") 開源模型OpenCLIP達(dá)成ImageNet里程碑成就!
開源模型OpenCLIP達(dá)成ImageNet里程碑成就!
【導(dǎo)讀】開源模型OpenCLIP達(dá)成ImageNet里程碑成就!
? ? 雖然ImageNet早已完成歷史使命,但其在計(jì)算機(jī)視覺領(lǐng)域仍然是一個(gè)關(guān)鍵的數(shù)據(jù)集。 2016年,在ImageNet上訓(xùn)練后的分類模型,sota準(zhǔn)確率仍然還不到80%;時(shí)至今日,僅靠大規(guī)模預(yù)訓(xùn)練模型的zero-shot泛化就能達(dá)到80.1%的準(zhǔn)確率。
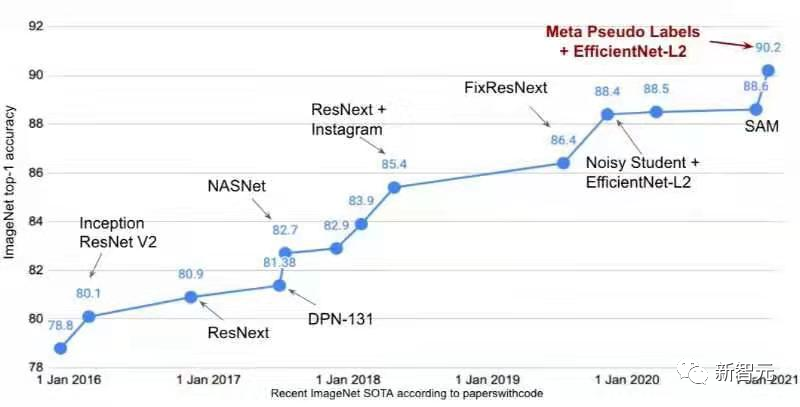
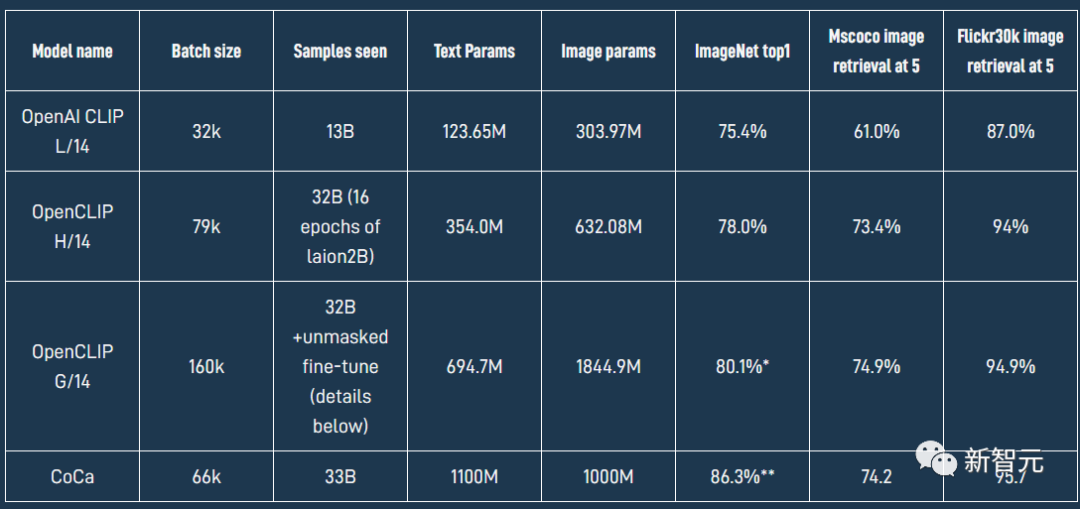
最近LAION使用開源代碼OpenCLIP框架訓(xùn)練了一個(gè)全新的 ViT-G/14 CLIP 模型,在 ImageNet數(shù)據(jù)集上,原版OpenAI CLIP的準(zhǔn)確率只有75.4%,而OpenCLIP實(shí)現(xiàn)了80.1% 的zero-shot準(zhǔn)確率,在 MS COCO 上實(shí)現(xiàn)了74.9% 的zero-shot圖像檢索(Recall@5),這也是目前性能最強(qiáng)的開源 CLIP 模型。
LAION全稱為L(zhǎng)arge-scale Artificial Intelligence Open Network,是一家非營(yíng)利組織,其成員來自世界各地,旨在向公眾提供大規(guī)模機(jī)器學(xué)習(xí)模型、數(shù)據(jù)集和相關(guān)代碼。他們聲稱自己是真正的Open AI,100%非盈利且100%免費(fèi)。 感興趣的小伙伴可以把手頭的CLIP模型更新版本了!
