 ChatGPT實現原理
ChatGPT實現原理
ChatGPT實現原理
用自然語言與計算機進行通信,ChatGPT實現了,那么ChatGPT實現原理是什么?
ChatGPT(Generative Pre-train Transformer)是由OpenAI發明的一種自然語言處理技術。它是一種預訓練的深度學習模型,可以用來生成文本,識別語義,做文本分類等任務。
ChatGPT實現原理
火爆的ChatGPT,得益于AIGC 背后的關鍵技術NLP(Natural LanguageProcessing,自然語言處理)得到突破。自然語言處理應用在過去十年呈爆炸式增長,NLP技術是一種自然語言處理技術,用于計算機中模擬人類的對話和文本理解。主要源于AI大模型化的NLP技術突破是將深度學習技術與傳統的NLP方法結合在一起,從而更好地提高NLP技術的準確性和效率。大模型化的NLP技術能夠更好地支持企業進行大規模的語料內容分析,并為企業更好地進行文本分析提供幫助。
NLP類模型要理解單詞的含義,還要理解如何造句和給出上下文有意義的回答,甚至使用合適的俚語和專業詞匯。
我們看到ChatGPT的回答是這樣的:
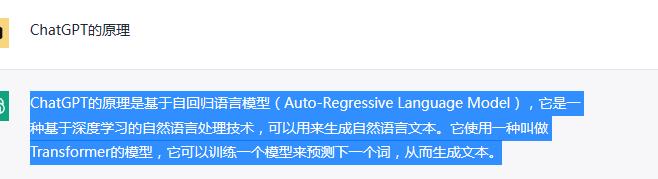
ChatGPT的原理是基于自回歸語言模型(Auto-Regressive Language Model),它是一種基于深度學習的自然語言處理技術,可以用來生成自然語言文本。它使用一種叫做Transformer的模型,它可以訓練一個模型來預測下一個詞,從而生成文本。
人類反饋強化學習
同時OpenAI采用了 RLHF(Reinforcement Learning from Human Feedbac,人類反饋強化學習) 技術對 ChatGPT 進行了訓練,而加入了更多人工監督進行微調。所以我們可以看到,一些錯誤的信息會逐步被更正。而且在很多用戶的測試中可以發現,若用戶指出其錯誤,模型會聽取意見并優化答案。
InstructGPT/GPT3.5(ChatGPT的前身)與GPT-3的主要區別在于,新加入了被稱為RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學習)。
InstructGPT的目標就是緩解這種生成回復與真實回復之間的偏置產生更加符合人類預期的回復。
chatGPT是一種基于轉移學習的大型語言模型,它使用GPT-2 (Generative PretrainedTransformer2)模型的技術,使用了transformer的架構,并進行了進一步的訓練和優化。
chatGPT是在GPT-2模型的基礎上進一步訓練和優化而得到的。 它使用了更多的語料庫,并且進行了專門的訓練來提高在對話系統中的表現。這使得chatGPT能夠在對話中白然地回應用戶的輸入,并且能夠生成流暢、連貫、通順的文本。
那么接下來我們來看下什么是InstructGPT。從字面上來看,顧名思義,它就是指令式的GPT,“which is trained to follow an instruction in a prompt and provide a detailed response”。接下來我們來看下InstructGPT論文中的主要原理:
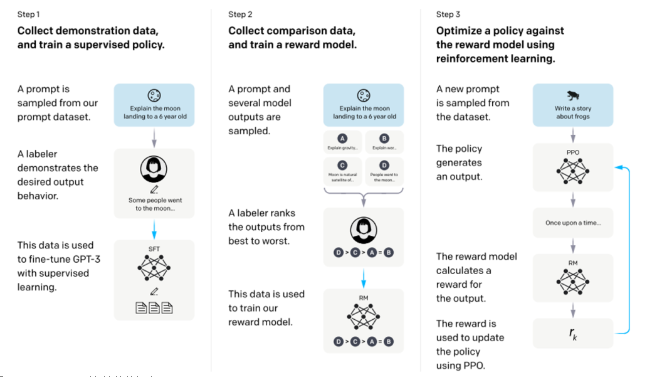
InstructGPT整體訓練流程
從該圖可以看出,InstructGPT是基于GPT-3模型訓練出來的,具體步驟如下:
步驟1.)從GPT-3的輸入語句數據集中采樣部分輸入,基于這些輸入,采用人工標注完成希望得到輸出結果與行為,然后利用這些標注數據進行GPT-3有監督的訓練。該模型即作為指令式GPT的冷啟動模型。
