 解讀ChatGPT背后的技術重點
解讀ChatGPT背后的技術重點
近段時間,ChatGPT 橫空出世并獲得巨大成功,使得 RLHF、SFT、IFT、CoT 等這些晦澀的縮寫開始出現在普羅大眾的討論中。這些晦澀的首字母縮略詞究竟是什么意思?為什么它們如此重要?我們調查了相關的所有重要論文,以對這些工作進行分類,總結迄今為止的工作,并對后續工作進行展望。
我們先來看看基于語言模型的會話代理的全景。ChatGPT 并非首創,事實上很多組織在 OpenAI 之前就發布了自己的語言模型對話代理 (dialog agents),包括 Meta 的 BlenderBot,Google 的 LaMDA,DeepMind 的 Sparrow,以及 Anthropic 的 Assistant (Anthropic 的 Claude 就是部分基于 Assistant 繼續開發而得的)。
其中一些團隊還公布了他們構建開源聊天機器人的計劃,并公開分享了路線圖 (比如 LAION 團隊的 Open Assistant),其他團隊肯定也有類似的內容,但尚未宣布。
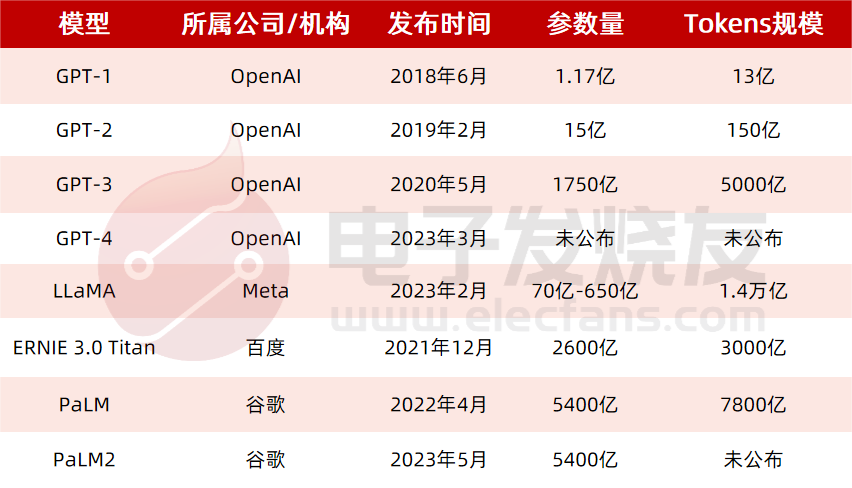
下表根據是否能公開訪問、訓練數據、模型架構和評估方向的詳細信息對這些 AI 聊天機器人進行了比較。ChatGPT 沒有這些信息的記錄,因此我們改為使用 InstructGPT 的詳細信息,這是一個來自 OpenAI 的指令微調模型,據信它是 ChatGPT 的基礎。
| LaMDA | BlenderBot 3 | Sparrow | ChatGPT / InstructGPT | Assistant | |
|---|---|---|---|---|---|
| 組織 | Meta | DeepMind | OpenAI | Anthropic | |
| 能否公開訪問 | 否 | 能 | 否 | 有限 | 否 |
| 大小 | 137B | 175B | 70B | 175B | 52B |
|
預訓練 基礎模型 |
未知 | OPT | Chinchilla | GPT-3.5 | 未知 |
| 預訓練語料庫大小 (詞數) | 2.81T | 180B | 1.4T | 未知 | 400B |
|
模型是否可以 訪問網絡 |
|||||
|
有監督 微調 |
|||||
|
微調 數據大小 |
質量:6.4K 安全性:8K 真實性:4K IR:49K |
大小從 18K 到 1.2M 不等的 20 個 NLP 數據集 | 未知 | 12.7K (此為 InstructGPT,ChatGPT 可能更多) | 150K+ LM 生成的數據 |
| RLHF | |||||
| 人為制定的安全規則 | |||||
| 評價標準 |
1、質量 (合情性、具體性、趣味性) 2、安全性 (偏見) 3、真實性 |
1、質量 (參與度、知識運用) 2、安全性 (毒性、偏見) |
1、校直 (有幫助,無害,正確) 2、證據 (來自網絡) 3、是否違反規則 4、偏見和刻板印象 5、誠信度 |
1、 校直 (有幫助、無害、真實) 2、偏見 |
1、校直 (有幫助、無害、誠實) 2、偏見 |
| 用于數據標注的眾包平臺 | 美國供應商 | 亞馬遜 MTurk | 未知 | Upwork 和 Scale AI | Surge AI、Amazon MTurk 和 Upwork |
我們觀察到,盡管在訓練數據、模型和微調方面存在許多差異,但也存在一些共性。上述所有聊天機器人的一個共同目標是「指令依從 (instruction following)」,即遵循用戶指定的指令。例如,要求 ChatGPT 寫一首關于微調的詩。
 ChatGPT 指令示例
ChatGPT 指令示例