模型地址:https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
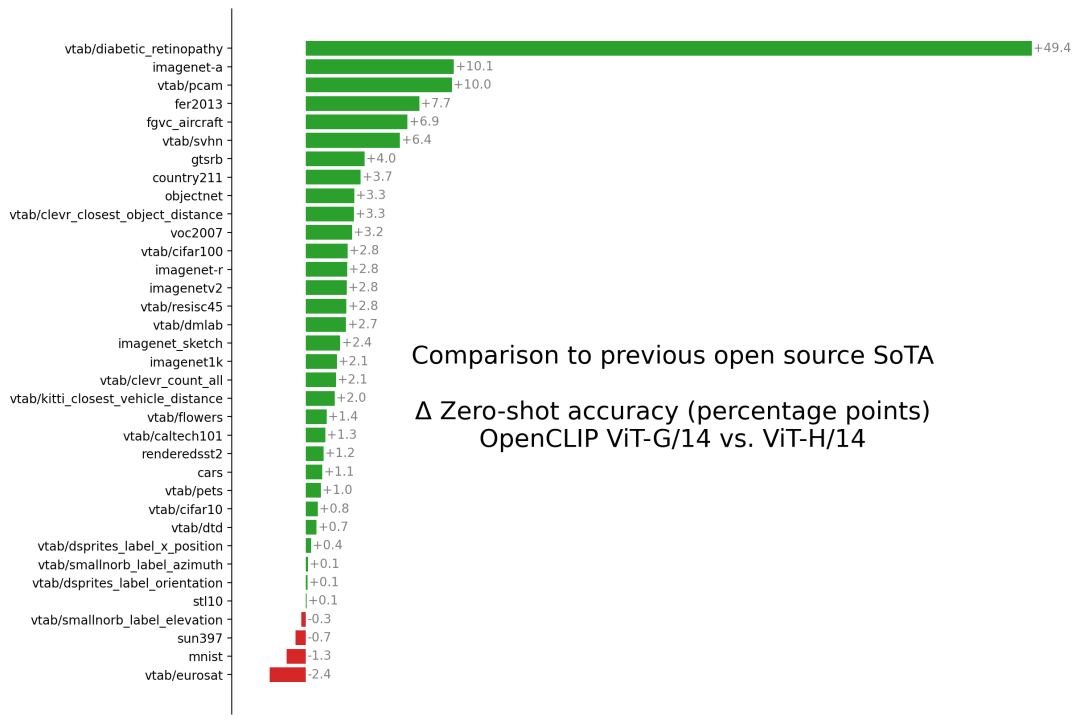
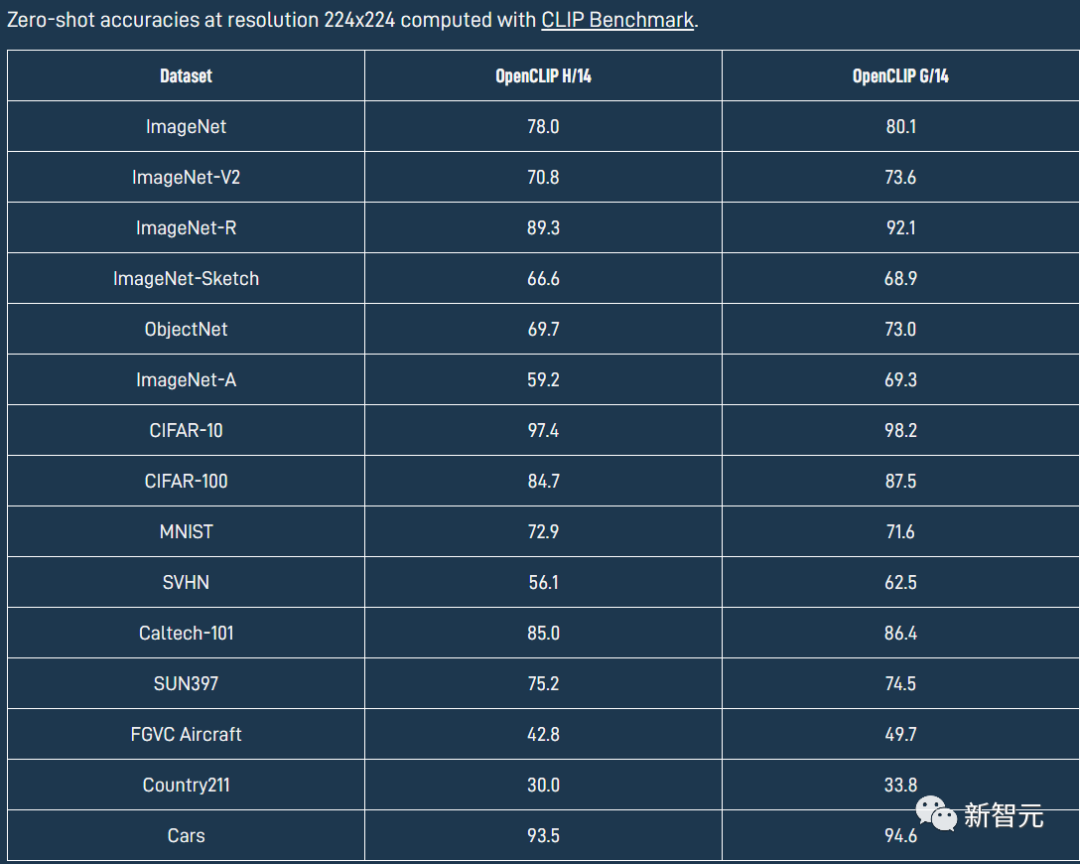
OpenCLIP模型在各個(gè)數(shù)據(jù)集上具體的性能如下表所示。
Zero-shot能力
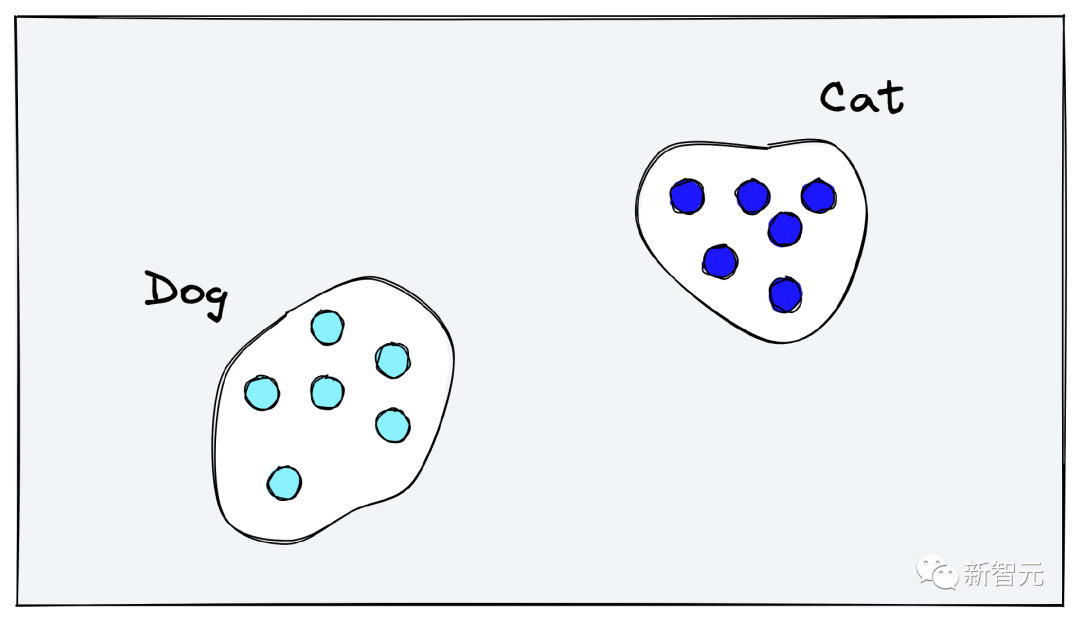
一般來說,計(jì)算機(jī)視覺(CV)模型在各個(gè)任務(wù)上的sota性能都是基于特定領(lǐng)域的訓(xùn)練數(shù)據(jù),無法泛化到其他領(lǐng)域或任務(wù)中,導(dǎo)致對(duì)視覺世界的通用屬性理解有限。 泛化問題對(duì)于那些缺少大量訓(xùn)練數(shù)據(jù)的領(lǐng)域尤其重要。 理想情況下,CV模型應(yīng)該學(xué)會(huì)圖像的語義內(nèi)容,而非過度關(guān)注訓(xùn)練集中的特定標(biāo)簽。比如對(duì)于狗的圖像,模型應(yīng)該能夠理解圖像中有一只狗,更進(jìn)一步來理解背景中有樹、時(shí)間是白天、狗在草地上等等。 但當(dāng)下采用「分類訓(xùn)練」得到的結(jié)果與預(yù)期正好相反,模型學(xué)習(xí)將狗的內(nèi)部表征推入相同的「狗向量空間」,將貓推入相同的「貓向量空間」,所有的問題的答案都是二元,即圖像是否能夠與一個(gè)類別標(biāo)簽對(duì)齊。
