 一篇看懂圖像分類基礎知識
一篇看懂圖像分類基礎知識
?
基礎知識
1.具體領域劃分
(1)多類別圖像分類
(2)細粒度圖像分類
(3)多標簽圖像分類
(4)弱監督與無監督圖像分類
(5)零樣本圖像分類
2.圖像分類問題的3層境界

多類別圖像分類在不同物種的層次上識別,往往具有較大的類間方差,而類內則具有較小的類內誤差。

細粒度圖像分類具有更加相似的外觀和特征,導致數據間的類內差異較大,分類難度也更高。

實例級分類可以看做是一個識別問題,比如人臉識別。

3.傳統圖像分類關鍵問題
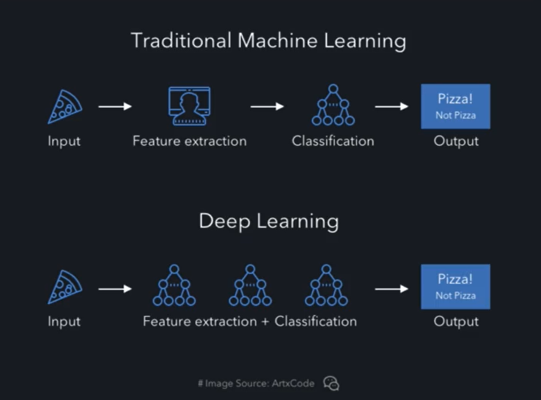
(1)數據預處理 (2)圖像特征 (3)分類模型
分為兩種: 手工特征+分類器、從數據自動學習特征
4.常用的圖像分類數據集
(1) MNIST數據集:
發布于1998年,60000張圖,10類,分布均勻,數據集中的”hello world”
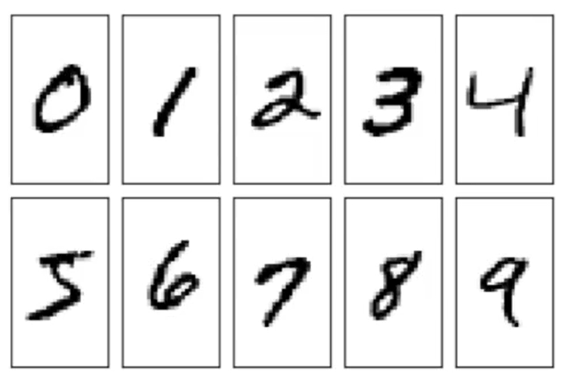
在票據等圖像中裁剪出數字,將其放在20 * 20像素的框中,并保持了長寬比率,然后放在28* 28的背景中。
(2) CIFAR10
MNIST的彩色增強版,60000張圖片,大小32 * 32,10類,均勻分布,都是真實圖片而不是手稿等,圖中只有一個主體目標,可以有部分遮擋,但是必須可辨識。

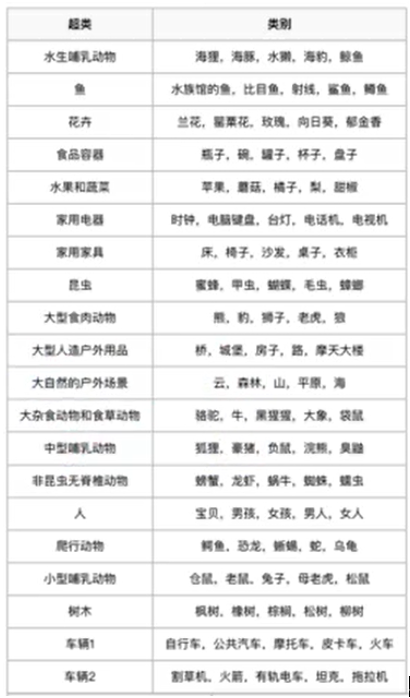
(3) CIFAR100
更加細粒度的CIFAR10,共100類,被分成20個超類。
每小類包含600個圖像,其中有500個訓練圖像和100個測試圖像。每個圖像都帶有一個“精細”標簽(它所屬的類)和一個粗糙的標簽(它所屬的超類)

