 河套IT TALK——TALK42:(原創)視頻制作的人工智能時代要到來了,你準備好了嗎?
河套IT TALK——TALK42:(原創)視頻制作的人工智能時代要到來了,你準備好了嗎?

關聯回顧
(原創)全圖說圖像處理的發展歷史(下)
(原創)全圖說ChatGPT的前世今生
(原創)全圖說動畫技術的發展歷史(下)
一幅獲獎的畫在藝術界炸了鍋近幾個月,關于圖像生成(Text To Image)的人工智能藝術創作,成為科技媒體的熱點話題。從DALL-E,到Stable Diffusion,再到Midjourney,我們能明顯看到深度學習在圖像生成方面肉眼可見的巨大進步。這些人工智能藝術創作工具在藝術界更是引發了不少插畫設計師和藝術家的職業焦慮。特別是去年9月份,當杰森·艾倫 (Jason Allen) 將他的“空間歌劇院”提交給科羅拉多州博覽會的美術比賽時,這幅華麗的印刷品立即大受歡迎,作品中多個人物的肖像,飄逸的長袍,凝視著明亮的遠方,復古風和星際風混搭的如此完美,且精細,立即征服了評委。在“數字處理攝影”類別中擊敗了其他 20 位藝術家,贏得了第一名藍色絲帶和 300 美元的獎金。
然后,艾倫告訴大家,這件藝術品是由人工智能工具Midjourney 創作的。這無疑在藝術界炸開了鍋。很多藝術家開始譴責艾倫用欺騙的手段獲得了獎項。甚至上綱上線,認為Midjourney這類Text to Image的生成工具,將徹底破壞人們的創造性,模糊藝術的邊界,甚至扼殺人類的藝術本身。
但吵歸吵,事情已經發生,而且還有愈演愈烈的趨勢。最近,幾個文本到視頻(Text to Video)的工具悄然興起,讓生成對抗網絡( GAN ) 和擴散模型的機器學習技術突破了圖片生成的邊界,延展到了視頻生成領域。今天我們會介紹三款近期剛剛萌芽的文本到視頻的生成工具。這些工具或許當下看起來都還非常青澀,但也足夠驚艷。根據文本到圖像的發展速度,相信今年,最遲明年,這種技術就會成熟到爐火純青的程度,不信等著瞧:)
Gen-1這個工具有五種使用模式:
風格化(Stylization):將任何圖像或提示的風格轉移到視頻的每一幀。
故事板(Storyboard):將模型變成完全風格化和動畫的渲染。
遮罩(Mask):隔離視頻中的主題并使用簡單的文本提示對其進行修改。
渲染(Render):通過應用輸入圖像或提示,將無紋理渲染變成逼真的輸出。
定制(Customization):通過自定義模型以獲得更高保真度的結果,釋放 Gen-1 的全部功能。