對(duì)新任務(wù)重新訓(xùn)練一個(gè)分類模型也是一種方案,但是訓(xùn)練本身需要大量的時(shí)間和資金投入來收集分類數(shù)據(jù)集以及訓(xùn)練模型。 幸運(yùn)的是,OpenAI 的CLIP模型是一個(gè)非常靈活的分類模型,通常不需要重新訓(xùn)練即可用于新的分類任務(wù)中。
CLIP為何能Zero-Shot
對(duì)比語言-圖像預(yù)訓(xùn)練(CLIP, Contrastive Language-Image Pretraining)是 OpenAI 于2021年發(fā)布的一個(gè)主要基于Transformer的模型。
CLIP 由兩個(gè)模型組成,一個(gè)Transformer編碼器用于將文本轉(zhuǎn)換為embedding,以及一個(gè)視覺Transformer(ViT)用于對(duì)圖像進(jìn)行編碼。
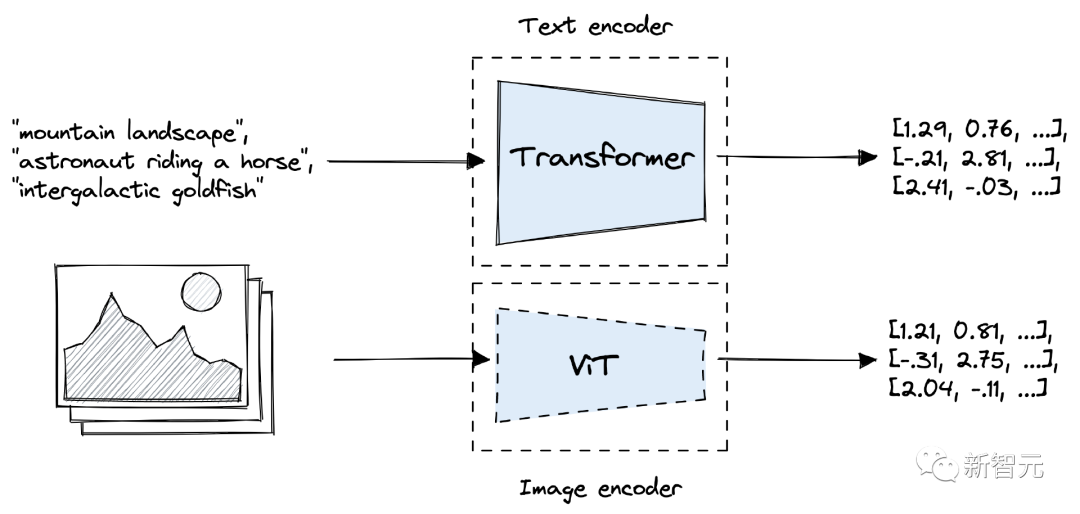
CLIP內(nèi)的文本和圖像模型在預(yù)訓(xùn)練期間都進(jìn)行了優(yōu)化,以在向量空間中對(duì)齊相似的文本和圖像。在訓(xùn)練過程中,將數(shù)據(jù)中的圖像-文本對(duì)在向量空間中將輸出向量推得更近,同時(shí)分離不屬于一對(duì)的圖像、文本向量。
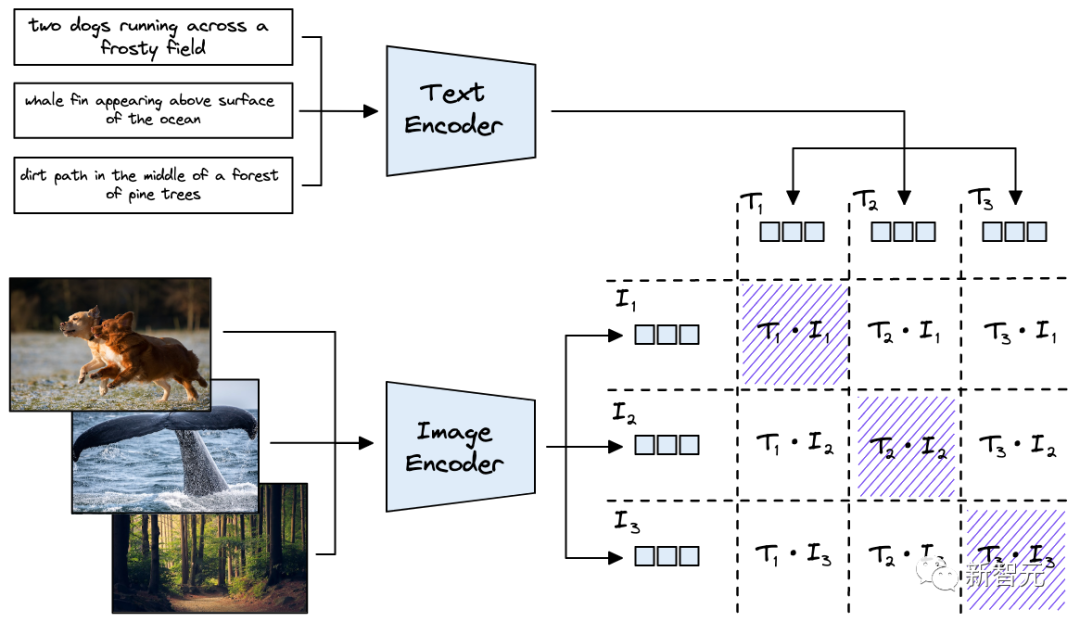
CLIP與一般的分類模型之間有幾個(gè)區(qū)別:
首先,OpenAI 使用從互聯(lián)網(wǎng)上爬取下來的包含4億文本-圖像對(duì)的超大規(guī)模數(shù)據(jù)集進(jìn)行訓(xùn)練,其好處在于:
1. CLIP的訓(xùn)練只需要「圖像-文本對(duì)」而不需要特定的類標(biāo)簽,而這種類型的數(shù)據(jù)在當(dāng)今以社交媒體為中心的網(wǎng)絡(luò)世界中非常豐富。
2. 大型數(shù)據(jù)集意味著 CLIP 可以對(duì)圖像中的通用文本概念進(jìn)行理解的能力。
3. 文本描述(text descriptor)中往往包含圖像中的各種特征,而不只是一個(gè)類別特征,也就是說可以建立一個(gè)更全面的圖像和文本表征。
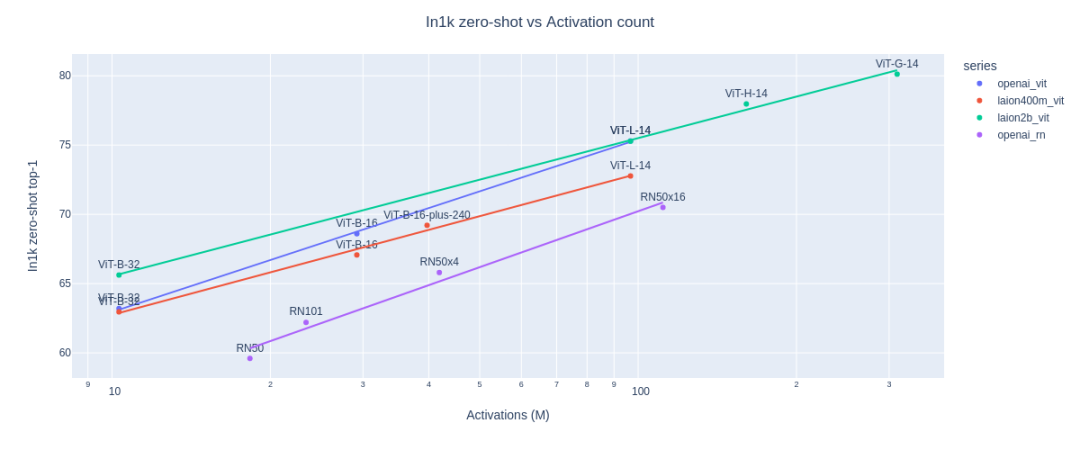
上述優(yōu)勢(shì)也是CLIP其建立Zero-shot能力的關(guān)鍵因素,論文的作者還對(duì)比了在ImageNet上專門訓(xùn)練的 ResNet-101模型和 CLIP模型,將其應(yīng)用于從ImageNet 派生的其他數(shù)據(jù)集,下圖為性能對(duì)比。
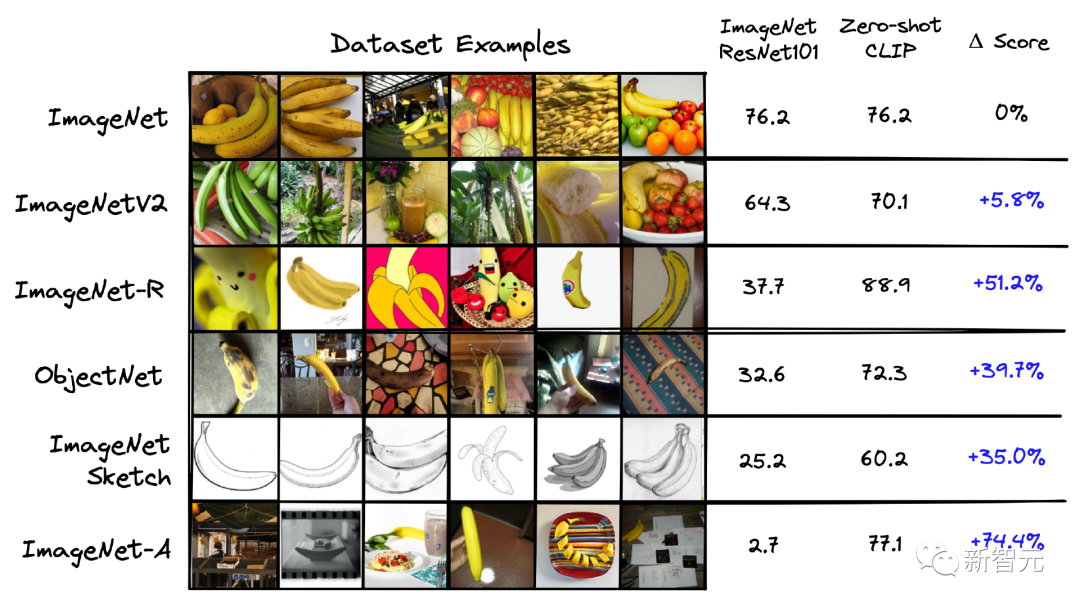
可以看到,盡管 ResNet-101是在ImageNet上進(jìn)行訓(xùn)練的,但它在相似數(shù)據(jù)集上的性能要比 CLIP 在相同任務(wù)上的性能差得多。