(4) PASCAL
來源于2005-2012的PASCAL Visual Object Classes(VOC項目),20類,來源于圖片社交網站flickr,總共9963張圖,24640個標注目標。
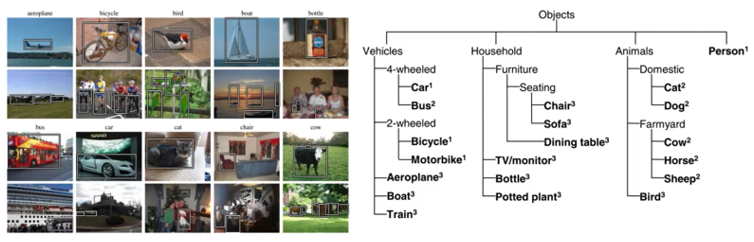
2005年主要用于目標檢測,從2007年開始引進了圖像分割的標注和人體結構布局的標注,2010年開始引進了行為分類標注。

(5)ImageNet數據集
包含21841個類別,14197122張圖片,百萬標注框

5 評估指標
(1)正負樣本
計標簽為正樣本,分類為正樣本的數目為True Positive,簡稱TP,標簽為正樣本,分類為負樣本的數目為「False Negative」,簡稱FN,標簽為負樣本,分類為正樣本的數目為「False Positive」,簡稱FP,標簽為負樣本,分類為負樣本的數目為「True Negative」,簡稱TN。

(2)精確率、召回率、F1值
精度(查準率): 被判定為正樣本的測試樣本中,真正的正樣本所占的比例
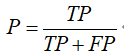
召回率(查全率): 被判定為正樣本的正樣本占全部正樣本的比例
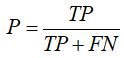
F1-score是綜合考慮了精度與召回率,其值越大模型越好。
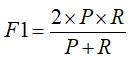
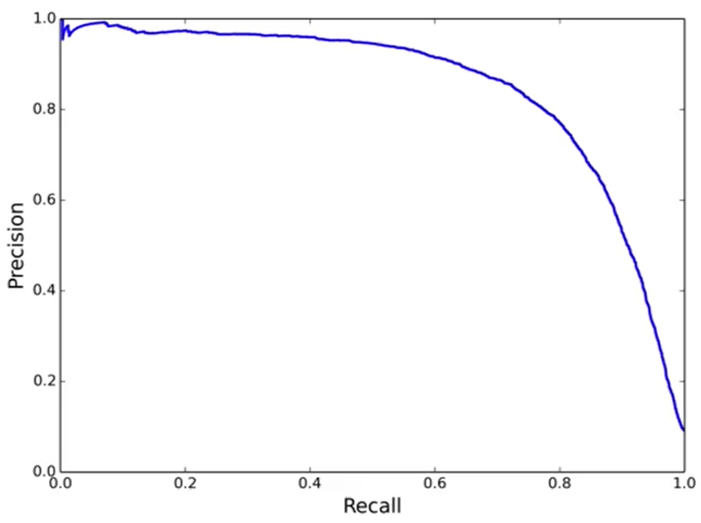
(3)PR曲線
精度與召回率是一對相互矛盾的指標,召回率增加,精度下降,曲線與坐標值面積越大,性能越好,對正負樣本不均衡敏感。
(4)ROC曲線與AUC
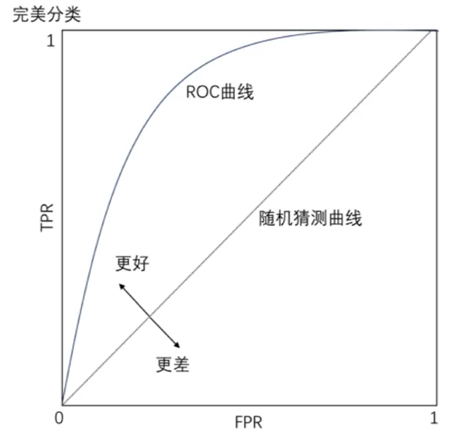
橫坐標(假陽率)FPR=FP/(FR+TN) 正類中實際負實例占所有負實例的比例。
縱坐標(正陽率) TPR=TP/(TP+FN) 正類中實際正實例占所有正實例的比例。
正負樣本的分布變化,ROC曲線保持不變,對正負樣本不均衡問題不敏感。
AUC(Area Under Curve): ROC曲線下的面積,表示隨機挑選一個正樣本以及一個負樣本,分類器會對正樣本給出的預測值高于負樣本的概率。
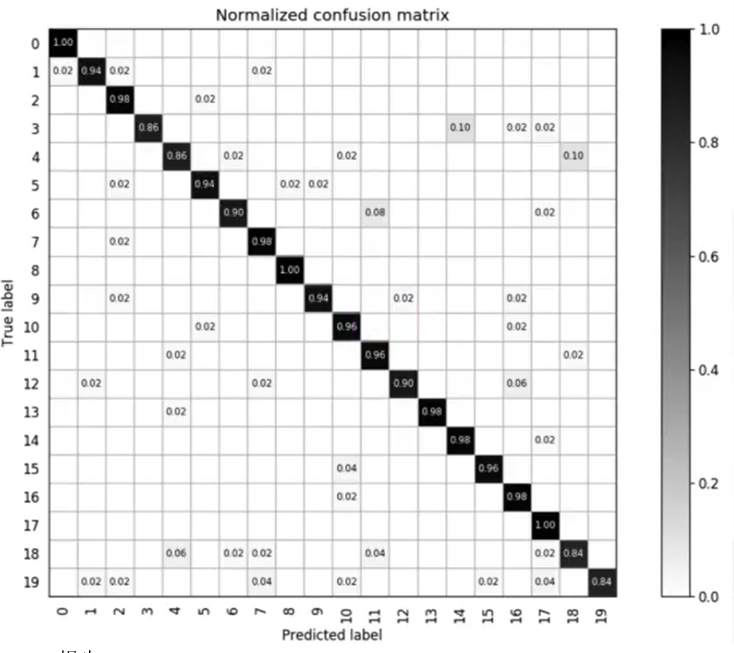
(5)混淆矩陣
多矩陣分類模型各個類別之間的分類情況。
對于k分類問題,混淆矩陣為k*k的矩陣,元素Cij表示第i類樣本被分類器判定為第j類的數量。
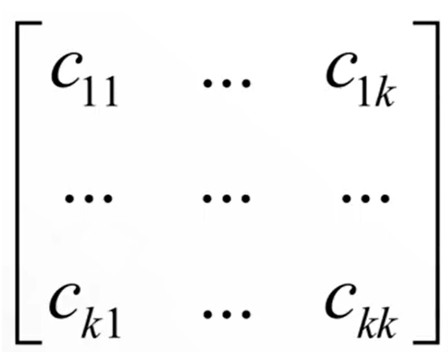
主對角線的元素之和為正確分類的樣本數,其他位置元素之和為錯誤分類的樣本數。對角線之和值越大,正確率越高。
混淆矩陣可以很清晰的反映出各類別之間的錯分概率,越好的分類器對角線上的值更大。
(6)0-1損失
只看分類的對錯,當標簽與與類別相等時,loss為0,否則為1。
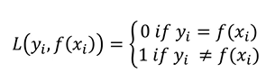
這個是真實的優化目標,但是無法求導和優化,只有理論意義。
(7)熵與交叉熵(cross entropy)
熵表示熱力學系統的無序程序,在信息學中用于表示信息多少,不確定性越大,概率越低,則信息越多,熵越高。
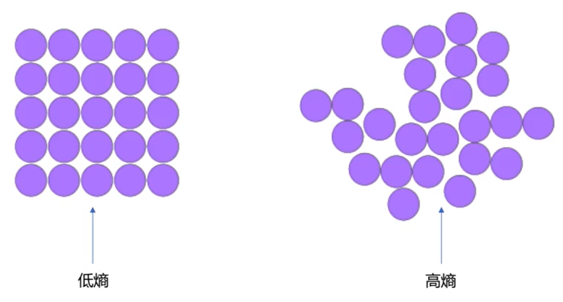
熵是概率的單調遞減的函數。

