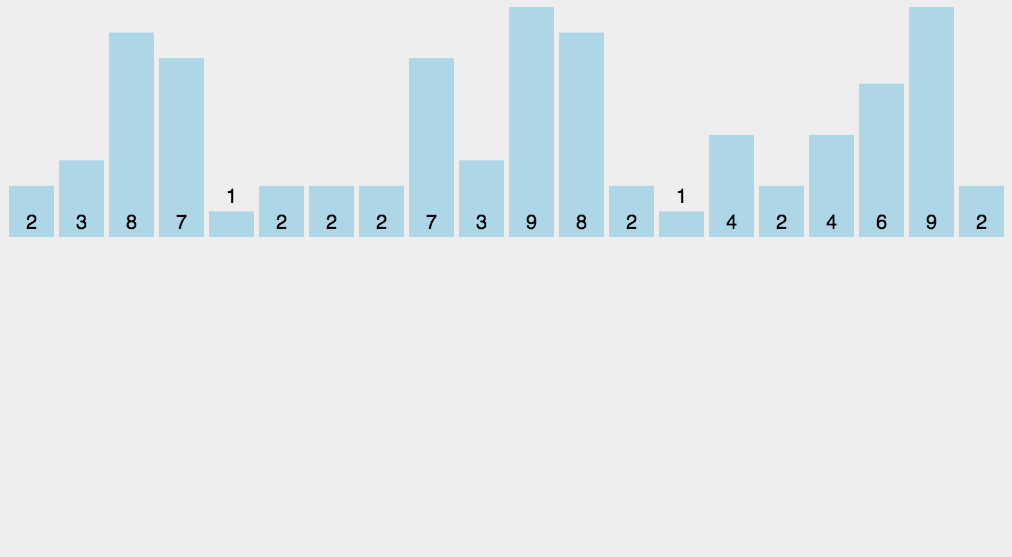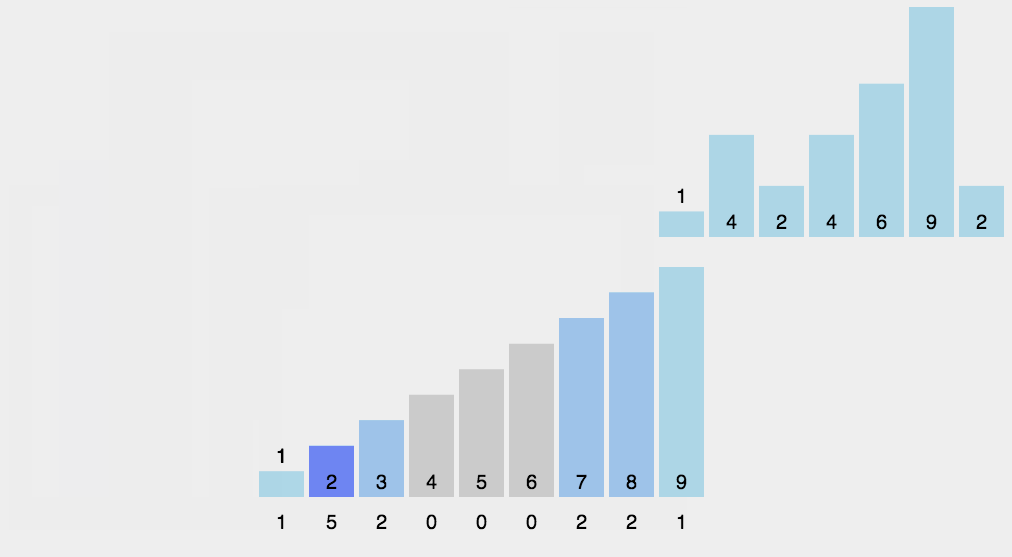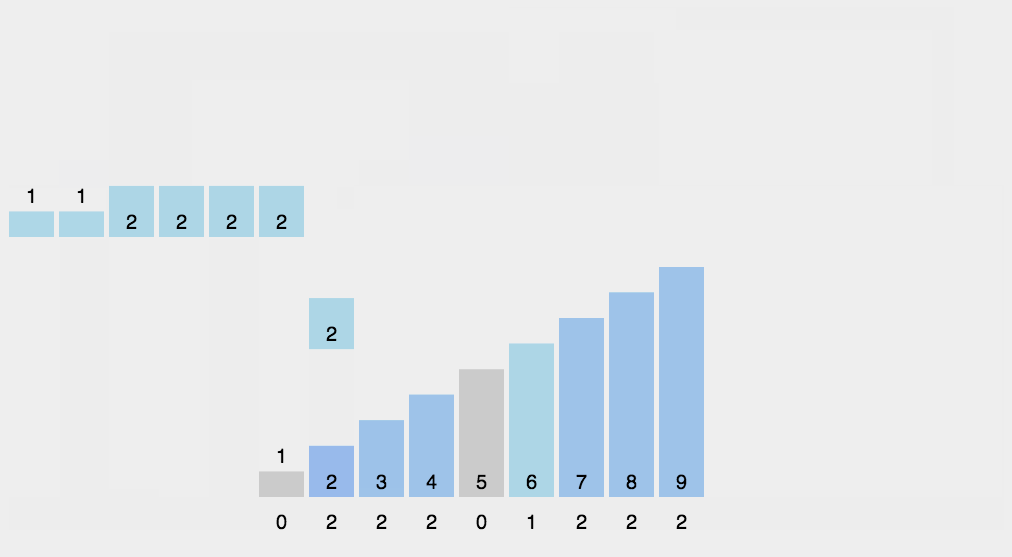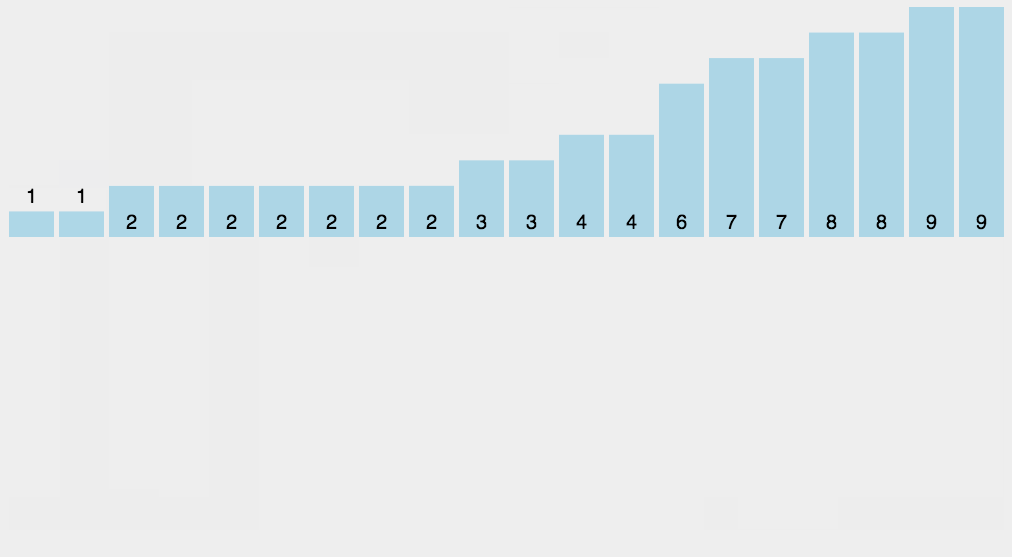
代碼:
#include
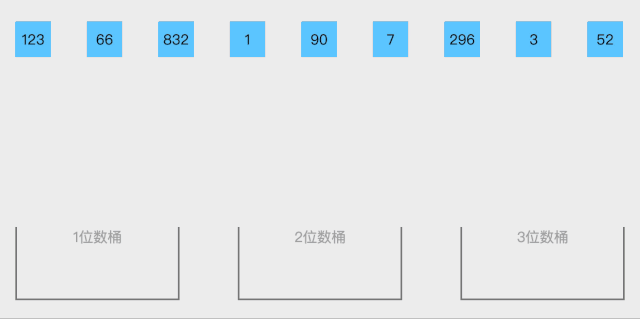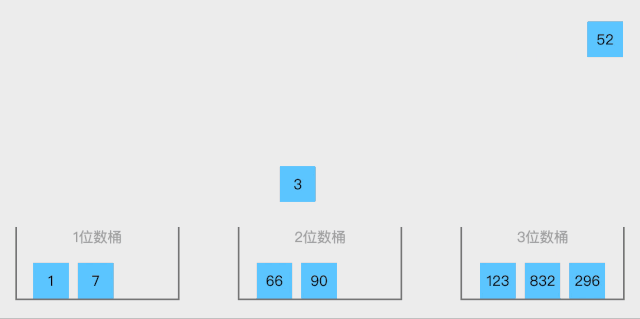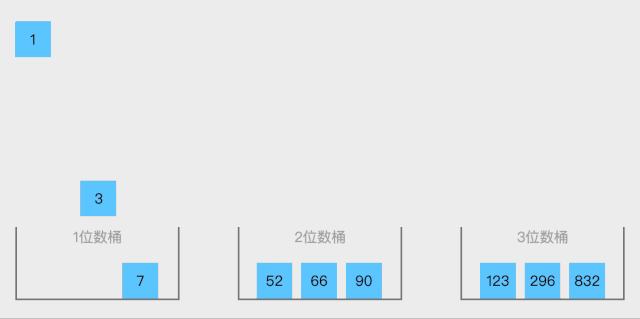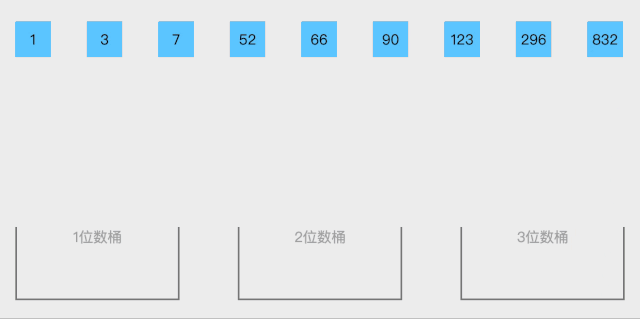
9 桶排序
將值為i的元素放入i號桶,最后依次把桶里的元素倒出來。
算法思想:
設置一個定量的數組當作空桶子。
尋訪序列,并且把項目一個一個放到對應的桶子去。
對每個不是空的桶子進行排序。
從不是空的桶子里把項目再放回原來的序列中。
代碼:
voidBucket_Sort(inta[],intn,intmax){
inti,j=0;
int*buckets=(int*)malloc((max+1)*sizeof(int));
//將buckets中的所有數據都初始化為0
memset(buckets,0,(max+1)*sizeof(int));
//1.計數
for(i=0;iprintf("%d:%d
",a[i],buckets[a[i]]);