Runway到底是何方神圣?在Runway的主頁上,我們看到他們的slogan是:“Everything you need to make anything you want.”(這里有你制作任何東西所需的一切)。“Make the impossible & Move Creativity Forward” (創造可能,推進創意)。他們的網站上,你能找到幾十種AI多媒體(圖像、聲音、視頻動畫)處理的小工具。Gen-1只是其諸多工具中的一個。
如果大家熟悉Stable Diffusion的話,就會明白,Stable Diffusion是由多家聯合發布的。Runway就是其中之一。
Stable Diffusion是一種潛在的擴散模型(LDM),深度生成神經網絡,代碼和模型權重已經開源,對外發布。Stable Diffusion 由 3 部分組成:變分自動編碼器(VAE)、U-Net和可選的文本編碼器。Stable Diffusion數據訓練采用的是Common Crawl數據,其中包括 50 億個圖像-文本對。
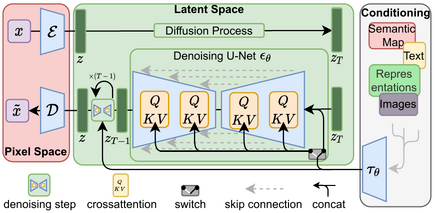
這次Runway發布的Gen-1,用到的還是Stable Diffusion的能力。
Runway是在2018年,由幾位在紐約大學Tisch藝術學院交互式電信項目(ITP)的研究員:克里斯托弗·巴倫蘇埃拉(Cristóbal Valenzuela)、亞歷杭德羅·馬塔馬拉(Alejandro Matamala )和阿納斯塔西斯·澤瑪尼迪斯(Anastasis Germanidis)成立的創業公司。
他們幾位癡迷于藝術與技術交集給藝術創作帶來的幫助。幾位年輕人堅信:利用計算機圖形學和機器學習的最新進展來突破創造力的極限,進而降低內容創作的障礙,必然會開啟新一波講故事的浪潮。
Google Dreamix就人工智能的龍頭老大而言,我們不得不佩服Google。近期,Google也發布了一款Text to Video通用視頻編譯器Google Dreamix。這款工具提供三種工具模式:
- 對已有視頻的編輯:提供一個輸入視頻,再給出一段文字描述,并根據這段文字描述對圖像進行修訂。
-
提供一張圖片,再對這張圖片提供一段描述,然后生成一段視頻來來讓這個圖片動起來。
-
提供一系列圖片,然后再提供一段描述,根據輸入圖片的素材,產生一個視頻動畫符合描述的含義。
從技術上來說,對于視頻編輯,Dreamix 將源圖像加噪并將它們傳遞給視頻擴散模型,然后該模型根據文本提示從噪聲源圖像生成新圖像并將它們組合成視頻。因此,源圖像提供了一種草圖,可以捕捉例如動物的形狀或其運動,同時留出足夠的變化空間。
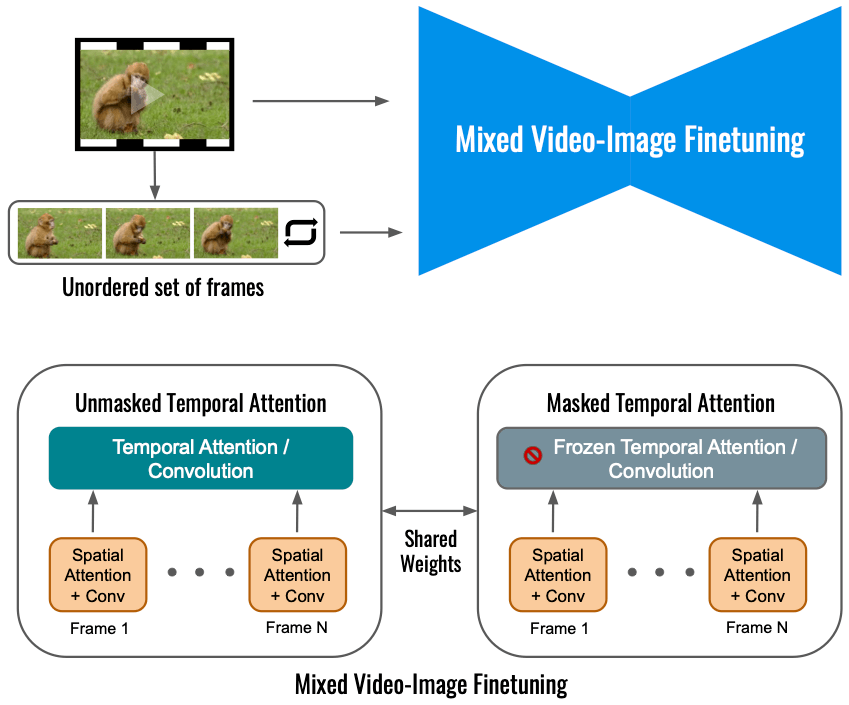
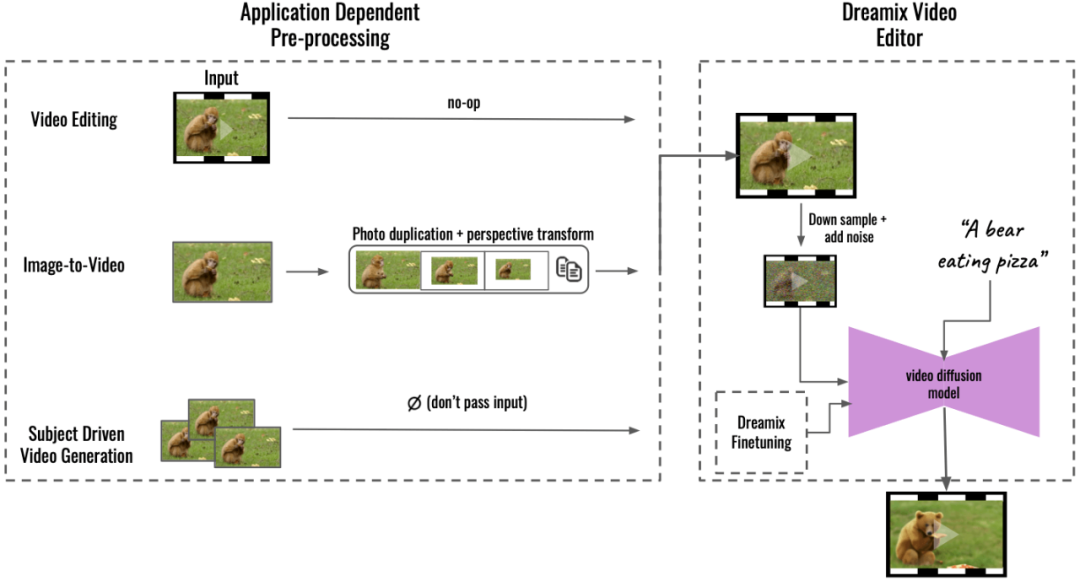
Google在人工智能貢獻遠遠不是Dreamix這么簡單。這個世紀以來至少有幾件事兒,Google是功不可沒的:
-
