") ChatGPT背后的原理簡(jiǎn)析
ChatGPT背后的原理簡(jiǎn)析
ChatGPT 是 OpenAI 發(fā)布的最新語(yǔ)言模型,比其前身 GPT-3 有顯著提升。與許多大型語(yǔ)言模型類似,ChatGPT 能以不同樣式、不同目的生成文本,并且在準(zhǔn)確度、敘述細(xì)節(jié)和上下文連貫性上具有更優(yōu)的表現(xiàn)。它代表了 OpenAI 最新一代的大型語(yǔ)言模型,并且在設(shè)計(jì)上非常注重交互性。
從官網(wǎng)介紹可以看到,ChatGPT與InstructGPT是同源的模型。
chatGPT是一種基于轉(zhuǎn)移學(xué) 習(xí)的大型語(yǔ)言模型,它使用GPT-2 (Generative PretrainedTransformer2)模型的技術(shù),并進(jìn)行了進(jìn)一步的訓(xùn)練和優(yōu)化。
GPT-2模型是一種基于注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)模型,它能夠處理序列建橫問(wèn)題,如自然語(yǔ)言處理中的語(yǔ)言建模和機(jī)器翻譯。它使用了一種叫做transformer的架構(gòu), 它能夠通過(guò)自注意力機(jī)制來(lái)學(xué)習(xí)語(yǔ)言的結(jié)構(gòu)和語(yǔ)義。GPT-2模型預(yù)先訓(xùn)練了一個(gè)大型語(yǔ)料庫(kù)上,以便在實(shí)際應(yīng)用中能夠更好地表現(xiàn)。
chatGPT是在GPT-2模型的基礎(chǔ)上進(jìn)一步訓(xùn)練和優(yōu)化而得到的。 它使用了更多的語(yǔ)料庫(kù),并且進(jìn)行了專門(mén)的訓(xùn)練來(lái)提高在對(duì)話系統(tǒng)中的表現(xiàn)。這使得chatGPT能夠在對(duì)話中白然地回應(yīng)用戶的輸入,并且能夠生成流暢、連貫、通順的文本。
那么接下來(lái)我們來(lái)看下什么是InstructGPT。從字面上來(lái)看,顧名思義,它就是指令式的GPT,“which is trained to follow an instruction in a prompt and provide a detailed response”。接下來(lái)我們來(lái)看下InstructGPT論文中的主要原理:
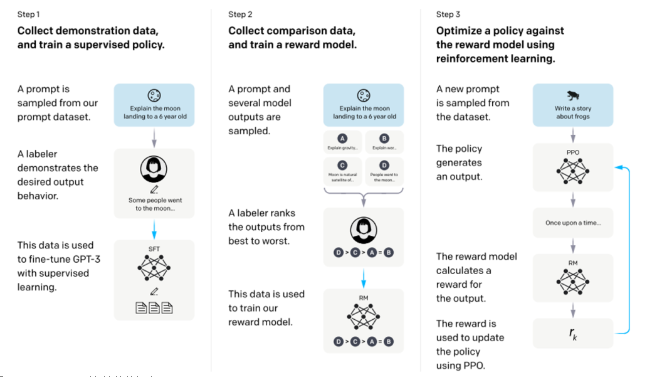
InstructGPT整體訓(xùn)練流程
從該圖可以看出,InstructGPT是基于GPT-3模型訓(xùn)練出來(lái)的,具體步驟如下:
步驟1.)從GPT-3的輸入語(yǔ)句數(shù)據(jù)集中采樣部分輸入,基于這些輸入,采用人工標(biāo)注完成希望得到輸出結(jié)果與行為,然后利用這些標(biāo)注數(shù)據(jù)進(jìn)行GPT-3有監(jiān)督的訓(xùn)練。該模型即作為指令式GPT的冷啟動(dòng)模型。
步驟2.)在采樣的輸入語(yǔ)句中,進(jìn)行前向推理獲得多個(gè)模型輸出結(jié)果,通過(guò)人工標(biāo)注進(jìn)行這些輸出結(jié)果的排序打標(biāo)。最終這些標(biāo)注數(shù)據(jù)用來(lái)訓(xùn)練reward反饋模型。
步驟3.)采樣新的輸入語(yǔ)句,policy策略網(wǎng)絡(luò)生成輸出結(jié)果,然后通過(guò)reward反饋模型計(jì)算反饋,該反饋回過(guò)頭來(lái)作用于policy策略網(wǎng)絡(luò)。以此反復(fù),這里就是標(biāo)準(zhǔn)的reinforcement learning強(qiáng)化學(xué)習(xí)的訓(xùn)練框架了。
所以總結(jié)起來(lái)ChatGPT(對(duì)話GPT)其實(shí)就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通過(guò)人工標(biāo)注方式訓(xùn)練出強(qiáng)化學(xué)習(xí)的冷啟動(dòng)模型與reward反饋模型,最后通過(guò)強(qiáng)化學(xué)習(xí)的方式學(xué)習(xí)出對(duì)話友好型的ChatGPT模型。
InstructGPT的訓(xùn)練實(shí)際上是分為三個(gè)階段的,第一階段就是我們上文所述,利用人工標(biāo)注的數(shù)據(jù)微調(diào)GPT3;第二階段,需要訓(xùn)練一個(gè)評(píng)價(jià)模型即Reward Model,該模型需學(xué)習(xí)人類對(duì)于模型回復(fù)的評(píng)價(jià)方式,對(duì)于給定的上文與生成回復(fù)給出分?jǐn)?shù);第三階段,利用訓(xùn)練好的Reward Model作為反饋信號(hào),去指導(dǎo)GPT進(jìn)一步進(jìn)行微調(diào),將目標(biāo)設(shè)定為Reward分?jǐn)?shù)最大化,從而使模型產(chǎn)生更加符合人類偏好的回復(fù)。
文章綜合CSDN、賽爾實(shí)驗(yàn)室、 IT架構(gòu)師聯(lián)盟
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4765瀏覽量
100562 -
OpenAI
+關(guān)注
關(guān)注
9文章
1045瀏覽量
6411 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1549瀏覽量
7507
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
新能源電池產(chǎn)業(yè)鏈及投資機(jī)會(huì)簡(jiǎn)析-磷酸亞鐵鋰
LLM風(fēng)口背后,ChatGPT的成本問(wèn)題
基于ATM理念的UTRAN傳輸架構(gòu)簡(jiǎn)析
電動(dòng)汽車用鋰離子電池技術(shù)的國(guó)內(nèi)外進(jìn)展簡(jiǎn)析
PCB線路板電鍍銅工藝簡(jiǎn)析
EPON技術(shù)簡(jiǎn)析
筆記本屏幕亮度與反應(yīng)速度簡(jiǎn)析
簡(jiǎn)析BGA封裝技術(shù)與質(zhì)量控制
鼠標(biāo)HID例程(中)簡(jiǎn)析
簡(jiǎn)析比較器的原理及應(yīng)用資料下載






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論