步驟2.)在采樣的輸入語句中,進行前向推理獲得多個模型輸出結果,通過人工標注進行這些輸出結果的排序打標。最終這些標注數據用來訓練reward反饋模型。
步驟3.)采樣新的輸入語句,policy策略網絡生成輸出結果,然后通過reward反饋模型計算反饋,該反饋回過頭來作用于policy策略網絡。以此反復,這里就是標準的reinforcement learning強化學習的訓練框架了。
所以總結起來ChatGPT(對話GPT)其實就是InstructGPT(指令式GPT)的同源模型,然后指令式GPT就是基于GPT-3,先通過人工標注方式訓練出強化學習的冷啟動模型與reward反饋模型,最后通過強化學習的方式學習出對話友好型的ChatGPT模型。
InstructGPT的訓練實際上是分為三個階段的,第一階段就是我們上文所述,利用人工標注的數據微調GPT3;第二階段,需要訓練一個評價模型即Reward Model,該模型需學習人類對于模型回復的評價方式,對于給定的上文與生成回復給出分數;第三階段,利用訓練好的Reward Model作為反饋信號,去指導GPT進一步進行微調,將目標設定為Reward分數最大化,從而使模型產生更加符合人類偏好的回復。
自然語言理解的不同發展階段
在20世紀60年代,隨著計算機技術的發展,自然語言處理技術也進一步提升。當時,美國國家科學基金會(NSF)成立了“自然語言處理研究計劃”,專門用于支持自然語言處理技術的研究。同時,英國也成立了“自然語言處理研究室(Natural Language Processing Research Laboratory)”,專門致力于自然語言處理技術的研究與應用。
在20世紀70年代,自然語言處理技術又迎來了一個新的發展階段。這一時期,自然語言處理技術發展到了語言學理論與計算機科學相結合的階段。其中,語義學和句法學等語言學理論成為自然語言處理技術研究的重要基礎。
在20世紀80年代,隨著人工智能技術的進一步發展,自然語言處理技術也進入了一個新的階段。這一時期,自然語言處理技術得到了廣泛應用,并取得了一系列突破性成果。例如,英國語言工程研究所(LEL)在1983年成功開發出了世界上第一個基于人工智能的翻譯系統,該系統能夠將英語翻譯成法語。
在20世紀90年代,自然語言處理技術進一步發展壯大。隨著互聯網的普及,自然語言處理技術在搜索引擎、社交媒體、客服機器人等領域得到廣泛應用。此外,自然語言處理技術還進入了深度學習階段,開始使用深度神經網絡進行語言模型的建立和訓練,從而提升自然語言處理技術的準確性和效率。如今,自然語言處理技術已經成為人工智能領域的重要組成部分,并在多個領域得到廣泛應用。
-
AI
+關注
關注
87文章
30239瀏覽量
268474 -
深度學習
+關注
關注
73文章
5493瀏覽量
120998 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13513 -
OpenAI
+關注
關注
9文章
1045瀏覽量
6411 -
ChatGPT
+關注
關注
29文章
1549瀏覽量
7507
發布評論請先 登錄
相關推薦
利用ChatGPT通過Shell腳本來實現日志分析
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了

科技大廠競逐AIGC,中國的ChatGPT在哪?
如何讓ChatGPT實現MIMO波束賦形
ChatGPT了的七個開源項目

如何讓ChatGPT實現MIMO波束賦形和寫一封會議邀請信?
微軟發布Visual ChatGPT:視覺模型加持ChatGPT實現絲滑聊天
基于ChatGPT實現微信機器人
人工智能技術的風險與應對措施
人工智能技術的風險與應對措施

ChatGPT是怎么實現的






 工商網監
工商網監
評論