 使用CNN進行2D路徑規劃
使用CNN進行2D路徑規劃
本文將介紹CNN應用于解決簡單的二維路徑規劃問題。
卷積神經網絡(CNN)是解決圖像分類、分割、目標檢測等任務的流行模型。本文將CNN應用于解決簡單的二維路徑規劃問題。主要使用Python, PyTorch, NumPy和OpenCV。
任務
簡單地說,給定一個網格圖,二維路徑規劃就是尋找從給定起點到所需目標位置(目標)的最短路徑。機器人技術是路徑規劃至關重要的主要領域之一。A、D、D* lite 和相關變體等算法就是為解決此類問題而開發的。如今強化學習被廣泛用于解決這一問題。本文將嘗試僅使用卷積神經網絡來解決簡單的路徑規劃實例。
數據集
我們的主要問題是(在機器學習中一如既往)在哪里可以找到數據。雖然沒有現成的數據集可用,但是我們可以通過制作隨機二維地圖創建自己的路徑規劃數據集。創建地圖的過程非常簡單:
從一個 100x100 像素的方形空矩陣 M 開始。
對于矩陣中的每一項(像素),從0到1均勻分布抽取一個隨機數r。如果 r > diff,則將該像素設置為 1;否則,將其設置為 0。這里的 diff 是一個參數,表示像素成為障礙物(即無法穿越的位置)的概率,它與在該地圖上找到可行路徑的難度成正比。
然后讓我們利用形態學來獲得更類似于真實占用網格地圖的“塊狀”效果。通過改變形態結構元素的大小和 diff 參數,能夠生成具有不同難度級別的地圖。

