 HashMap遍歷操作為什么不能一邊遍歷一遍刪除呢?
HashMap遍歷操作為什么不能一邊遍歷一遍刪除呢?
前段時間,同事在代碼中 KW 掃描的時候出現這樣一條:
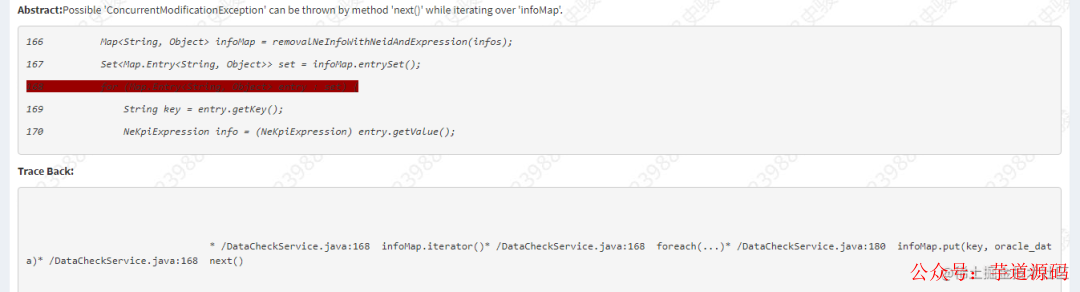
上面出現這樣的原因是在使用 foreach 對 HashMap 進行遍歷時,同時進行 put 賦值操作會有問題,異常 ConcurrentModificationException。
于是幫同簡單的看了一下,印象中集合類在進行遍歷時同時進行刪除或者添加操作時需要謹慎,一般使用迭代器進行操作。
于是告訴同事,應該使用迭代器 Iterator 來對集合元素進行操作。同事問我為什么?這一下子把我問蒙了?對啊,只是記得這樣用不可以,但是好像自己從來沒有細究過為什么?
于是今天決定把這個 HashMap 遍歷操作好好地研究一番,防止采坑!
foreach 循環?
Java foreach 語法是在 JDK 1.5 時加入的新特性,主要是當作 for 語法的一個增強,那么它的底層到底是怎么實現的呢?下面我們來好好研究一下:
foreach 語法內部,對 collection 是用 iterator 迭代器來實現的,對數組是用下標遍歷來實現。Java 5 及以上的編譯器隱藏了基于 iteration 和數組下標遍歷的內部實現。
注意:這里說的是“Java 編譯器”或 Java 語言對其實現做了隱藏,而不是某段 Java 代碼對其實現做了隱藏,也就是說,我們在任何一段 JDK 的 Java 代碼中都找不到這里被隱藏的實現。這里的實現,隱藏在了Java 編譯器中,查看一段 foreach 的 Java 代碼編譯成的字節碼,從中揣測它到底是怎么實現的了。
我們寫一個例子來研究一下:
publicclassHashMapIteratorDemo{ String[]arr={ "aa", "bb", "cc" }; publicvoidtest1(){ for(Stringstr:arr){} } }
將上面的例子轉為字節碼反編譯一下(主函數部分):
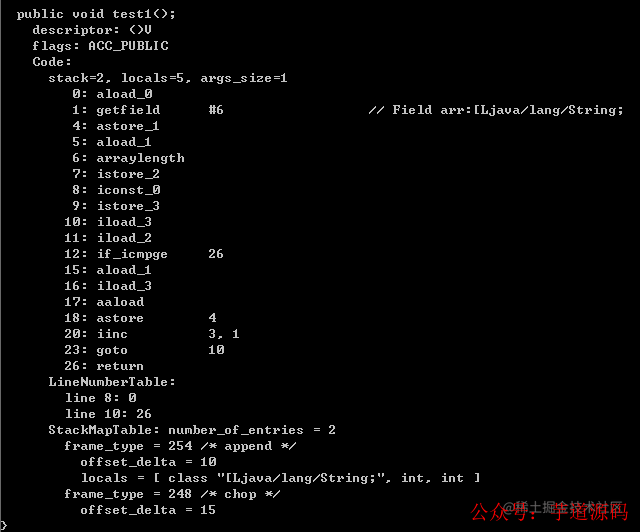
也許我們不能很清楚這些指令到底有什么作用,但是我們可以對比一下下面段代碼產生的字節碼指令:
publicclassHashMapIteratorDemo2{
String[]arr={
"aa",
"bb",
"cc"
};
publicvoidtest1(){
for(inti=0;i