(8)KL散度
用于估計兩個分布p和q的相似性
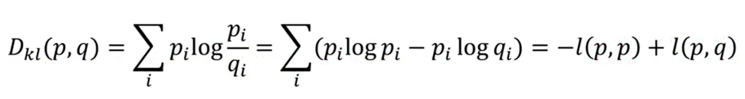
如果p是一個已知的分布(標簽),則-l(p,p)是一個常數,此時KL散度與交叉熵l(p,q)只有一個常數的差異。
KL散度的特性是大于等于0,當且僅當兩個分布完全相同時等于0。
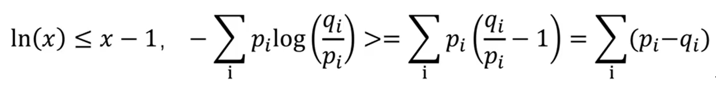
-
模型
+關注
關注
1文章
3172瀏覽量
48714 -
圖像分類
+關注
關注
0文章
90瀏覽量
11907 -
數據集
+關注
關注
4文章
1205瀏覽量
24644
原文標題:小白必讀!一篇看懂圖像分類基礎知識
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
鴻蒙移植必備的基礎知識

117篇電子基礎知識文章大全

了解一下機器學習中的基礎知識

圖像處理基礎知識及OpenCV入門函數
圖像處理基礎知識 1





 工商網監
工商網監
評論