在將 ResNet 模型應(yīng)用于其他領(lǐng)域時(shí),一個(gè)常用的方法是「linear probe」(線性探測(cè)),即將ResNet模型最后幾層所學(xué)到的特性輸入到一個(gè)線性分類器中,然后針對(duì)特定的數(shù)據(jù)集進(jìn)行微調(diào)。
在CLIP論文中,線性探測(cè)ResNet-50與zero-shot的CLIP 進(jìn)行了對(duì)比,結(jié)論是在相同的場(chǎng)景中,zero-shot CLIP 在多個(gè)任務(wù)中的性能都優(yōu)于在ResNet-50中的線性探測(cè)。
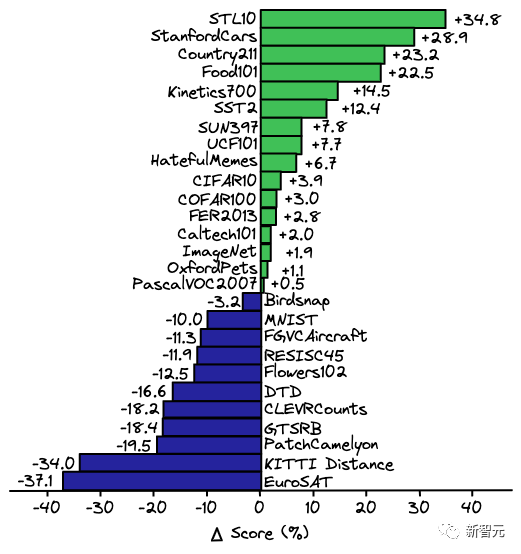
不過值得注意的是,當(dāng)給定更多的訓(xùn)練樣本時(shí),Zero-shot并沒有優(yōu)于線性探測(cè)。
用CLIP做Zero-shot分類
從上面的描述中可以知道,圖像和文本編碼器可以創(chuàng)建一個(gè)512維的向量,將輸入的圖像和文本輸入映射到相同的向量空間。
用CLIP做Zero-shot分類也就是把類別信息放入到文本句子中。
舉個(gè)例子,輸入一張圖像,想要判斷其類別為汽車、鳥還是貓,就可以創(chuàng)建三個(gè)文本串來表示類別:
T1代表車:a photo of a car
T2代表鳥:a photo of a bird
T3代表貓:a photo of a cat
將類別描述輸入到文本編碼器中,就可以得到可以代表類別的向量。
假設(shè)輸入的是一張貓的照片,用 ViT 模型對(duì)其進(jìn)行編碼獲取圖像向量后,將其與類別向量計(jì)算余弦距離作為相似度,如果與T3的相似度最高,就代表圖像的類別屬于貓。