從預測文本到遵循指令
通常,基礎模型的語言建模目標不足以讓模型學會以有用的方式遵循用戶的指令。模型創建者使用「指令微調 (Instruction Fine-Tuning,IFT)」方法來達到該目的,該方法除了使用情感分析、文本分類、摘要等經典 NLP 任務來微調模型外,還在非常多樣化的任務集上向基礎模型示范各種書面指令及其輸出,從而實現對基礎模型的微調。
這些指令示范由三個主要部分組成 —— 指令、輸入和輸出。輸入是可選的,一些任務只需要指令,如上文使用 ChatGPT 做開放式文本生成的示例。當存在輸入時,輸入和輸出組成一個「實例 (instance)」。給定指令可以有多個輸入和輸出實例。如下例 (摘自 Wang 等,'22):
 指令和實例示例
指令和實例示例
IFT 的訓練數據通常是人工編寫的指令及用語言模型自舉 (bootstrap) 生成的實例的集合。在自舉時,先使用少樣本技術輸入一些樣本給 LM 用于提示它 (如上圖所示),隨后要求 LM 生成新的指令、輸入和輸出。每一輪都會從人工編寫的樣本和模型生成的樣本中各選擇一些送給模型。人類和模型對創建數據集的貢獻構成了一個譜圖,見下圖:
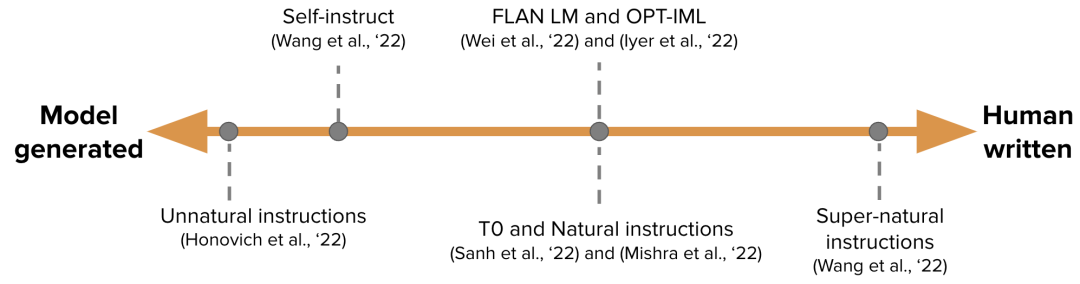 IFT 譜圖
IFT 譜圖
譜圖的一端是純模型生成的 IFT 數據集,例如 Unnatural Instructions (Honovich 等,'22);另一端是經由社區的大量努力精心制作的指令如 Super-natural instructions (Wang 等,'22)。在這兩者之間的工作是使用一小組高質量的種子數據集,然后進行自舉生成最終數據集,如 Self-Instruct (Wang 等,'22)。
為 IFT 整理數據集的另一種方法是將現有的用于各種任務 (包括提示)的高質量眾包 NLP 數據集使用統一模式或不同模板轉換為指令。這一系列工作包括 T0 (Sanh 等,'22)、Natural instructions 數據集 (Mishra 等,'22)、FLAN LM (Wei 等,'22) 和 OPT-IML (Iyer 等,'22)。
安全地遵循指令
然而,經過指令微調的 LM 并不總是能生成 有幫助的 和 安全的 響應。這種行為的例子包括通過總是給出無益的回應來逃避,例如 “對不起,我不明白。” 或對敏感話題的用戶輸入生成不安全的響應。為了減輕這種行為,模型開發人員使用 有監督微調 (Supervised Fine-tuning, SFT),在高質量的人類標注數據上微調基礎語言模型,以提高有用性和無害性。例如,請參閱下面的表格(摘自 Sparrow 論文的附錄 F)。
SFT 和 IFT 聯系非常緊密。指令微調可以看作是有監督微調的一個子集。在最近的文獻中,SFT 階段經常被用于提高響應的安全性,而不是接在 IFT 后面提高指令相應的具體性。將來,這種分類和劃分應該日臻成熟,形成更清晰的使用場景和方法論。
 人工安全規則
人工安全規則
谷歌的 LaMDA 也根據一組規則 (論文附錄 A) 在帶有安全標注的對話數據集上進行微調。這些規則通常由模型創建者預先定義和開發,涵蓋廣泛的主題,包括傷害、歧視、錯誤信息。
微調模型
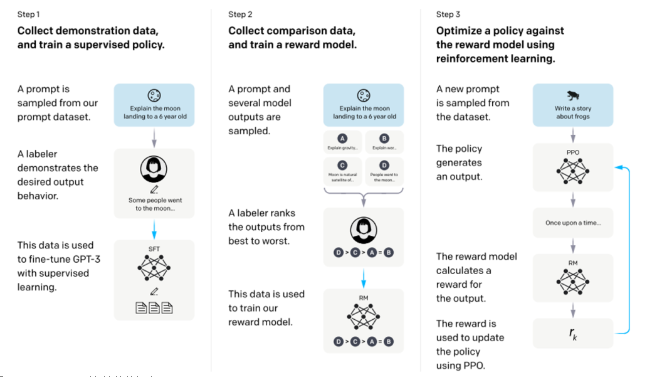
同時,OpenAI 的 InstructGPT、DeepMind 的 Sparrow 和 Anthropic 的 Constitutional AI 使用 人類反饋強化學習 (Reinforcement Learning From Human Feedback,RLHF) 來微調模型,該方法使用基于人類偏好的標注數據。在 RLHF 中,根據人類反饋來對模型的響應進行排序標注 (如,根據人類偏好選擇文本簡介)。然后,用這些帶標注的響應來訓練偏好模型,該模型用于返回 RL 優化器的標量獎勵。最后,通過強化學習訓練對話代理來模擬偏好模型。有關更多詳細信息,請參閱我們之前關于 RLHF 的文章: ChatGPT 背后的“功臣”——RLHF 技術詳解。
