 性別偏見探索和緩解的中文數據集-CORGI-PM
性別偏見探索和緩解的中文數據集-CORGI-PM
介紹
大規模語言模型(LMs)已經成為了現在自然語言處理的關鍵技術,但由于訓練語料中常帶有主觀的性別偏見、歧視等,在大模型的使用過程中,它們時常會被放大,因此探測和緩解數據中的性別偏見變得越來越重要。
部分研究通過性別交換等自動標注方法,緩解性別偏見的語料庫;也有一些人工標注的性別偏見語料庫,但主要集中在單詞層面或語法層面的偏見,或只關注與性別歧視相關的話題,并主要以英文為主。因此,該論文提出了第一個用于性別偏見探測和緩解的句子級中文語料庫,采用一種自動方法(如圖1所示,對含有性別偏見得分高的詞的樣本進行召回,然后根據其句子級性別偏見概率對樣本進行重新排序和過濾),從現有的大規模中文語料庫中構建可能存在性別偏見的句子集,再通過精心設計的標注方案,對候選數據集進行進一步的標注,構建可以用于性別偏見檢測、分類和緩解三種任務的數據集。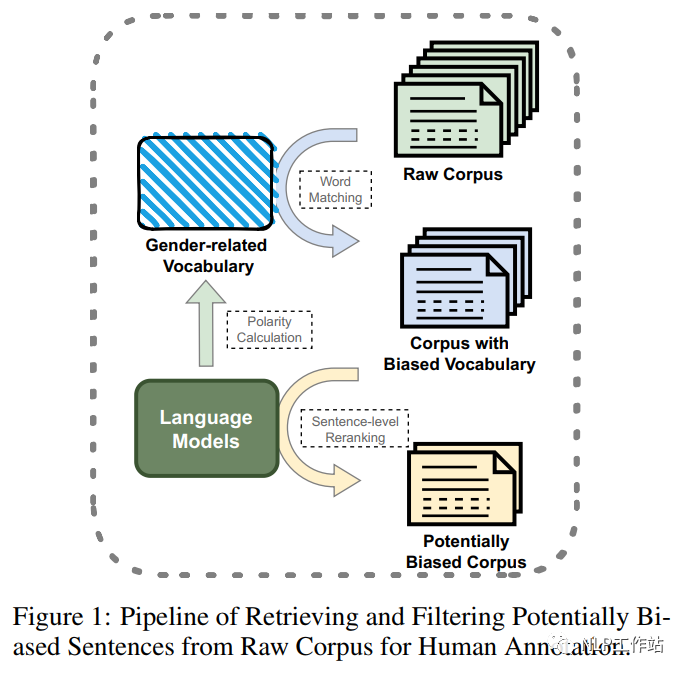
數據構建
樣本過濾
如圖1所示,該研究通過單詞級到句子級的兩階段過濾,從原始語料庫中召回、排序和過濾待標注候選數據。對于詞級別過濾,通過計算目標詞與種子方向之間得分,構建一個高偏見分數的詞表,并從原始語料庫中匹配包含這些詞語的句子,為初步候選集合。其中得分計算如下: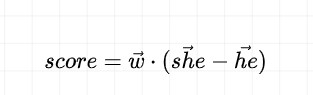
正值表示該詞語更適合女性,負值表示該詞語更適合男性,性別偏見得分絕對值越高,說明該詞語的偏見程度越高。過濾得到的詞匯繪制的詞云如圖5所示,
對于句子級別過濾,計算句子的性別偏見得分,并根據獲得性別偏見關鍵詞進行分組,然后根據特定的全局閾值性別偏見得分和組內閾值排名選擇待標注的最終句子集合。
標注規則
標注方案為標注人員對一個句子進行判斷,判斷是否存在性別偏見;如果存在,則需要給出偏見具體類型,并為了緩解性別偏見,還需要對有偏見的句子進行糾正,給出無偏見句子。為保證標注質量,6名標注人員均具有學士學位,并且男女比例相同。
「偏見類別」共包含3種:
AC:性別刻板的活動和職業選擇;
DI:性別刻板的描述和概況;
ANB:表達性別刻板的態度、規范和信仰。
緩解性別偏見主要是在保留原始語義信息的同時,減輕所選句子的性別偏見,并要求標注者進行使句子的表達式多樣化,主要修改規則如下:
用中性代詞取代性別代詞;
用語義定義相近的中性描述替換性別特定的形容詞;
對不能直接減輕的句子,添加額外的解釋進行中和。
標注過程分為兩個階段:第一階段,各標注者進行標注,并要求不要輸入不確定樣本;第二階段,標注者之間進行交叉標注。
語料分析
CORGI-PM數據統計如表1所示,共包含32.9k數據,并考慮數據分布,劃分了訓練集、驗證集及測試集。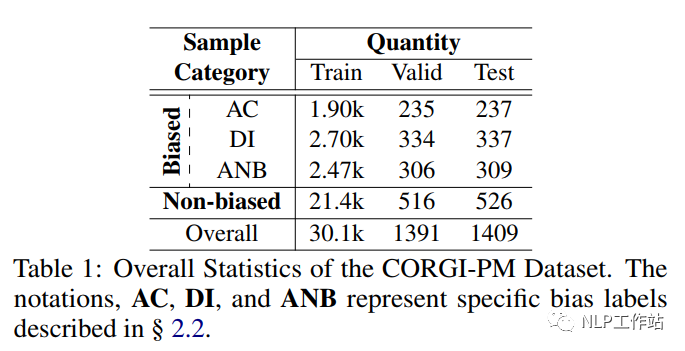
