 有了Fine-tune-CoT方法,小模型也能做推理,完美逆襲大模型
有了Fine-tune-CoT方法,小模型也能做推理,完美逆襲大模型
大型語言模型可以用來教小得多的學生模型如何進行一步一步地推理。本文方法顯著提高了小型 (~0.3B 參數) 模型在一系列任務上的性能,在許多情況下甚至可以達到或超過大型模型的性能。
語言模型(LMs)在各種下游任務中表現出色,這主要歸功于它們通過 Transformer 架構(Vaswani et al.,2017)和大量網絡訓練數據獲得的可擴展性。先前的語言模型研究遵循了在大型語料庫上預先訓練,然后在下游任務上微調的范式(Raffel et al.,2020; Devlin et al.,2018)。最近,大型語言模型(LLMs)向人們展示了其上下文泛化能力:通過僅在幾個上下文樣例或純自然語言任務描述上調整就能完成下游任務(Brown et al.,2020; Sun et al.,2021)。
如果給語言模型生成一些 prompting,它還向人們展示了其解決復雜任務的能力。標準 prompting 方法,即為使用少樣本的問答對或零樣本的指令的一系列方法,已經被證明不足以解決需要多個推理步驟的下游任務(Chowdhery 等,2022)。
但是,最近的研究已經證明,通過包含少數思維鏈(CoT)推理的樣本(Wang 等,2022b)或通過 promp 來讓模型逐步思考的方法(Kojima 等,2022)可以在大型語言模型中促成復雜的推理能力。
基于 promp 的思維鏈方法的主要缺點是它需要依賴于擁有數十億參數的巨大語言模型(Wei et al,2022b;Kojima et al,2022)。由于計算要求和推理成本過于龐大,這些模型難以大規模部署(Wei et al,2022b)。因此,來自韓國科學技術院的研究者努力使小型模型能夠進行復雜的推理,以用于實際應用。
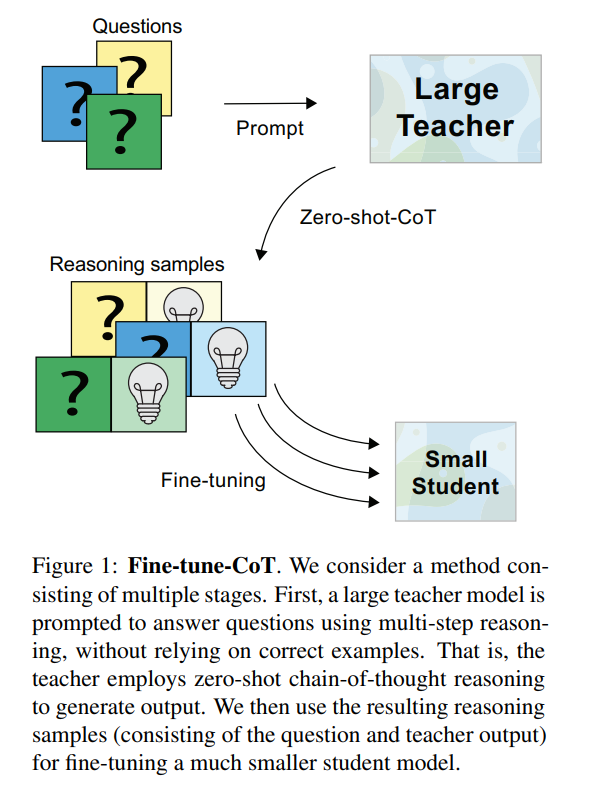
有鑒于此,本文提出了一種名為微調思維鏈的方法,該方法旨在利用非常大的語言模型的思維鏈推理能力來指導小模型解決復雜任務。

論文鏈接:https://arxiv.org/pdf/2212.10071.pdf
項目地址:https://github.com/itsnamgyu/reasoning-teacher
為了詳細說明,本文應用現有的零樣本思維鏈 prompting(Kojima 等人,2022)從非常大的教師模型中生成推理,并使用它們來微調較小的學生模型。