2011年,谷歌人工智能研究部門Google AI和斯坦福大學教授吳恩達合作,成立了一個深度學習的團隊,取名非常大膽,叫:谷歌大腦(Google Brain),杰夫·迪恩(Jeff" Dean)是負責人。目的是將開放式機器學習研究與信息系統和大規模計算資源相結合。2015年,谷歌大腦搞出來一個TensorFlow。這是一個在Apache License 2.0下開源的用于機器學習和人工智能的免費開源軟件庫。采用于深度神經網絡的訓練和推理。后續很多機器學習的初創公司都受益于TensorFlow。
-
針對TensorFlow,Google開發了新的硬件Tensor Processing Unit(TPU),這是一種專門為神經網絡機器學習開發的AI加速器專用集成電路(ASIC)。谷歌于 2015 年開始在內部使用 TPU,并于 2018 年將其提供給第三方使用,既作為其云基礎設施的一部分,也通過出售較小版本的芯片。TPU對待深度卷積神經網絡的運算效率要高于GPU。當然我們要承認,由于TPU僅僅是為了TensorFlow的優化,目前主流的人工智能圖像生成領域,硬件還是以GPU為主。2007年,隨著 Nvidia GeForce 8 系列的推出,以及隨后新的通用流處理單元,GPU 成為一種更通用的計算設備。GPU 上的通用計算開始真正進入機器學習領域,讓標準神經網絡在GPU實施比CPU上的等效實施快 20 倍。正是因為這種邊際成本的變化,才激發了很多初創公司開始投身于人工智能的領域。
-
Google工程師 亞歷山大·莫德文采夫(Alexander Mordvintsev )為2014年ImageNet大規模視覺識別挑戰賽(ILSVRC)開發了一個深度卷積計算機視覺程序DeepDream。這名字來源于電影《盜夢空間》。DeepDream使用卷積神經網絡通過算法錯視來查找和增強圖像中的模式,從而在故意過度處理的圖像中創造出一種夢幻般的外觀,讓人聯想到迷幻體驗。2015年7月,程序發布后,被行業熱捧,也激發了很多藝術界的人士,意識到用機器學習充實藝術創作的巨大潛能。
-
2017年,Google Brain團隊又搞出來一個深度學習模型Transformer,采用自注意力機制,對輸入數據的每一部分的重要性進行差異加權。這個模型直接刺激了預訓練系統的發展。Transformer在自然語言處理和圖像處理都表現了非凡的優勢。后來的OpenAI的GPT,就是基于Transformer的應用。
當然,除了Google之外,另外一家行業大佬Meta也沒有閑著。盡管操作了很久的元宇宙并未達到預期效果,Meta還是在圖像生成領域做了大膽的嘗試。
Make-a-VideoMeta AI是Meta平臺公司(原Facebook)的人工智能實驗室(FAIR)。最近Meta AI搞了一個工具,叫Make-a-Video。是一款通過深度學習的方式實現從文本到視頻。Make-a-Video支持三種用法:
1. 單純的Text to Video,人們可以使用盡可能詳盡的語言來描繪視頻的內容,以及選定對應視頻的風格(現實、超現實主義、風格化),然后來生成對應的視頻,比如:
泰迪熊在畫自畫像