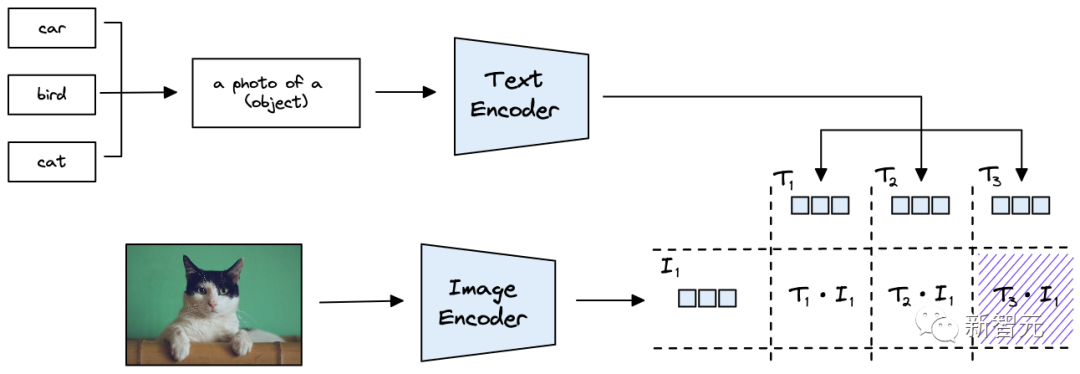
可以看到,類別標(biāo)簽并不是一個(gè)簡(jiǎn)單的詞,而是基于模板「a photo of a {label}」的格式重新改寫為一個(gè)句子,從而可以擴(kuò)展到不受訓(xùn)練限制的類別預(yù)測(cè)。
實(shí)驗(yàn)中,使用該prompt模板在ImageNet的分類準(zhǔn)確性上提高了1.3個(gè)百分點(diǎn),但prompt模板并不總是能提高性能,在實(shí)際使用中需要根據(jù)不同的數(shù)據(jù)集進(jìn)行測(cè)試。
Python實(shí)現(xiàn)
想要快速使用CLIP做zero-shot分類也十分容易,作者選取了Hugging Face中的frgfm/imagenette數(shù)據(jù)集作為演示,該數(shù)據(jù)集包含10個(gè)標(biāo)簽,且全部保存為整數(shù)值。

使用 CLIP進(jìn)行分類,需要將整數(shù)值標(biāo)簽轉(zhuǎn)換為對(duì)應(yīng)的文本內(nèi)容。
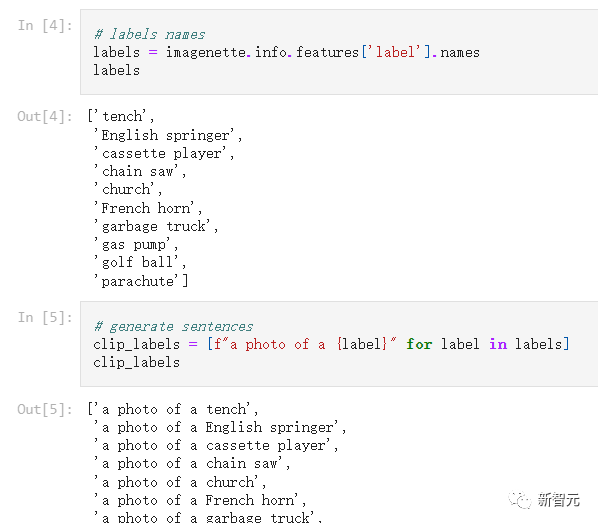
在直接將標(biāo)簽和照片進(jìn)行相似度計(jì)算前,需要初始化 CLIP模型,可以使用通過 Hugging Face transformers找到的 CLIP 實(shí)現(xiàn)。