研究者注意到,與標準的 prompting 類似,對于訓練語言模型來解決復雜推理的任務來說,純微調往往是不夠的。雖然已經有人嘗試用規定好的推理步驟對小模型進行微調來解決這個問題,但這些方法需要巨量的推理注釋,而且往往還需要與特定任務匹配的訓練設置(Nye 等人,2021;Cobbe 等人,2021)。
本文提出的方法,由于基于語言模型的教師具有顯著的零樣本推理能力(Kojima 等人,2022),無需手工制作推理注釋及特定任務設置,可以很容易地應用于新的下游任務。從本質上講,本文的方法保留了基于 prompting 的思維鏈的多功能性,同時模型規模還不是很大。
研究者還對本文中的方法提出了一種擴展,稱為多樣化推理,這種擴展方法通過為每個訓練樣本生成多個推理方案來最大限度地提高對思維鏈進行微調的教學效果。具體來說可以通過簡單的重復隨機抽樣來實現。多樣化推理的動機是,多種推理路徑可以用來解決復雜的第二類任務(Evans, 2010)。本文認為,這種推理路徑的多樣性以及語言模板的加入可以大大有助于復雜推理的微調。
本文使用公開的 GPT-3 模型對思維鏈微調和各類任務及規模的多樣化推理進行了實證評估。本文提出的微調方法在復雜任務的小模型中具備明顯的推理性能,而以前基于 prompting 的方法則只具有接近隨機的性能。
本文表明,在思維鏈微調方法下的小模型在某些任務中的表現甚至超過了它們的大模型老師。通過多樣化的推理,研究者發現維鏈微調方法的性能是高度可擴展的,并且即使在很少的訓練例子中也能具備較高的樣本效率和顯著的推理性能。研究者對思維鏈微調方法在眾多數據集上的表現進行了徹底的樣本研究和消融實驗,在小模型上證明了其價值。在此過程中,本文揭示了微調在思維鏈推理中前作沒有被考慮到的一些重要細微差別。
方法概覽
本文提出了思維鏈微調方法,這是一種與下游任務無關的方法,可以在小型語言模型中實現思維鏈推理。該方法的核心思想是使用基于 prompting 的思維鏈方法從非常大的教師模型中生成推理樣本,然后使用生成的樣本對小型學生模型進行微調。
這種方法保留了任務無偏的基于 prompt 思維鏈方法的優點,同時克服了其對過大模型的依賴性。為了最大限度地提高通用性,本文在教師模型上使用了最新的零樣本思維鏈 prompting 方法(Kojima 等人,2022),因為此方法不需要任何手工注釋的推理解釋。作者注意到,本文提出的方法其實并不限于這種教師模型的 prompting 方式。文本將思維鏈微調方法拆解為三個步驟,如下圖所示。
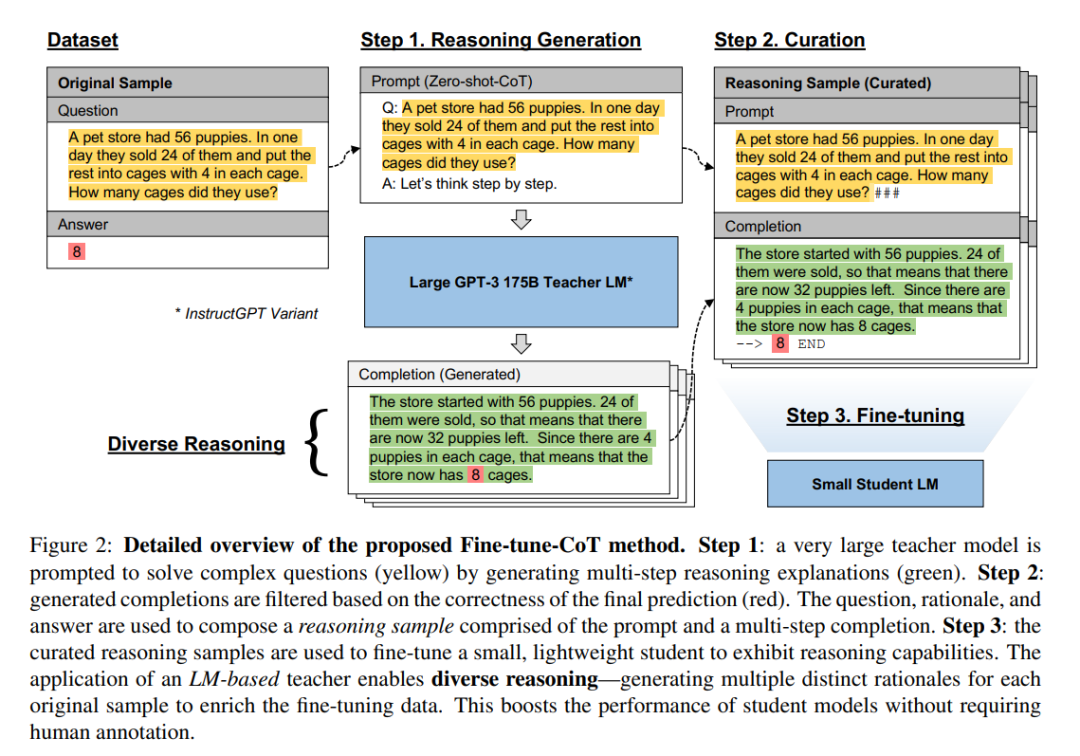
步驟 1—— 推理生成