對于每張地圖需要選擇 2 個不同的位置:起點 (s) 和終點 (g)。該選擇同樣是隨意的,但這次必須確保 s 和 g 之間的歐幾里得距離大于給定閾值(使實例具有挑戰性)。
最后需要找到從 s 到 g 的最短路徑。這是我們訓練的目標。所以可以直接使用了流行的 D* lite 算法。
我們生成的數據集包含大約 230k 個樣本(170k 用于訓練,50k 用于測試,15k 用于驗證)。數據量很大,所以我使用 Boost c++ 庫將自定義的 D* lite 重寫為 python 擴展模塊。使用這個模塊,生成超過 10k 個樣本/小時,而使用純 python 實現,速率約為 1k 個樣本/小時(i7–6500U 8GB 內存)。自定義 D* lite 實現的代碼會在文末提供。
然后就是對數據做一些簡單的檢查,比如刪掉余弦相似度很高,起點和終點坐標太近的地圖。數據和代碼也都會在文末提供。
模型架構
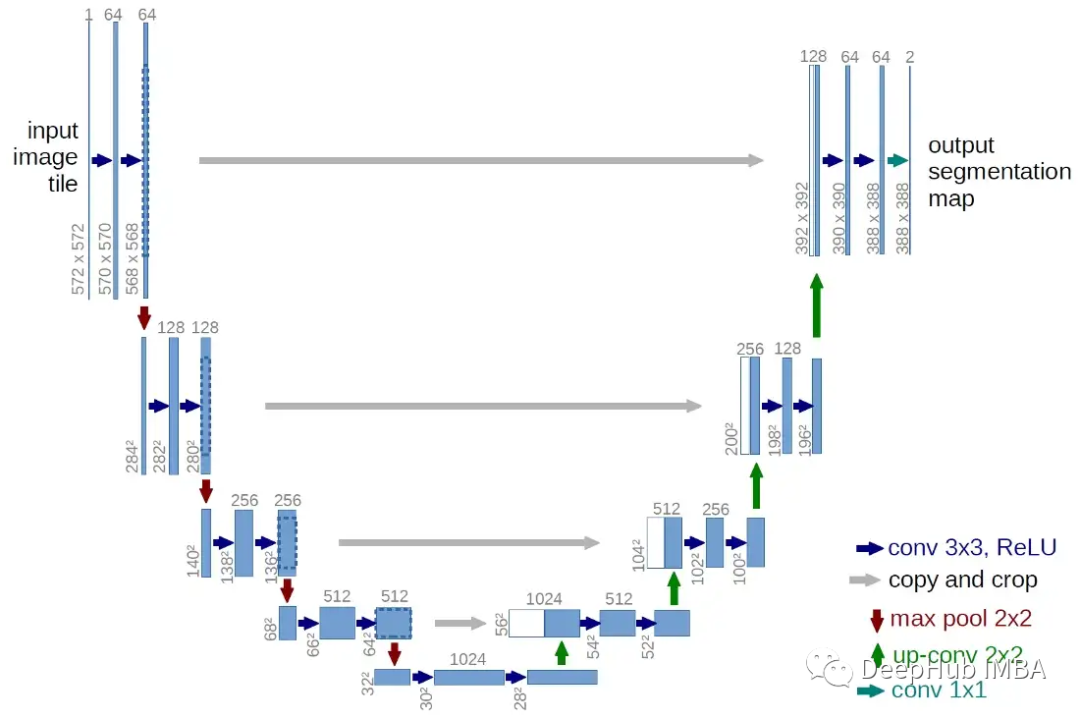
模型是經典的編碼器-解碼器架構,將 20 個卷積層分為 3 個卷積塊(編碼部分),然后是另外 3 個轉置卷積塊(解碼部分)。每個塊由 3 個 3x3 卷積層組成,每個層之間有BN和 ReLU 激活。最后,還有另外 2 個 conv 層,加上輸出層。編碼器的目標是找出輸入壓縮后的相關表示。解碼器部分將嘗試重建相同的輸入映射,但這次嵌入的有用信息應該有助于找到從 s 到 g 的最佳路徑。
該網絡的輸入是:
map:一個 [n, 3, 100, 100] 張量,表示占用網格圖。n 是批量大小。這里的通道數是 3 而不是簡單的 1。稍后會詳細介紹。
start: 一個 [n, 2] 張量,包含每個地圖中起點 s 的坐標
goal:一個[n, 2]張量,包含每個地圖中目標點g的坐標
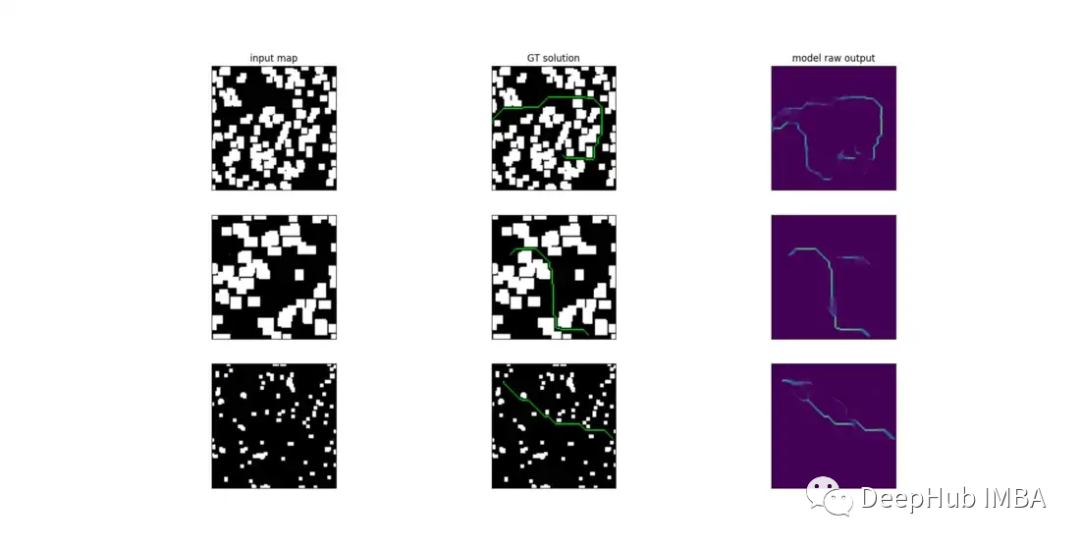
網絡的輸出層應用 sigmoid 函數,有效地提供了一個“分數圖”,其中每個項目的值都在 0 和 1 之間,與屬于從 s 到 g 的最短路徑的概率成正比。然后可以通過從 s 開始并迭代地選擇當前 8 鄰域中得分最高的點來重建路徑。一旦找到與 g 具有相同坐標的點,該過程就會結束。為了提高效率,我為此使用了雙向搜索算法。
在模型的編碼器和解碼器塊之間,我還插入了 2 個跳過連接。該模型現在非常類似于 U-Net 的架構。跳過連接將給定隱藏層的輸出注入網絡中更深的其他層。在我們的任務中關心的細節是 s、g 的確切位置,以及我們在軌跡中必須避開的所有障礙物。所以加入跳過鏈接大大提高了效果。
訓練
在Google Colab 上對模型進行了大約 15 小時或 23 個周期的訓練。使用的損失函數是均方誤差 (MSE)。可能有比 MSE 更好的選擇,但我一直堅持使用它,因為它簡單易用。
學習率最初使用 CosineAnnealingWithWarmRestarts 調度程序設置為 0.001(略微修改以降低每次重啟后的最大學習率)。批量大小設置為 160。
我嘗試對輸入圖應用高斯模糊,并在第一個卷積層應用一個小的 dropout。這些技術都沒有帶來任何相關效果,所以我最終放棄了它們。
下面是訓練后模型原始輸出的可視化。