2. 從靜到動(From Static to Magic)
比如一艘大海航行船的圖像:

可以通過Make-a-Video生成一個動圖:

3. 為視頻添加額外的創意
可以根據原始視頻創建視頻的變體,比如下面這個多色的毛茸跳舞者

通過Make-a-Video可以生成多個變體:?


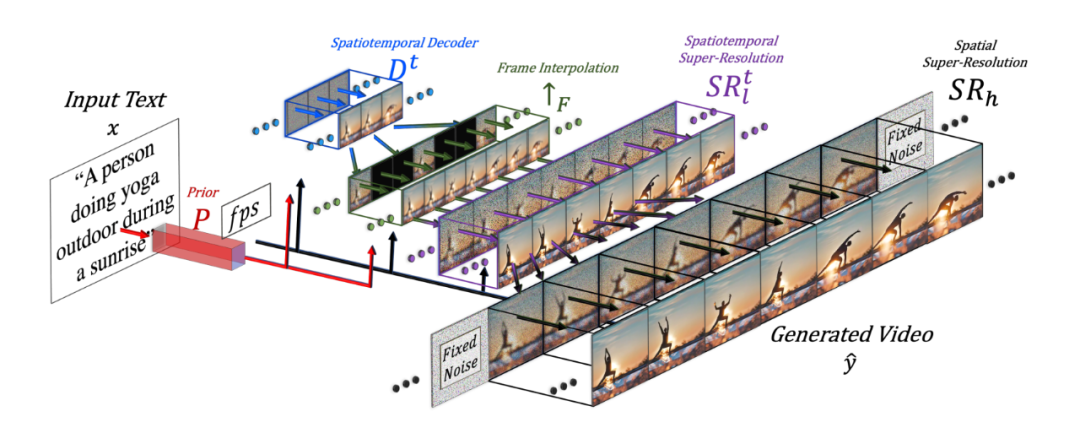
?從技術上來看,Meta這個工具首先可以分解完整的時間U-Net和注意力張量,并在空間和時間上進行近似。其次,設計了一個通過差值模型來實現時空管道來生成高分辨率和幀率的視頻。
其實人工智能在藝術領域的介入從2015年左右就開始進入大眾的視野了。那個時候,主要的應用場景是通過神經網絡和人工智能應用某些藝術效果來轉換已有的圖片。相信大家都有印象包括Prisma、Pikazo、Painnt、Lucid、Artisto、Style和DeepArt等一系列的App出現在應用市場上。這些App多半是將人工智能作為特效濾鏡的方式來運用,把一張普通的照片,轉換為梵高、莫奈、達利和畢加索等等一系列藝術畫風格的作品,當然,高級一些的,還會生成視頻。
之所以卡在這個時間點突然出現,主要要歸功于伊恩·古德費洛(Ian Goodfellow)完成了一項人工智能神經網絡的研究,發明了生成對抗網絡(Generative adversarial network,簡稱GAN)。這種技術可以讓經過照片訓練的 GAN 可以生成新照片,這些照片至少在人類觀察者看來是真實的,具有許多現實特征。最初GAN是作為無監督學習的生成模型形式提出來的,但事實證明,GAN也可以用于半監督學習、全監督學習、和強化學習。

隨著伊恩·古德費洛畢業加入Google后,他的同事就用他的GAN搞了一個DeepDream,這種奇幻的效果立即給AI藝術創作屆打了一針強心劑。緊接著,一堆的初創公司就如春筍般生長起來了。
開源在技術上迸發的力量軟件開源,盡管現在已經幾乎眾人皆知的開發模式,但其實從前麻省理工學院人工智能實驗室的研究員理查德·斯托曼(Richard Stallman)不滿閉源軟件的不便,進而在Dr. Dobb‘s軟件雜志上憤然發表《GNU宣言》(The GNU Manifesto),直到2005年,30年過去了,從自由軟件到開源,還一直都是小圈子的事情。

2005年,萊納斯·托沃茲(Linus Torvalds)開發了Git,進而在2007年孵化出GitHub,才徹底改變了局面。GitHub的出現,讓開源項目全球化協作和軟件版本管理變得無比便捷。
而正是因為用于機器學習和人工智能的免費開源軟件庫TensorFlow、OpenAI的GPT模型代碼和GPT-2和Google深度學習模型Transformer等等這些軟件能力被開源了,才會被世界上其他心中有藝術夢想的程序員所獲得,才會激發這個圖像生成產業的繁榮。
也正是這個原因,當看到OpenAI不再把自回歸語言模型GPT-3繼續開源之后,我心中開始對這家公司表示質疑,估計OpenAI會在短期盈利,但是很難走的長遠。
優質的數據訓練是基礎
 2001年,美國法律學者和政治活動家、哈佛大學教授勞倫斯·萊西格(Lester Lawrence Lessig)拉著哈羅德·阿貝爾森和埃里克·埃爾德雷德在紅帽羅伯特·揚(Bob Young)的公共領域中心支持下,成立了一個非營利組織知識共享組織(Creative Commons ,簡稱CC ) 。鼓勵創作者采用“CC授權”,來推動知識和作品的共享和創新,積極促成學術資料、音樂、文學、電影和科學作品對大眾開放, 并向全球各國推廣。
2001年,美國法律學者和政治活動家、哈佛大學教授勞倫斯·萊西格(Lester Lawrence Lessig)拉著哈羅德·阿貝爾森和埃里克·埃爾德雷德在紅帽羅伯特·揚(Bob Young)的公共領域中心支持下,成立了一個非營利組織知識共享組織(Creative Commons ,簡稱CC ) 。鼓勵創作者采用“CC授權”,來推動知識和作品的共享和創新,積極促成學術資料、音樂、文學、電影和科學作品對大眾開放, 并向全球各國推廣。