思維鏈 (Chain-of-thought,CoT) 提示 (Wei 等,'22) 是指令示范的一種特殊情況,它通過引發對話代理的逐步推理來生成輸出。使用 CoT 微調的模型使用帶有逐步推理的人工標注的指令數據集。這是 Let’s think step by step 這一著名提示的由來。下面的示例取自 Chung 等,'22,橙色高亮的部分是指令,粉色是輸入和輸出,藍色是 CoT 推理。

CoT 圖解
如 Chung 等,'22 中所述,使用 CoT 微調的模型在涉及常識、算術和符號推理的任務上表現得更好。
如 Bai 等,'22 的工作所示,CoT 微調也顯示出對無害性非常有效 (有時比 RLHF 做得更好),而且對敏感提示,模型不會回避并生成 “抱歉,我無法回答這個問題” 這樣的回答。更多示例,請參見其論文的附錄 D。
 CoT 和 RLHF 的對比
CoT 和 RLHF 的對比
要點
與預訓練數據相比,您只需要非常小的一部分數據來進行指令微調 (幾百個數量級);
使用人工標注的有監督微調使模型輸出更安全和有用;
CoT 微調提高了模型在需要逐步思考的任務上的性能,并使它們在敏感話題上不那么回避。
對話代理的進一步工作
這個博客總結了許多關于使對話代理有用的現有工作。但仍有許多懸而未決的問題有待探索。我們在這里列出了其中的一些。
RL 在從人類反饋中學習有多重要?我們能否通過在 IFT 或 SFT 中使用更高質量的數據進行訓練來獲得 RLHF 的性能?
為了安全的角度看,Sparrow 中的 SFT+RLHF 與 LaMDA 中僅使用 SFT 相比如何?
鑒于我們有 IFT、SFT、CoT 和 RLHF,預訓練有多大的必要性?如何折衷?人們應該使用的最佳基礎模型是什么 (公開的和非公開的)?
本文中引用的許多模型都經過 紅藍對抗 (red-teaming) 的精心設計,工程師特地搜尋故障模式并基于已被揭示的問題改進后續的訓練 (提示和方法)。我們如何系統地記錄這些方法的效果并重現它們?
審核編輯:劉清
-
機器人
+關注
關注
210文章
28231瀏覽量
206614 -
COT
+關注
關注
0文章
23瀏覽量
16460 -
OpenAI
+關注
關注
9文章
1045瀏覽量
6411 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
原文標題:解讀ChatGPT背后的技術重點:RLHF、IFT、CoT、紅藍對抗
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
LLM風口背后,ChatGPT的成本問題
ChatGPT背后的算力芯片
科技大廠競逐AIGC,中國的ChatGPT在哪?
詳細解讀ChatGPT 背后的技術重點
解讀ChatGPT背后的技術重點:RLHF、IFT、CoT、紅藍對抗
ChatGPT背后的原理簡析
ChatGPT 的背后:OpenAI 創始人Sam Altman如何用微軟的數十億美元打造了全球最熱門技術
ChatGPT實現原理
ChatGPT for SegmentFault 插件來襲 ChatGPT for SegmentFault 插件使用方案解讀
ChatGPT成功背后的技術原因
ChatGPT背后的大模型技術
ChatGPT 的背后:OpenAI 創始人Sam Altman如何用微軟的數十億美元打造了全球最熱門技術






 工商網監
工商網監
評論