}
printf("
");
//2.排序
for(i=0;i1;i++){
while((buckets[i]--)>0){
a[j++]=i;
}
}
}
intmain(){
intarr[]={9,5,1,6,2,3,0,4,8,7};
Bucket_Sort(arr,10,9);
for(inti=0;i10;i++){
printf("%d",arr[i]);
}
printf("
");
return0;
}
10 基數排序
一種多關鍵字的排序算法,可用桶排序實現。
算法思想:
取得數組中的最大數,并取得位數;
arr為原始數組,從最低位開始取每個位組成radix數組;
對radix進行計數排序(利用計數排序適用于小范圍數的特點)

代碼:
intmaxbit(intdata[],intn)//輔助函數,求數據的最大位數
{
intmaxData=data[0];///
///先求出最大數,再求其位數,這樣有原先依次每個數判斷其位數,稍微優化點。
for(inti=1;iif(maxDataintd=1;
intp=10;
while(maxData>=p)
{
//p*=10;//Maybeoverflow
maxData/=10;
++d;
}
returnd;
/*intd=1;//保存最大的位數
intp=10;
for(inti=0;i=p)
{
p*=10;
++d;
}
}
returnd;*/
}
voidradixsort(intdata[],intn)//基數排序
{
intd=maxbit(data,n);
int*tmp=newint[n];
int*count=newint[10];//計數器
inti,j,k;
intradix=1;
for(i=1;i<=?d;?i++)?//進行d次排序
{
for(j=0;j10;j++)
count[j]=0;//每次分配前清空計數器
for(j=0;j10;//統計每個桶中的記錄數
count[k]++;
}
for(j=1;j10;j++)
count[j]=count[j-1]+count[j];//將tmp中的位置依次分配給每個桶
for(j=n-1;j>=0;j--)//將所有桶中記錄依次收集到tmp中
{
k=(data[j]/radix)%10;
tmp[count[k]-1]=data[j];
count[k]--;
}
for(j=0;j//將臨時數組的內容復制到data中
data[j]=tmp[j];
radix=radix*10;
}
delete[]tmp;
delete[]count;
}
審核編輯 :李倩
-
算法
+關注
關注
23文章
4599瀏覽量
92642 -
C語言
+關注
關注
180文章
7598瀏覽量
136186 -
線性
+關注
關注
0文章
196瀏覽量
25128
原文標題:動圖演示C語言10大經典排序算法(含代碼)
文章出處:【微信號:mcu168,微信公眾號:硬件攻城獅】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論