同年,由吉米·威爾士(Jimmy Wales)發起的多語言的免費在線百科全書維基百科啟動。內容許可遵守CC Attribution 和 Share-Alike 3.0。

2012年,亞馬遜Amazon Web Services開始通過Common Crawl基金會這個非營利組織負責抓取網絡并免費向公眾提供其檔案和數據集。致力于使互聯網信息訪問民主化的非營利組織。
沒有這些符合CC協議的優質內容的大型平臺,GAN的機器學習,算法再好,也是無源之水。比如:也正是有了CC協議的這些優質數據資源,類似LAION(德國的非營利組織)才能夠去調用這些數據,專門訓練很多備受矚目的文本到圖像模型,包括Stable Diffusion和Imagen。
不可阻擋的藝術平民化藝術圈的很多人都明白,藝術在當代社會的生存空間已經被極大地壓縮了。圈內人流傳一種說法:藝術家不會忙死,不會焦慮死,但藝術家會被餓死。現在很多藝術創作工具都是商業化工具,購買軟件要花費高昂的成本,對于很多剛剛踏足藝術工作的新人來講,這些預支成本往往帶來巨大的生存壓力。
從最近圖像生成、視頻生成炒作熱度可以看出,藝術界的這種訴求非常強烈。今天介紹的幾個工具,應該都是深知藝術圈這種窘境和痛苦的。他們的使命就是讓所有人都能零起步低成本創作內容。他們也明白,解決這個問題的關鍵在于要擁抱機器學習的AI時代,他們堅信機器學習能讓藝術創作民主化,平等化,而不是被壟斷在大的廣告公司和特效公司手里。
藝術平民化的道路,其實從文藝復興后,一直都在不停地迭代,從印象派到抽象派到達達主義之后到波普藝術,都是在簡化藝術創作的難度和門檻上變得越來越容易,而AI讓這個進程又加速了,讓普通人不僅僅可以創作藝術,而且還能創作出藝術家才能創造的高品質的藝術作品,這無疑是一種變革。因為AI讓普通人站在了藝術界巨人的肩膀上。
寫在最后我們經常會為一個新的技術熱點出現而興奮,但每個熱點的背后,都不是憑空產生的。在到達引爆媒體的臨界點之前的蓄能階段,有很多的技術和平臺,都在孵化這個引爆點。如果用放大鏡去看,都有有軌跡可循的。我們會洞見到:生態界和教育界的配合,非營利機構和營利產業界的配合,某些行業領袖開放開源的胸懷。而往往每一環都是關鍵的助推力量,缺少任何一環,技術的引爆點都可能會延遲數年,甚至數十年。但有一點是明確的:是金子,最后一定會發光,但天時地利人和是何時何地發光的關鍵。
原文標題:河套IT TALK——TALK42:(原創)視頻制作的人工智能時代要到來了,你準備好了嗎?
文章出處:【微信公眾號:開源技術服務中心】歡迎添加關注!文章轉載請注明出處。
-
開源技術
+關注
關注
0文章
389瀏覽量
7914 -
OpenHarmony
+關注
關注
25文章
3661瀏覽量
16159
原文標題:河套IT TALK——TALK42:(原創)視頻制作的人工智能時代要到來了,你準備好了嗎?
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【開源項目】你準備好DIY一款功能強大的機器人了嗎?
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
用TAS5631做音頻功放,需要怎么做才能使芯片準備好呢?
人工智能ai4s試讀申請
Google開發專為視頻生成配樂的人工智能技術
MINIWARE的品牌故事,你了解多少?

RISC-V Foundational Associate (RVFA) 官方認證,你準備好了嗎?

stm8外部時鐘未準備好是怎么回事?
NDI 6來了!你的設備準備好了嗎?

嵌入式人工智能的就業方向有哪些?
OpenAI發布人工智能文生視頻大模型Sora
基于TRIZ的可穿戴設備:未來已來,你準備好了嗎?

身邊的人工智能有哪些
Copilot Studio全面進駐你的日常辦公軟件,你準備好了嗎?






 工商網監
工商網監
評論