文本transformer無法直接讀取文本,而是需要一組稱為token ID(或input _ IDs)的整數(shù)值,其中每個(gè)唯一的整數(shù)表示一個(gè)word或sub-word(即token)。

將轉(zhuǎn)換后的tensor輸入到文本transformer中可以獲取標(biāo)簽的文本embedding

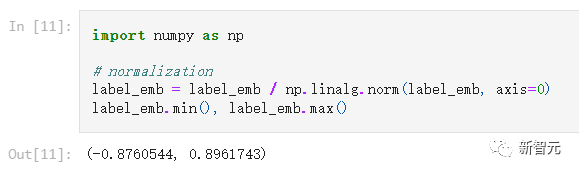
注意,目前CLIP輸出的向量還沒有經(jīng)過歸一化(normalize),點(diǎn)乘后獲取的相似性結(jié)果是不準(zhǔn)確的。
下面就可以選擇一個(gè)數(shù)據(jù)集中的圖像作測(cè)試,經(jīng)過相同的處理過程后獲取到圖像向量。

將圖像轉(zhuǎn)換為尺寸為(1, 3, 224, 224)向量后,輸入到模型中即可獲得embedding

下一步就是計(jì)算圖像embedding和數(shù)據(jù)集中的十個(gè)標(biāo)簽文本embedding之間的點(diǎn)積相似度,得分最高的即是預(yù)測(cè)的類別。

模型給出的結(jié)果為cassette player(盒式磁帶播放器),在整個(gè)數(shù)據(jù)集再重復(fù)運(yùn)行一遍后,可以得到準(zhǔn)確率為98.7%

除了Zero-shot分類,多模態(tài)搜索、目標(biāo)檢測(cè)、 生成式模型如OpenAI 的 Dall-E 和 Stable disusion,CLIP打開了計(jì)算機(jī)視覺的新大門。
審核編輯 :李倩
-
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1696瀏覽量
45927 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24644 -
Clip
+關(guān)注
關(guān)注
0文章
31瀏覽量
6649
原文標(biāo)題:ImageNet零樣本準(zhǔn)確率首次超過80%!OpenCLIP:性能最強(qiáng)的開源CLIP模型
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
直線模組新技術(shù)里程碑
重要的里程碑:售出了10億顆點(diǎn)火IGBT
敦泰科技與TSMC達(dá)成1000萬顆觸控芯片出貨里程碑
3D CAD模型程序發(fā)展里程碑:更完善、更流暢!
Velodyne : 出貨30000臺(tái),5億美元銷售里程碑
Xilinx 創(chuàng)下新里程碑,Versal ACAP 開始出貨了!
我國(guó)首次火星探測(cè)器天問一號(hào)達(dá)成新里程碑
了解Linux on IBM Z的重大里程碑
PingCAP創(chuàng)造全球數(shù)據(jù)庫歷史新的里程碑
開源模型OpenCLIP達(dá)成ImageNet里程碑成就
它人機(jī)器人與俄羅斯的AVIALIFT正式攜手,達(dá)成里程碑式合作






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論