首先,本文利用一個大型的教師模型來為一個給定的任務生成思維鏈推理解釋。本文定義一個由問題 Q^i 和其真實答案 a^i 組成為一個標準樣本 S^i,然后使用零樣本思維鏈來為教師模型生成一個推理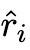 來解決問題 q^i,并生成最終的答案預測
來解決問題 q^i,并生成最終的答案預測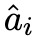 。由此產生的文本序列,包括 prompt 和生成結果,均采取以下形式
。由此產生的文本序列,包括 prompt 和生成結果,均采取以下形式
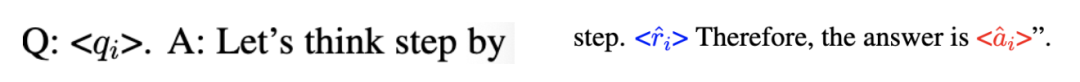
第 2 步 —— 整理
為了制備用于微調的樣本,本文對生成的樣本進行了過濾,并將其重新格式化為 prompt-completion 形式的成對數據。對于過濾,本文將教師模型的最終預測值與真實答案 a^i 進行比較,這與之前的一些工作是相同的(Zelikman 等人,2022;Huang 等人,2022)。對于所有這樣的實例 i,本文將(S_i ,?,?)重新打包成一個推理樣本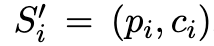 ,也就是一個 prompt-completion 形式的成對數據。由于本文提出的方法旨在為特定任務訓練高效的模型,所以使用基于特殊字符的文本格式來盡量減少標記的使用。具體來說,p_i 采用「
,也就是一個 prompt-completion 形式的成對數據。由于本文提出的方法旨在為特定任務訓練高效的模型,所以使用基于特殊字符的文本格式來盡量減少標記的使用。具體來說,p_i 采用「
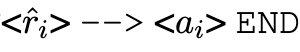
的形式。作者注意到,基于答案預測的過濾并不能確保推理的正確性,特別是對于可能出現隨機猜測的多選題。遺憾的是,以前的工作中這個問題還沒有得到解決。
步驟 3—— 微調
最后,本文使用開源的 OpenAI API 在集成的推理樣本上對一個小型的預訓練學生模型進行微調。本文使用與預訓練時相同的訓練目標,即自回歸語言建模目標,或者用 token 預測(Radford 等人,2018)。
多樣化推理
為了最大限度地提高思維鏈微調方法的對樣本的使用效率,本文提出可以為每個訓練樣本生成多種推理解釋,從而增強微調數據。本文將此稱為多樣化推理。詳細來說,對于一個給定的樣本 S_i,本文不是采用貪心解碼策略的零樣本思維鏈方法來獲得單一的「解釋 — 答案」形式的成對數據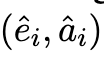 ,而是采用隨機抽樣策略,即用 T 代表溫度抽樣,然后獲得 D 批不同的生成數據