卷積的一些問題
起初使用輸入是一個形狀為 [n, 1, 100, 100](加上起始位置和目標位置)的張量。但無法獲得任何令人滿意的結果。重建的路徑只是完全偏離目標位置并穿過障礙物的隨機軌跡。
卷積算子的一個關鍵特征是它是位置不變的。卷積濾波器學習的實際上是一種特定的像素模式,這種像素模式在它所訓練的數據分布中反復出現。例如下面的圖案可以表示角或垂直邊緣。

無論過濾器學習什么模式,關鍵的問題是它學會獨立于圖像中的位置來識別它。對于像圖像分類這樣的任務來說,這無疑是一個理想的特性,因為在這些任務中,表征目標類的模式可能出現在圖像的任何地方。但在我們的情況下,位置是至關重要的!我們需要這個網絡非常清楚的知道軌跡從哪里開始,從哪里結束。
位置編碼
位置編碼是一種通過將數據嵌入(通常是簡單的和)到數據本身中來注入關于數據位置的信息的技術。它通常應用于自然語言處理(NLP)中,使模型意識到句子中單詞的位置。我想這樣的東西對我們的任務也有幫助。
我通過在輸入占用圖中添加這樣的位置編碼進行了一些實驗,但效果并不好。可能是因為通過添加關于地圖上每個可能位置的信息,違背了卷積的位置不變性,所以濾波器現在是無用的。
所以這里基于對路徑規劃的觀察,我們對絕對位置不感興趣,而只對相對范圍感興趣。也就是說,我們感興趣的是占用圖中每個單元格相對于起點s和目標點g的位置。例如,以坐標(x, y)為單元格。我并不真正關心(x, y)是否等于(45,89)還是(0,5)。我們關心的是(x, y)距離s 34格,距離g15格。
所以我為每個占用網格圖創建2個額外的通道,現在它的形狀為[3,100,100] 。第一個通道是圖像。第二個通道表示一個位置編碼,它為每個像素分配一個相對于起始位置的值。第三通道則是相對于結束位置的值。這樣的編碼是通過分別從以s和g為中心的二維高斯函數創建2個特征映射來實現的。Sigma被選為核大小的五分之一(通常在高斯濾波器中)。在我們的例子中是20,地圖大小是100。
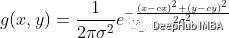
在注入關于期望的軌跡起始和最終位置的有用信息的同時,我們還部分地保留了與過濾器位置不變性的一致性。可學習的模式現在只依賴于相對于給定點的距離,而不是地圖上每個可能的位置。距離s或g相同距離的2個相等的圖案現在將觸發相同的過濾器激活。經過實驗這個小技巧在收斂訓練中非常有效。

結果和結論
通過測試了超過 51103 個樣本的訓練模型。
95% 的總測試樣本能夠使用雙向搜索提供解決方案。也就是說,該算法使用模型給出的得分圖可以在 48556 個樣本中找到從 s 到 g 的路徑,而對于其余 2547 個樣本則無法找到。
總測試樣本的 87% 提供了有效的解決方案。也就是說從 s 到 g 的軌跡不穿越任何障礙物(該值不考慮 1 個單元格的障礙物邊緣約束)。
在有效樣本上,真實路徑與模型提供的解決方案之間的平均誤差為 33 個單元格。考慮到地圖是 100x100 單元格,這是相當高的。錯誤范圍從最小 0(即,在 2491 個樣本中的真實路徑被“完美”的重建了)到最大……745 個單元(這個肯定還有一些問題)。
下面可以看看我們測試集中的一些結果。圖像的左側描述了訓練過的網絡提供的解決方案,而右側顯示了D* lite算法的解決方案。
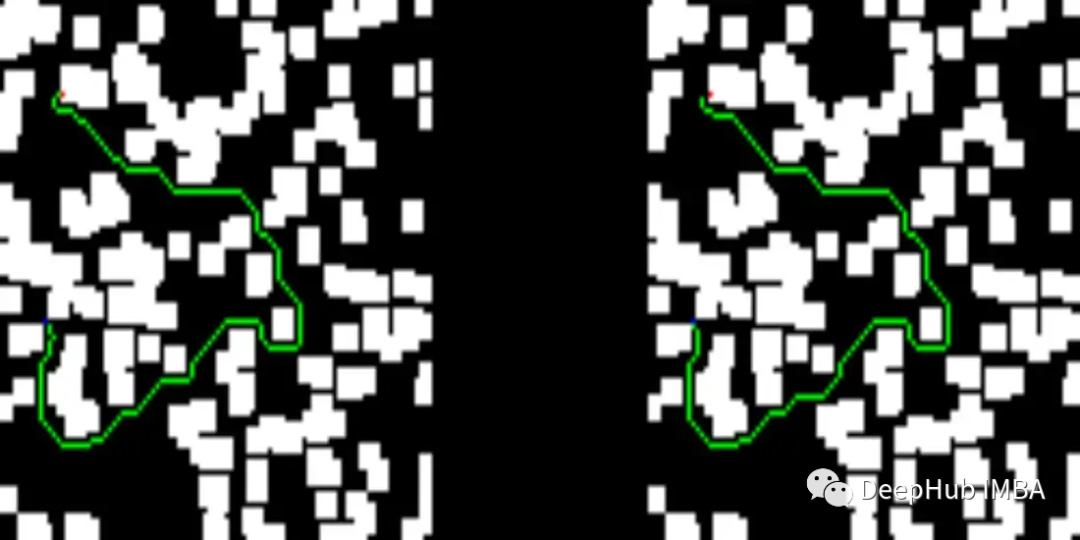