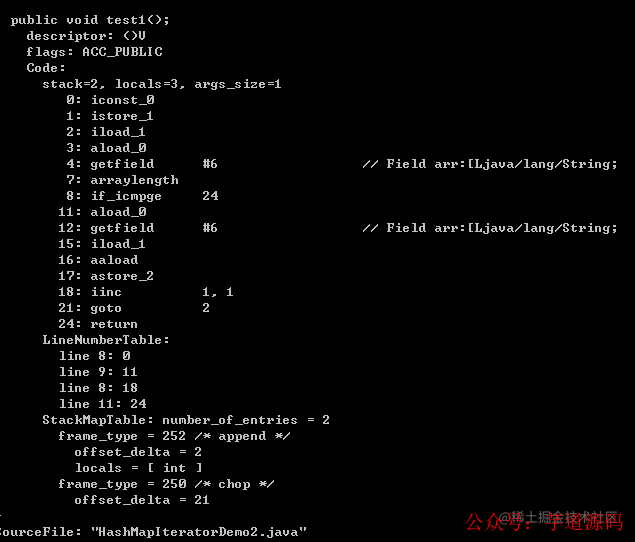
看看兩個字節碼文件,有木有發現指令幾乎相同,如果還有疑問我們再看看對集合的 foreach 操作:
通過 foreach 遍歷集合:
publicclassHashMapIteratorDemo3{
Listlist=newArrayList();
publicvoidtest1(){
list.add(1);
list.add(2);
list.add(3);
for(Integer
var:list){}
}
}
通過 Iterator 遍歷集合:
publicclassHashMapIteratorDemo4{
Listlist=newArrayList();
publicvoidtest1(){
list.add(1);
list.add(2);
list.add(3);
Iteratorit=list.iterator();
while(it.hasNext()){
Integer
var=it.next();
}
}
}
將兩個方法的字節碼對比如下:
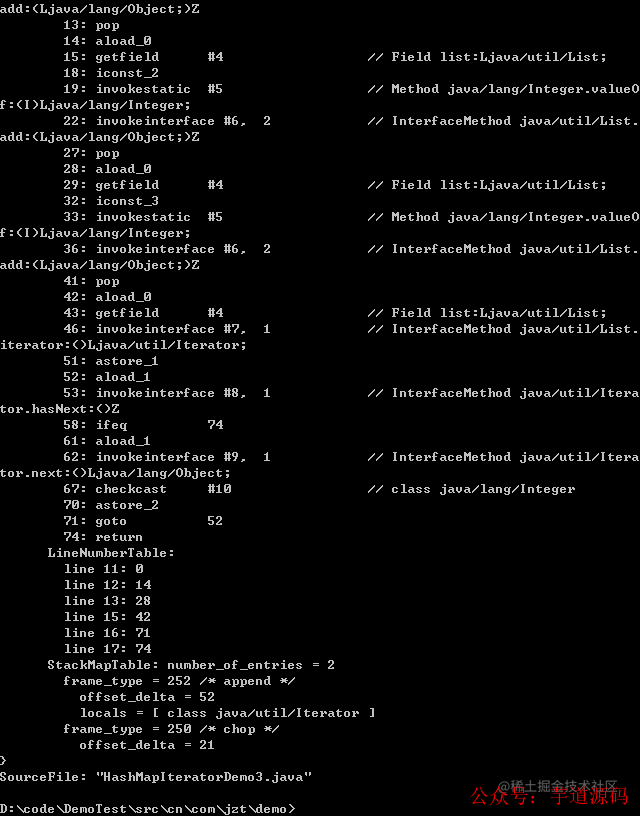
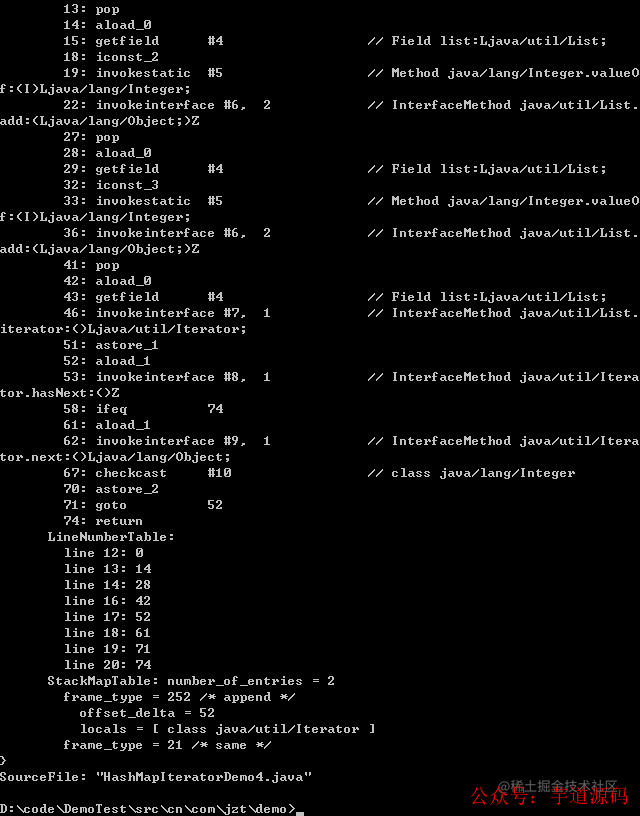
我們發現兩個方法字節碼指令操作幾乎一模一樣;
這樣我們可以得出以下結論:
對集合來說,由于集合都實現了 Iterator 迭代器,foreach 語法最終被編譯器轉為了對 Iterator.next() 的調用;
對于數組來說,就是轉化為對數組中的每一個元素的循環引用。
HashMap 遍歷集合并對集合元素進行 remove、put、add
1、現象
根據以上分析,我們知道 HashMap 底層是實現了 Iterator 迭代器的 ,那么理論上我們也是可以使用迭代器進行遍歷的,這倒是不假,例如下面:
publicclassHashMapIteratorDemo5{
publicstaticvoidmain(String[]args){
Mapmap=newHashMap();
map.put(1,"aa");
map.put(2,"bb");
map.put(3,"cc");
for(Map.Entryentry:map.entrySet()){
intk=entry.getKey();
Stringv=entry.getValue();
System.out.println(k+"="+v);
}
}
}
輸出:

OK,遍歷沒有問題,那么操作集合元素 remove、put、add 呢?
publicclassHashMapIteratorDemo5{
publicstaticvoidmain(String[]args){
Mapmap=newHashMap();
map.put(1,"aa");
map.put(2,"bb");
map.put(3,"cc");
for(Map.Entryentry:map.entrySet()){
intk=entry.getKey();
if(k==1){
map.put(1,"AA");
}
Stringv=entry.getValue();
System.out.println(k+"="+v);
}
}
}
執行結果:

執行沒有問題,put 操作也成功了。
但是!但是!但是!問題來了!!!
我們知道 HashMap 是一個線程不安全的集合類,如果使用 foreach 遍歷時,進行add, remove 操作會 java.util.ConcurrentModificationException 異常。put 操作可能會拋出該異常。(為什么說可能,這個我們后面解釋)
為什么會拋出這個異常呢?
我們先去看一下 Java API 文檔對 HasMap 操作的解釋吧。

翻譯過來大致的意思就是:該方法是返回此映射中包含的鍵的集合視圖。
集合由映射支持,如果在對集合進行迭代時修改了映射(通過迭代器自己的移除操作除外),則迭代的結果是未定義的。集合支持元素移除,通過 Iterator.remove、set.remove、removeAll、retainal 和 clear 操作從映射中移除相應的映射。簡單說,就是通過 map.entrySet() 這種方式遍歷集合時,不能對集合本身進行 remove、add 等操作,需要使用迭代器進行操作。
對于 put 操作,如果這個操作時替換操作如上例中將第一個元素進行修改,就沒有拋出異常,但是如果是使用 put 添加元素的操作,則肯定會拋出異常了。我們把上面的例子修改一下:
publicclassHashMapIteratorDemo5{
publicstaticvoidmain(String[]args){
Mapmap=newHashMap();
map.put(1,"aa");
map.put(2,"bb");
map.put(3,"cc");
for(Map.Entryentry:map.entrySet()){
intk=entry.getKey();
if(k==1){
map.put(4,"AA");
}
Stringv=entry.getValue();
System.out.println(k+"="+v);
}
}
}
執行出現異常:

這就是驗證了上面說的 put 操作可能會拋出 java.util.ConcurrentModificationException 異常。
但是有疑問了,我們上面說過 foreach 循環就是通過迭代器進行的遍歷啊?為什么到這里是不可以了呢?
這里其實很簡單,原因是我們的遍歷操作底層確實是通過迭代器進行的,但是我們的 remove 等操作是通過直接操作 map 進行的,如上例子:map.put(4, "AA"); //這里實際還是直接對集合進行的操作,而不是通過迭代器進行操作。所以依然會存在 ConcurrentModificationException 異常問題。
2、細究底層原理
我們再去看看 HashMap 的源碼,通過源代碼,我們發現集合在使用 Iterator 進行遍歷時都會用到這個方法:
finalNodenextNode(){
Node[]t;
Nodee=next;
if(modCount!=expectedModCount)
thrownewConcurrentModificationException();
if(e==null)
thrownewNoSuchElementException();
if((next=(current=e).next)==null&&(t=table)!=null){
do{}while(index
這里 modCount 是表示 map 中的元素被修改了幾次(在移除,新加元素時此值都會自增),而 expectedModCount 是表示期望的修改次數,在迭代器構造的時候這兩個值是相等,如果在遍歷過程中這兩個值出現了不同步就會拋出 ConcurrentModificationException 異常。
現在我們來看看集合 remove 操作:
(1)HashMap 本身的 remove 實現:
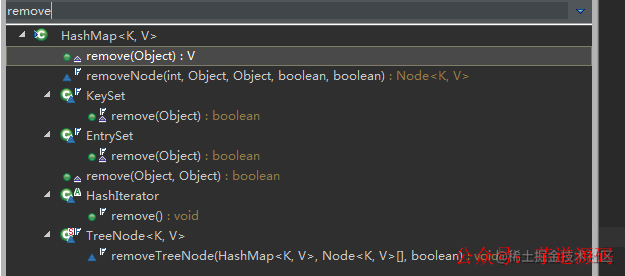
publicVremove(Objectkey){
Nodee;
return(e=removeNode(hash(key),key,null,false,true))==null?
null:e.value;
}
(2)HashMap.KeySet 的 remove 實現
publicfinalbooleanremove(Objectkey){
returnremoveNode(hash(key),key,null,false,true)!=null;
}
(3)HashMap.EntrySet 的 remove 實現
publicfinalbooleanremove(Objecto){
if(oinstanceofMap.Entry){
Map.Entry<e=(Map.Entry<)o;
Objectkey=e.getKey();
Objectvalue=e.getValue();
returnremoveNode(hash(key),key,value,true,true)!=null;
}
returnfalse;
}
(4)HashMap.HashIterator 的 remove 方法實現
publicfinalvoidremove(){
Nodep=current;
if(p==null)
thrownewIllegalStateException();
if(modCount!=expectedModCount)
thrownewConcurrentModificationException();
current=null;
Kkey=p.key;
removeNode(hash(key),key,null,false,false);
expectedModCount=modCount;//--這里將expectedModCount與modCount進行同步
}
以上四種方式都通過調用 HashMap.removeNode 方法來實現刪除key的操作。在 removeNode 方法內只要移除了 key, modCount 就會執行一次自增操作,此時 modCount 就與 expectedModCount 不一致了;
finalNoderemoveNode(inthash,Objectkey,Objectvalue,
booleanmatchValue,booleanmovable){
Node[]tab;
Nodep;
intn,index;
if((tab=table)!=null&&(n=tab.length)>0&&
...
if(node!=null&&(!matchValue||(v=node.value)==value||
(value!=null&&value.equals(v)))){
if(nodeinstanceofTreeNode)
((TreeNode)node).removeTreeNode(this,tab,movable);
elseif(node==p)
tab[index]=node.next;
else
p.next=node.next;
++modCount;//----這里對modCount進行了自增,可能會導致后面與expectedModCount不一致
--size;
afterNodeRemoval(node);
returnnode;
}
}
returnnull;
}
上面三種 remove 實現中,只有第三種 iterator 的 remove 方法在調用完 removeNode 方法后同步了 expectedModCount 值與 modCount 相同,所以在遍歷下個元素調用 nextNode 方法時,iterator 方式不會拋異常。
到這里是不是有一種恍然大明白的感覺呢!
所以,如果需要對集合遍歷時進行元素操作需要借助 Iterator 迭代器進行,如下:
publicclassHashMapIteratorDemo5{
publicstaticvoidmain(String[]args){
Mapmap=newHashMap();
map.put(1,"aa");
map.put(2,"bb");
map.put(3,"cc");
Iterator>it=map.entrySet().iterator();
while(it.hasNext()){
Map.Entryentry=it.next();
intkey=entry.getKey();
if(key==1){
it.remove();
}
}
}
}
審核編輯:劉清
-
編譯器
+關注
關注
1文章
1618瀏覽量
49052 -
JAVA語言
+關注
關注
0文章
138瀏覽量
20076 -
hashmap
+關注
關注
0文章
14瀏覽量
2277
原文標題:HashMap 為什么不能一邊遍歷一遍刪除
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
手機如何實現一邊充電一邊聽歌(邊充邊聽)呢
Merkle樹遍歷技術的研究
二叉樹的前序遍歷、中序遍歷、后續遍歷的非遞歸實現
圖不同存儲方式的應用和遍歷操作及綜合應用資料說明

螺旋遍歷二維數組漫畫講解

二叉樹的前序遍歷非遞歸實現
總結一下OpenCV遍歷圖像的幾種方法

如何遍歷中文字符串





 工商網監
工商網監
評論