,而是采用隨機抽樣策略,即用 T 代表溫度抽樣,然后獲得 D 批不同的生成數據
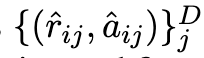
。隨后對推理樣本整理和微調工作就像上面一樣進行。本文把 D 稱為推理的多樣性程度。多樣化推理的動機是,多種推理路徑可以用來解決復雜的任務,即第二類任務(Evans, 2010)。
在樣本研究中,研究者確認多樣化推理樣本包含各種推理路徑以及語言模板,這一點也可以在細化的學生模型中觀察到。這與 Wang 等人(2022b);Zelikman 等人(2022);Huang 等人(2022)的成果類似,多樣化推理路徑被生成并被邊緣化以找到最優答案。多樣化推理也與 Yoo 等人(2021)有相似之處,后者利用大模型語言模型的生成能力,合成的樣本來增加訓練數據。
實驗結果
下表將思維鏈微調方法的學生模型,與現有的對下游任務不敏感的方法 —— 零樣本學習(Kojima 等人,2022)以及標準的零樣本 prompt 和沒有任何推理的微調方法進行對比,并記錄了準確率。
思維鏈微調在相同的任務中性能明顯更突出,這顯示出使用較小的模型比零樣本思維鏈方法收益更大。
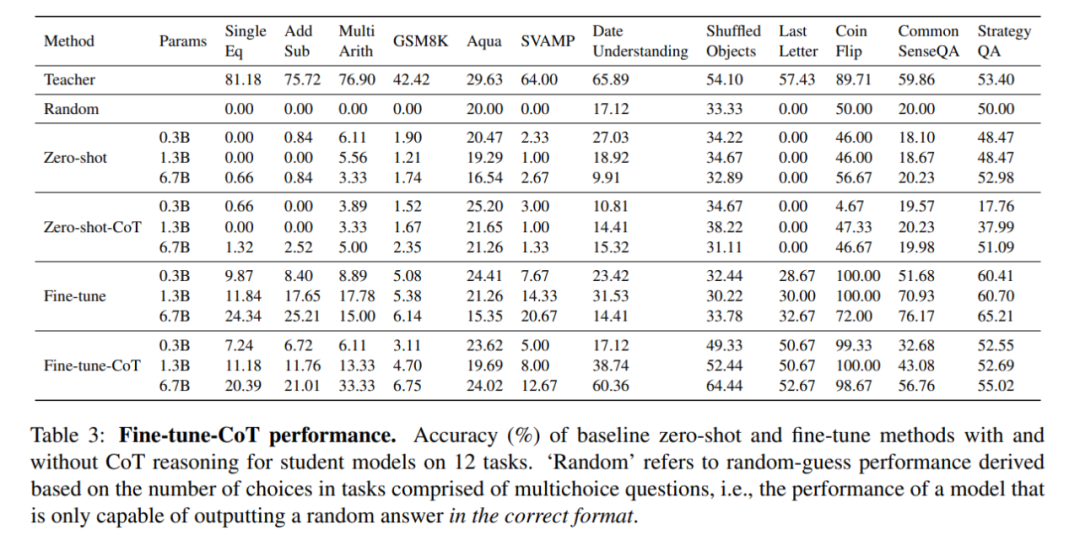
上表還顯示,思維鏈微調對小模型非常有效。同樣地,本文還發現思維鏈微調在很多任務中的表現優于 vanilla 微調,如上表所示。
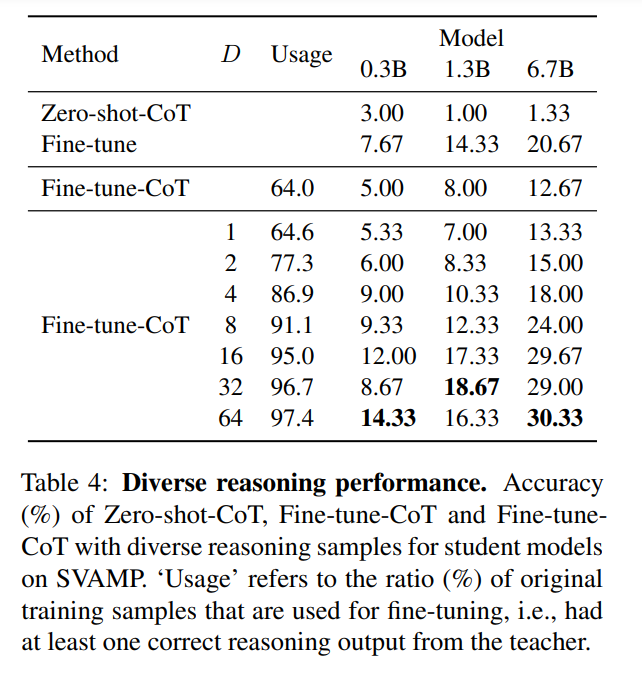
下表顯示,多樣化的推理可以顯著提高使用思維鏈微調的學生模型的性能。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3178瀏覽量
48730 -
語言模型
+關注
關注
0文章
508瀏覽量
10247 -
大模型
+關注
關注
2文章
2339瀏覽量
2500
原文標題:有了Fine-tune-CoT方法,小模型也能做推理,完美逆襲大模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的應用
基于LS-SVM逆模型的青霉素發酵軟測量方法
用tflite接口調用tensorflow模型進行推理
【飛凌RK3568開發板試用體驗】RKNN模型推理測試
壓縮模型會加速推理嗎?
HarmonyOS:使用MindSpore Lite引擎進行模型推理
全新科學問答數據集ScienceQA讓深度學習模型推理有了思維鏈
LLM大模型推理加速的關鍵技術
Google Gemma 2模型的部署和Fine-Tune演示
FPGA和ASIC在大模型推理加速中的應用







 工商網監
工商網監
評論