我們網絡提供的解決方案比D* lite給出的解決方案短:

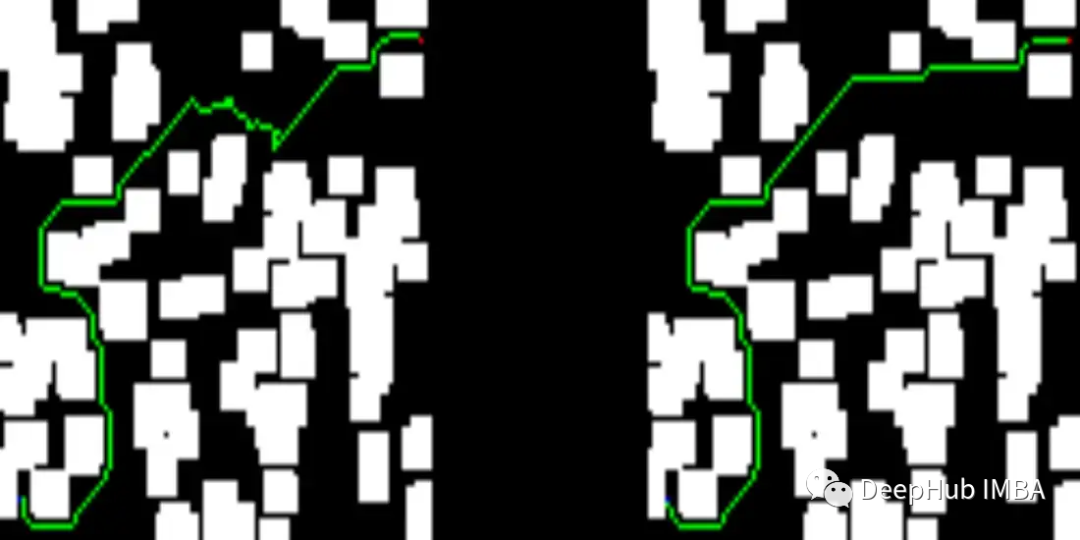
下面就是一些錯誤的圖:


看著應該是感受野不太大,所以在感受野的區域內沒有找到任何的邊緣,這個可能還要再改進模型。
-
python
+關注
關注
56文章
4783瀏覽量
84473 -
cnn
+關注
關注
3文章
351瀏覽量
22178
原文標題:使用CNN進行2D路徑規劃
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多臺倉儲AGV協作全局路徑規劃算法的研究

Allegro推出2D霍爾效應速度和方向鎖存器

3D封裝熱設計:挑戰與機遇并存

【Vision Board創客營連載體驗】基于RA8D1-Vision Board的自動路徑規劃小車
通過2D/3D異質結構精確控制鐵電材料弛豫時間


有了2D NAND,為什么要升級到3D呢?

谷歌DeepMind推新AI模型Genie,能生成2D游戲平臺
一文了解3D視覺和2D視覺的區別
2D與3D視覺技術的比較
使用Python從2D圖像進行3D重建過程詳解

機器視覺系統組成 3D相機與2D相機的區別





 工商網監
工商網監
評論