如表2所示,發現偏見句子相較于無偏見句子來說,句子更長,包含詞匯更少;但由于去偏句子需要在保持原意圖語義不變、句子連貫、減輕偏見,因此去偏樣本與原樣本相比表達更長、更多樣化。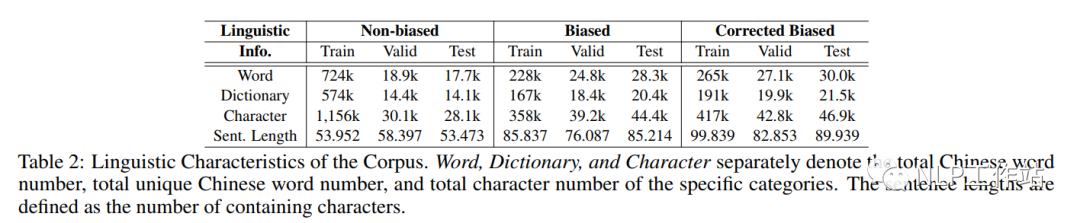
偏見數據格式樣例:
{
'train':{
#原始句子
'ori_sentence':[
sent_0,
sent_1,
...,
],
#偏見類型
'bias_labels':[
[010],
[010],
[010],
...,
],
#人工去偏句子
'edit_sentence':[
edited_sent_0,
edited_sent_1,
...,
],
},
'valid':{
...#與訓練集一致
},
'test':{
...#與訓練集一致
}
}
無偏見數據格式樣例:
{
'train':{
#原始句子
'text':[
sent_0,
sent_1,
...,
],
},
'valid':{
...#與訓練集一致
},
'test':{
...#與訓練集一致
}
}
實驗結果
針對性別偏見檢測及分類任務,以Precision、Recall和F1作為評價指標,采用BERT、Electra和XLNet模型進行微調進行實驗對比,并采用GPT-3 Curie模型進行zero-shot實驗,結果如表3所示。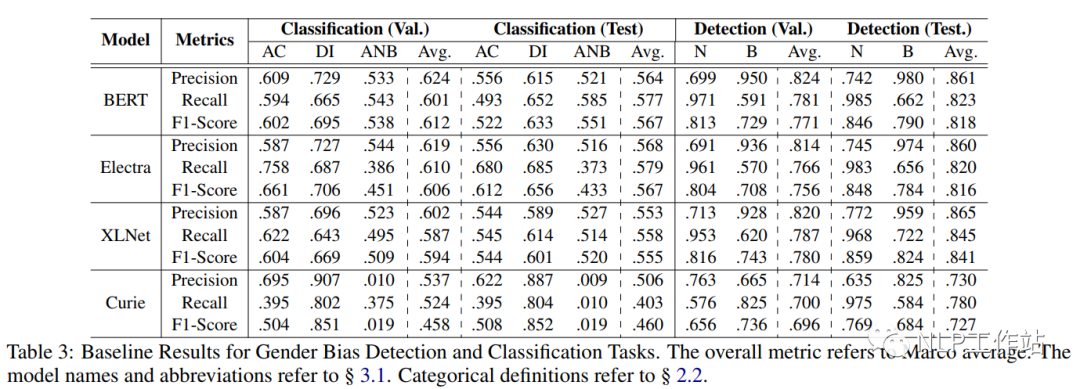
針對性別緩解任務,采用GPT-3 Ada(350M)、Babbage(1.3B)和Curie(6.7B)進行微調, 并采用Davinci(175B)進行zero-shot實驗,結果如表4所示。
總結
中文首個性別偏見探索和緩解數據集,開源不易,且用且珍惜。
審核編輯:劉清
-
RGB
+關注
關注
4文章
798瀏覽量
58388 -
過濾器
+關注
關注
1文章
427瀏覽量
19559 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:CORGI-PM:首個中文性別偏見探索和緩解數據集
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
那個涉嫌性別歧視被開除的谷歌工程師,到底吐槽了些什么?
本應公平公正的 AI,卻從數據中學會了人類的偏見
Spectre和Meltdown的利用漏洞的軟件影響和緩解措施
人工智能遭遇的偏見 算法偏見帶來的問題
IBM打造百萬人臉數據 意圖減少AI偏見與歧視問題
Cloud AI提供免費消除性別偏見 將不再標識性別
谷歌的AI工具已可以通過人的圖像標記來識別個人的性別
AI可能帶有性別偏見?Salesforce提出了減輕AI性別偏見的方法





 工商網監
工商網監
評論